0x00 Imports
1. 当从一个包中引入多个时,用花括号
import com.twitter.concurrent.{Broker, Offer}
2. 当引入超过6个时使,用通配符
import com.twitter.concurrent._
注:不要轻率的使用: 一些包导入了太多的名字
3. 避免不清晰的引入
// 避免import com.twitterimport concurrent// 而应该使用明确的引入import com.twitter.concurrent
0x01 注释
1. 单行注释
// 我是注释内容👨
2. 多行注释
/*** 注释内容😃* ...*/
0x02 数据类型
1. 基本数据类型
| 数据类型 | 描述 |
|---|---|
| Byte | 8bit(1字节)有符号数字,范围在-128 到 127 |
| Short | 16bit(2字节)有符号数字,范围在-32768 到 32767 |
| Int | 32bit(4字节)有符号数字,范围在-2147483648 到 2147483647 |
| Long | 64bit(8字节)有符号数字,范围在-9223372036854775808 到 9223372036854775807 |
| Float | 32bit(4字节),IEEE 754标准的单精度浮点数 |
| Double | 64bit(4字节),IEEE 754标准的双精度浮点数 |
| Char | 16bit Unicode字符,范围在U+0000 到 U+FFFF |
| String | 字符串 |
| Boolean | 布尔类型 |
| Unit | 表示无值,和Java中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成() |
| Null | 空值或空引用,唯一实例是null,AnyRef的子类 |
| Nothing | Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型,表示没有值,没有实例 |
| Option | 表示可能存在(Some),可能不存在(None)的值 |
| None | Option的两个子类之一,用于安全的函数返回值,比Null安全 |
| Some | Option的两个子类之一,表示包装了值 |
| Any | 所有其他类的超类 |
| AnyRef | 所有引用类(reference class)的超类 |
| AnyVal | 所有值类型的超类 |
| Nil | 长度为0的List |
2. 类型层次结构

数据类型关系图
3. 类型转换
值类型可以按照下面的方向进行单向转换:
Demo
val x: Long = 987654321val y: Float = x // 9.8765434E8 (note that some precision is lost in this case)val face: Char = '☺'val number: Int = face // 9786
0x03 变量&常量
1. 声明
声明变量
var myVar : String = "Foo"var myVar : String = "Too"
声明常量(常量的值不可修改,修改常量程序将会在编译时报错)
val myVal : String = "Foo"
2. 类型推断
Scala 编译器通常可以推断出表达式的类型,因此你不必显式地声明它。
如果在没有指明数据类型的情况下声明变量或常量必须要给出其初始值,否则将会报错。
var myVar = 10;val myVal = "Hello, Scala!";
3. 多个变量声明
val x, y = 100 // x, y 都声明为100
0x04 基本语法
1. 图解Scala语法
val name: String = "Scala"println(s"嗨,我是${name},擅长并发和大数据,以语法简洁而著称。")println("""我诞生于2001年,读作:"skah-lah"。我的发明人是 Martin Odersky,他是瑞士洛桑联邦理工大学教授,顶级编程语言学家。 他曾参与设计了一个原型系统GJ, 最终演变为 Java泛型。他还曾受雇于 Sun 公司,编写了 javac 的参考编译器。""")def max(x: Int, y: Int): Int = {if (x > y) { x } else { y }}for(i <- 0 to 10 if i % 2 == 0) { println(i) }val tuple = ("jack", 20)println(s"tuple: ${tuple}, name: ${tuple._1}, age: ${tuple._2}")case class User(name: String, age: Int = 20)val jack = User("jack")val rose = User("rose", 18)println(jack, rose)println(jack.name == "jack", jack == User("jack"))val lambda = (x: Int, y: Int) => { x + y }val strings = List("1", "2", "3", "4", "5")println(strings.map(s => s.toInt).filter(i => i % 2 == 0).mkString(","))val page = 1val users = List(jack, rose)println(users.filter(u => u.age >= 18).sortBy(u => (u.name, u.age)).slice(10*(page -1), 10))val map = Map("jack" -> 20, "rose" -> 18)println(map("jack"))val User(jackName, jackAge) = jackprintln(jackName, jackAge)jack match {case User(name, age) if name == "jack" => println(s"jack matched.")case other => println(s"Hello, ${other.name}")}

0x05 元组
1. 简介
在 Scala 中,元组是一个可以容纳不同类型元素的类,元组是不可变的。
当我们需要从函数返回多个值时,元组会派上用场。
元组的索引从1开始。
2. 定义
val ingredient = ("Sugar" , 25):Tuple2[String, Int]
3. 访问元素
使用下划线语法访问元组, tuple._n 取出了第 n 个元素(假设有足够多元素)。
println(ingredient._1) // Sugarprintln(ingredient._2) // 25
4. 解构元组数据
val ingredient = ("Sugar" , 25):Tuple2[String, Int]val (name, quantity) = ingredientprintln(name) // Sugarprintln(quantity) // 25
5. 元组的应用
在 for 表达式中
val numPairs = List((2, 5), (3, -7), (20, 56))for ((a, b) <- numPairs) {println(a * b)}
拉链操作
var s = Array(73, 65, 88)var n = Array("zhangsan", "lishi", "wangwu")var a = n.zip(s)println(a.mkString("Array(", ", ", ")"))// Array((zhangsan,73), (lishi,65), (wangwu,88))
0x06 数组
1. 声明定长数组
var z:Array[String] = new Array[String](3)// 或var z = new Array[String](3)// 或var z = Array("Runoob", "Baidu", "Google")
2. 声明变长数组(数组缓冲)
import scala.collection.mutable.ArrayBuffervar arr1 = ArrayBuffer[Int]()var arr2 = ArrayBuffer()var arr3 = new ArrayBuffer[Int](1, 2, 3)var arr4 = ArrayBuffer(1, "str")
3. 赋值
z(0) = "Runoob"; z(1) = "Baidu"; z(4/2) = "Google"
4. 遍历数组
方法一
var myList = Array(1.9, 2.9, 3.4, 3.5)// 输出所有数组元素for (x <- myList) {println(x)}
方法二
val arr = ArrayBuffer(1, 2, 3, 4, 5, 6)for (i <- arr.indices) {println(arr(i))}
方法三
val arr = ArrayBuffer(1, 2, 3, 4, 5, 6)for (i <- 0 until arr.length) {println(arr(i))}
5. 数组操作
追加单个元素,使用 +=
val arr = ArrayBuffer[Int]()// 追加单个元素arr += 1// 插入元素arr.insert()
追加多个元素,使用 +=(0,1,2)
// 追加多个arr += (2,3,4,5)
追加数组,使用 ++= Array()
// 追加数组arr ++= Array(6,7,8)
追加变长数组,使用 ++= ArrayBuffer()
// 追加变长数组arr ++= ArrayBuffer(9,10)
插入元素,使用 .insert(index: Int, elem: Int)
val arr = ArrayBuffer[Int]()// 在下标0的位置插入1arr.insert(0, 1)// 在下标1的位置插入1,-1, 0arr.insert(1, 1, -1, 0)
6. 多维数组
定义多维数组
val myMatrix = Array.ofDim[Int](3, 3)
二维数组处理Demo
