- 1 应用部署方式的演变
- 2 kubernetes 简介
- 3 kubernetes 组件
- 4 kubernetes 概念
- 2.k8s集群环境的搭建
- 1 环境规划
- 2 环境搭建
- 3 服务部署
- 4 kubernetes中kubectl命令自动补全
- k8s的资源管理
- 1 资源管理介绍
- 2 YAML语法介绍
- 3 资源管理方式
- 注意这两种展示方式,会展示出来非常的信息。
- 3.3 命令式对象配置
- 上边就会创建出来一个 叫做dev的namespace
- 3.4 声明式对象配置
- 3.5 使用方式推荐
- 3.6 扩展:kubectl可以在Node上运行
- 4 如何快速的编写yaml文件
- 5.k8s的实战入门
- 1 前言
- 2 Namespace
- 或者
- 查看具体命名空间
- 3 Pod
- 注意我们这里要指定 -n dev 标识从哪个名称空间查找,否则他会默认去default这个名称
- 这样可以看到更详细的关于这个pod的信息
- 这里上边的 nginx-f89759699-vsx59 这个名字不用写全,也可以查询到,他会把所有匹配的pod的详细信息都输出出来。List也就是
- 4 Label
- 5 Deployment(pod控制器)
- 6 Service
- 暴露Service
#kubectl expose deployment xxx —name=service的名称 —type=ClusterIP —port=暴露的端口,指定service的端口 —target-port=指向集群中的Pod的端口 [-n 命名空间] - 上述命令可以发现,这里是通过指定deployment来创建service的,因为pod都是通过deploy来管理的。所以这样写能更有表达性
#type的类型有很多种,这里用ClusterIP 表示的是集群IP,如果不指定,他默认也是ClusterIP - 会产生一个CLUSTER-IP,这个就是service的IP,在Service的生命周期内,这个地址是不会变化的
- 注意:type= ClusterIP这个类型的IP只能在集群内部访问,就是部署集群的机器上,外部是不能访问的。
- k8s的Pod详解
- 1 Pod的介绍
- 2 Pod的配置
- ">此时已经运行起来了一个基本的Pod,虽然它暂时有问题
kubectl describe pod pod-base -n dev
特别说明:通过上面发现command已经可以完成启动命令和传递参数的功能,为什么还要提供一个args选项,用于传递参数?其实和Docker有点关系,kubernetes中的command和args两个参数其实是为了实现覆盖Dockerfile中的ENTRYPOINT的功能:">在容器中执行命令
# kubectl exec -it pod的名称 -n 命名空间 -c 容器名称 /bin/sh
#上述的容器名称要和yaml中的 name指定的容器名字一样
kubectl exec -it pod-command -n dev -c busybox /bin/sh
特别说明:通过上面发现command已经可以完成启动命令和传递参数的功能,为什么还要提供一个args选项,用于传递参数?其实和Docker有点关系,kubernetes中的command和args两个参数其实是为了实现覆盖Dockerfile中的ENTRYPOINT的功能:- 3 Pod的生命周期
- 4 Pod的调度
- 5 临时容器
- 6 服务质量Qos
1 应用部署方式的演变
1.1 应用部署方式的演变
- 在部署应用程序的方式上,主要经历了三个时代:
- ① 传统部署:
- 互联网早期,会直接将应用部署在物理机上。
- 优点:简单,不需要其他的技术参与。
- 缺点:不能为应用程序定义资源的使用边界,很难合理的分配计算机资源,而且程序之间容易产生影响。
- ② 虚拟化部署:
- 可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境。
- 优点:程序环境不会相互产生影响,提供了一定程序上的安全性。
- 缺点:增加了操作系统,浪费了部分资源。
③ 容器化部署:
容器化部署方式带来了很多的便利,但是也会带来一些问题,比如:
- 一旦容器故障停机了,怎么让另外一个容器立刻启动去替补停机的容器。
- 当并发访问量变大的时候,怎么做到横向扩展容器数量。
- ……
这些容器管理的问题统称为 容器编排问题 ,为了解决这些容器编排问题,就产生了一些容器编排的软件:
Kubernetes,是一个全新的基于容器技术的分布式架构领先方案,是 Google 严格保密十几年的秘密武器— Borg 系统的一个开源版本,于 2014 年 9 月发布第一个版本,2015 年 7 月发布第一个正式版本。
Kubernetes 的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。它的目的就是实现资源管理的自动化,主要提供了如下的功能:
一个 kubernetes 集群主要由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件。
- 控制节点(master):集群的控制平面,负责集群的决策。
- API Server:集群操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制。
- Scheduler:负责集群资源调度,按照预定的调度策略将 Pod 调度到相应的 node 节点上。
- ControllerManager:负责维护集群的状态,比如程序部署安排、故障检测、自动扩展和滚动更新等。
- Etcd:负责存储集群中各种资源对象的信息。
- 工作节点(node):集群的数据平面,负责为容器提供运行环境。
- Kubelet:负责维护容器的生命周期,即通过控制 Docker ,来创建、更新、销毁容器。
- KubeProxy:负责提供集群内部的服务发现和负载均衡。
- Docker:负责节点上容器的各种操作。

3.2 kubernetes 组件调用关系的应用示例
- 以部署一个 Nginx 服务来说明 Kubernetes 系统各个组件调用关系:
- ① 首先需要明确,一旦 Kubernetes 环境启动之后,master 和 node 都会将自身的信息存储到etcd数据库中。
- ② 一个Nginx服务的安装请求首先会被发送到 master 节点上的 API Server 组件。
- ③ API Server 组件会调用 Scheduler 组件来决定到底应该把这个服务安装到那个 node 节点上。此时,它会从 etcd 中读取各个 node 节点的信息,然后按照一定的算法进行选择,并将结果告知 API Server 。
- ④ API Server 调用 Controller-Manager 去调用 Node 节点安装 Nginx 服务。
- ⑤ Kubelet 接收到指令后,会通知 Docker ,然后由 Docker 来启动一个 Nginx 的 Pod 。Pod 是 Kubernetes 的最小操作单元,容器必须跑在 Pod 中。
⑥ 一个 Nginx 服务就运行了,如果需要访问 Nginx ,就需要通过 kube-proxy 来对 Pod 产生访问的代理,这样,外界用户就可以访问集群中的 Nginx 服务了。
4 kubernetes 概念
Master:集群控制节点,每个集群要求至少有一个 Master 节点来负责集群的管控。
- Node:工作负载节点,由 Master 分配容器到这些 Node 工作节点上,然后 Node 节点上的 Docker 负责容器的运行。
- Pod:Kubernetes 的最小控制单元,容器都是运行在 Pod 中的,一个 Pod 中可以有一个或多个容器。
- Controller:控制器,通过它来实现对 Pod 的管理,比如启动 Pod 、停止 Pod 、伸缩 Pod 的数量等等。
- Service:Pod 对外服务的统一入口,其下面可以维护同一类的多个 Pod 。
- Label:标签,用于对 Pod 进行分类,同一类 Pod 会拥有相同的标签。
NameSpace:命名空间,用来隔离 Pod 的运行环境。
2.k8s集群环境的搭建
1 环境规划
1.1 集群类型
Kubernetes集群大致分为两类:一主多从和多主多从。
- 一主多从:一个Master节点和多台Node节点,搭建简单,但是有单机故障风险,适合用于测试环境。
- 多主多从:多台Master和多台Node节点,搭建麻烦,安全性高,适合用于生产环境。

