这一系列文章翻译自 Eli Bendersky 的博客,原文地址:https://eli.thegreenplace.net/2020/implementing-raft-part-0-introduction/,翻译已获得原文作者许可,禁止转载和商用
这是介绍 Raft 一致性协议的系列文章的第一篇,完整的目录结构如下:
- Part 0: Introduction (this post)
- Part 1: Elections
- Part 2: Commands and log replication
- Part 3: Persistence and optimizations
虽然 Raft 是一个新推出的算法(2014),但是在业界已经有比较多的应用。最知名的是 k8s,其中的组件 etcd 里的 kv 存储依赖 Raft 进行数据一致性复制。
本文的目的是介绍一个功能完整、测试严格的 Raft 实现(采用 Go 语言),并同时点出一些 Raft 算法如何工作的细节。但是,这篇文章并非完全面向初学者。我假设屏幕前的你至少应该阅读过 Raft 原始论文,并观看过 Raft 作者一到两个演讲视频,动手试玩过 Raft 官网提供的算法动画,甚至浏览过原作者 Ongaro 的博士论文等,有这些基础会让你更容易读懂这一系列文章。
注意,不要期望一天内融会贯通 Raft。虽然 Raft 在设计上确实比 Paxos 更易懂,但它仍比较复杂。因为它所解决的问题——分布式共识协议,本身就是个困难的课题,因此任何解决方案的复杂度肯定有下限,即使算法被精简得足够多,但仍会有很多恼人的细节需要你关注。
Replicated State Machines
分布式共识算法所要解决的问题,是如何在多个 server 之间复制一个状态确定的状态机(deterministic state machine)。术语 “状态机”(state machine)被用来表示一个任意的服务;状态机是计算机科学的基石之一。数据库,文件服务器,锁服务等,这些服务都可以被认为是一个个更复杂的状态机模型。
假设三个蓝点组成的就是代表某个状态机模型的服务。客户端可以连上它们并发送请求、得到响应。

只要运行状态机的机器足够可靠,那这个系统可以一直正常运行下去。但当机器崩溃(crash)时,我们的服务就不可用了,这是不能令人接受的。总结下来,我们的整个系统的可用性跟单个 server 的可用性紧密关联。
提升这种系统可用性的方法很简单,就是复制(replication)。我们可以在多个机器上运行多个服务实例。这种方法构建了一个集群(cluster),它们联合在一起对外提供服务,任何一个机器崩溃时都不应该影响整个集群的可用性。更进一步,通过机器之间的物理隔离,我们也降低了多机同时出现故障的可能性。
这种架构下,与之前客户端连接单个机器不同,现在它是连接整个集群。另外,集群中的副本(replica)也需要相互通信来传递状态/数据信息。三个蓝点组成的状态机可以被认为是运行在一台机器上,那么下图就展示了一个三机集群。
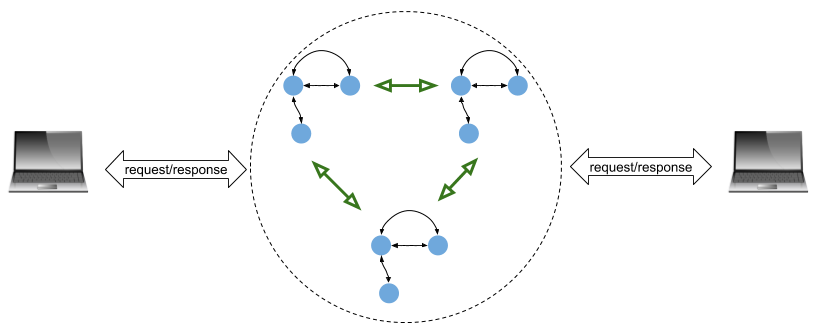
上图中每个状态机都是服务一个副本。理想状态下所有的状态机都按步执行,从客户端接收输入并执行同样的状态变更过程。这保证了即使某些机器异常(fail)的情况下,他们对客户端也返回相同的结果。Raft 就是实现这种机制的一种算法。
现在需要声明一些本文使用的术语及其含义:
- Service:我们实现的分布式系统中运行的逻辑任务。例如,一个 kv 存储系统。
- Server or Replica:一个使用了 Raft 算法的、运行在单独的机器上的、与其他副本或者客户端通过网络连接的实例
- Cluster:多个 Raft server 组合起来实现分布式服务的集合,典型的有三机集群或者五机集群。
Consensus module and Raft log
现在是时候窥探一下上面图中展示的状态机的内部细节了。Raft 作为一种算法,它没有强制规定服务如何去实现一个状态机。它的目的是保证可靠地(reliably)、确定地(deterministically)记录数据流,并向状态机回放(reproduce)数据流(这种数据流在 Raft 中也称为 commands)。考虑到如果给定一个初始化状态和所有的待输入数据集,那就可以实现精确地重建一个状态机。另一种思考这个问题的角度是,如何我们让两个彼此隔离的副本拥有同样的状态机,并给定同样的初始化状态和命令输入顺序,那么两个副本最终会达到相同的终态,在此期间也会一直产生相同的输出。