import Array._object Test {def main(args: Array[String]) {val myMatrix = Array.ofDim[Int](3, 3)// 创建矩阵for (i <- 0 to 2) {for ( j <- 0 to 2) {myMatrix(i)(j) = j;}}// 打印二维阵列for (i <- 0 to 2) {for ( j <- 0 to 2) {print(" " + myMatrix(i)(j));}println();}}}
7. 合并数组
可以使用 concat() 方法来合并两个数组, concat() 方法中接受多个数组参数:
import Array._object Test {def main(args: Array[String]) {var myList1 = Array(1.9, 2.9, 3.4, 3.5)var myList2 = Array(8.9, 7.9, 0.4, 1.5)var myList3 = concat( myList1, myList2)// 输出所有数组元素for ( x <- myList3 ) {println( x )}}}
8. 创建区间数组
使用 range() 方法可以生成一个区间范围内的数组, range() 方法最后一个参数为步长,默认为 1:
// 生成10-20,步长为2的数组var myList1 = range(10, 20, 2)// 10 12 14 16 18// 生成10-20,步长为1的数组var myList2 = range(10, 20)// 10 11 12 13 14 15 16 17 18 19
0x07 集合
1. 集合的类型
Scala 集合类包括可变的和不可变的集合两大类。可变集合类可以修改,添加,移除一个集合的元素。而不可变集合类永远不会改变。不过,仍然可以模拟添加,移除或更新操作。

可变和不可变集合
不可变:
- List
- Set
- Map

可变:_
- scala.collection.mutable__.List
- scala.collection.mutable__.Set
- scala.collection.mutable__.Map
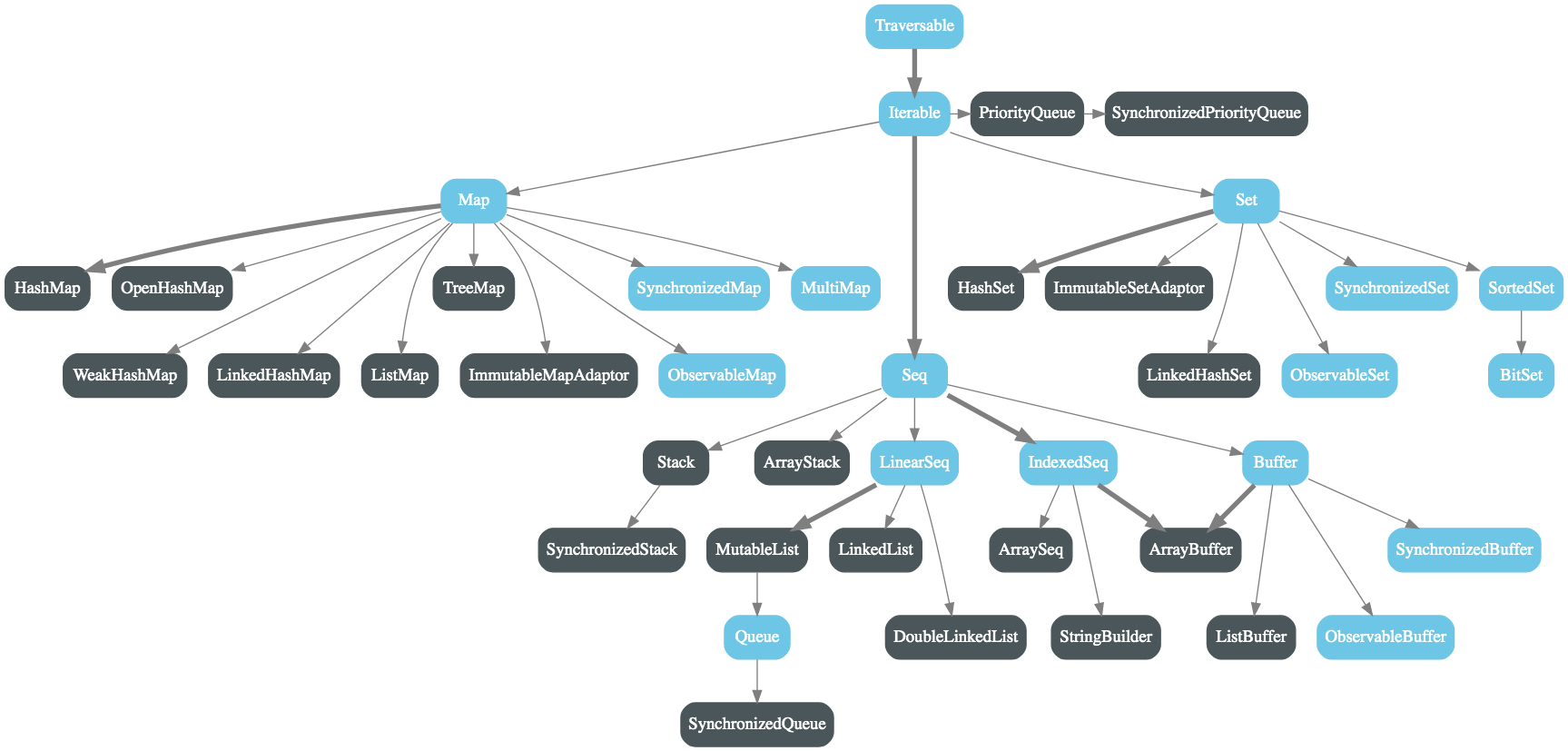
2. List
- 所有的元素类型必须相同
- 长度不可变
- 列表是有序的
- 可以包含重复项 ```scala // 整型列表 val a = List(1, 2, 3, 4) val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
// 字符串列表 val b = List(“a”, “b”, “c”) val site = “Runoob” :: (“Google” :: (“Baidu” :: Nil))
// 二维列表 val d = List(List(1, 2), List(3, 4))
// 空列表 val empty = Nil
- 常用操作| **方法** | **描述** || :---: | :---: || head | 此方法返回列表的第一个元素 || tail | 此方法返回由除第一个之外的所有元素组成的列表 || isEmpty | 如果列表为空,则此方法返回_ true _,否则返回_ false _ || take(n) | 此方法返回前n个元素 || contains(n) | 是否包含n,此方法返回_ true _,否则返回_ false _ |```scalapackage testobject listDemo {def main(args: Array[String]): Unit = {val list: List[String] = List("a", "b" ,"a")//为列表预添加元素println("A" +: list)//在列表开头添加元素println("c" :: list)//在列表开头添加指定列表的元素println(List("d","e") ::: list)//复制添加元素后列表println(list :+ "1")//将列表的所有元素添加到 StringBuilderval sb = new StringBuilder("f")println(list.addString(sb))//指定分隔符println(list.addString(sb,","))//通过列表索引获取元素println(list.apply(0))//检测列表中是否包含指定的元素println(list.contains("a"))//将列表的元素复制到数组中,在给定的数组xs中填充该列表的最多为长度(len)元素,从start位置开始。