1.六层encoder,一层encoder即NX
六层decoder,右侧NX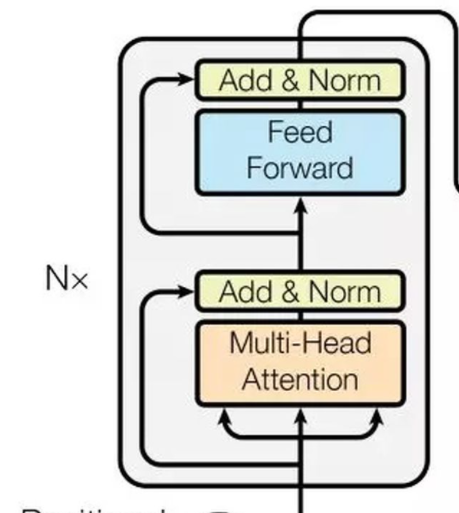
输入序列先经过word embedding 再和positional encoding相加后,输入encoder
输出序列经过处理和输入序列一样,输入decoder中
decoder输出经过一个线性层,再接Softmax
2.Encoder(6)两部分组成,都有一个残差连接residual connection + Layer Normalization
multi-head self-attention
position-wise feed-forward network 全连接层
3.Decoder(6)三部分,残差连接+layer Normalization
multi-head self-attention mechanism
multi-head context-attention mechanism
position-wise feed-forward network
4.Attention :encoder层输出经过加权平均后再输入decoder层
加性Attention, 乘性Attention
输入隐状态,输出隐状态
Self-Attention:输出序列就是输入序列,自己计算自己attention得分
Context-Attention:是两个不同序列之间的attention
一、
Embedding
位置编码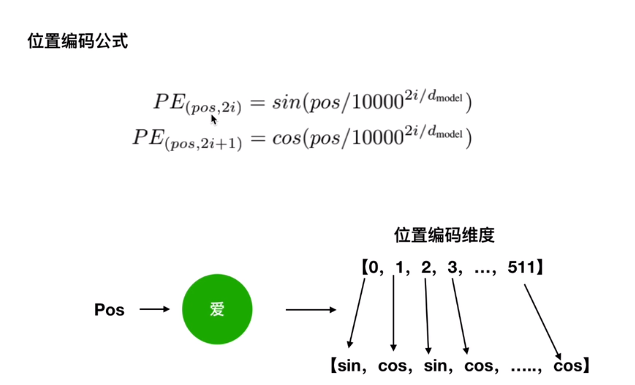
二、注意力机制
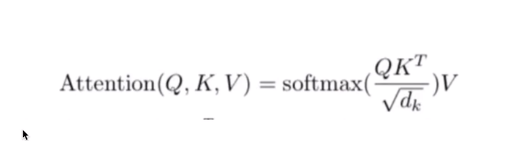
Q,K,V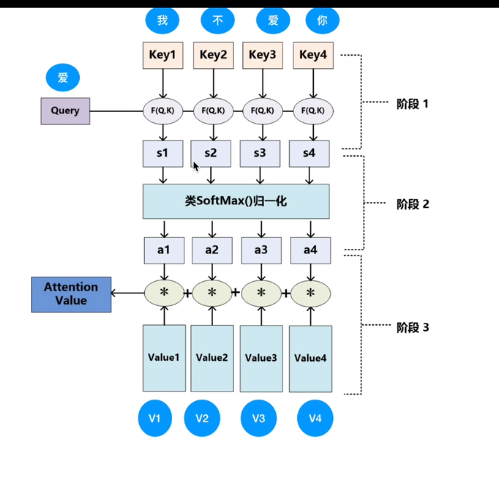
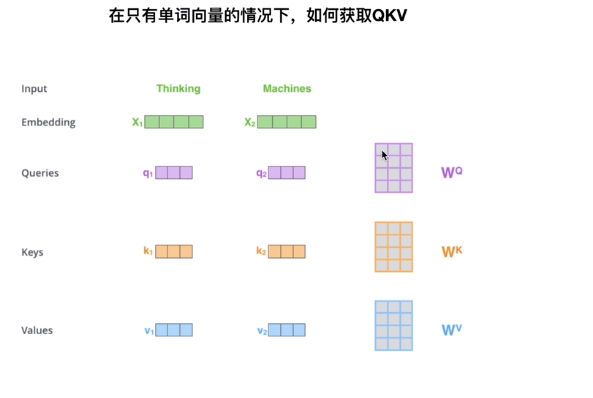
区别
RNN—-针对 N to N 1 to N N to 1,对于N to M无法处理
Seq2Seq Encoder 和Decoder (两者都是RNN),句子太长,翻译精读下降
Attention机制(摆脱输入序列长度限制) :生成单词时有意识的从原始句子中提取生成该单词时最需要的单词
即 Self-Attention,并行计算 生成Transformer
三、LSTM与Transformer区别
LSTM训练是迭代的,一个接一个字来
transformer并行了,就是所有字全部同时训练,加快效率
位置嵌入理解语言顺序,自注意力机制和全连接层,
1.编码器:序列映射成为隐藏层 编码输入并行
2.解码器把隐藏层再映射为自然语言序列 解码输出串行
上游任务(编码任务)
句数 句长 层数 字向量维度
①位置嵌入 :因缺失循环神经网络的迭代操作,需要提供每个字的位置信息来识别语言顺序
方法:使用sin,cos函数线性变换,不同维度产生不同纹理信息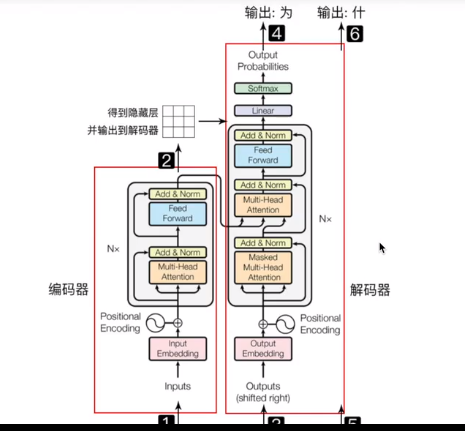
②self attention mechanism Q,K,V
词向量和位置嵌入,
多头注意力机制 嵌入维度整除
注意力矩阵 点积 — 关联性,关联程度 加权 颜色越亮关联度越强
第一行值第一个字与其他所有字的相关性,所有字的信息融入到当前字中
mini batch —-softmax
有效句长区域,无效区域需要masking,避免其干预
③残差连接:避免梯度消失
LayerNorm:隐藏层归一化标准正态分布,加快训练速度,加速收敛



若有收获,就点个赞吧
0 人点赞
