1. 概述
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制、Spark任务调度机制、Spark内存管理机制、Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更好地完成Spark代码设计,并能够帮助我们准确锁定项目运行过程中出现的问题的症结所在。
1.1. Spark核心组件回顾
1.1.1. Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:
- 将用户程序转化为作业(Job);
- 在Executor之间调度任务(Task);
- 跟踪Executor的执行情况;
-
1.1.2. Executor
Spark Executor节点是负责在Spark作业中运行具体任务,任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个Spark应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能: 负责运行组成Spark应用的任务,并将结果返回给驱动器(Driver);
它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
1.2. Spark通用运行流程概述
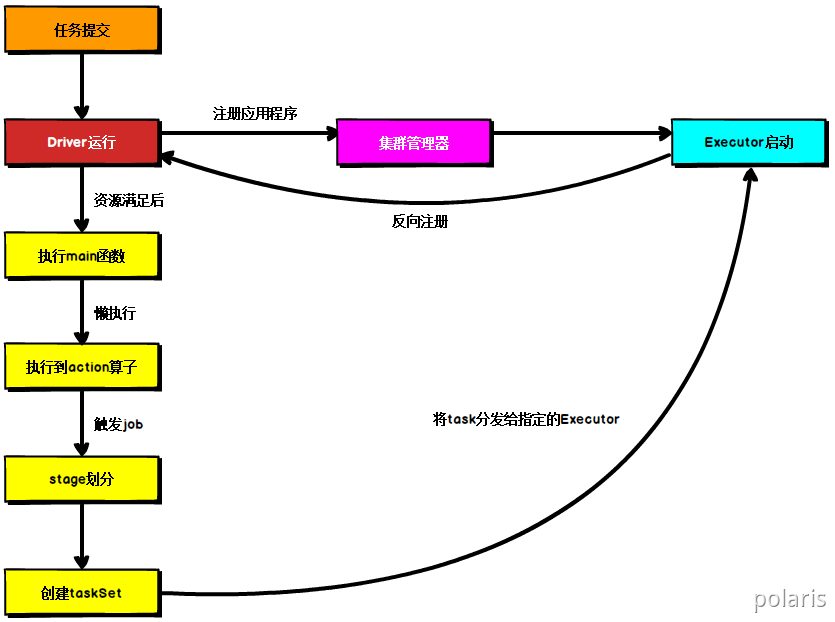
上图为Spark通用运行流程图,体现了基本的Spark应用程序在部署中的基本提交流程。这个流程是按照如下的核心步骤进行工作的:任务提交后,都会先启动Driver程序;
- 随后Driver向集群管理器注册应用程序;
- 之后集群管理器根据此任务的配置文件分配Executor并启动;
- Driver开始执行main函数,Spark查询为懒执行,当执行到Action算子时开始反向推算,根据宽依赖进行Stage的划分,随后每一个Stage对应一个Taskset,Taskset中有多个Task,查找可用资源Executor进行调度;
根据本地化原则,Task会被分发到指定的Executor去执行,在任务执行的过程中,Executor也会不断与Driver进行通信,报告任务运行情况。
2. Spark部署模式
Spark支持多种集群管理器(Cluster Manager),分别为:
Standalone:独立模式,Spark原生的简单集群管理器,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统,使用Standalone可以很方便地搭建一个集群;
- Hadoop YARN:统一的资源管理机制,在上面可以运行多套计算框架,如MR、Storm等。根据Driver在集群中的位置不同,分为yarn client和yarn cluster;
- Apache Mesos:一个强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括Yarn。
- K8S : 容器式部署环境。
实际上,除了上述这些通用的集群管理器外,Spark内部也提供了方便用户测试和学习的本地集群部署模式和Windows环境。由于在实际工厂环境下使用的绝大多数的集群管理器是Hadoop YARN,因此我们关注的重点是Hadoop YARN模式下的Spark集群部署。
2.1. YARN模式运行机制
2.1.1. YARN Cluster模式
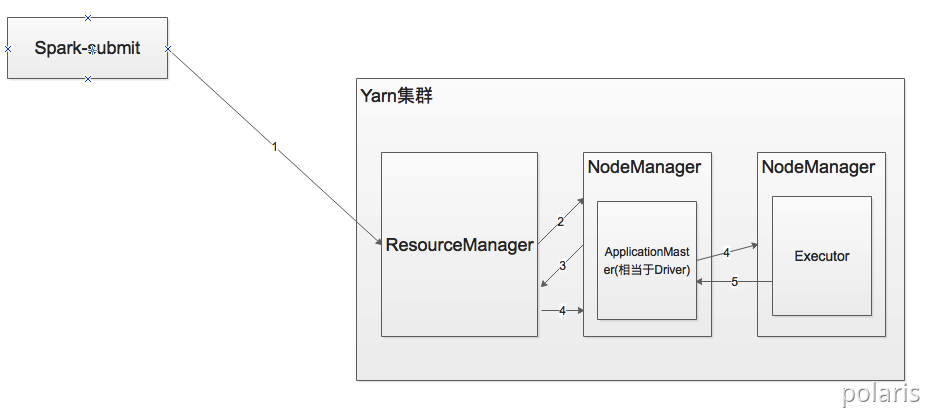
- 执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
- SparkSubmit类中的main方法反射调用YarnClusterApplication的main方法;
- YarnClusterApplication创建Yarn客户端,然后向Yarn发送执行指令:bin/java ApplicationMaster;
- Yarn框架收到指令后会在指定的NM中启动ApplicationMaster;
- ApplicationMaster启动Driver线程,执行用户的作业;
- AM向RM注册,申请资源;
- 获取资源后AM向NM发送指令:bin/java CoarseGrainedExecutorBackend;
- CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
- Driver分配任务并监控任务的执行。
注意:SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBackend是独立的进程;Driver是独立的线程;Executor和YarnClusterApplication是对象。
2.1.2. YARN Client模式
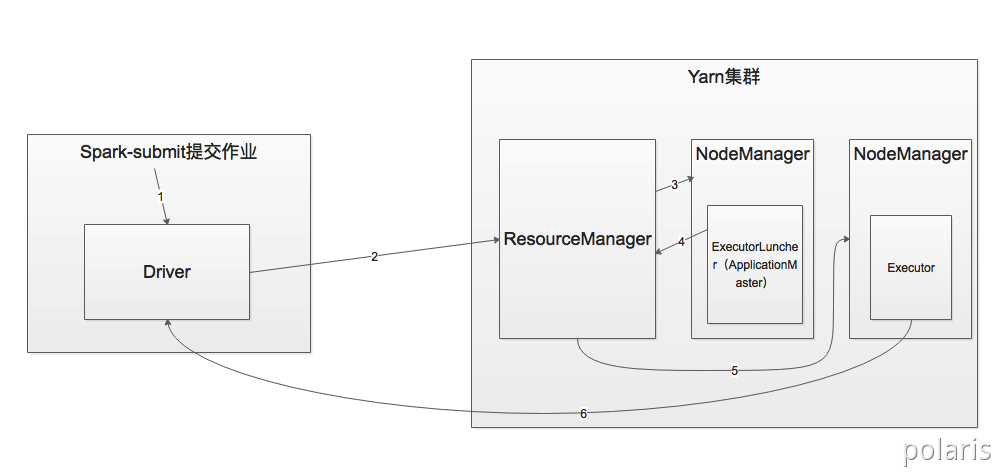
- 执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
- SparkSubmit类中的main方法反射调用用户代码的main方法;
