一、前言

多链接实验参考:https://www.volcengine.com/docs/6287/65808
二、遇到的场景
1、不同广告落地页,对比各广告落地页转化率,希望找出优胜的广告落地页
2、不同内容页,H5活动页,对比各活动页面的转化率,希望找出最优的内容页
3、不同注册流程页,对比不同流程带来的转化率,希望找出最优的注册流程页
三、主要内容
1、AB一些专有名词介绍(二)
2、多链接实验原理
3、设置实验版本
4、URL的匹配规则
四、专有名词介绍(二)
1、指标类别:
- 事件指标:主要是通过事件触发方式的统计计算分析,选择事件支持事件属性和公共属性筛选。支持单一指标和组合指标。
- 留存指标:主要是根据起始事件和回访事件来确定圈选的人群来进行统计计算分析用户的留存情况,选择的事件支持事件属性和公共属性筛选。
- 技术指标:技术指标涉及移动端、Web端、小程序端,需要分别接入对应的SDK才能使用。也就是默认内置的指标,目前支持的是应用性能监控的技术指标。
2、指标类型:
只有事件指标支持指标类型
- 单一指标:指的是单一事件
- 组合指标:多个单一事件的组合,新增指标关系,指标关系允许事件编号大写字母、输入括号()、加号+、减号-、乘号*、除号/;计算公式可任意组合,仅支持一层括号的计算。
3、实验策略:参数,参数类型,参数值。开启一个实验的时候,通过「参数」随机下发,用户进组,然后通过「参数值」随机下发到对照组和实验组中。「参数类型」支持参数值可以是多种类型的数据类型,灵活运用。