1.2 安装方式
- kubernetes有多种部署方式,目前主流的方式有kubeadm、minikube、二进制包。
- ① minikube:一个用于快速搭建单节点的kubernetes工具。
- ② kubeadm:一个用于快速搭建kubernetes集群的工具。
- ③ 二进制包:从官网上下载每个组件的二进制包,依次去安装,此方式对于理解kubernetes组件更加有效。
- 我们需要安装kubernetes的集群环境,但是又不想过于麻烦,所以选择kubeadm方式。
1.3 主机规划
| 角色 | IP地址 | 操作系统 | 配置 | | —- | —- | —- | —- | | Master | 192.168.18.100 | CentOS7.8+,基础设施服务器 | 2核CPU,2G内存,50G硬盘 | | Node1 | 192.168.18.101 | CentOS7.8+,基础设施服务器 | 2核CPU,2G内存,50G硬盘 | | Node2 | 192.168.18.102 | CentOS7.8+,基础设施服务器 | 2核CPU,2G内存,50G硬盘 |
2 环境搭建
2.1 前言
- 本次环境搭建需要三台CentOS服务器(一主二从),然后在每台服务器中分别安装Docker(18.06.3)、kubeadm(1.18.0)、kubectl(1.18.0)和kubelet(1.18.0)。
2.2 环境初始化
2.2.1 检查操作系统的版本
- 检查操作系统的版本(要求操作系统的版本至少在7.5以上):

2.2.2 关闭防火墙和禁止防火墙开机启动

hostnamectl set-hostname
- 设置192.168.18.100的主机名:
hostnamectl set-hostname k8s-master
- 设置192.168.18.101的主机名:
hostnamectl set-hostname k8s-node1
- 设置192.168.18.102的主机名:
hostnamectl set-hostname k8s-node2
2.2.4 主机名解析
- 为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的DNS服务器。
cat >> /etc/hosts << EOF
192.168.18.100 k8s-master
192.168.18.101 k8s-node1
192.168.18.102 k8s-node2
EOF
2.2.5 时间同步
- kubernetes要求集群中的节点时间必须精确一致,所以在每个节点上添加时间同步:
yum install ntpdate -y
ntpdate time.windows.com
2.2.6 关闭selinux
- 查看selinux是否开启:
getenforce
- 永久关闭selinux,需要重启:
sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config
- 临时关闭selinux,重启之后,无效:
2.2.7 关闭swap分区
- 永久关闭swap分区,需要重启:
sed -ri ‘s/.swap./#&/‘ /etc/fstab
- 临时关闭swap分区,重启之后,无效::
2.2.8 将桥接的IPv4流量传递到iptables的链
在每个节点上将桥接的IPv4流量传递到iptables的链:
cat > /etc/sysctl.d/k8s.conf << EOFnet.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1net.ipv4.ip_forward = 1vm.swappiness = 0EOF# 加载br_netfilter模块modprobe br_netfilter# 查看是否加载lsmod | grep br_netfilter# 生效sysctl --system
2.2.9 开启ipvs
在kubernetes中service有两种代理模型,一种是基于iptables,另一种是基于ipvs的。ipvs的性能要高于iptables的,但是如果要使用它,需要手动载入ipvs模块。
在每个节点安装ipset和ipvsadm:
yum -y install ipset ipvsadm
在所有节点执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF#!/bin/bashmodprobe -- ip_vsmodprobe -- ip_vs_rrmodprobe -- ip_vs_wrrmodprobe -- ip_vs_shmodprobe -- nf_conntrack_ipv4EOF
授权、运行、检查是否加载:
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
检查是否加载:
lsmod | grep -e ipvs -e nf_conntrack_ipv4
2.2.10 重启三台机器
重启三台Linux机器:
2.3 每个节点安装Docker、kubeadm、kubelet和kubectl
2.3.1 安装Docker
安装Docker:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repoyum -y install docker-ce-18.06.3.ce-3.el7systemctl enable docker && systemctl start dockerdocker version
设置Docker镜像加速器:
sudo mkdir -p /etc/dockersudo tee /etc/docker/daemon.json <<-'EOF'{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://du3ia00u.mirror.aliyuncs.com"],"live-restore": true,"log-driver":"json-file","log-opts": {"max-size":"500m", "max-file":"3"},"storage-driver": "overlay2"}EOFsudo systemctl daemon-reloadsudo systemctl restart docker
2.3.2 添加阿里云的YUM软件源
由于kubernetes的镜像源在国外,非常慢,这里切换成国内的阿里云镜像源:
cat > /etc/yum.repos.d/kubernetes.repo << EOF[kubernetes]name=Kubernetesbaseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64enabled=1gpgcheck=0repo_gpgcheck=0gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpgEOF
2.3.3 安装kubeadm、kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
为了实现Docker使用的cgroup drvier和kubelet使用的cgroup drver一致,建议修改”/etc/sysconfig/kubelet”文件的内容:
vim /etc/sysconfig/kubelet# 修改KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"KUBE_PROXY_MODE="ipvs"
设置为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动:
systemctl enable kubelet
2.4 查看k8s所需镜像
查看k8s所需镜像:

2.5 部署k8s的Master节点
部署k8s的Master节点(192.168.18.100):
# 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库地址kubeadm init \--apiserver-advertise-address=192.168.18.100 \--image-repository registry.aliyuncs.com/google_containers \--kubernetes-version v1.18.0 \--service-cidr=10.96.0.0/12 \--pod-network-cidr=10.244.0.0/16


根据提示消息,在Master节点上使用kubectl工具:
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config
2.6 部署k8s的Node节点
根据提示,在192.168.18.101和192.168.18.102上添加如下的命令:
kubeadm join 192.168.18.100:6443 --token jv039y.bh8yetcpo6zeqfyj \--discovery-token-ca-cert-hash sha256:3c81e535fd4f8ff1752617d7a2d56c3b23779cf9545e530828c0ff6b507e0e26

