Linux三剑客+管道+正则
1、正则表达式
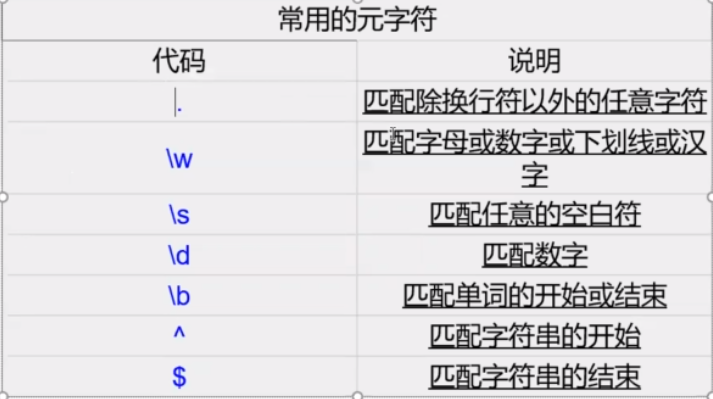
1.1 正则常用元字符
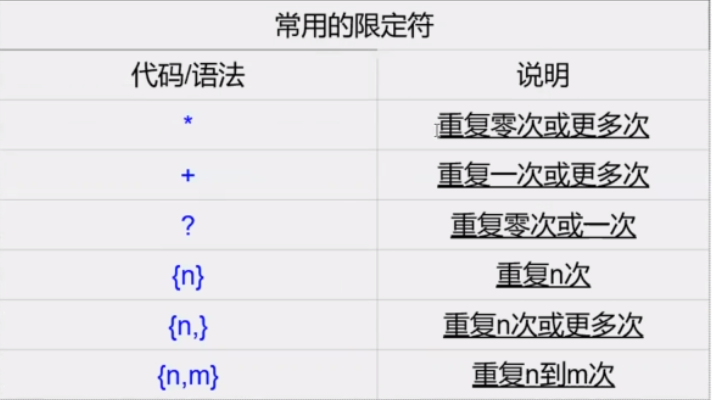
1.2 扩展正则限定符ERE
“A|B” A和B任意匹配一个
ERE 开启方法 加 -E 参数 详细正则查看:
https://www.runoob.com/java/java-regular-expressions.html
2、 | 管道
将不同程序的输入输出进行连接,可以连接多个命令
cat /etc/passwd | grep root
原理:
linux中每个命令的执行都存在输入和输出及错误出口,管道是将事务一的输出作为事务二的输入去进行链式执行。
在管道中使用变量:

在bash中使用变量无法用{},要用()
echo "hello world" | (read x;echo $x;)
3、 grep:获取内容后进行过滤
常用参数:

用法:

# 找出nginx.log中500错误上一行和下两行的数据 -A后面 -B前面less nginx.log | grep -A2 -B1 -E "HTTP/1.1\" 500"
4、 sed:将文本内容进行修改后打印出来,不会修改原文件
sed工作流程: sed为流编辑器,一次只处理一行
(1)、先把一行内容储存储存在模式空间(临时储存空间)当中;
(2)、在利用sed命令去处理模式空间的内容
(3)、处理完后将内容输出到屏幕当中
(4)、将模式空间清空,准备储存下一行内容,再重复步骤1直到内容结束
sed命令解析:


sed常用参数:

sed常用脚本:
sed 's/123/321/g' ~/test # 将所有123替换成321 /g表示将单行内所有匹配到的字符都进行替换,不加只会替换第一个sed -i 's/123/321/g' ~/test # 加了-i参数 会直接修改原文件sed '1,2d' # 删除第1,2行sed -n '3p' test # 打印第3行sed 's/old_regex/new/g' # 将new替换old 参数g会将单行中找到的全部替换sed 's/(regex1 | regex2)(regex3 | regex4)/new_content\1/' # \1表示第一个括号中匹配到的内容
5、awk: 把文件逐行读入,以空白符为默认分隔符将每行切片,切开的部分在进行后续处理
awk工作流程:
(1)、把单行作为输入,将其赋值给$0
(2)、将行切段,默认以空格作为分隔符。切分后的的段落从$1开始
(3)、对行进行正则匹配再执行动作
(4)、将目标内容打印后再重复步骤1直到内容结束**
用法:

常用参数:


字段处理:

单行分割/多行整合处理

awk 'NR==1{for(i=1;i<=NF;i++) print i" = "$i}' nginx.log # 查看各列内容,可以快速找出目的列awk -F $ 以$作为分隔符awk -F $ '/root/{print $0}' # root为想要找到的目标对象正则表达式 print $0可打印匹配上的整行内容awk -F $ 'NR==2{print $0}' # 只打印文本中第二行内容"aaa|bbb ddd|eee ccc ddd|123"|awk 'BEGIN{RS="|"}{print $0}' RS="|" # 以|作为行分隔符;默认为回车\nawk -F : 'BEGIN{print "BEGIN", "BEGIN"}{print $1,$2}' passwd # 在整体操作开始前进行BEGIN所指定的内容,操作用用{}包裹
6、练习题
# 题目1:找出所有404和500的错误日志,统计错误日志的行数awk ' $9~/404|500/{print $9}' niginx.log | wc -l # 对第九列进行匹配,等于400或500的就输出出来,在用wc命令统计行数awk ' $9~/404|500/{t++}END{print t} ' niginx.log # 对第九列进行匹配,匹配到400或500的就让t+1,等匹配完后输出tawk '{print $9}' | grep -E '404|500' | wc -l# 题目2:打印以冒号为分隔符,第6列中不以/home开头,并且不以bash结尾的行的行号awk -F ":" '$6!~/^\/home/&&/bash$/{print NR}' /etc/passwd# 题目3:统计文件行数awk ‘ BEGIN{t=0}{t++}END{print t}’|awk '{t++}END{print t}'# 题目4: 以“文件名,行号,域个数,行内容”格式输出awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd# 题目5: 输出不以a/b/c/d开头的行awk '/^[^a-d]/{print}' passwd# 题目6:找出nginx.log 访问量最高的三个urlawk '{print $7}' nginx.log | sort | uniq -c| sort -nr |head -3# 题目7:找出nginx.log中url以/topic开头的的平均响应时间,倒数第二个字段awk '$7~/^\/topic/{total_time=total_time+$(NF-1);count+=1}END{print total_time/count}' nginx.logless nginx.log | awk '$7=="/topics"{count++;total_time+=$(NF-1)}END{print "avg_time="total_time/count}'# 题目8:统计阿里云盾 AliYunDun 进程的cpu与mem,持续统计20s,每秒输出一下即时的cpu与mem的利用率,并在最后结束时候给出cpu与mem的平均值,输出结果的字段用tab隔开top -b -d1 -n5 | grep --line-buffered ' AliYunDun$'|awk 'BEGIN{OFS="\t";print "perf_avg\ncpu","mem"}{CPU=$(NF-3);MEM=$(NF-2);print CPU,MEM;total_cpu+=CPU;total_mem+=MEM}END{print "\navg:";print total_cpu/NR,total_mem/NR}'# 题目9:统计每个端口对应的网络连接数,以及每个端口的不同状态的数量netstat -tpn | sed 1,2d | awk '{print $4,$6}' | awk -F ":" '{print $2}'| sort | uniq -c | awk 'BEGIN{OFS="\t";print "net_avg"}{print $2,$3,$1}'

若有收获,就点个赞吧
0 人点赞