- 启动Driver线程,执行用户的作业,并创建ScheduleBackend;
- YarnClientSchedulerBackend向RM发送指令:bin/java ExecutorLauncher;
Yarn框架收到指令后会在指定的NM中启动ExecutorLauncher(实际上还是调用ApplicationMaster的main方法);
object ExecutorLauncher {def main(args: Array[String]): Unit = {ApplicationMaster.main(args)}}
AM向RM注册,申请资源;
- 获取资源后AM向NM发送指令:bin/java CoarseGrainedExecutorBackend;
- CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务;
- Driver分配任务并监控任务的执行。
注意:SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBackend是独立的进程;Executor和Driver是对象。
2.2. Standalone模式运行机制
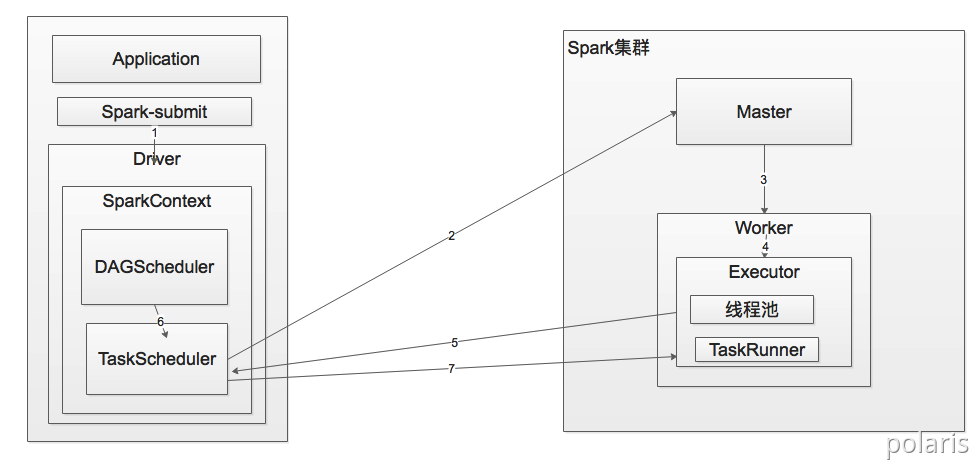
Standalone集群有2个重要组成部分,分别是:
- Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
- Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
2.2.1. Standalone Cluster模式
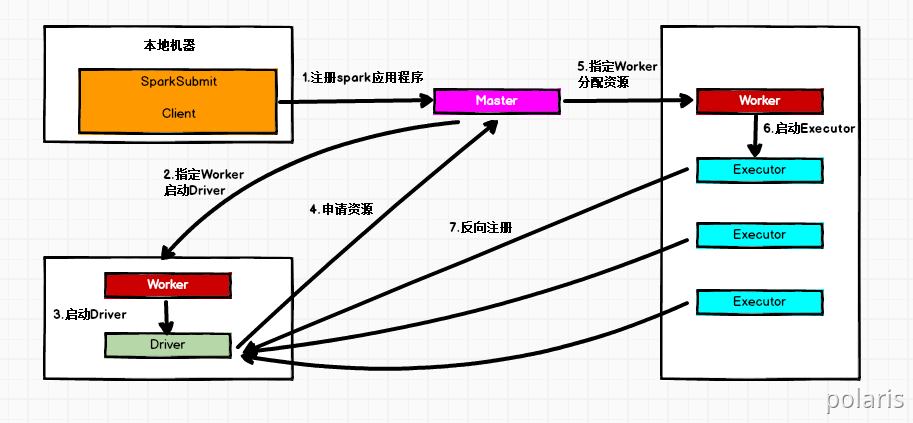
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver。Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分Stage,每个Stage生成对应的taskSet,之后将Task分发到各个Executor上执行。2.2.2. Standalone Client模式
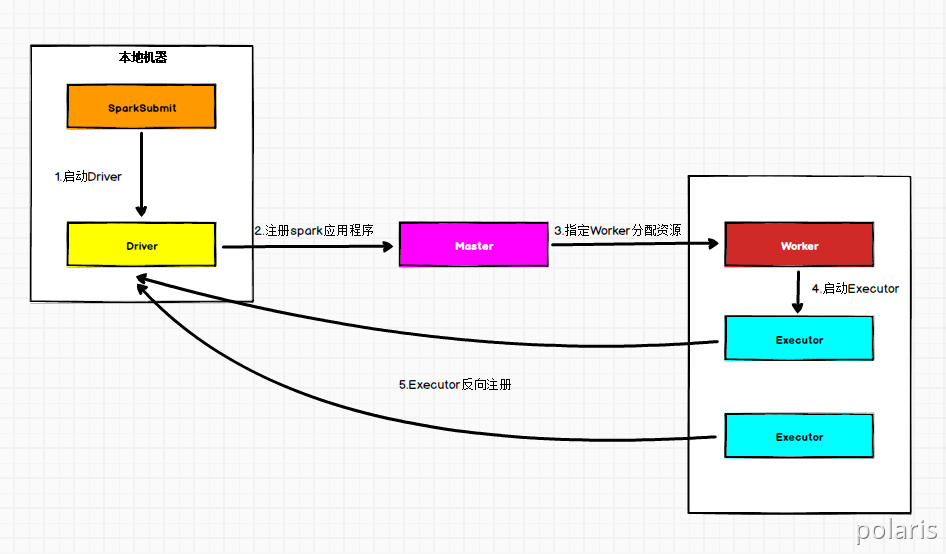
在Standalone Client模式下,Driver在任务提交的本地机器上运行。Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。3. Spark通讯架构
3.1. Spark通信架构概述
Spark中通信框架的发展:
- Spark早期版本中采用Akka作为内部通信部件。
- Spark1.3中引入Netty通信框架,为了解决Shuffle的大数据传输问题使用
- Spark1.6中Akka和Netty可以配置使用。Netty完全实现了Akka在Spark中的功能。
- Spark2系列中,Spark抛弃Akka,使用Netty。
Spark2.x版本使用Netty通讯框架作为内部通讯组件。Spark 基于Netty新的RPC框架借鉴了Akka的中的设计,它是基于Actor模型,如下图所示: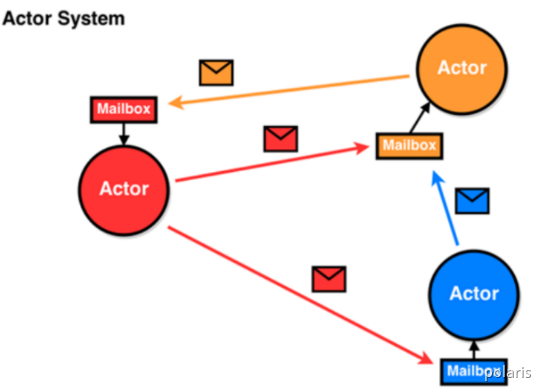
Spark通讯框架中各个组件(Client/Master/Worker)可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下: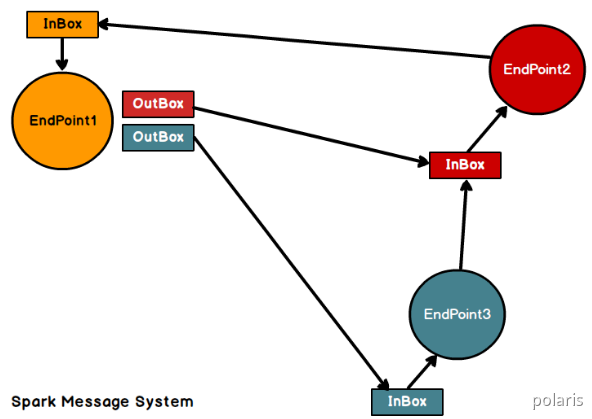
Endpoint(Client/Master/Worker)有1个InBox和N个OutBox(N>=1,N取决于当前Endpoint与多少其他的Endpoint进行通信,一个与其通讯的其他Endpoint对应一个OutBox),Endpoint接收到的消息被写入InBox,发送出去的消息写入OutBox并被发送到其他Endpoint的InBox中。
Spark通信终端
- Driver
class DriverEndpoint extends ThreadSafeRpcEndpoint
- Executor
class CoarseGrainedExecutorBackend extends ThreadSafeRpcEndpoint
3.2. Spark通讯架构解析
Spark通信架构如下图所示: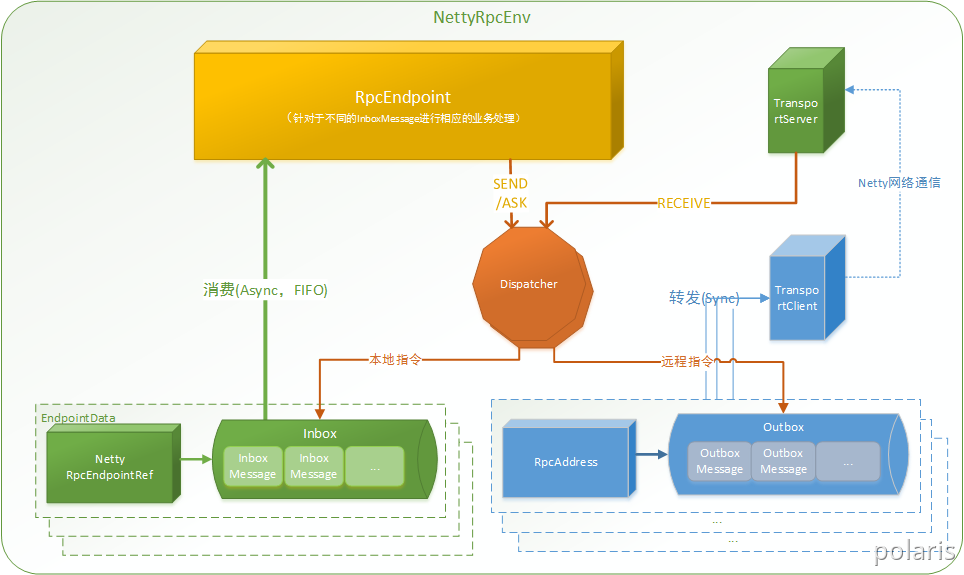
RpcEndpoint:RPC通信终端。Spark针对每个节点(Client/Master/Worker)都称之为一个RPC终端,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。在Spark中,所有的终端都存在生命周期:
l Constructorl onStartl receive*l onStop
RpcEnv:RPC上下文环境,每个RPC终端运行时依赖的上下文环境称为RpcEnv;在把当前Spark版本中使用的NettyRpcEnv。
