页面相应太慢容易导致响应超时,404,断开的管道等各种问题。
总结项目中几个接口优化的方案:
1.并行操作。
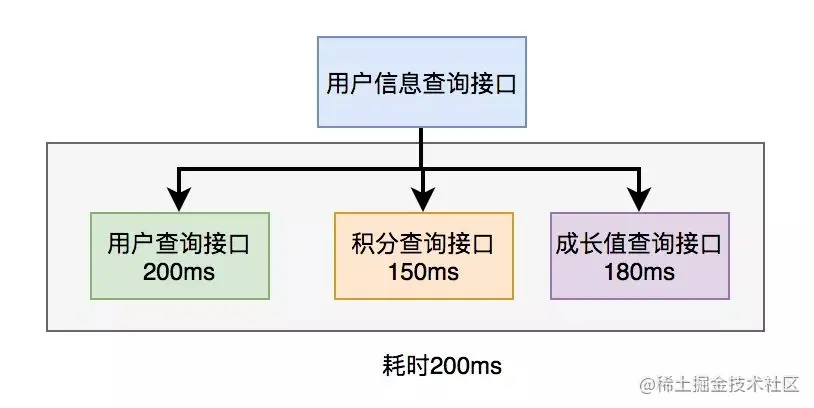
循环使用CompletableFuture多线程调用方法体,等待全部完成后进行接下来的操作,会将串行变并行运行,查询效率提高。
CompletableFuture.supplyAsync(() ->{
方法体
});
List<CompletableFuture<WordResult>> futures = new ArrayList<>();for (int i = 0; i < firstElementlist.size(); i++) {String elementId = firstElementlist.get(i).getTempletKey();futures.add(CompletableFuture.supplyAsync(() -> {WordResult wordResulTOne = selectWordElement(taskNo, templetKeyId, elementId);return wordResulTOne;}));}//等待全部完成CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()])).join();
2.另起线程操作
对可以不用实时相应的数据查询,另起线程进行操作。
比如:批量提交、批量导入万级以上的数据等等。
try {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {//批量插入数据batchAdd();}});thread.start();} catch (Exception e) {log.info("批量提交失败!{}", e.getMessage());}
3.将单次操作改成批量操作
如果有循环100次,那么就会远程调用数据库100次,是非常耗时的操作。所以需要批量查一次,就能查出所有的结果,减少远程调用的次数。如果数据量很大,需要分批次操作数据库,建议每次查询量不超过500次。
1.将循环中单个查询改成批量查询
首先查出所有的数据list集合,在根据java8的stream流的方法对某个字段进行分组,转换成map的形式,之后对map进行操作。
//批量查询出所有的数据List<InstitutionRiskCollection> scoreList = selectByScoreItemList(idList,taskNo);//将list转换成map的形式Map<String, List<InstitutionRiskCollection>> elementRisksMap = new HashMap<>();if (CollUtil.isNotEmpty(elementRisks)) {elementRisksMap = scoreList.stream().collect(Collectors.groupingBy(InstitutionRiskCollection::getElementId));}
mapper.java
List<InstitutionRiskCollection> selectByScoreItemList(@Param("scoreItemKeyList") List<String> scoreItemKeyList, String taskNo);
mapper.xml
<select id="selectByScoreItemListAndTaskNo" resultMap="BaseResultMap">select<include refid="Base_Column_List"/>from INSTITUTION_RISK_COLLECTIONwhereTASK_NO = #{taskNo,jdbcType=VARCHAR}<if test="scoreItemKeyList != null and scoreItemKeyList.size > 0">ANDSCORE_ITEM IN<foreach collection="scoreItemKeyList" index="index" item="index"open="(" separator="," close=")">#{index,jdbcType=VARCHAR}</foreach></if></select>
2.批量插入
mapper.java
int batchAdd(List<InstitutionRiskResult> list);
mapper.xml
<insert id="batchAdd" parameterType="java.util.List">INSERT INTO INSTITUTION_RISK_RESULT( RISK_RESULT_KEY,INSTITUTION_RISK_KEY,TEMPLET_ID, RISK_SCORE, MEASURES_SCORE,RISK_LEVEL,MEASURES_LEVEL,SURPLUS_LEVELKEY,MESSAGE)VALUES<foreach collection="list" item="item" separator=",">(#{item.riskResultKey},#{item.institutionRiskKey},#{item.templetId},#{item.riskScore},#{item.measuresScore},#{item.riskLevel},#{item.measuresLevel},#{item.surplusLevelKey},#{item.message})</foreach></insert>
3.批量更新
mapper.java
int batchUpdate(@Param("riskScoreList") List<InherentRiskScore> riskScoreList);
mapper.xml
<update id="batchUpdate"><foreach collection="riskScoreList" item="index" index="index" open="" close="" separator=";">UPDATE INHERENT_RISK_SCORESET TOTAL_SCORE=#{index.totalScore,jdbcType=VARCHAR}WHERE INHERENT_SCORE_ID= #{index.inherentScoreId,jdbcType=VARCHAR}</foreach></update>
ps:批量更新操作有两种方法,1.循环update语句2.case when
1.循环update效率要比case when效率高一些。如果数据量很大的话,还是建议分批更新
4.异步处理
比如有个用户请求接口中,需要做业务操作,发站内通知,和记录操作日志。为了实现起来比较方便,通常我们会将这些逻辑放在接口中同步执行,势必会对接口性能造成一定的影响。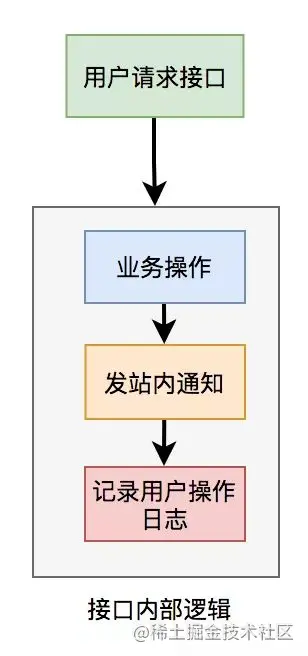
这个接口表面上看起来没有问题,但如果你仔细梳理一下业务逻辑,会发现只有业务操作才是核心逻辑,其他的功能都是非核心逻辑。
ps:
在这里有个原则就是:核心逻辑可以同步执行,同步写库。非核心逻辑,可以异步执行,异步写库。

若有收获,就点个赞吧
0 人点赞