下面是一个简单的、使用 Raft 算法的服务的内部结构:
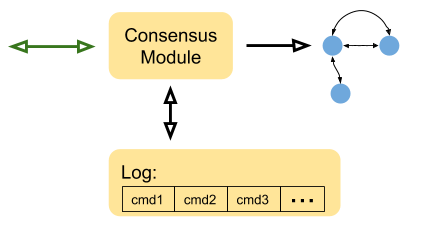
这些组成部分的细节有:
- 状态机(三个小蓝点)与我们上文叙述的一致,它代表了一些抽象的服务;提到 Raft 时 kv 存储往往是最典型的状态机模型。
- Log 是持久化存储所有客户端发送的命令流的地方。这些命令并不会直接被应用(apply)到状态机里;而是,当 Raft 将它们复制到绝大部分(majority)的副本后才会应用到状态机中。另外,Log 是持久化的——它被存储在持久化介质中以此规避机器崩溃的风险,当机器崩溃后 Log 会被用来重建状态机。
- 一致性模块是 Raft 的核心;它从客户端接收命令,保证命令被存储在 Log 中,向集群中其他 Raft 副本复制这些命令(之前的图中的绿色箭头)并当大多数机器复制成功后将命令提交(commit)给状态机。提交给状态机后向客户端返回真实的值变更。
如果读到现在觉得很模糊,不要担心。我们后面的文章会给出更多的细节!
Leaders and Followers
Raft 使用了一个很严格的 leadership 模型,集群中一个 server 是 leader 其他都是 follower。Leader 用来接收客户端的请求,将命令复制给其他 follower 并向客户端返回响应。
通常来说,follower 的作用就是简单的从 leader 接收日志。万一 leader 崩溃或者发生网络分区了,一个 follower 会接管它成为新 leader,整个集群继续保持可用。
这种模型有它的优缺点,很大的优点是简单易懂。数据永远从 leader 流向 follower,并且只有一个 leader 节点接收和响应客户端请求。这点让 Raft 集群易于分析、测试和 debug。一个缺点是性能——由于仅有一个 server 可以跟客户端通信,当客户端请求出现峰值时可能会成为集群瓶颈。这个问题的答案通常来说就是,Raft 不应该被用于 traffic-heavy 类型的服务。它更适合 low-traffic 但一致性要求严格、允许牺牲一些可用性的场景——当讲到容错时我们会再回来讨论这个问题。
Client interaction
当与一个 Raft 集群交互时,客户端知道集群中所有节点的地址,怎么知道的这部分内容不在我们叙述范围内(通过使用一些服务注册发现机制实现)。
客户端最开始随机发送请求到任意一个节点,如果该节点正好是 leader 则它立刻响应请求,客户端等待 leader 处理完成之后返回响应。在此之后,客户端记录下当前的 leader 是哪个地址,并一直向其发生请求直到 leader crash 或者发生其他异常。
如果节点返回称它自己不是 leader,客户端会向其他节点重试,一个可能的优化是该节点如果不是 leader 则直接返回真正 leader 的地址给客户端,那么客户端仅需要两次通信就可以连上真正的 leader,无需反复重试。
另一个客户端可能知晓它正在连接的节点并非 leader 的场景是,它的请求在超时时间(timeout)内未被提交,这可能意味着客户端正在连接的节点并非 leader(即使客户端自认为是)——因为网络分区,这个节点可能跟其他 Raft 集群节点隔离了。当超时之后,客户端会继续寻找不同的节点询问是否是 leader。
第三部分提及的优化点在大多数场景下并非必须,通常来说,在 Raft 环境下我们需要能区分正常请求(normal operation)还是出错状态下的请求(fault scenario)。一个典型的服务在 99.9% 的情况下是正常的,客户端第一次知晓 leader 地址后会缓存记录下 leader 地址。当发生异常状态时,一开始确实会糟糕一些,但这个时间不会持续很久。我们在后续的文章中会讲到,一个 Raft 集群从一个 server 故障或者网络分区中恢复是很迅速的,通常在一秒以内。在新 leader 宣布自己的领导权之前集群会出现一个很短暂的不可用时间,然后客户端会重新回答执行正常请求的状态。
Fault tolerance in Raft and the CAP theorem
让我们回顾下,下面这张三个 Raft 副本的架构图,这时候没有客户端连上集群:
从这个集群中我们能设想哪些异常场景(failure)呢?