val a = Array('a', 'b', 'c')val b : Array[Char] = new Array(5)a.copyToArray(b,0,1)b.foreach(println)//去除列表的重复元素,并返回新列表println(list.distinct)//丢弃前n个元素,并返回新列表println(list.drop(1))//丢弃最后n个元素,并返回新列表println(list.dropRight(1))//从左向右丢弃元素,直到条件p不成立println(list.dropWhile(_.equals("a")))//检测列表是否以指定序列结尾println(list.endsWith(Seq("a")))//判断是否相等println(list.head.equals("a"))//判断列表中指定条件的元素是否存在,判断l是否存在某个元素println(list.exists(x=> x == "a"))//输出符号指定条件的所有元素println(list.filter(x=> x.equals("a")))//检测所有元素println(list.forall(x=> x.startsWith("b")))//将函数应用到列表的所有元素list.foreach(println)//获取列表的第一个元素println(list.head)//从指定位置 from 开始查找元素第一次出现的位置println(list.indexOf("b",0))//返回所有元素,除了最后一个println(list.init)//计算多个集合的交集println(list.intersect(Seq("a","b")))//检测列表是否为空println(list.isEmpty)//创建一个新的迭代器来迭代元素val it = list.iteratorwhile (it.hasNext){println(it.next())}//返回最后一个元素println(list.last)//在指定的位置 end 开始查找元素最后出现的位置println(list.lastIndexOf("b",1))//返回列表长度println(list.length)//通过给定的方法将所有元素重新计算list.map(x=> x+"jason").foreach(println)//查找最大元素println(list.max)//查找最小元素println(list.min)//列表所有元素作为字符串显示println(list.mkString)//使用分隔符将列表所有元素作为字符串显示println(list.mkString(","))//列表反转println(list.reverse)//列表排序println(list.sorted)//检测列表在指定位置是否包含指定序列println(list.startsWith(Seq("a"),1))//计算集合元素之和,这个地方必须是int类型,如果是string直接报错//println(list.sum)//返回所有元素,除了第一个println(list.tail)//提取列表的前n个元素println(list.take(2))//提取列表的后n个元素println(list.takeRight(1))//列表转换为数组println(list.toArray)//返回缓冲区,包含了列表的所有元素println(list.toBuffer)//List 转换为 Mapval arr = Array(("jason", 24), ("jim", 25))arr.toMap.foreach(println)//List 转换为 Seqprintln(list.toSeq)//List 转换为 Setprintln(list.toSet)//列表转换为字符串println(list.toString())}}
3. Set
- 所有元素都是唯一的
- 集合无序
常用方法 | 方法 | 描述 | | :—-: | :—-: | | head | 此方法返回Set的第一个元素 | | tail | 此方法返回由除第一个之外的所有元素组成的列表 | | isEmpty | 如果列表为空,则此方法返回 true ,否则返回 false | | take(n) | 此方法返回前n个元素 | | contains(n) | 是否包含n,此方法返回 true ,否则返回 false |
基本操作 ```scala import scala.collection.mutable
// 可变 Set val mutableSet = mutable.SetInt
// 添加元素 mutableSet.add(1) mutableSet.add(2) mutableSet.add(3)
// 移除元素 mutableSet.remove(2)
// 调用 mkString 方法 输出1,3 println(mutableSet.mkString(“,”))
- 拼接集合可以使用 ++ 运算符或 Set.++() 方法连接两个或多个集合,但是在添加集合时,它将删除重复的元素。```scalaobject Demo {def main(args: Array[String]) {val fruit1 = Set("apples", "oranges", "pears")val fruit2 = Set("mangoes", "banana")// use two or more sets with ++ as operatorvar fruit = fruit1 ++ fruit2println( "fruit1 ++ fruit2 : " + fruit )// use two sets with ++ as methodfruit = fruit1.++(fruit2)println( "fruit1.++(fruit2) : " + fruit )}}/* 运行结果:fruit1 ++ fruit2 : Set(banana, apples, mangoes, pears, oranges)fruit1.++(fruit2) : Set(banana, apples, mangoes, pears, oranges)*/