4、假设检验: 假设检验是用来判断样本与样本,样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。其基本原理是先对总体的特征作出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受作出推断
5、显著性水平: 是假设检验中的一个概念,是指当原假设为正确时人们却把它拒绝了的概率或风险。它是公认的小概率事件的概率值,必须在每一次统计检验之前确定,通常取α=0.05或α=0.01。这表明,当作出接受原假设的决定时,其正确的可能性(概率)为95%或99%
五、多链接实验原理
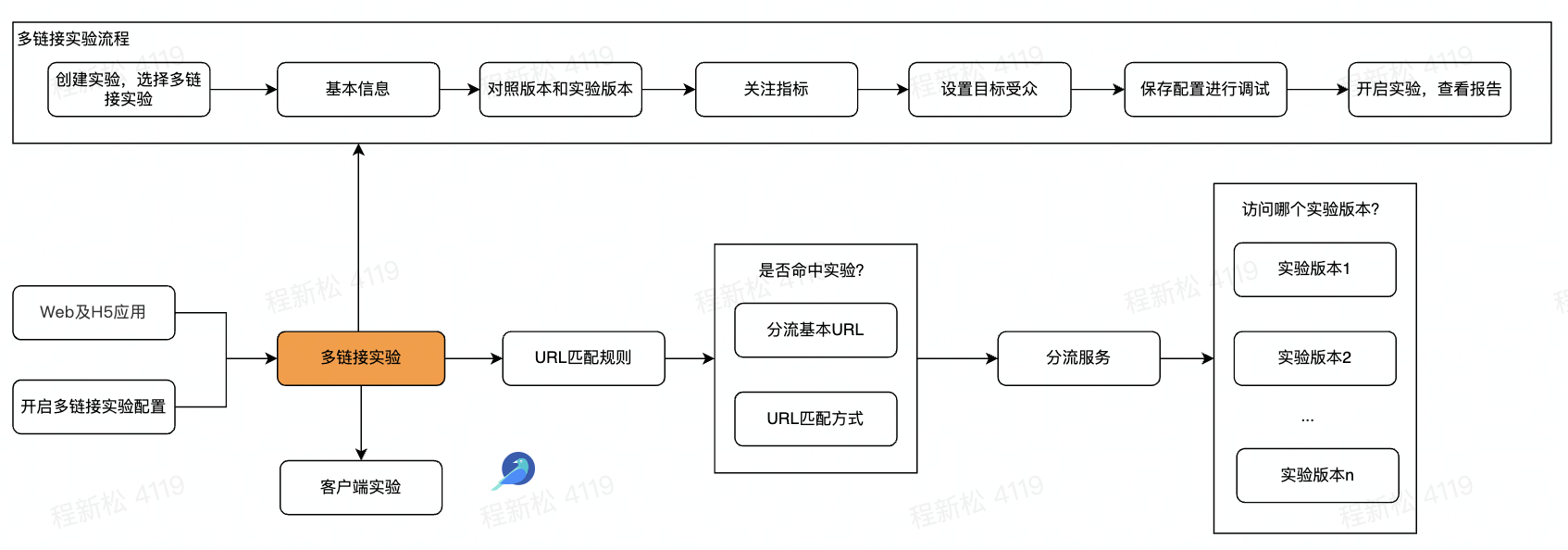
六、设置实验版本
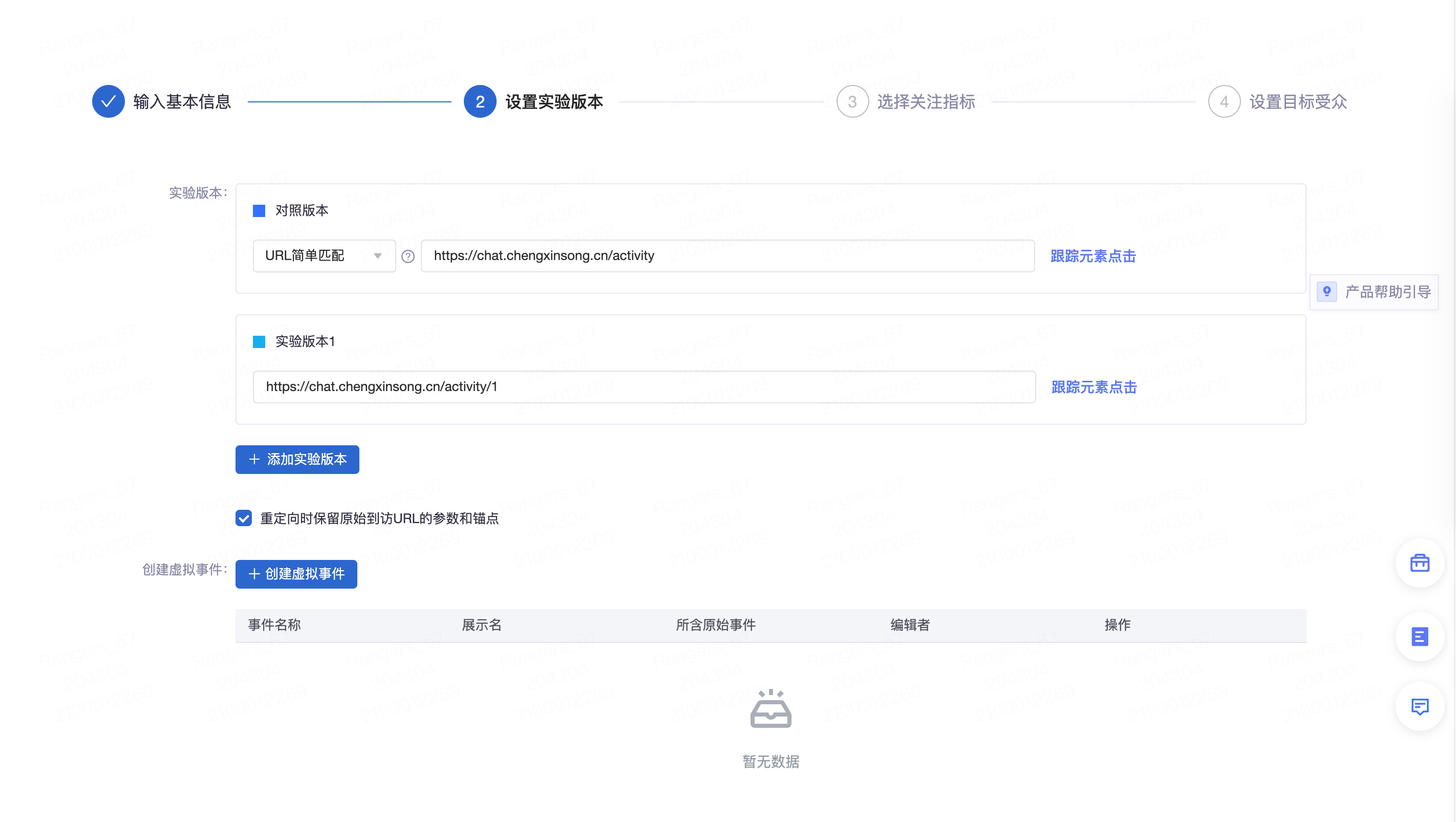
在多链接实验中,只需要根据实际场景配置对照版本及实验版本的url即可,其中 对照版本是分流的基本url, 此处填写的url及url匹配方式是决定用户访问的页面是否可以命中实验的依据,命中实验后会访问到哪个版本是分流服务决定的。
七、URL的匹配规则
1、重定向时保留原始到访URL的参数和锚点
用户到访地址url中的参数及锚点将会保留并与用户最终实际命中的版本中url的参数和锚点合并,若参数值有冲突则会以填写的url中的参数值及锚点值为准。
2、简单匹配
在url进行匹配时,简单匹配会忽略url中的查询参数和锚点,在用户访问页面的url域名和路径匹配的情况即可命中实验。
- 简单匹配会忽略网址中的以下部分:
- 查询参数
- 哈希或锚标记
- url中是否存在www