默认的token有效期为24小时,当过期之后,该token就不能用了,这时可以使用如下的命令创建token:
kubeadm token create --print-join-command# 生成一个永不过期的tokenkubeadm token create --ttl 0 --print-join-command
2.7 部署CNI网络插件
根据提示,在Master节点上使用kubectl工具查看节点状态:
kubectl get nodes
- kubernetes支持多种网络插件,比如flannel、calico、canal等,任选一种即可,本次选择flannel,如果网络不行,可以使用本人提供的📎kube-flannel.yml,当然,你也可以安装calico,请点这里📎calico.yaml,推荐安装calico。
下面操作只需要在master节点上执行就可以了,插件使用的是DaemonSet控制器,他会在每个节点上都运行
在Master节点上获取flannel配置文件(可能会失败,如果失败,请下载到本地,然后安装):
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml#当我们使用本地flannel.yml文件的时候 修改文件中的 quay.io仓库为quay-mirror.qiniu.com 这是个国内镜像
使用配置文件启动flannel:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml#如果使用的是下载好的flannel.yml文件,用如下的方式kubectl apply -f /lujing/flannel.yml
查看部署CNI网络插件进度:
kubectl get pods -n kube-system
- 再次在Master节点使用kubectl工具查看节点状态:
kubectl get nodes
- 查看集群健康状况:
kubectl get cs
kubectl cluster-info
3 服务部署
3.1 前言
在Kubernetes集群中部署一个Nginx程序,测试下集群是否正常工作。
3.2 步骤
如下操作都在master节点操作就可以了。
部署Nginx:
kubectl create deployment nginx --image=nginx:1.14-alpine
暴露端口:NodePort的意思就是,可以让集群之外的浏览器可以访问他
kubectl expose deployment nginx --port=80 --type=NodePort
查看服务状态:
kubectl get pods,svc#或者:kubectl get pod #查看podkubectl get svc #查看服务 svc是service的简写,我们可以直接写service也可以
pod是k8s的最小单元,我们的程序在容器里,容器在pod里,下图中30871是暴露给外界的端口号。然后我们用master服务器的ip+这个端口来访问,注意我们不仅master节点可以访问,而是master节点和两个node节点都可以访问


4 kubernetes中kubectl命令自动补全
yum install -y bash-completionsource /usr/share/bash-completion/bash_completionsource <(kubectl completion bash)echo “source <(kubectl completion bash)” >> ~/.bashrcvim /root/.bashrcsource /usr/share/bash-completion/bash_completionsource <(kubectl completion bash)
k8s的资源管理
1 资源管理介绍
在Kubernetes中,所有的内容都抽象为资源(就像java中一切皆对象,k8s中一切皆资源),用户需要通过操作资源来管理Kubernetes。比如pod是资源,pod控制器是资源,service也是资源
- Kubernetes的本质就是一个集群系统,用户可以在集群中部署各种服务。所谓的部署服务,其实就是在Kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中,比如前面我们讲讲nginx跑到了一个容器里边。
- Kubernetes的最小管理单元是Pod而不是容器,所以只能将容器放在Pod中,而Kubernetes一般也不会直接管理Pod,而是通过Pod控制器来管理Pod的。
- Pod提供服务之后,就需要考虑如何访问Pod中的服务,Kubernetes提供了Service资源实现这个功能。
- 当然,如果Pod中程序的数据需要持久化,Kubernetes还提供了各种存储系统。
下图中的 Pod Controller就是pod控制器,当然不止这六种。
上图中 pod Controller就是为了产生各种各样的pod,然后pod里边运行容器,容器里边运行程序,如果程序需要数据持久化,就会用到下边的数据卷,然后如果这个pod想让被外部访问,就要通过service代理,外部访问service就能访问到pod了。
volume下边的就是各种存储系统。
学习kubernets的核心,就是学习如何对集群中的Pod、Pod控制器、Service、存储等各种资源进行操作。
2 YAML语法介绍
2.1 YAML语法介绍
- YAML是一个类似于XML、JSON的标记性语言。它强调的是以“数据”为中心,并不是以标记语言为重点。因而YAML本身的定义比较简单,号称是“一种人性化的数据格式语言”。
```xml
15 beijign
对于xml来说,上述我们写了很多,但是有价值的数据只有15 和beijign两个,其他的都是辅助作用。,并且有浪费空间的闭合标间,所以它是以标记为重点的语言,信息密度低,使用复杂。
同样的如果用yml```yamlheima:age: 15address:beijign#可见他比xml要简洁的多。而且他除了属性名和属性数据外,基本上没有无用的标签在里边。因此它是以数据为中心。
spring boot 就推荐用yml为配置文件。
- YAML的语法比较简单,主要有下面的几个:
- 大小写敏感。
- 使用缩进表示层级关系。
- 缩进不允许使用tab,只允许空格(低版本yaml的限制)。
- 缩进的空格数不重要,只要相同层级的元素左对齐即可。
- ‘#’表示注释。
- YAML支持以下几种数据类型:
- 常量:单个的、不能再分的值,yml中管他叫常量。
- 对象:键值对的集合,又称为映射/哈希/字典。
- 数组:一组按次序排列的值,又称为序列/列表。
我们可以用下边的网站验证我们的yml是否正确,他就是一个yml和json相互转换的网站:
2.2 YAML语法示例
2.2.1 YAML常量
#常量,就是指的是一个简单的值,字符串、布尔值、整数、浮点数、NUll、时间、日期# 布尔类型c1: true# 整型c2: 123456# 浮点类型c3: 3.14# null类型c4: ~ # 使用~表示null# 日期类型c5: 2019-11-11 # 日期类型必须使用ISO 8601格式,即yyyy-MM-dd# 时间类型c6: 2019-11-11T15:02:31+08.00 # 时间类型使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区# 字符串类型c7: haha # 简单写法,直接写值,如果字符串中间有特殊符号,必须使用双引号或单引号包裹c8: line1line2 # 字符串过多的情况可以折成多行,每一行都会转换成一个空格
2.2.2 对象
# 对象# 形式一(推荐):xudaxian:name: 许大仙age: 16# 形式二(了解):xuxian: { name: 许仙, age: 18 }
2.2.3 数组
# 数组# 形式一(推荐):address:- 江苏- 北京# 形式二(了解):address: [江苏,上海]
3 资源管理方式
3.1 资源管理方式
k8s提供了如下三种资源管理的方式:
命令式对象管理:直接使用命令去操作kubernetes的资源,就是把参数和配置写到命令行里边,一起执行。
kubectl run nginx-pod --image=nginx:1.17.1 --port=80#这个命令就是运行一个nginx的pod --image就是指定容器镜像, --port就是指定暴露的端口
命令式对象配置:通过命令配置和配置文件去操作kubernetes的资源。