- Dispatcher:消息调度(分发)器,针对于RPC终端需要发送远程消息或者从远程RPC接收到的消息,分发至对应的指令收件箱(发件箱)。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱;
- Inbox:指令消息收件箱。一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费;
- RpcEndpointRef:RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。
- OutBox:指令消息发件箱。对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
- RpcAddress:表示远程的RpcEndpointRef的地址,Host + Port。
- TransportClient:Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer;
- TransportServer:Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱;
4. Spark任务调度机制
在生产环境下,Spark集群的部署方式一般为YARN-Cluster模式,之后的内核分析内容中我们默认集群的部署方式为YARN-Cluster模式。在上一章中我们讲解了Spark YARN-Cluster模式下的任务提交流程,但是我们并没有具体说明Driver的工作流程, Driver线程主要是初始化SparkContext对象,准备运行所需的上下文,然后一方面保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源,另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Executor上。
当ResourceManager向ApplicationMaster返回Container资源时,ApplicationMaster就尝试在对应的Container上启动Executor进程,Executor进程起来后,会向Driver反向注册,注册成功后保持与Driver的心跳,同时等待Driver分发任务,当分发的任务执行完毕后,将任务状态上报给Driver。4.1. Spark任务调度概述
当Driver起来后,Driver则会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务。在详细阐述任务调度前,首先说明下Spark里的几个概念。一个Spark应用程序包括Job、Stage以及Task三个概念:
- Job是以Action方法为界,遇到一个Action方法则触发一个Job;
- Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
- Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
Spark的任务调度总体来说分两路进行,一路是Stage级的调度,一路是Task级的调度,总体调度流程如下图所示: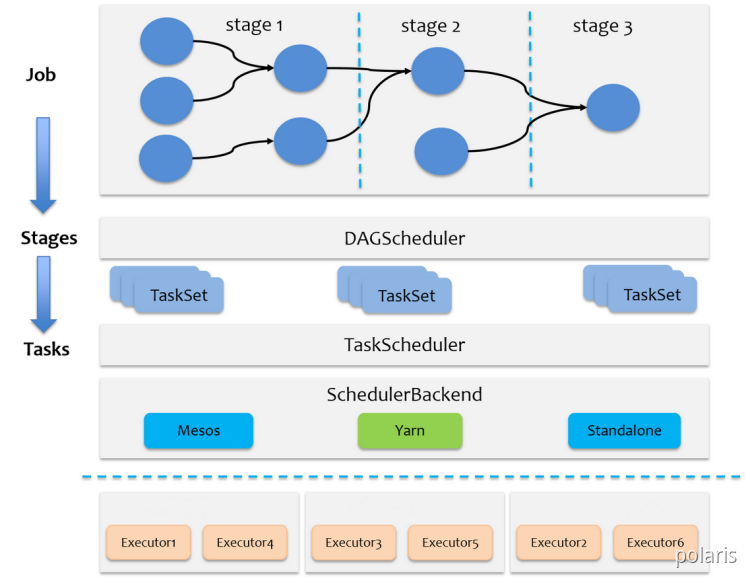
Spark RDD通过其Transactions操作,形成了RDD血缘(依赖)关系图,即DAG,最后通过Action的调用,触发Job并调度执行,执行过程中会创建两个调度器:DAGScheduler和TaskScheduler。
- DAGScheduler
负责Stage级的调度,主要是将job切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
- TaskScheduler
负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。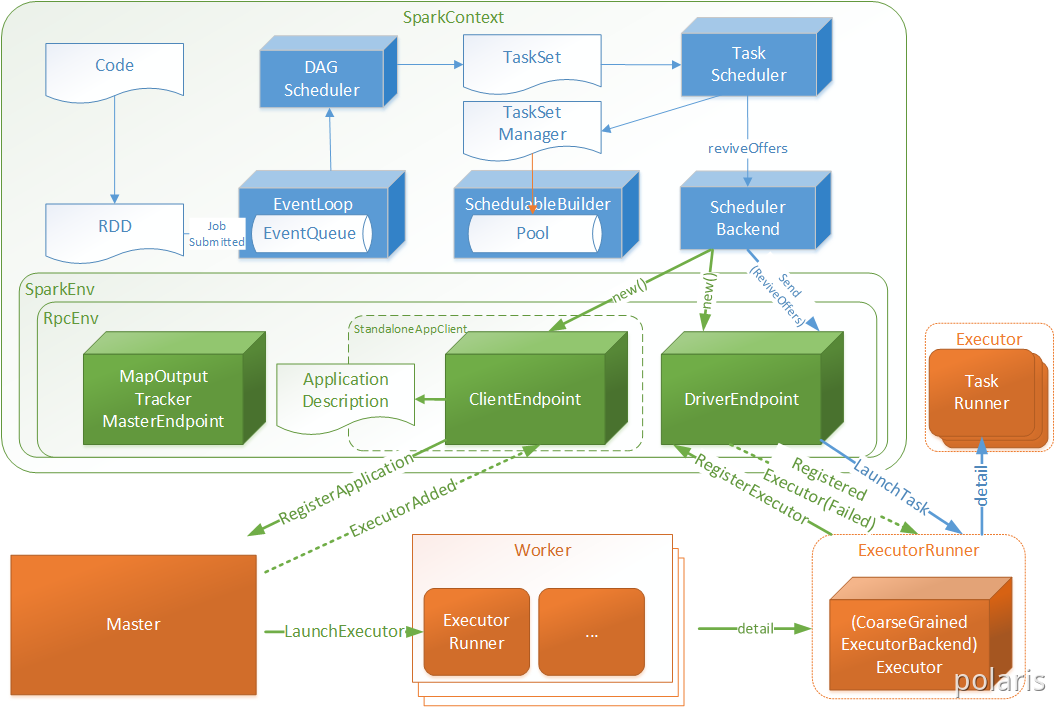
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver。SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。
4.2. Spark Stage级调度
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交,下图是涉及到Job提交的相关方法调用流程图。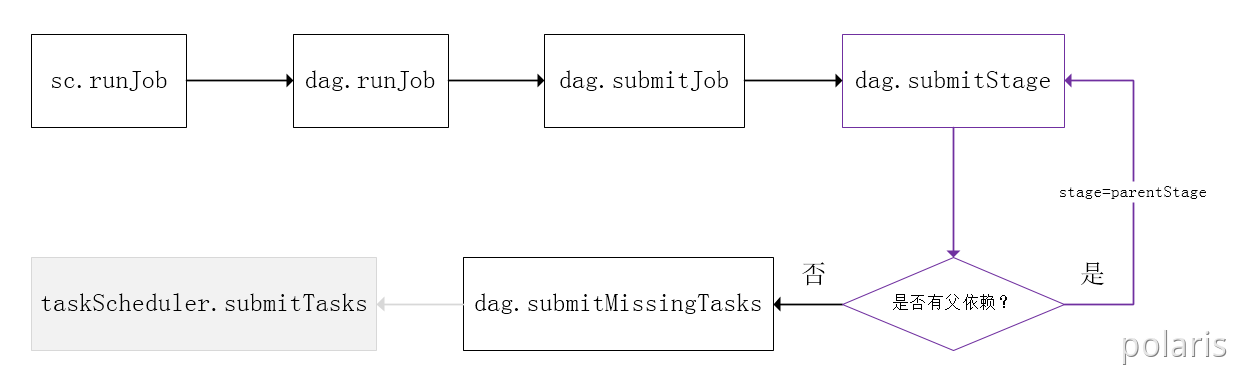
- Job由最终的RDD和Action方法封装而成;
- SparkContext将Job交给DAGScheduler提交,它会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,即以Shuffle为界,划分Stage,窄依赖的RDD之间被划分到同一个Stage中,可以进行pipeline式的计算。划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据,下面看一个简单的例子WordCount。