- url简单匹配会对比以下部分:
- 子域名
- 子目录
- 文件扩展名(.html,.php等)
举个🌰【对照版本不带参+实验版本带参】:对照版本按照「普通匹配」方式匹配http://app.test.com,实验版本URL为http://miniapp.test.com/path1?param1=redirect#frag1,则具体的匹配和重定向情况如下: 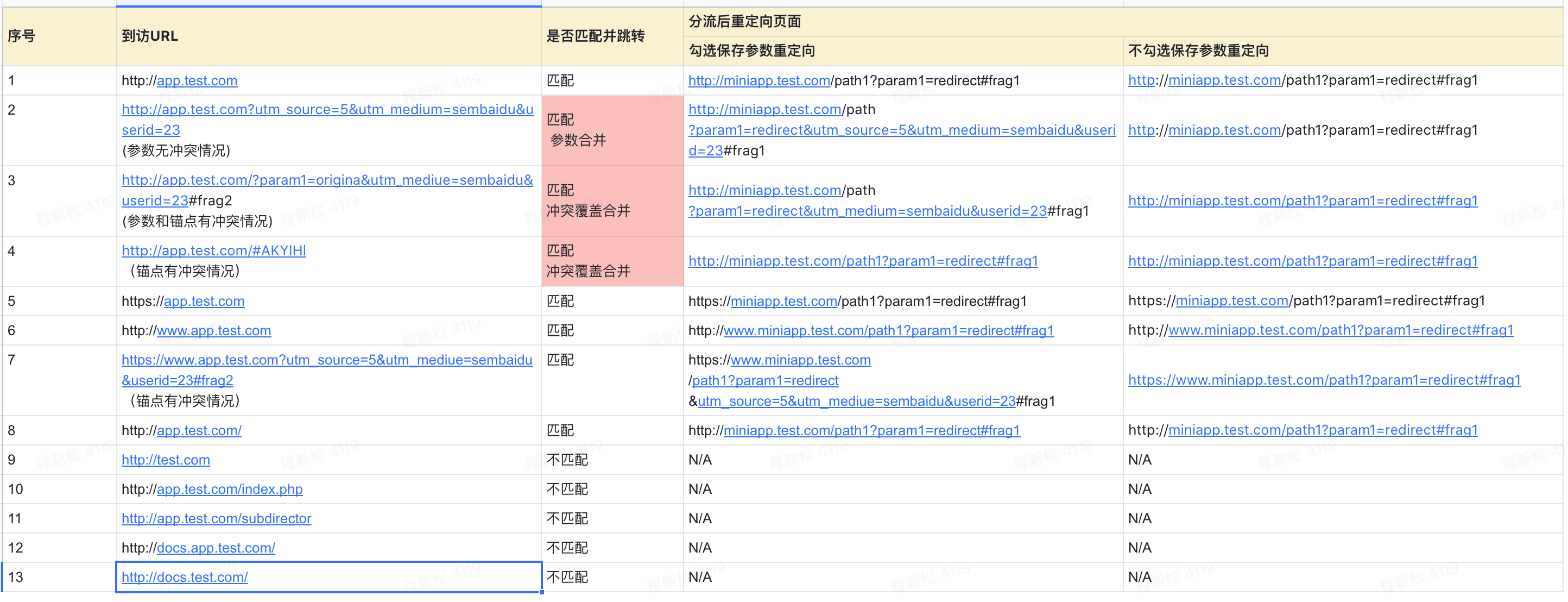
举第二个🌰【对照版本带参+实验版本不带参】:对照版本按照「普通匹配」方式匹配http://miniapp.test.com/path1?param1=redirect#frag1,实验版本URL为http://app.test.com。因「普通匹配」会忽略URL的参数及锚点,所以在匹配逻辑上,对照版本的URL与设置为http://miniapp.test.com/path1相同,后面的参数及锚点会影响跳转的锚点参数。则具体的匹配和重定向情况如下: 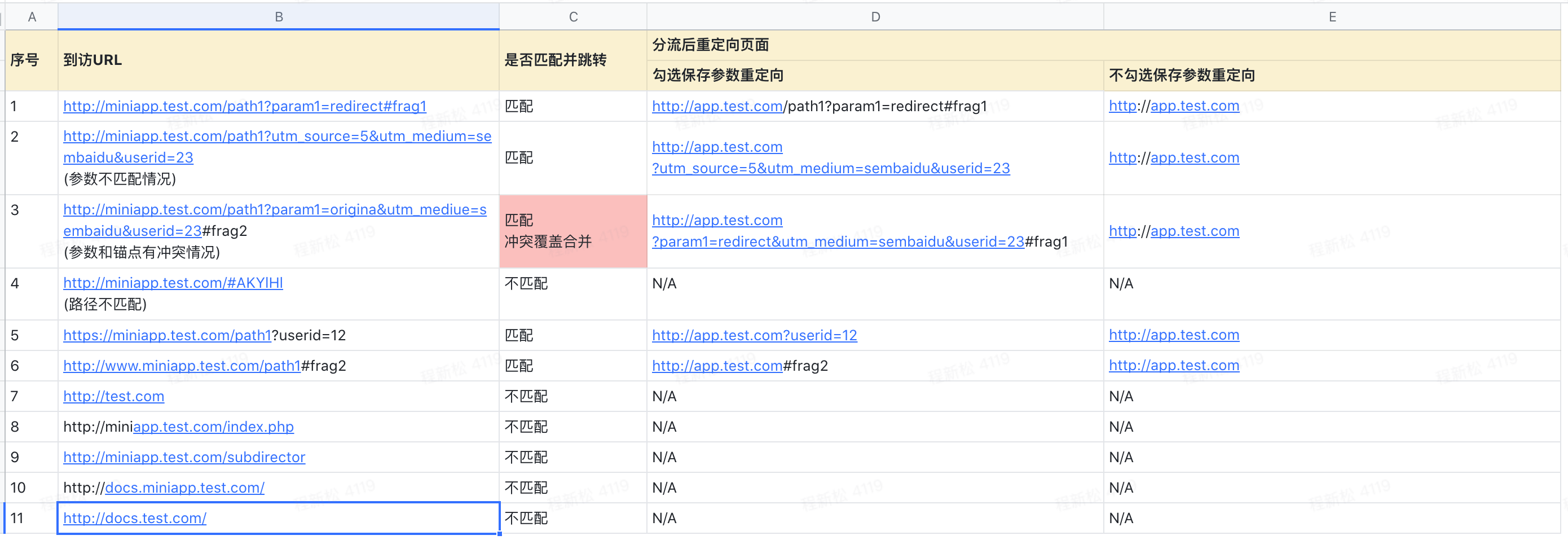
3、精准匹配
url精准匹配,即完全匹配,不会忽略网址的任何部分,且只有在完全匹配网址后,实验才会运行。当您需要排除带有参数的页面时,可使用「精准匹配」。完全匹配,不会忽略网址的任何部分。 只有在完全匹配网址后,实验才会运行。在这种情况下,勾选项「拆分测试时保存动态查询参数进行重定向」无效。当用户需要排除具有特定查询或主题标签(锚标签)的页面时,可使用「精准匹配」。