kubectl create/patch -f nginx-pod.yaml#create/patch 这里就是说明要做一个什么样的事,做这件事需要的参数在nginx-pod.yaml这个文件中。
声明式对象配置:通过apply命令和配置文件去操作kubernetes的资源。
kubectl apply -f nginx-pod.yaml#apply命令只用于创建和更新资源,是无法完全替代第二种方式的。
| 类型 | 操作 | 适用场景 | 优点 | 缺点 | | —- | —- | —- | —- | —- | | 命令式对象管理 | 对象 | 测试 | 简单 | 只能操作活动对象(比如查看),无法审计、跟踪 | | 命令式对象配置 | 文件 | 开发 | 可以审计、跟踪 | 项目大的时候,配置文件多,操作麻烦 | | 声明式对象配置 | 目录 | 开发 | 支持目录操作 | 意外情况下难以调试 |
3.2 命令式对象管理
3.2.1 kubectl命令
- kubectl是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装和部署。
- kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]
- command:指定要对资源执行的操作,比如create、get、delete。
- type:指定资源的类型,比如deployment、pod、service。
- name:指定资源的名称,名称大小写敏感。
- flags:指定额外的可选参数。
一般来说,command和type是必须的,name和flags都是可选的。
- 示例:查看所有的pod
kubectl get pods
- 示例:查看某个pod
kubectl get pod pod_name
- 示例:查看某个pod,以yaml格式展示结果
kubectl get pod pod_name -o yaml
kubectl get pod pod_name -o json #用json的方式展示信息
注意这两种展示方式,会展示出来非常的信息。
- 如果想查看更详细的信息,可以用如下命令:
kubectl get pod pod_name -o wide:
输出如下图所示:
可以看到更多的信息
3.2.2 操作(command)
- kubernetes允许对资源进行多种操作,可以通过—help查看详细的操作命令:
kubectl —help
- 经常使用的操作如下所示:
① 基本命令: | 命令 | 翻译 | 命令作用 | | —- | —- | —- | | create | 创建 | 创建一个资源 | | edit | 编辑 | 编辑一个资源 | | get | 获取 | 获取一个资源 | | patch | 更新 | 更新一个资源 | | delete | 删除 | 删除一个资源 | | explain | 解释 | 展示资源文档 |
② 运行和调试: | 命令 | 翻译 | 命令作用 | | —- | —- | —- | | run | 运行 | 在集群中运行一个指定的镜像 | | expose | 暴露 | 暴露资源为Service | | describe | 描述 | 显示资源内部信息 | | logs | 日志 | 输出容器在Pod中的日志 | | attach | 缠绕 | 进入运行中的容器 | | exec | 执行 | 执行容器中的一个命令 | | cp | 复制 | 在Pod内外复制文件 | | rollout | 首次展示 | 管理资源的发布 | | scale | 规模 | 扩(缩)容Pod的数量 | | autoscale | 自动调整 | 自动调整Pod的数量 |
对于describe命令来说,他可以查看多非常多的资源信息:
以及容器在启动的过程中经历的一个例程,如下图所示。
我们会经常使用describe这个命令查看容器的运行的状态,尤其是容器启动时问题的时候
③ 高级命令: | 命令 | 翻译 | 命令作用 | | —- | —- | —- | | apply | 应用 | 通过文件对资源进行配置 | | label | 标签 | 更新资源上的标签 |
④ 其他命令: | 命令 | 翻译 | 命令作用 | | —- | —- | —- | | cluster-info | 集群信息 | 显示集群信息 | | version | 版本 | 显示当前Client和Server的版本 |
3.2.3 资源类型(type)
- kubernetes中所有的内容都抽象为资源,可以通过下面的命令进行查看:
kubectl api-resources
- 经常使用的资源如下所示:
① 集群级别资源: | 资源名称 | 缩写 | 资源作用 | | —- | —- | —- | | nodes | no | 集群组成部分 | | namespaces | ns | 隔离Pod |
② Pod资源: | 资源名称 | 缩写 | 资源作用 | | —- | —- | —- | | Pods | po | 装载容器 |
③ Pod资源控制器: | 资源名称 | 缩写 | 资源作用 | | —- | —- | —- | | replicationcontrollers | rc | 控制Pod资源 | | replicasets | rs | 控制Pod资源 | | deployments | deploy | 控制Pod资源 | | daemonsets | ds | 控制Pod资源 | | jobs | | 控制Pod资源 | | cronjobs | cj | 控制Pod资源 | | horizontalpodautoscalers | hpa | 控制Pod资源 | | statefulsets | sts | 控制Pod资源 |
④ 服务发现资源: | 资源名称 | 缩写 | 资源作用 | | —- | —- | —- | | services | svc | 统一Pod对外接口 | | ingress | ing | 统一Pod对外接口 |
⑤ 存储资源: | 资源名称 | 缩写 | 资源作用 | | —- | —- | —- | | volumeattachments | | 存储 | | persistentvolumes | pv | 存储 | | persistentvolumeclaims | pvc | 存储 |
⑥ 配置资源: | 资源名称 | 缩写 | 资源作用 | | —- | —- | —- | | configmaps | cm | 配置 | | secrets | | 配置 |
3.2.4 应用示例
- 示例:创建一个namespace
kubectl create namespace dev
#上班的 namespace可以简写为ns
- 示例:获取namespace
kubectl get namespace
kubectl get ns
- 示例:在刚才创建的namespace下创建并运行一个Nginx的Pod
kubectl run nginx —image=nginx:1.17.1 -n dev
# 这里 -n dev就是指定名称空间
- 示例:查看名为dev的namespace下的所有Pod,如果不加-n,默认就是default的namespace
kubectl get pods -n dev
- 示例:删除指定namespace下的指定Pod
kubectl delete pod nginx -n dev
- 示例:删除指定的namespace,这个资源里边的其他资源也会被删除,覆巢之下无完卵

3.3 命令式对象配置
3.3.1 概述
命令式对象配置:通过命令配置和配置文件去操作kubernetes的资源。这里的重点不是编辑yaml文件,而是使用这种方式
3.3.2 应用示例
示例:
- ① 创建一个nginxpod.yaml,内容如下: ```yaml apiVersion: v1 kind: Namespace #类型为名称空间 metadata: name: dev #名称的名称
上边就会创建出来一个 叫做dev的namespace
apiVersion: v1 kind: Pod #类型为pod metadata: name: nginxpod #pod的名字 namespace: dev #所属的名称空间 spec: containers:
name: nginx-containers #pod中容器的名字
image: nginx:1.17.1 #容器的镜像
```
② 执行create命令,创建资源:
kubectl create -f nginxpod.yaml
- ③ 执行get命令,查看资源:
kubectl get -f nginxpod.yaml