- 集合中查找最大值,最小元素
可以使用 Set.min 方法和 Set.max 方法来分别找出集合中元素的最大值和最小值
object Demo {def main(args: Array[String]) {val num = Set(5,6,9,20,30,45)// find min and max of the elementsprintln( "Min element in Set(5,6,9,20,30,45) : " + num.min )println( "Max element in Set(5,6,9,20,30,45) : " + num.max )}}/* 运行结果:Min element in Set(5,6,9,20,30,45) : 5Max element in Set(5,6,9,20,30,45) : 45*/
- 查找交集值
可以使用 Set.& 或 Set.intersect 方法来查找两个集合之间的交集(相交值)
object Demo {def main(args: Array[String]) {val num1 = Set(5,6,9,20,30,45)val num2 = Set(50,60,9,20,35,55)// find common elements between two setsprintln( "num1.&(num2) : " + num1.&(num2) )println( "num1.intersect(num2) : " + num1.intersect(num2) )}}/* 运行结果num1.&(num2) : Set(20, 9)num1.intersect(num2) : Set(20, 9)*/
4. Map
- 键值对
- 键唯一,值不唯一
- 所有的值都可以通过键来获取
- 常用操作 | 方法 | 描述 | | :—-: | :—-: | | keys | 返回 Map 所有的键(key) | | values | 返回 Map 所有的值(value) | | isEmpty | 如果Map为空,则此方法返回 true ,否则返回 false |
// Map 键值对演示val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF")// 初始化一个空 mapval scores01 = new HashMap[String, Int]// 从指定的值初始化 Map(方式一)val scores02 = Map("hadoop" -> 10, "spark" -> 20, "storm" -> 30)// 从指定的值初始化 Map(方式二)val scores03 = Map(("hadoop", 10), ("spark", 20), ("storm", 30))// 使用可变Mapimport scala.collection.mutableval scores04 = mutable.Map("hadoop" -> 10, "spark" -> 20, "storm" -> 30)//判断Map是否为空colors.isEmpty//返回 Map 所有的键(key)colors.keys//返回 Map 所有的值(value)colors.values// 获取指定 key 对应的值println(scores("hadoop"))// 如果对应的值不存在则使用默认值println(scores.getOrElse("hadoop01", 100))val scores = scala.collection.mutable.Map("hadoop" -> 10, "spark" -> 20, "storm" -> 30)// 如果 key 存在则更新scores("hadoop") = 100// 如果 key 不存在则新增scores("flink") = 40// 可以通过 += 来进行多个更新或新增操作scores += ("spark" -> 200, "hive" -> 50)// 可以通过 -= 来移除某个键和值scores -= "storm"// 由不可变Map产生新Mapval scores = Map("hadoop" -> 10, "spark" -> 20, "storm" -> 30)val newScores = scores + ("spark" -> 200, "hive" -> 50)
- 遍历Map ```scala val scores = Map(“hadoop” -> 10, “spark” -> 20, “storm” -> 30)
// 1. 遍历键 for (key <- scores.keys) { println(key) }
// 2. 遍历值 for (value <- scores.values) { println(value) }
// 3. 遍历键值对 for ((key, value) <- scores) { println(key + “:” + value) }