举个🌰,对照版本按照「精准匹配」方式匹配http://app.test.com/promo,实验版本URL为http://miniapp.test.com/promo,则具体的匹配和重定向情况如下: 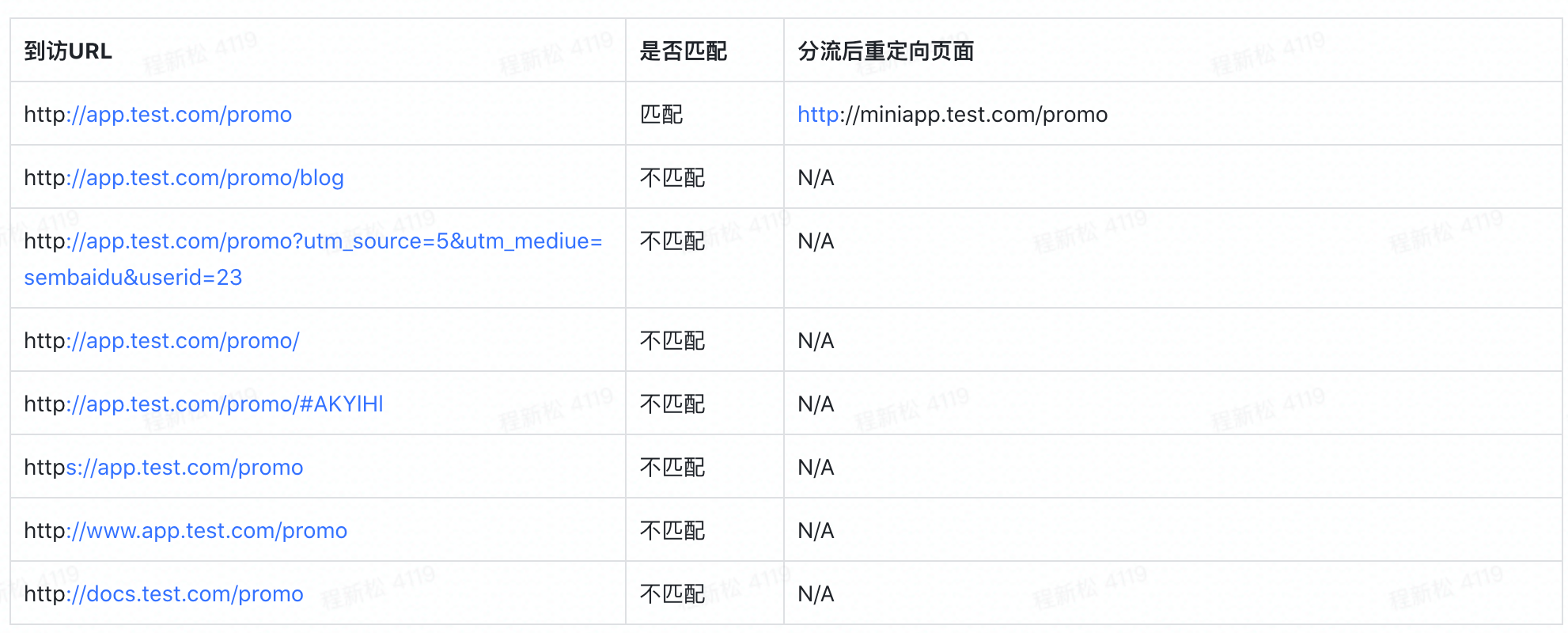
八、如何解读实验报告
产生一组数据很容易,但是从数据中分析得到实验的洞察(Insight)并不简单。
说到实验结果是否显著,我们需要知道统计学中2类统计错误,我们简单说明一下,这里我们不展开说。
1、基础知识
(0)两类统计学错误
在统计学的世界里,我们往往只说概率,不说确定,在现实世界中往往只能基于样本进行推断。在AB实验中,我们 不知道真实情况是什么,因此做假设检验的时候就会犯错误,这种错误可以划分为两类:
- 这是第一类错误:实际没有区别,但实验结果表示有区别,我们得到显著结果因此否定原假设,认为实验组更优,发生的概率用 𝛂 表示。
- 这是第二类错误:实际有区别,但是实际结果表示没有区别,我们得到不显著的结果因此无法拒绝原假设,认为实验组和对照组没有区别,发生的概率用 𝜷 表示。
理想状态下当然是希望可以同时控制这两类错误,但是这是不可能的,两个概率值之间是负向关系,其中一个值的减少必然伴随着另一个值的增大,为什么呢?后续有机会再分享。
2、结果是否可信
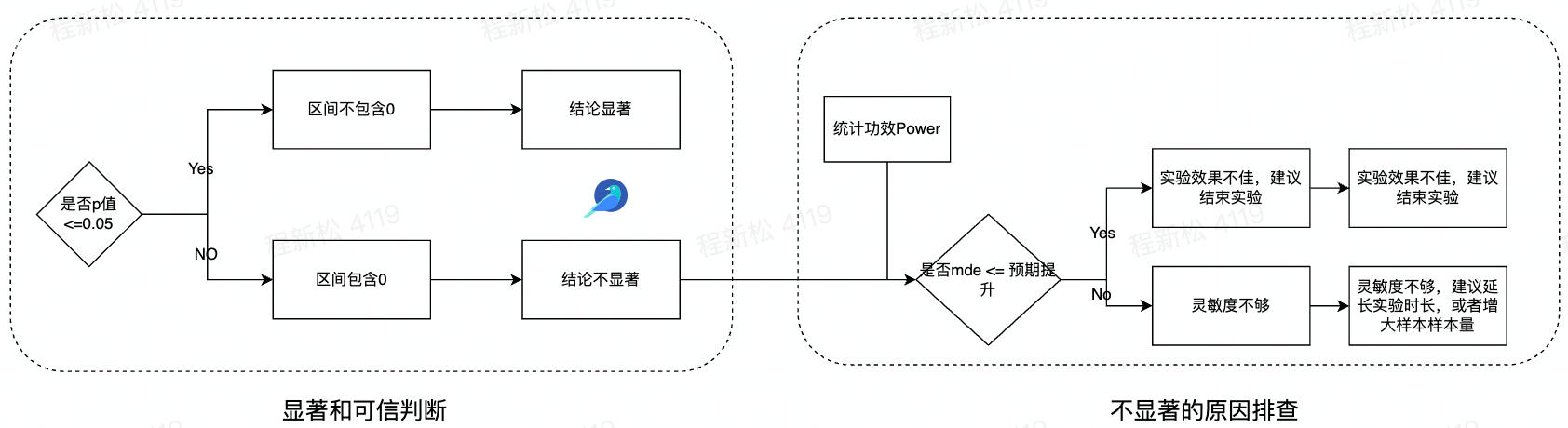
是否显著,是否可信,我们可以通过以下几种因素来判断:
(1)p值。展示该指标在实验中犯第一类错误的概率,该概率小于显著性水平 α ,统计学中称为显著,1-α 为置信度或置信水平。