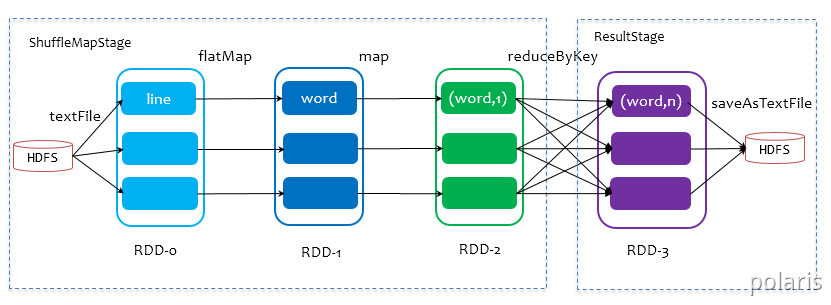
Job由saveAsTextFile触发,该Job由RDD-3和saveAsTextFile方法组成,根据RDD之间的依赖关系从RDD-3开始回溯搜索,直到没有依赖的RDD-0,在回溯搜索过程中,RDD-3依赖RDD-2,并且是宽依赖,所以在RDD-2和RDD-3之间划分Stage,RDD-3被划到最后一个Stage,即ResultStage中,RDD-2依赖RDD-1,RDD-1依赖RDD-0,这些依赖都是窄依赖,所以将RDD-0、RDD-1和RDD-2划分到同一个Stage,形成pipeline操作,。即ShuffleMapStage中,实际执行的时候,数据记录会一气呵成地执行RDD-0到RDD-2的转化。不难看出,其本质上是一个深度优先搜索(Depth First Search)算法。
一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage,如果一个Stage没有父Stage,那么从该Stage开始提交。Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面TaskScheduler会监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
相对来说DAGScheduler做的事情较为简单,仅仅是在Stage层面上划分DAG,提交Stage并监控相关状态信息。TaskScheduler则相对较为复杂,下面详细阐述其细节。
4.3. Spark Task级调度
Spark Task的调度是由TaskScheduler来完成,由前文可知,DAGScheduler将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将TaskSet封装为TaskSetManager加入到调度队列中,TaskSetManager结构如下图所示。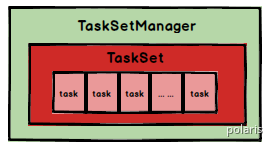
TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。
前面也提到,TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,所以说SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么余粮,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,大致方法调用流程如下图所示: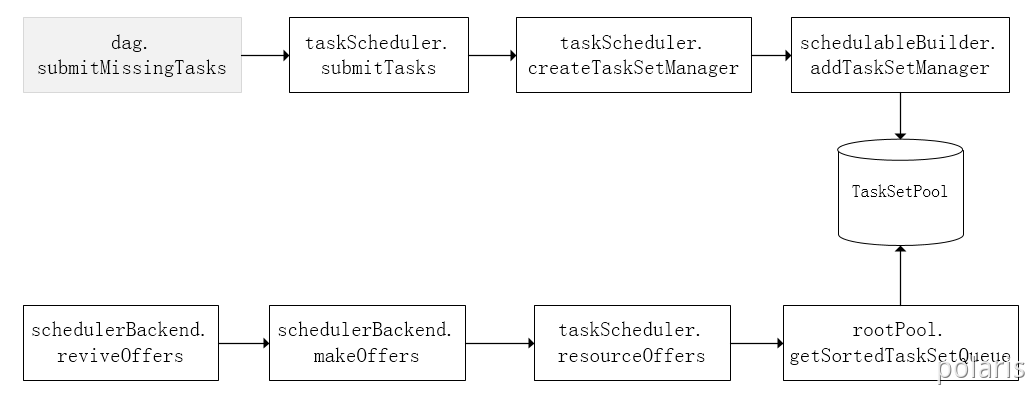
上图中,将TaskSetManager加入rootPool调度池中之后,调用SchedulerBackend的riviveOffers方法给driverEndpoint发送ReviveOffer消息;driverEndpoint收到ReviveOffer消息后调用makeOffers方法,过滤出活跃状态的Executor(这些Executor都是任务启动时反向注册到Driver的Executor),然后将Executor封装成WorkerOffer对象;准备好计算资源(WorkerOffer)后,taskScheduler基于这些资源调用resourceOffer在Executor上分配task。
4.3.1. 调度策略
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。在TaskScheduler初始化过程中会实例化rootPool,表示树的根节点,是Pool类型。
- FIFO调度策略
如果是采用FIFO调度策略,则直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager,其树结构如下图所示,TaskSetManager保存在一个FIFO队列中。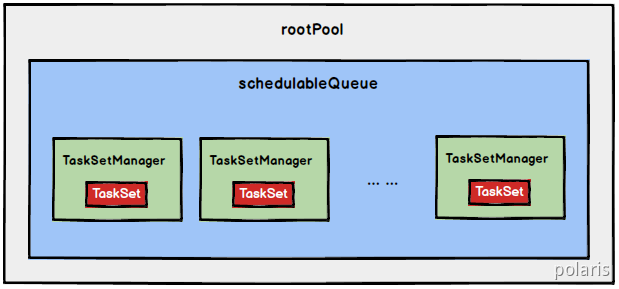
- FAIR调度策略
FAIR调度策略的树结构如下图所示: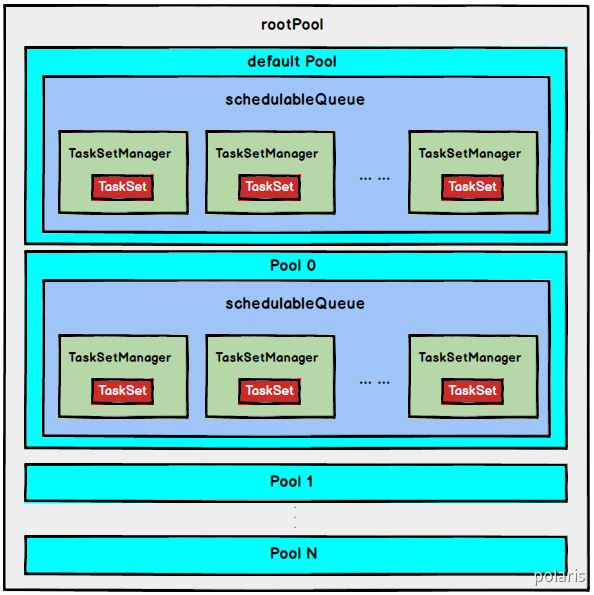
FAIR模式中有一个rootPool和多个子Pool,各个子Pool中存储着所有待分配的TaskSetMagager。
在FAIR模式中,需要先对子Pool进行排序,再对子Pool里面的TaskSetMagager进行排序,因为Pool和TaskSetMagager都继承了Schedulable特质,因此使用相同的排序算法。
排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare值以及weight值。
注意,minShare、weight的值均在公平调度配置文件fairscheduler.xml中被指定,调度池在构建阶段会读取此文件的相关配置。
