https://pytorch.org/docs/stable/nn.html
class My_Model(nn.Module):def __init__(self, input_dim):super(My_Model, self).__init__()# 顺序容器,模块将按顺序执行self.layers = nn.Sequential(nn.Linear(input_dim, 16),nn.ReLU(),nn.Linear(16, 8),nn.ReLU(),nn.Linear(8, 1))def forward(self, x):x = self.layers(x)x = x.squeeze(1) # (B, 1) -> (B) 删除所有维度为1的张量return x
Convolution Layers 卷积层
nn.Conv1d:通常用于处理一维数据,如文本
nn.Conv2d:通常用于处理二维数据,如图片
Pooling Layers 池化层
作用:
- 通过池化层可以减少空间信息的大小,提高运算效率
- 减少空间信息意味着减少参数,降低了overfit的风险
- 获得空间变换不变性(translation rotation scale invarance,平移旋转缩放的不变性)
Padding Layers 填充层
顾名思义,填充数据
Non-linear Activations 非线性激活
ReLU
线性整流函数(Linear rectification function),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数
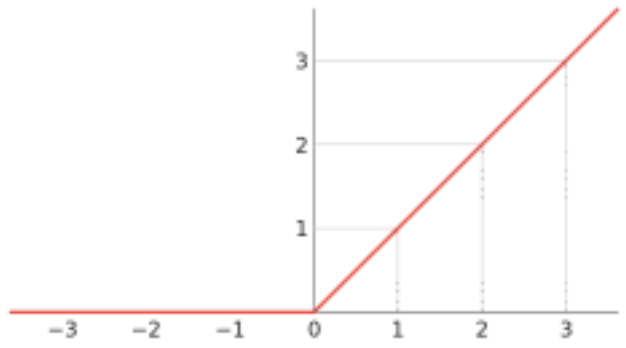
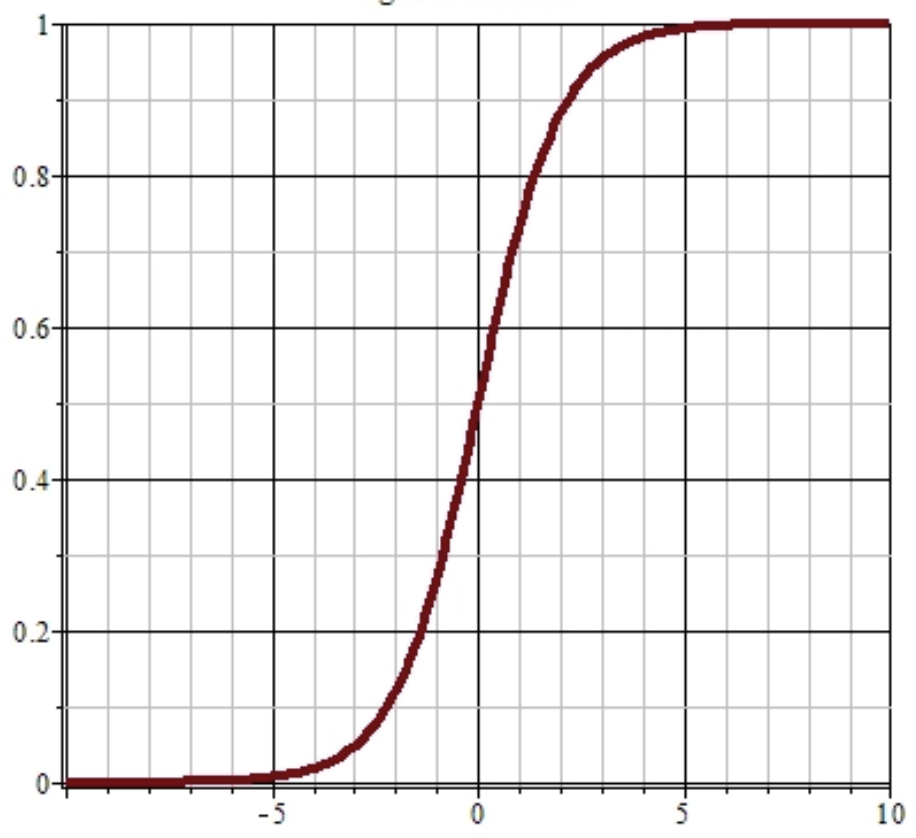
Sigmoid
Sigmoid函数是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的激活函数,将变量映射到0,1之间。
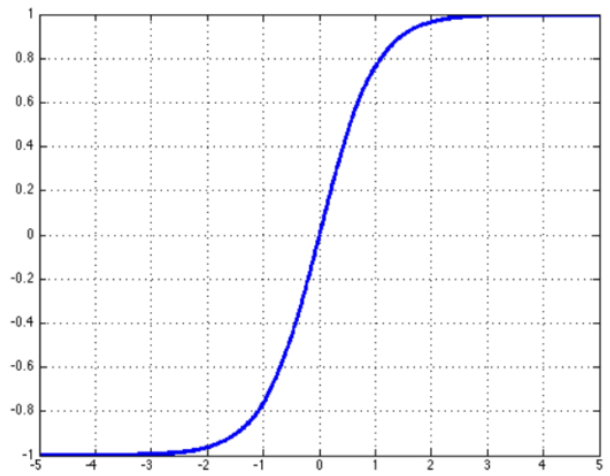
Tanh
tanh是双曲函数中的一个,tanh为双曲正切。在数学中,双曲正切“tanh”是由双曲正弦和双曲余弦这两种基本双曲函数推导而来。
Recurrent Layers 递归/循环层
递归神经网络(RNN)是两种人工神经网络的总称。一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network)
Transformer Layers
Google 2017年的论文《Attention is all you need》提出了Transformer模型,完全基于Attention mechanism,抛弃了传统的RNN和CNN。链接:
https://arxiv.org/abs/1706.03762
Transformer模型使用经典的encoer-decoder架构,由encoder和decoder两部分组成。
Dropout Layers
作用:正则化和防止神经元的互适应(co-adaptation)效应,提升数据间独立性
Sparse Layers 稀疏层
嵌入实现、对稀疏特征进行降维
Distance Functions
CosineSimilarity:余弦相似性
PairwiseDistance:p-范数距离
Loss Functions 损失函数
二分类损失函数
使用场景:当需要得到分类的结果为0/1时
常用函数:
torch.nn.BCELoss()torch.nn.BCEWithLogitsLoss()
多分类损失函数
使用场景:当需要得到分类的结果为多种时,如0-9数字识别
常用函数:
torch.nn.CrossEntropyLoss()torch.nn.L1Loss() # 绝对值torch.nn.MSELoss() # 平方差
Vision Layers 视觉层
Shuffle Layers

若有收获,就点个赞吧
0 人点赞