通常情况下:
p值 > α(显著水平α,α 值一般5%) ,说明A版本和B版本没有太大差别,不存在显著性差异。
p值 < α(显著水平,α 值一般5%),说明A版本和B版本有很大的差别,存在显著性差异。
我们根据判断 p 值和第一类错误概率 α 比较,已经做了决策。是不是觉得大功告成,不,我们可以继续考虑power统计功效来衡量实验的可信。也就是我们要同时考虑第二类错误概率,这时候引入power统计功效。
(2)power统计功效(1 - 𝜷)。实验能正确做出存在差异判断的概率。
- 可以理解为有多少的把握认为版本之间有差别。
- 该值越大则表示概率越大、功效越充分。
- 一般来说,我们一般并设置的最低的统计功效值为80%以上。认为这样的可信度是可以接受的。
举个例子🌰:
实验A显示,power(统计功效)为92%,那么就可以理解为有92%的把握认为版本A和版本B之间是有差别的。
但是power根本算不出来,power作为需要满足的前提条件,作为先验的输入值。
- 实验开启前,通过流量计算器中计算流量和实验运行时长。
- 实验开启后,通过power=80%,然后计算MDE。
(3)MDE检验灵敏度,能有效检验出指标置信度的diff幅度。
通过比较指标MDE与指标的目标提升率来判断不显著的结论是否solid,可以避免实验在灵敏度不足的情况下被过早作出非显著结论而结束,错失有潜力的feature。
MDE 越小,说明当前的实验灵敏度越高,并且可以认为:实验组相比于对照组,只有高于 MDE 的提升才能大概率检测出效果显著。小于 MDE 的提升,大概率不会被检测出显著。