- 如果A对象的runningTasks大于它的minShare,B对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks比minShare小的先执行)
- 如果A、B对象的runningTasks都小于它们的minShare,那么就比较runningTasks与minShare的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行)
- 如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
- 如果上述比较均相等,则比较名字。
整体上来说就是通过minShare和weight这两个参数控制比较过程,可以做到让minShare使用率和权重使用率少(实际运行task比例较少)的先运行。
FAIR模式排序完成后,所有的TaskSetManager被放入一个ArrayBuffer里,之后依次被取出并发送给Executor执行。
从调度队列中拿到TaskSetManager后,由于TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
4.3.2. 本地化调度
DAGScheduler切割Job,划分Stage, 通过调用submitStage来提交一个Stage对应的tasks,submitStage会调用submitMissingTasks,submitMissingTasks 确定每个需要计算的 task 的preferredLocations,通过调用getPreferrdeLocations()得到partition 的优先位置,由于一个partition对应一个Task,此partition的优先位置就是task的优先位置,对于要提交到TaskScheduler的TaskSet中的每一个Task,该task优先位置与其对应的partition对应的优先位置一致。
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task。
根据每个Task的优先位置,确定Task的Locality级别,Locality一共有五种,优先级由高到低顺序:
| 名称 | 解析 |
|---|---|
| PROCESS_LOCAL | 进程本地化,task和数据在同一个Executor中,性能最好。 |
| NODE_LOCAL | 节点本地化,task和数据在同一个节点中,但是task和数据不在同一个Executor中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 对于task来说,从哪里获取都一样,没有好坏之分。 |
| ANY | task和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
在调度执行时,Spark调度总是会尽量让每个task以最高的本地性级别来启动,当一个task以X本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以X本地性级别来启动该task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。
可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的Executor可能就会有相应的资源去执行此task,这就在在一定程度上提到了运行性能。
4.3.3. 失败重试与黑名单机制
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor Id和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
5. Spark Shuffle解析
5.1. Shuffle的核心要点
5.1.1. ShuffleMapStage与ResultStage
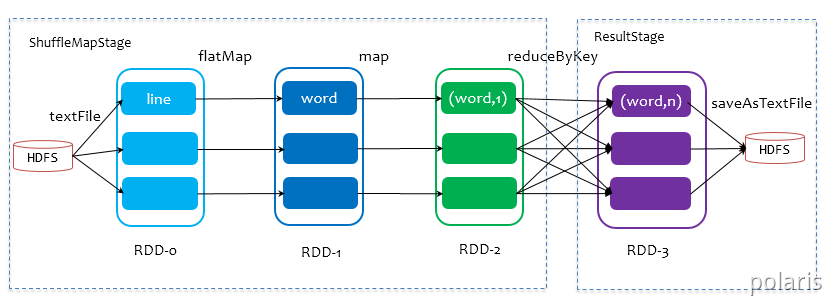
在划分stage时,最后一个stage称为finalStage,它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。
ShuffleMapStage的结束伴随着shuffle文件的写磁盘。
ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束。
5.2. HashShuffle解析
5.2.1. 未优化的HashShuffle
这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
如下图中有3个 Reducer,从Task 开始那边各自把自己进行 Hash 计算(分区器:hash/numreduce取模),分类出3个不同的类别,每个 Task 都分成3种类别的数据,想把不同的数据汇聚然后计算出最终的结果,所以Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,每1个 Task 输出3份本地文件,这里有4个 Mapper Tasks,所以总共输出了4个 Tasks x 3个分类文件 = 12个本地小文件。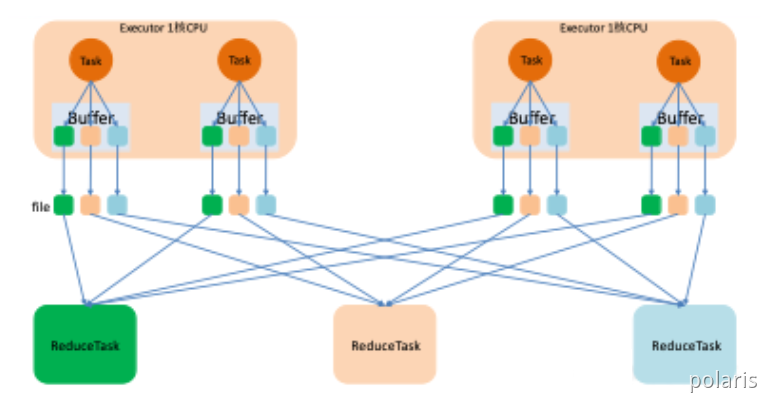