组成现代计算机的每个组成部分都可能故障,但是为了理解简便,我们认为一个运行 Raft 的实例机器是一个原子整体。我们从中可以发掘两种主要的异常场景:
- 一个 server crash,意味着一个 server 在一段时间内停止响应任何网络请求,一个 crashed server 可能会被重启或者在一段时间的休息后重新上线。
- 一次网络分区,一个或多个 server 由于网络设备或者传输问题与其他 server 断连。
假设 server A 跟 server B 通信,server B crash 和 AB 之前发生网络分区,对 server A 来说表象是一样的——都表现为 A 无法从 B 接收到任何消息或者响应。从系统层面来看,网络分区往往更加“阴险”,因为它可能会同时影响多个 server。关于网络分区,我们在之后的文章中将会涉及一些更 tricky 的场景。
为了更好地处理网络分区或者 server crash 问题,Raft 要求多数 server 节点(a majority of servers)都能正常运行并正常响应 leader 的请求。如果是一个三机集群,Raft 可以容忍一个 server 发生异常。如果是五机集群,Raft 可以容忍两个 server 异常;以此类推,如果是 2N+1 个机器组成的集群,Raft 最多可以容忍 N 个机器发生异常。
这给我们带来另一个问题——CAP 定理,由于网络分区在分布式环境下通常难以避免,因此我们需要更小心地权衡可用性和一致性。
在这种权衡中毫无疑问,Raft 是坚定保证一致性的,它就是被用来防止集群出现数据不一致的、防止不同客户端收到不一致的响应的。出于这个目的,Raft 设计上牺牲了可用性。
就像我之前简要描述过的,Raft 并不适用于高吞吐量、细粒度的应用。每个客户端请求都会触发背后许多数据操作——与 Raft 副本通信、复制数据、持久化 Log 等,客户端只有等待这些操作全部完成之后才能得到响应结果。
因此你最好不要设计一个多副本数据库,所有客户端都需要通过 Raft 协议才能执行请求,这是不合理的它的性能可能非常差。 Raft 更适合粗粒度的分布式系统设计原语——像是实现一个 lock server,leader 选举协议,在分布式系统中复制配置信息等场景。
Why Go
这一系列文章的 Raft 实现采用了 Go 语言。以我之见,Go 有三个优点让我选择它去实现 Raft:
- 并发:像 Raft 这样的算法会有很多并发编程,每个副本都持续性地处理源源不断的请求,运行定时器、处理时间事件,并需要及时响应其他副本或者客户端的异步请求。我之前已经写过一篇文章叙述:why I consider Go the perfect language for such code。
- 标准库:Go 自身拥有一个强有力、业界成熟的标准库,让用户能无需引入或者学习第三方依赖,就可以简单地写出足够鲁棒的网络服务。特别是对于 Raft,第一个问题就是“如何在副本之间发生消息?”,此时很多人就会陷入协议设计、序列化的泥沼,或者使用依赖庞杂的第三方库。Go 只需要 net/rpc 就足够解决问题,可以非常迅速投入工作,无需其他依赖引入。
- 简单:即使先不考虑究竟选择什么语言,实现分布式共识算法这个过程也非常复杂。可能其他语言也可以将算法实现地非常清晰易懂,但目前来看毫无疑问 Go 是最理想的语言。
What’s next
感谢你阅读到这里!如果觉得我有哪些地方写得不好的话,请直接告诉我。Raft 在概念上可能会让你觉得挺简单,但实际上这是具有迷惑性的,因为只要我们深入代码细节,就会出现很多坑。接下来的文章会提供更多关于算法实现的细节。
现在你可以准备好进入 Part1 了,我们要开始实现 Raft 协议了。

若有收获,就点个赞吧
0 人点赞