- 当前条件:指当前样本量,指标值和指标分布情况,并假设样本方差与总体指标方差足够接近。
- 有效检测:指检出概率大于等于80%(也就是犯第二类错误概率 𝜷 <=20%)
- 主要影响因素:样本量大小
举个例子🌰
假设你对该指标的预期目标提升率为1%。
- 如果此时MDE=0.5%,MDE < 预期提升值,说明指标变化真的不显著,请结合业务ROI和其他维度里例如用户体验、长期战略价值等来综合判断是否值得上线;
- 如果那此时MDE=2%,MDE > 预期提升值,说明当前能检验出显著性的最小差异值是2%,由于灵敏度不足未能检测出。这种情况下建议增大样本量,例如扩大流量、再观察一段时间积累更多进组用户,指标还有置信的可能。
(4)置信区间。置信区间就是用来对一个概率样本的总体参数的进行区间估计的样本均值范围。一般来说,我们使用 95% 的置信水平来进行区间估计。
置信区间可以辅助确定版本间是否有存在显著差异的可能性:
- 如果置信区间上下限的值同为正或负,认为存在有显著差异的可能性;
- 如果同时正负值,那么则认为不存在有显著差异的可能性。
详细视图中有个值叫相对差,该值就是指标变化的点估计值,而置信区间给出的是指标预期变化的区间估计值,区间估计值有更大的可能性覆盖到指标相对变化的真实值。(假设做100次实验,有95次算出的置信区间包含了真实值)。
- 可以这样简单但不严谨地解读置信区间:假设策略全量上线,你有95%的把握会看到真实的指标收益在置信区间这个范围内。
九、QA
1、ssid,user_unique_id,webid的区别?