注意我们上边的pod加不加s都是一个意思。
- ④ 执行delete命令,删除资源:
kubectl delete -f nginxpod.yaml #这种方式就把这个yaml创建的namespace和pod都删了
3.3.3 总结
命令式对象配置的方式操作资源,可以简单的认为:命令+yaml配置文件(里面是命令需要的各种参数)。
3.4 声明式对象配置
3.4.1 概述
声明式对象配置:通过apply命令和配置文件去操作kubernetes的资源。
- 声明式对象配置和命令式对象配置类似,只不过它只有一个apply命令。
-
3.4.2 应用示例
示例:
kubectl apply -f nginxpod.yaml#首次执行他会创建资源,如果我们再次执行一下:kubectl apply -f nginxpod.yaml#会发现它会提示是否修改了资源

如果我们把nginx的版本调整一下,比如把17.2改成17.1 ,然后再执行这个命令就会发现如下提示:
他提示我们的pod重新配置过了。3.4.3 总结
声明式对象配置就是使用apply描述一个资源的最终状态(在yaml中定义状态)。
使用apply操作资源:
创建和更新资源使用声明式对象配置:kubectl apply -f xxx.yaml。
- 删除资源使用命令式对象配置:kubectl delete -f xxx.yaml。
查询资源使用命令式对象管理:kubectl get(describe) 资源名称。
3.6 扩展:kubectl可以在Node上运行
kubectl的运行需要进行配置,它的配置文件是$HOME/.kube,如果想要在Node节点上运行此命令,需要将Master节点的.kube文件夹复制到Node节点上,即在Master节点上执行下面的操作:
scp -r $HOME/.kube k8s-node1:$HOME
4 如何快速的编写yaml文件
4.1 使用kubectl create命令生成yaml文件
- 此种方式适用于没有真正部署资源。
- 使用kubectl create命令生成yaml文件:
kubectl create deployment nginx —image=nginx:1.17.1 —dry-run=client -n dev -o yaml
- 如果yaml文件太长,可以写入到指定的文件中。
kubectl create deployment nginx —image=nginx:1.17.1 —dry-run=client -n dev -o yaml > test.yaml
4.2 使用kubectl get命令导出yaml文件(此种方式已经不建议使用)
- 此种方式适合于资源已经部署,动态的导出yaml文件。
- 创建一个Deployment:
kubectl create deployment nginx —image=nginx:1.17.1 -n dev
- 使用kubectl get命令导出yaml文件:
kubectl get deployment nginx -n dev -o yaml —export > test2.yaml
此种方式会在未来版本中删除,因此不再建议使用。
5.k8s的实战入门
1 前言
介绍如何在kubernetes集群中部署一个Nginx服务,并且能够对其访问。
2 Namespace
2.1 概述
Namespace是kubernetes系统中一种非常重要的资源,它的主要作用是用来实现多套系统的资源隔离或者多租户的资源隔离。
- 默认情况下,kubernetes集群中的所有Pod都是可以相互访问的。但是在实际中,可能不想让两个Pod之间进行互相的访问,那么此时就可以将两个Pod划分到不同的Namespace下。kubernetes通过将集群内部的资源分配到不同的Namespace中,可以形成逻辑上的“组”,以方便不同的组的资源进行隔离使用和管理。
- 可以通过kubernetes的授权机制,将不同的Namespace交给不同租户进行管理,这样就实现了多租户的资源隔离。此时还能结合kubernetes的资源配额机制,限定不同租户能占用的资源,例如CPU使用量、内存使用量等等,来实现租户可用资源的管理。

- kubernetes在集群启动之后,会默认创建几个namespace。
kubectl get namespace#如下是k8s启动后默认创建的四个namespace#NAME STATUS AGE#default Active 67d 所有未指定namespace的对象都会被分配在default命名空间#kube-node-lease Active 67d 集群节点之间的心跳维护,v1.13开始引入#kube-public Active 67d 这个命名空间下的资源可以被所有人访问(包括未认证用户)#kube-system Active 67d 所有由k8s系统创建的资源都处于这个命名空间

- default:所有未指定的Namespace的对象都会被分配在default命名空间。
- kube-node-lease:集群节点之间的心跳维护,v1.13开始引入。
- kube-public:此命名空间的资源可以被所有人访问(包括未认证用户)。
- kube-system:所有由kubernetes系统创建的资源都处于这个名称空间。 可以通过kubectl get pod -n kube-system来查看
我们k8s本身的组件,也是以pod方式运行的,都在kube-system这个名称空间下。
2.2 应用示例
查看具体命名空间
kubectl get ns defalut
STATUS表示当前名称空间的状态,AGE标识这个名称空间工作了多久了<br />- 可以通过describe命令查看名称空间的详细信息:```shellkubectl describe ns default

注意 STATUS中 active:表示正在运行的名称空间,Terminating标识正在删除的命名空间,这是因为我们当前的命名空间下可能会有很多的资源,我们删除这个名称空间的时候,这些资源也要被删除,删除这些资源肯定是需要时间的。
然后 resource quota表示针对namespace做的资源限制
LimitRange resource表示针对namespace中的每个组件做的资源限制
- 示例:查看指定的命名空间
kubectl get namespace default
kubectl get ns default
- 示例:指定命名空间的输出格式
kubectl get ns default -o wide
kubectl get ns default -o json
kubectl get ns default -o yaml
- 示例:查看命名空间的详情
kubectl describe namespace default
kubectl describe ns default
- 示例:创建命名空间
kubectl create namespace dev
kubectl create ns dev
- 示例:删除命名空间
kubectl delete ns dev
- 示例:命令式对象配置
- ① 新建ns-dev.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: dev
- ② 通过命令式对象配置进行创建和删除:
kubectl create -f ns-dev.yaml
kubectl delete -f ns-dev.yaml
3 Pod
3.1 概述
- Pod是kubernetes集群进行管理的最小单元,程序要运行必须部署在容器中,而容器必须存在于Pod中。
- Pod可以认为是容器的封装,一个Pod中可以存在一个或多个容器。