<a name="3NZMI"></a>### 5. 使用可变集合```scalaimport scala.collection.mutable// 定义可变集合val set = mutable.Set()val set = mutable.Map()
0x08 字符串操作
1. 常用操作
//字符串去重"aabbcc".distinct // "abc"//取前n个字符,如果n大于字符串长度返回原字符串"abcd".take(10) // "abcd"//字符串排序"bcad".sorted // "abcd"//过滤特定字符"bcad".filter(_ != 'a') // "bcd"//类型转换"true".toBoolean"123".toInt"123.0".toDouble
2. 原生字符串
//包含换行的字符串val s1= """Welcome here.Type "HELP" for help!"""//包含正则表达式的字符串val regex = """\d+"""
3. 字符串插值
val name = "world"val msg = s"hello, ${name}" // hello, world
0x09 函数
1. 函数声明
声明方式
def functionName ([list of parameters]) : [return type]
Demo ```scala // 规范化写法 def addInt(a:Int, b:Int) : Int = { var total : Int = a + b return total }
// Unit,是Scala语言中数据类型的一种,表示无值,用作不返回任何结果的方法 def returnUnit(): Unit = { println(“哈哈哈!”) }
// 不写明返回值的类型,程序会自行判断,最后一行代码的执行结果为返回值 def addInt(a:Int, b:Int) = { a+b }
// 省略返回值类型和等于号,返回的是() def addInt(a:Int, b:Int) { a+b }
// 函数只有一行的写法 def addInt (a:Int, b:Int) = x + y
// 最简单写法:def ,{ },返回值都可以省略,此方法在spark编程中经常使用 val addInt = (x: Int, y: Int) => x + y
<a name="ckmiM"></a>### 2. 函数定义```scaladef functionName ([参数列表]) : [return type] = {function bodyreturn [expr]}
- 返回类型可以是任何有效的Scala数据类型
- 参数列表将是由逗号分隔的变量列表
- 参数列表和返回类型是可选的
-
3. 函数调用
基本调用方式
functionName( list of parameters )
对象的实例调用函数
[instance.]functionName( list of parameters )
函数不带参数,可以不写括号 ```scala scala> def three() = 1 + 2 three: ()Int
scala> three() res2: Int = 3
scala> three res3: Int = 3
<a name="49QGj"></a>### 4. 部分应用- 可以使用下划线“_”部分应用一个函数,结果将得到另一个函数```scalascala> def adder(m: Int, n: Int) = m + nadder: (m: Int, n: Int)Intscala> val add2 = adder(2, _:Int)add2: (Int) => Int = <function1>scala> add2(3)res50: Int = 5
可以部分应用参数列表中的任意参数,而不仅仅是最后一个
5. 柯里化函数
有时会有这样的需求:允许别人一会在你的函数上应用一些参数,然后又应用另外的一些参数。
例如一个乘法函数,在一个场景需要选择乘数,而另一个场景需要选择被乘数。
scala> def multiply(m: Int)(n: Int): Int = m * nmultiply: (m: Int)(n: Int)Int
你可以直接传入两个参数
scala> multiply(2)(3)res0: Int = 6
你可以填上第一个参数并且部分应用第二个参数
scala> val timesTwo = multiply(2) _timesTwo: (Int) => Int = <function1>scala> timesTwo(3)res1: Int = 6
你可以对任何多参数函数执行柯里化,例如之前的 adder 函数
scala> (adder _).curriedres1: (Int) => (Int) => Int = <function1>
6. 可变长度参数
这是一个特殊的语法,可以向方法传入任意多个同类型的参数。例如要在多个字符串上执行String的 capitalize 函数,可以这样写:
def capitalizeAll(args: String*) = {args.map { arg =>arg.capitalize}}capitalizeAll("rarity", "applejack")// ArrayBuffer(Rarity, Applejack)
0x10 类和对象
1. 简介