- SDK的init初始化的时候,user_unique_id 与 web_id 相等的,ssid是根据user_unique_id等hash操作生成。
当用户调用config方法的时候,可能会修改ssid,这时候user_unique_id 与 web_id 不想等,判断后端表中是否有该user_unique_id对应的ssid(也就是该user_unique_id是否调用了config方法)?
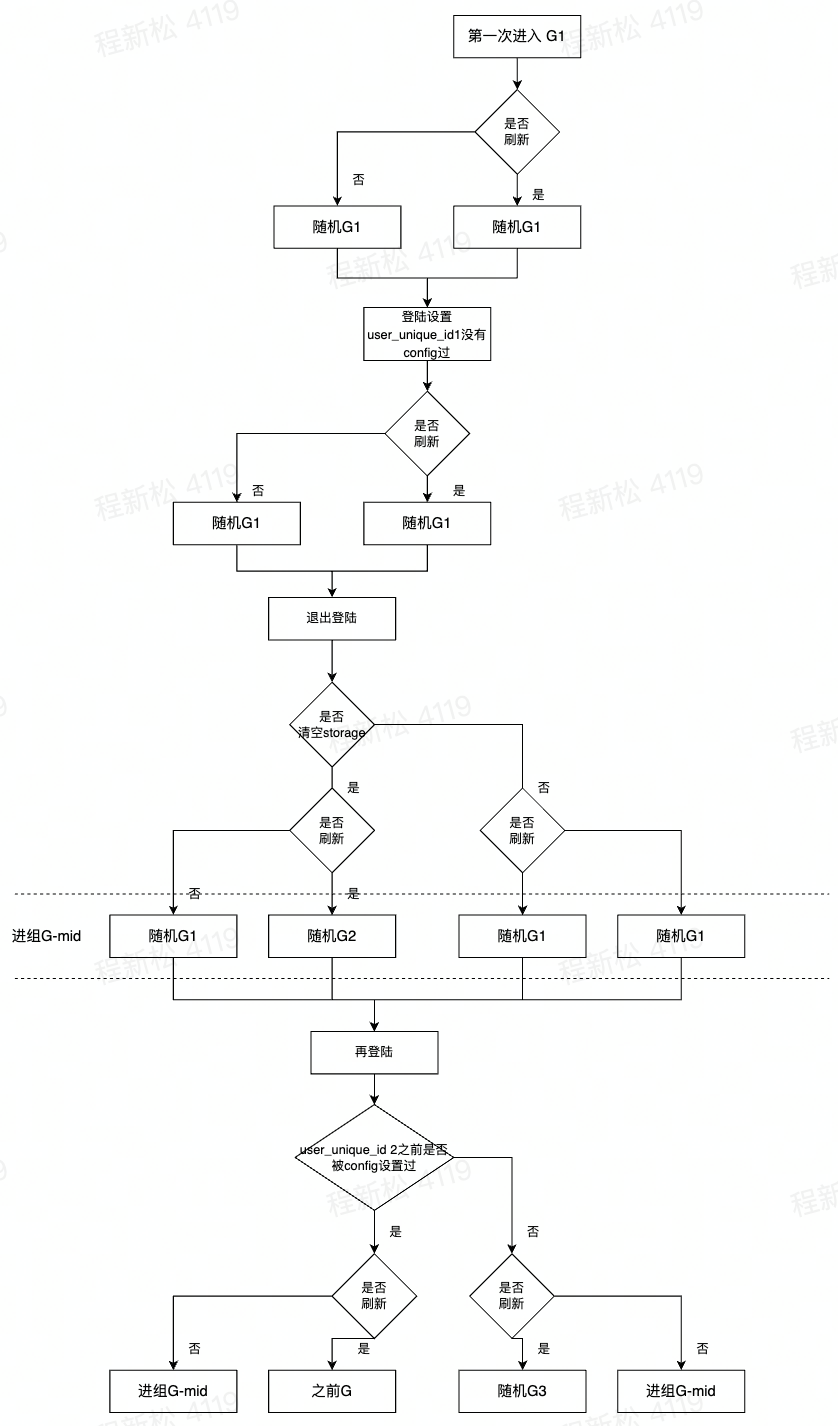
如果新设备上没有登陆账号,会随机进组,再登陆,设置config接口,
- 如果登陆的用户已经进组,刷新页面,还是会进到之前的组。
- 如果登陆的用户没有进组,还是会进到页面加载时候的随机分组里。
如果新设备上已经登陆了账户。
第一次进入,随机进组G1,刷新页面不会影响刚才进组结果。
- 然后登陆一个user_unique_id 1之前没有被config设置过,该用户还是在该组G1,刷新页面不会影响刚才进组结果,同时这个user_unique_id 1与进组情况绑定。
- 然后退出登陆
- 如果用户退出的时候,清除了所有localstorage,或者清除_tea_cache_tokens{appId}相关的。
- 如果刷新页面,用户会再次随机进组G2。
- 然后再登陆
- 如果再登陆user_unique_id 2之前没有被config设置过,不刷新页面,用户会在G2组,如果刷新页面用户会在G2组