5.2.2. 优化后的HashShuffle
优化的HashShuffle过程就是启用合并机制,合并机制就是复用buffer,开启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
这里还是有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。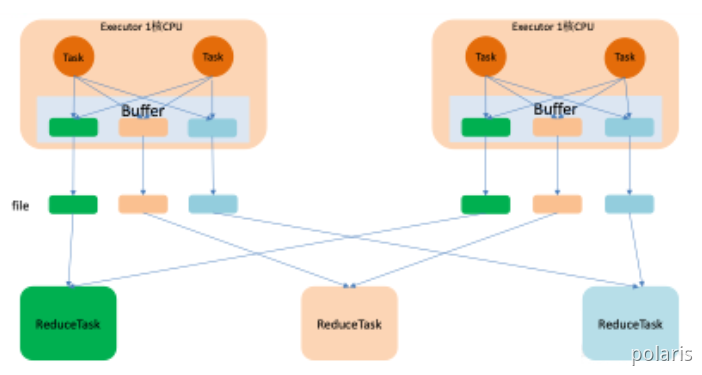
5.3. SortShuffle解析
5.3.1. 普通SortShuffle
在该模式下,数据会先写入一个数据结构,reduceByKey写入Map,一边通过Map局部聚合,一遍写入内存。Join算子写入ArrayList直接写入内存中。然后需要判断是否达到阈值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
在溢写磁盘前,先根据key进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为10000条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个Task过程会产生多个临时文件。
最后在每个Task中,将所有的临时文件合并,这就是merge过程,此过程将所有临时文件读取出来,一次写入到最终文件。意味着一个Task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个Task的数据在文件中的索引,start offset和end offset。
5.3.2. bypass SortShuffle
bypass运行机制的触发条件如下:
- shuffle reduce task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。
- 不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
6. Spark内存管理
6.1. 堆内和堆外内存规划
作为一个JVM 进程,Executor 的内存管理建立在JVM的内存管理之上,Spark对 JVM的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。堆内内存受到JVM统一管理,堆外内存是直接向操作系统进行内存的申请和释放。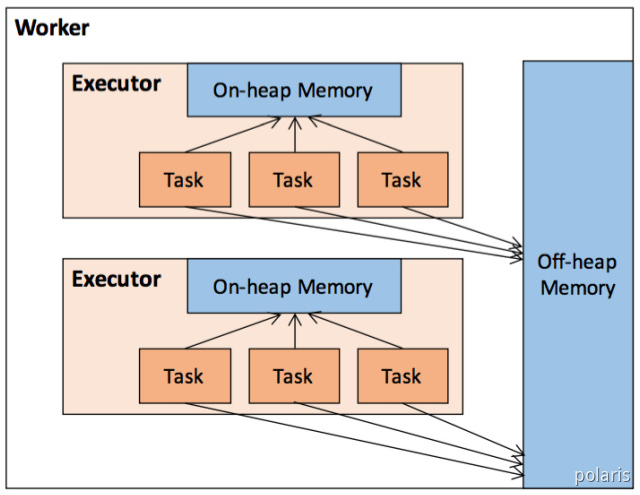
6.1.1. 堆内内存
堆内内存的大小,由Spark应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同。
Spark对堆内内存的管理是一种逻辑上的”规划式”的管理,因为对象实例占用内存的申请和释放都由JVM完成,Spark只能在申请后和释放前记录这些内存,我们来看其具体流程:
申请内存流程如下:
Spark 在代码中 new 一个对象实例;
JVM 从堆内内存分配空间,创建对象并返回对象引用;
Spark 保存该对象的引用,记录该对象占用的内存。
释放内存流程如下:
- Spark记录该对象释放的内存,删除该对象的引用;
- 等待JVM的垃圾回收机制释放该对象占用的堆内内存。
我们知道,JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
对于Spark中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期。此外,在被Spark标记为释放的对象实例,很有可能在实际上并没有被JVM回收,导致实际可用的内存小于Spark记录的可用内存。所以 Spark并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
6.1.2. 堆外内存
为了进一步优化内存的使用以及提高Shuffle时排序的效率,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
利用JDK Unsafe API(从Spark 2.0开始,在管理堆外的存储内存时不再基于Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放(堆外内存之所以能够被精确的申请和释放,是由于内存的申请和释放不再通过JVM机制,而是直接向操作系统申请,JVM对于内存的清理是无法准确指定时间点的,因此无法实现精确的释放),而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
6.2. 内存空间分配
6.2.1. 静态内存管理
在Spark最初采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在Spark应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置,堆内内存的分配如图所示:
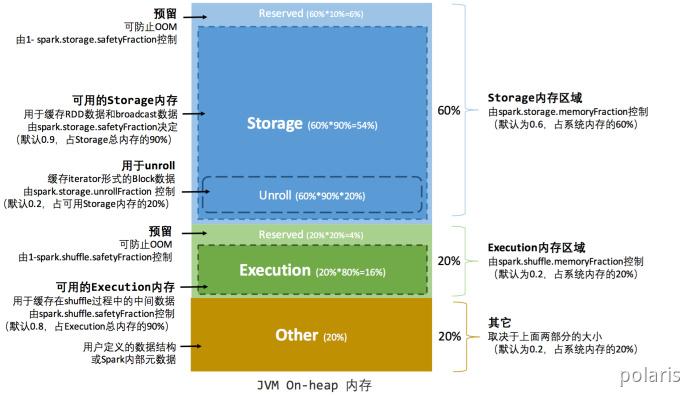
可以看到,可用的堆内内存的大小需要按照下列方式计算:
可用的存储内存 = systemMaxMemory spark.storage.memoryFraction spark.storage.safety Fraction 可用的执行内存 = systemMaxMemory spark.shuffle.memoryFraction spark.shuffle.safety Fraction
其中systemMaxMemory取决于当前JVM堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的memoryFraction 参数和safetyFraction 参数相乘得出。上述计算公式中的两个 safetyFraction 参数,其意义在于在逻辑上预留出 1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时 Spark 并没有区别对待,和”其它内存”一样交给了 JVM 去管理。
Storage内存和Execution内存都有预留空间,目的是防止OOM,因为Spark堆内内存大小的记录是不准确的,需要留出保险区域。
堆外的空间分配较为简单,只有存储内存和执行内存,如下图所示。可用的执行内存和存储内存占用的空间大小直接由参数spark.memory.storageFraction 决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。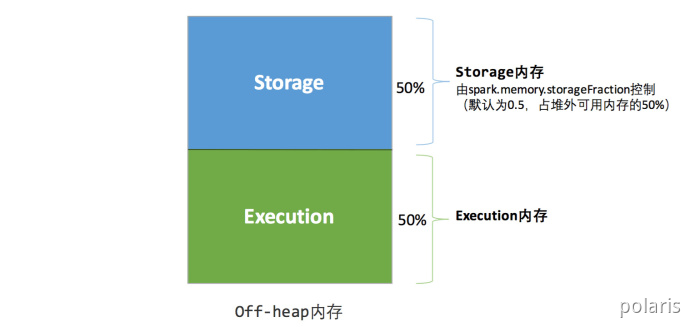
静态内存管理机制实现起来较为简单,但如果用户不熟悉Spark的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成”一半海水,一半火焰”的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
6.2.2. 统一内存管理
Spark1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,统一内存管理的堆内内存结构如图所示: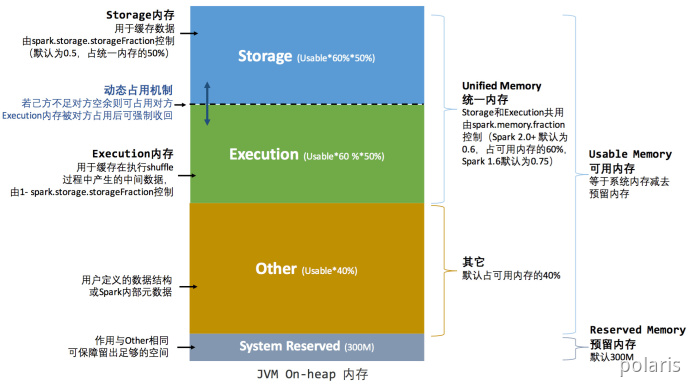
统一内存管理的堆外内存结构如下图所示: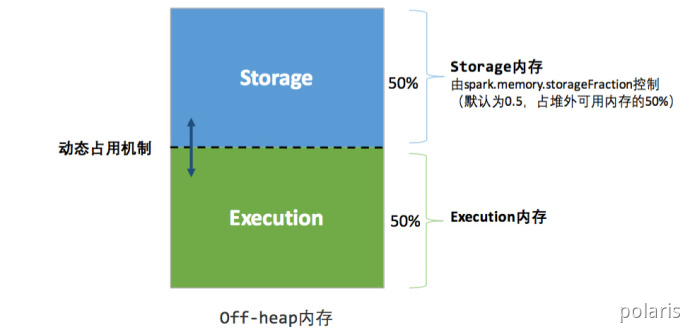
其中最重要的优化在于动态占用机制,其规则如下:
- 设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围;
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间;
- 存储内存的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle过程中的很多因素,实现起来较为复杂。
统一内存管理的动态占用机制如图所示: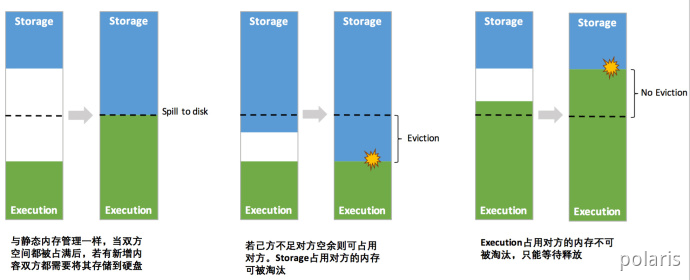
凭借统一内存管理机制,Spark在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护Spark内存的难度,但并不意味着开发者可以高枕无忧。如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的RDD数据通常都是长期驻留内存的。所以要想充分发挥Spark的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
6.3. 存储内存管理
6.3.1 RDD的持久化机制
弹性分布式数据集(RDD)作为 Spark 最根本的数据抽象,是只读的分区记录(Partition)的集合,只能基于在稳定物理存储中的数据集上创建,或者在其他已有的RDD上执行转换(Transformation)操作产生一个新的RDD。转换后的RDD与原始的RDD之间产生的依赖关系,构成了血统(Lineage)。凭借血统,Spark 保证了每一个RDD都可以被重新恢复。但RDD的所有转换都是惰性的,即只有当一个返回结果给Driver的行动(Action)发生时,Spark才会创建任务读取RDD,然后真正触发转换的执行。
Task在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查Checkpoint 或按照血统重新计算。所以如果一个 RDD 上要执行多次行动,可以在第一次行动中使用 persist或cache 方法,在内存或磁盘中持久化或缓存这个RDD,从而在后面的行动时提升计算速度。
事实上,cache 方法是使用默认的 MEMORY_ONLY 的存储级别将 RDD 持久化到内存,故缓存是一种特殊的持久化。 堆内和堆外存储内存的设计,便可以对缓存RDD时使用的内存做统一的规划和管理。