上图中,最后一个显示Pause的表示的是根容器,然后再往上的 user ContainerN就是表示用户容器
- kubernetes在集群启动之后,集群中的各个组件也是以Pod方式运行的,可以通过下面的命令查看:
kubectl get pods -n kube-system
例如上图中的,kube-apiserver-k8s-master就是我们的访问入口
kube-scheduler-k8s-master就是我们的调度组件,比如把容器安装到哪个节点
kube-controller-manager-k8s-master 应该就是具体执行我们的pod的。
etcd-k8s-master:就是我们存储信息的。
kube-flannel- 是用来管理网络的,他在每个节点都运行了以后,可以看到他后边ds接的应该就是md5
kube-proxy-是做访问代理的,也是每个节点都部署了一个。
3.2 语法及应用示例
语法:创建并运行Pod
kubernetes没有单独运行pod的命令,都是通过pod控制器来实现的。
# 命令格式:kubectl run (Pod控制器的名称) [参数]# --image 指定Pod的镜像# --port 指定端口# --namespace 指定namespace# kubectl run nginx --image=nginx:1.17.1 --port=80 --namespace=dev 这里的run后边的nginx就是pod控制器的名称
示例:在名称为dev的namespace下创建一个Nginx的Pod
kubectl run nginx —image=nginx:1.17.1 —port=80 —namespace=dev
- 语法: 查询所有Pod的基本信息
kubectl get pods [-n 命名空间的名称]
- 示例:查询名称为dev的namespace下的所有Pod的基本信息
kubectl get pods -n dev
- 语法:查看Pod的详细信息
kubectl describe pod pod的名称 [-n 命名空间名称]
- 示例:查看名称为dev的namespace下的Pod的名称为nginx的详细信息
```shell
kubectl describe pods nginx-f89759699-vsx59 -n dev
注意我们这里要指定 -n dev 标识从哪个名称空间查找,否则他会默认去default这个名称
这样可以看到更详细的关于这个pod的信息
这里上边的 nginx-f89759699-vsx59 这个名字不用写全,也可以查询到,他会把所有匹配的pod的详细信息都输出出来。List也就是
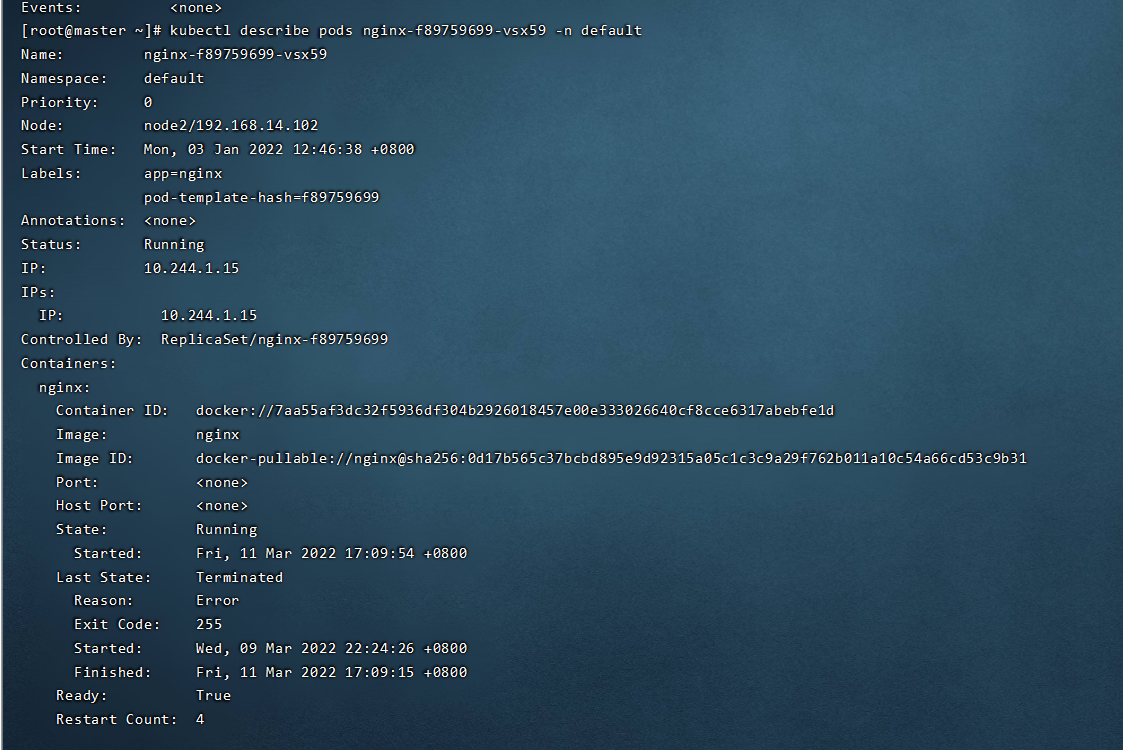<br />describe对于我们来说,最重要的是下边的events这部分,我们经常用这部分的内容来排查容器启动时候的错误,我们可以用 | grep Events:直接抓取这部分内容:<br />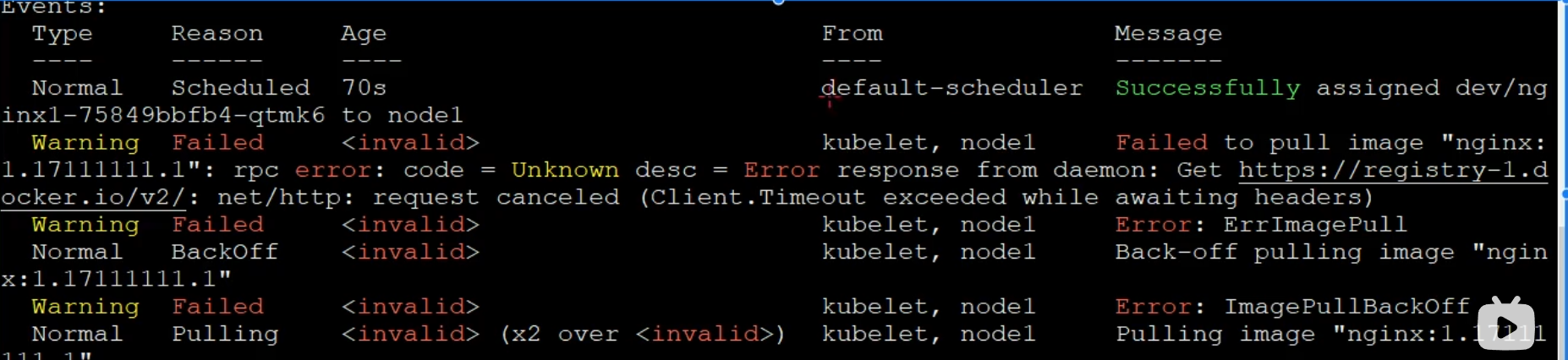- 语法:Pod的访问```shell# 获取Pod的IPkubectl get pods [-n dev] -o wide# 通过curl访问curl ip:端口
示例:访问Nginx的Pod
kubectl get pods -n dev -o widecurl 10.244.2.7:80
下图中,
NAME:标识pod的名称
READ:当前pod里边有几个容器,容器里边有几个正在运行的,根容器不会计算在内。
RESTARS:表示这个pod重启的次数。
AGE:标识pod运行的时间
IP:标识这个pod的IP地址,注意pod的IP地址会随着pod的重新创建而变化,也就是说重启这个pod后,他的IP可能就变了
NODE:表示这个pod被调度到了那个节点上运行了
语法:删除指定的Pod
kubectl delete pod pod的名称 [-n 命名空间]
示例:删除Nginx的Pod
kubectl delete pod nginx -n dev

我们删除了一个pod以后,发现他又自动创建了一个新的pod, 通过 AGE就能看出来,也就是他删除的时候又重新创建了一个。
这是我们的pod控制器在生效。示例:命令式对象配置
- ① 新建pod-nginx.yaml: ```yaml apiVersion: v1 kind: Pod metadata: name: nginx namespace: dev spec: containers:
- image: nginx:1.17.1 imagePullPolicy: IfNotPresent name: pod ports:
name: nginx-port containerPort: 80
protocol: TCP
```
② 执行创建和删除命令:
kubectl create -f pod-nginx.yaml
kubectl delete -f pod-nginx.yaml
4 Label
4.1 概述
- Label是kubernetes的一个重要概念。它的作用就是在资源上添加标识,用来对它们进行区分和选择。
- Label的特点:
- 一个Label会以key/value键值对的形式附加到各种对象上,如添加到Node、Pod、Service等,大多数资源都可以添加标签。
- 一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去。
- Label通常在资源对象定义时确定,当然也可以在对象创建后动态的添加或删除。
- 可以通过Label实现资源的多纬度分组,以便灵活、方便地进行资源分配、调度、配置和部署等管理工作。
- 所谓的标签就是标识选择机制,先添加标签,再根据标签进行选择和区分
一些常用的Label标签示例如下:
- 版本标签:“version”:”release”,”version”:”stable”。。。
- 环境标签:“environment”:”dev”,“environment”:”test”,“environment”:”pro”。。。
- 架构标签:“tier”:”frontend”,”tier”:”backend”。。。
- 标签定义完毕之后,还要考虑到标签的选择,这就要用到Label Selector,即:
- Label用于给某个资源对象定义标识。
- Label Selector用于查询和筛选拥有某些标签的资源对象。
- 当前有两种Label Selector:
- 基于等式的Label Selector。
- name=salve有包含Label中的key=“name”并且value=“slave”的对象(比如上述的 environment:dev 在我们这里就是 environment=dev)。
- env!=production:选择所有包含Label中的key=“env”并且value!=“production”的对象。
- 基于集合的Label Selector。
- name in (master,slave):选择所有包含Label中的key=“name”并且value=“master”或value=“slave”的对象。
- name not in (master,slave):选择所有包含Label中的key=“name”并且value!=“master”和value!=“slave”的对象。
- 基于等式的Label Selector。
标签的选择条件可以使用多个,此时将多个Label Selector进行组合,使用逗号(,)进行分隔即可。
语法:为资源打标签
kubectl label pod xxx key=value [-n 命名空间]#pod是指给pod资源打标签#xxx表示某个pod的名字# key=value就是标签