- 如果再登陆user_unique_id 1之前被config设置过,不刷新页面,用户会在G2组,如果刷新页面用户会在G1组
- 然后再登陆
- 如果不刷新页面,用户还在刚才的组G1
- 然后再登陆
- 如果再登陆user_unique_id 2之前没有被config设置过,不刷新页面,用户会在G1组,刷新页面会进入到G2组。
- 如果再登陆user_unique_id 1之前被config设置过,不刷新页面,用户还在G1组,如果刷新页面用户在G1组
- 然后再登陆
- 如果刷新页面,用户会再次随机进组G2。
- 如果用户退出的时候,不清空localstorage
- 如果刷新页面,用户还在刚才的组G1
- 然后再登陆
- 如果再登陆user_unique_id 2之前没有被config设置过,不刷新页面,用户会在G1组,如果刷新页面用户会在G2组
- 如果再登陆user_unique_id 1之前被config设置过,不刷新页面,用户会在G1组,如果刷新页面用户会在G1组
- 然后再登陆
- 如果不刷新页面,用户还在刚才的组G1
- 然后再登陆
- 如果再登陆user_unique_id 2之前没有被config设置过,不刷新页面,用户会在G1组,刷新页面会进入到G2组。
- 如果再登陆user_unique_id 1之前被config设置过,不刷新页面,用户还在G1组,如果刷新页面用户在G1组
- 然后再登陆
- 如果刷新页面,用户还在刚才的组G1
- 如果用户退出的时候,清除了所有localstorage,或者清除_tea_cache_tokens{appId}相关的。

若有收获,就点个赞吧
0 人点赞