- 类是对象的抽象,而对象是类的具体实例。
- 类是抽象的,不占用内存,而对象是具体的,占用存储空间。
类是用于创建对象的蓝图,它是一个定义包括在特定类型的对象中的方法和变量的软件模板。
2. 声明类
class Point(xc: Int, yc: Int) {var x: Int = xcvar y: Int = ycdef move(dx: Int, dy: Int) {x = x + dxy = y + dyprintln ("x 的坐标点: " + x);println ("y 的坐标点: " + y);}}
3. 实例化类
可以使用 new 来实例化类,并访问类中的方法和变量 ```scala object Test { def main(args: Array[String]) {
val pt = new Point(10, 20);// 移到一个新的位置pt.move(10, 10);
} }
/ x 的坐标点: 20 y 的坐标点: 30 /
<a name="T9Cb9"></a>### 4. 继承- 重写一个非抽象方法必须使用 override 修饰符。- 只有主构造函数才可以往基类的构造函数里写参数。- 在子类中重写超类的抽象方法时,你不需要使用 override 关键字。```scalaclass Point(xc: Int, yc: Int) {var x: Int = xcvar y: Int = ycdef move(dx: Int, dy: Int) {x = x + dxy = y + dyprintln ("x 的坐标点: " + x);println ("y 的坐标点: " + y);}}class Location(override val xc: Int, override val yc: Int, val zc :Int) extends Point(xc, yc){var z: Int = zcdef move(dx: Int, dy: Int, dz: Int) {x = x + dxy = y + dyz = z + dzprintln ("x 的坐标点 : " + x);println ("y 的坐标点 : " + y);println ("z 的坐标点 : " + z);}}
Scala 使用 extends 关键字来继承一个类,实例中 Location 类继承了 Point 类。 Point 称为父类(基类), Location 称为子类。 override val xc 为重写了父类的字段。 继承会继承父类的所有属性和方法,Scala 只允许继承一个父类。
5. 重写
class Person {var name = ""override def toString = getClass.getName + "[name=" + name + "]"}class Employee extends Person {var salary = 0.0override def toString = super.toString + "[salary=" + salary + "]"}object Test extends App {val fred = new Employeefred.name = "Fred"fred.salary = 50000println(fred)}
6. 私有成员
成员默认是公有(public)的。使用 private 访问修饰符可以在类外部隐藏它们。
class Point {private var _x = 0private var _y = 0private val bound = 100def x = _xdef x_= (newValue: Int): Unit = {if (newValue < bound) _x = newValue else printWarning}def y = _ydef y_= (newValue: Int): Unit = {if (newValue < bound) _y = newValue else printWarning}private def printWarning = println("WARNING: Out of bounds")}val point1 = new Pointpoint1.x = 99point1.y = 101 // prints the warning
在这个版本的Point类中,数据存在私有变量x和_y中。def x和def y方法用于访问私有数据。def x=和def y=是为了验证和给_x和_y赋值。注意下对于setter方法的特殊语法:这个方法在getter方法的后面加上=,后面跟着参数。
主构造方法中带有 val 和 var 的参数是公有的,然而由于 val 是不可变的,所以不能像下面这样去使用。
class Point(val x: Int, val y: Int)val point = new Point(1, 2)point.x = 3 // <-- does not compile
不带 val 或 var 的参数是私有的,仅在类中可见。
class Point(x: Int, y: Int)val point = new Point(1, 2)point.x // <-- does not compile

若有收获,就点个赞吧
0 人点赞