示例:为Nginx的Pod打上标签
kubectl label pod nginx version=1.0 -n dev
语法:更新资源的标签
kubectl label pod xxx key=value [-n 命名空间] --overwrite#上述--overwrite就是强制覆盖以后标签#由此我们也知道,同一个key的标签只能有一个 比如version=1.0 和version=2.0只能有一个

示例:为Nginx的Pod更新标签
kubectl label pod nginx version=2.0 -n dev —overwrite
- 语法:查看标签
kubectl get pod xxx [-n 命名空间] —show-labels
- 示例:显示Nginx的Pod的标签
kubectl get pod nginx -n dev —show-labels
语法:筛选标签
kubectl get pod -l key=value [-n 命名空间] --show-labels#这里 key=value就是要筛选的标签# -l 就是要筛选的标签#key=value这里,我们还可以写 不等于 key!=value

示例:筛选版本号是2.0的在名称为dev的namespace下的Pod
kubectl get pod -l version=2.0 -n dev —show-labels
- 语法:删除标签
kubectl label pod xxx key- [-n 命名空间]
#注意 key-是连在一起的
- 示例:删除名称为dev的namespace下的Nginx的Pod上的标签
kubectl label pod nginx version- -n dev
添加和筛选标签,是我们平时用的最多的。
- 示例:命令式对象配置
- ① 新建pod-nginx.yaml:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: dev
labels: #此处就是在资源定义的时候,就打上了标签
version: “3.0” #标签的key和value
env: “test”
spec: containers: - image: nginx:1.17.1 imagePullPolicy: IfNotPresent name: pod ports:
name: nginx-port containerPort: 80
protocol: TCP
```
② 执行创建和删除命令:
kubectl create -f pod-nginx.yaml
kubectl delete -f pod-nginx.yaml
5 Deployment(pod控制器)
5.1 概述
- 在kubernetes中,Pod是最小的控制单元,但是kubernetes很少直接控制Pod,一般都是通过Pod控制器来完成的。
- Pod控制器用于Pod的管理,确保Pod资源符合预期的状态,当Pod的资源出现故障的时候,会尝试进行重启或重建Pod。
什么叫符合预期的状态:
比如,我们需要三个部署nginx的pod来支持我们的服务,当运行一段时间后,有一个pod挂了,此时就不符合我们的预期了,这回收pod控制器(Deployment)就会尝试重启这个pod,如果重启失败,就会干掉这个pod来创建一个新的pod,使nginx的pod始终保持三个,让她一直处于符合我们预期的状态。
这也就是为啥之前我们直接删pod是删不掉的。(注意在1.18之前是这样,1.18之后,直接用kubectl run命令创建pod是不会创建deployment的,所以可以删掉的)
- 在kubernetes中Pod控制器的种类有很多,每一种pod控制器都有适合自己的场景,本章节只介绍一种:Deployment。
- 从下图中可以发现,pod和pod控制器是通过标签的方式来联系的,看下图的红字。所以我们创建的pod默认都是带有一个标签的。

5.2 语法及应用示例
#命令格式:kubectl run deployment名称 [参数]# --image 指定pod的镜像# --port 指定端口# --replicas 指定创建pod的数量# --namespace 指定名称空间kubectl run nginx --image=nginx:1.17.1 --port=80 --replicas=3 -n dev#上述中 nginx就是我们要创建的deployment的名字
特别注意:在v1.18版之后,kubectl run nginx —image=nginx —replicas=2 —port=80,会反馈Flag —replicas has been deprecated, has no effect and will be removed in the future,并且只会创建一个Nginx容器实例,不会又deployment。因此这个版本不建议我们这样创建deployment和pod了,建议我们使用下边的deployment的命令创建。
而且上述的这种方式,已经不会创建deployment了,他只会创建一个pod,这样我们这个pod直接删除也会删掉,不会再重新出来一个新的了。
可以看到,我们用上述的命令创建完,是看不到depyment资源的。只有pod
语法:创建指定名称的deployement
kubectl create deployment xxx [-n 命名空间]#注意这个命令是不能直接使用的,必须要跟上 --image这个参数kubectl create deploy xxx [-n 命名空间]#注意这个命令是不能直接使用的,必须要跟上 --image这个参数
示例:在名称为test的命名空间下创建名为nginx的deployment,这里就指定了 image
kubectl create deployment nginx —image=nginx:1.17.1 -n test
- 语法:根据指定的deplyment创建Pod
kubectl scale deployment xxx [—replicas=正整数] [-n 命名空间]
#这里的xxx是我们的deployment 也就是pod控制器的名称
- 示例:在名称为test的命名空间下根据名为nginx的deployment创建4个Pod
kubectl scale deployment nginx —replicas=4 -n dev

上图中我们可以看出来,pod都是以deployment的名字开头的。
- 语法:命令式对象配置
- ① 创建一个deploy-nginx.yaml,内容如下:
```yaml
apiVersion: apps/v1 #版本 这里应该是固定写法
kind: Deployment #类型为Deployment
metadata:
name: nginx #Deployment的名字 namespace: dev #Deployment所属的命名空间 spec: replicas: 3 #创建3个pod selector: #控制器要选择的标签 被控制的pod上就会有这个标签 matchLabels:
run: nginx template: #pod模板 metadata: labels: run: nginx #pod的标签 spec: containers: #pod的相关信息 - image: nginx:1.17.1 name: nginx ports:
containerPort: 80
protocol: TCP
```
② 执行创建和删除命令:
kubectl create -f deploy-nginx.yaml
kubectl delete -f deploy-nginx.yaml
- 语法:查看创建的Pod
kubectl get pods [-n 命名空间]
- 示例:查看名称为dev的namespace下通过deployment创建的3个Pod
kubectl get pods -n dev
- 语法:查看deployment的信息
kubectl get deployment [-n 命名空间]
kubectl get deploy [-n 命名空间]
- 示例:查看名称为dev的namespace下的deployment
kubectl get deployment -n dev
- 语法:查看deployment的详细信息
kubectl describe deployment xxx [-n 命名空间]
kubectl describe deploy xxx [-n 命名空间]
- 示例:查看名为dev的namespace下的名为nginx的deployment的详细信息
kubectl describe deployment nginx -n dev
- 语法:删除deployment
kubectl delete deployment xxx [-n 命名空间]
#注意这个控制器下的pod也会对应着被删除
kubectl delete deploy xxx [-n 命名空间]
- 示例:删除名为dev的namespace下的名为nginx的deployment
kubectl delete deployment nginx -n dev
6 Service
6.1 概述
- 我们已经能够利用Deployment来创建一组Pod来提供具有高可用性的服务,虽然每个Pod都会分配一个单独的Pod的IP地址,但是却存在如下的问题:
- Pod的IP会随着Pod的重建产生变化。
- Pod的IP仅仅是集群内部可见的虚拟的IP,外部无法访问。

- 这样对于访问这个服务带来了难度,因此,kubernetes设计了Service来解决这个问题。
- Service可以看做是一组同类的Pod对外的访问接口,借助Service,应用可以方便的实现服务发现和负载均衡。
- service也是通过标签选择的机制来链接pod
- service在它整个生命周期中IP地址都不会发生变化
- service是通过deploy来寻找pod的

6.2 语法及应用示例
6.2.1 创建集群内部可访问的Service
- 语法:暴露Service
暴露Service
#kubectl expose deployment xxx —name=service的名称 —type=ClusterIP —port=暴露的端口,指定service的端口 —target-port=指向集群中的Pod的端口 [-n 命名空间]
上述命令可以发现,这里是通过指定deployment来创建service的,因为pod都是通过deploy来管理的。所以这样写能更有表达性
#type的类型有很多种,这里用ClusterIP 表示的是集群IP,如果不指定,他默认也是ClusterIP
会产生一个CLUSTER-IP,这个就是service的IP,在Service的生命周期内,这个地址是不会变化的
注意:type= ClusterIP这个类型的IP只能在集群内部访问,就是部署集群的机器上,外部是不能访问的。
- 示例:暴露名为test的namespace下的名为nginx的deployment,并设置服务名为svc-nginx1
kubectl expose deployment nginx —name=svc-nginx1 —type=ClusterIP —port=80 —target-port=80 -n test
- 语法:查看Service
kubectl get service [-n 命名空间] [-o wide]
- 示例:查看名为test的命名空间的所有Service

6.2.2 创建集群外部可访问的Service
- 语法:暴露Service
上述创建的Service是不可以被外部访问的,因为他的type类型为ClusterIP,想让她被外部节点访问,type的类型应改为NodePort
kubectl expose deployment xxx —name=服务名 —type=NodePort —port=暴露的端口 —target-port=指向集群中的Pod的端口 [-n 命名空间]
# 当指定type的类型为NodePort的时候,会产生一个外部也可以访问的Service
- 示例:暴露名为test的namespace下的名为nginx的deployment,并设置服务名为svc-nginx2
kubectl expose deploy nginx —name=svc-nginx2 —type=NodePort —port=80 —target-port=80 -n test
- 语法:查看Service
kubectl get service [-n 命名空间] [-o wide]

注意,我们可以看到PORT的部分不在只有一个80,而是 80:31961 ,这个意思是,当我们通过主机的IP+31961端口进行访问的时候,他就会被转换到 10.100.31.194:80上,也就实现了外部访问service,如下us哦是 192.168.14.100就是主机的IP
- 示例:查看名为test的命名空间的所有Service

6.2.3 删除服务
- 语法:删除服务
kubectl delete service xxx [-n 命名空间]
- 示例:删除服务
kubectl delete service/svc svc-nginx1 -n test
6.2.4 对象配置方式
- 示例:对象配置方式
① 新建svc-nginx.yaml,内容如下:
apiVersion: v1kind: Servicemetadata:name: svc-nginxnamespace: devspec:clusterIP: 10.109.179.231ports:- port: 80protocol: TCPtargetPort: 80selector: #这里是选择的哪个标签run: nginxtype: ClusterIP #这里写上后,上边的clusterIP可写可不写,写就是自己指定IP,不写就是k8s随机一个IP#上述我们也可以指定type的类型为 NodePort,
② 执行创建和删除命令:
kubectl create -f svc-nginx.yaml
kubectl delete -f svc-nginx.yaml
详细介绍Pod资源的各种配置(YAML)和原理。
k8s的Pod详解
1 Pod的介绍
1.1 Pod的结构

- 每个Pod中都包含一个或者多个容器,这些容器可以分为两类:
- ① 用户程序所在的容器,数量可多可少。
② Pause容器,这是每个Pod都会有的一个根容器,它的作用有两个:
下面是Pod的资源清单,也就是pod的yml配置:
- 其实我们通过 kubectl get pod nginx1 -o yaml 这种方式获取到的详细信息,和pod的yaml配置就很相像了

apiVersion: v1 #必选,版本号,例如v1kind: Pod #必选,资源类型,例如 Podmetadata: #必选,元数据name: string #必选,Pod名称namespace: string #Pod所属的命名空间,默认为"default"labels: #自定义标签列表- name: stringspec: #必选,Pod中容器的详细定义,这事最重要的的一个属性,我们可以看到下边所有的配置都是他的containers: #必选,Pod中容器列表- name: string #必选,容器名称image: string #必选,容器的镜像名称imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令args: [string] #容器的启动命令参数列表workingDir: string #容器的工作目录volumeMounts: #挂载到容器内部的存储卷配置- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符readOnly: boolean #是否为只读模式ports: #需要暴露的端口库号列表- name: string #端口的名称containerPort: int #容器需要监听的端口号hostPort: int #容器所在主机需要监听的端口号,默认与Container相同protocol: string #端口协议,支持TCP和UDP,默认TCPenv: #容器运行前需设置的环境变量列表- name: string #环境变量名称value: string #环境变量的值resources: #资源限制和请求的设置limits: #资源限制的设置cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数requests: #资源请求的设置cpu: string #Cpu请求,容器启动的初始可用数量memory: string #内存请求,容器启动的初始可用数量lifecycle: #生命周期钩子postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器exec: #对Pod容器内检查方式设置为exec方式command: [string] #exec方式需要制定的命令或脚本httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、portpath: stringport: numberhost: stringscheme: stringHttpHeaders:- name: stringvalue: stringtcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式port: numberinitialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次successThreshold: 0failureThreshold: 0securityContext:privileged: falserestartPolicy: [Always | Never | OnFailure] #Pod的重启策略nodeName: <string> #设置NodeName表示将该Pod调度到指定到名称的node节点上nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定- name: stringhostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络volumes: #在该pod上定义共享存储卷列表- name: string #共享存储卷名称 (volumes类型有很多种)emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录path: string #Pod所在宿主机的目录,将被用于同期中mount的目录secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部scretname: stringitems:- key: stringpath: stringconfigMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部name: stringitems:- key: stringpath: string
语法:查看每种资源的可配置项
# 查看某种资源可以配置的一级配置,就是yaml文件最外一层的标签,二级资源自然就是yaml的第二级的标签#比如metadata是第一级资源,那么metadata的第二级资源就是metadata.namekubectl explain 资源类型# 查看属性的子属性kubectl explain 资源类型.属性#查看子属性的子属性kubectl explain 资源类型.属性.属性
示例:查看资源类型为pod的可配置项
kubectl explain pod
- 示例:查看资源类型为Pod的metadata的属性的可配置项
kubectl explain pod.metadata
在kubernetes中基本所有资源的一级属性都是一样的,主要包含5个部分:
- apiVersion
:版本,有kubernetes内部定义,版本号必须用kubectl api-versions查询。每个资源都有指定的类型,通过kubectl explain 资源名(比如pod) 就可以查到了 - kind
:类型,有kubernetes内部定义,类型必须用kubectl api-resources查询。 每个资源的名字也是固定的,比如pod,同样可以通过kubectl explain 资源名查看到 - metadata

若有收获,就点个赞吧
0 人点赞