RDD的持久化由 Spark的Storage模块负责,实现了RDD与物理存储的解耦合。Storage模块负责管理Spark在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时Driver端和 Executor 端的Storage模块构成了主从式的架构,即Driver端的BlockManager为Master,Executor端的BlockManager 为 Slave。
Storage模块在逻辑上以Block为基本存储单位,RDD的每个Partition经过处理后唯一对应一个 Block(BlockId 的格式为rdd_RDD-ID_PARTITION-ID )。Driver端的Master负责整个Spark应用程序的Block的元数据信息的管理和维护,而Executor端的Slave需要将Block的更新等状态上报到Master,同时接收Master 的命令,例如新增或删除一个RDD。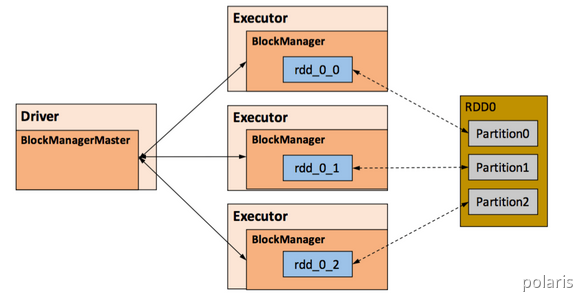
在对RDD持久化时,Spark规定了MEMORY_ONLY、MEMORY_AND_DISK 等7种不同的存储级别,而存储级别是以下5个变量的组合:
class StorageLevel private(private var _useDisk: Boolean, //磁盘private var _useMemory: Boolean, //这里其实是指堆内内存private var _useOffHeap: Boolean, //堆外内存private var _deserialized: Boolean, //是否为非序列化private var _replication: Int = 1 //副本个数)
Spark中7种存储级别如下:
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它们的时候,重新被计算 |
| MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
| MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
| MEMORY_AND_DISK_SER | 同MEMORY_AND_DISK,但是使用序列化方式持久化Java对象 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 |
如果是尾部加了2的持久化级别,表示将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
过对数据结构的分析,可以看出存储级别从三个维度定义了RDD的 Partition(同时也就是Block)的存储方式:
- 存储位置:磁盘/堆内内存/堆外内存。如MEMORY_AND_DISK是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
- 存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY是非序列化方式存储,OFF_HEAP 是序列化方式存储。
- 副本数量:大于1时需要远程冗余备份到其他节点。如DISK_ONLY_2需要远程备份1个副本。
6.3.2. RDD的缓存过程
RDD 在缓存到存储内存之前,Partition中的数据一般以迭代器(Iterator)的数据结构来访问,这是Scala语言中一种遍历数据集合的方法。通过Iterator可以获取分区中每一条序列化或者非序列化的数据项(Record),这些Record的对象实例在逻辑上占用了JVM堆内内存的other部分的空间,同一Partition的不同 Record 的存储空间并不连续。
RDD 在缓存到存储内存之后,Partition 被转换成Block,Record在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为”展开”(Unroll)。
Block 有序列化和非序列化两种存储格式,具体以哪种方式取决于该 RDD 的存储级别。非序列化的Block以一种 DeserializedMemoryEntry 的数据结构定义,用一个数组存储所有的对象实例,序列化的Block则以SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。每个 Executor 的 Storage模块用一个链式Map结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的Block对象的实例,对这个LinkedHashMap新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可以一次容纳 Iterator 中的所有数据,当前的计算任务在 Unroll 时要向 MemoryManager 申请足够的Unroll空间来临时占位,空间不足则Unroll失败,空间足够时可以继续进行。
对于序列化的Partition,其所需的Unroll空间可以直接累加计算,一次申请。
对于非序列化的 Partition 则要在遍历 Record 的过程中依次申请,即每读取一条 Record,采样估算其所需的Unroll空间并进行申请,空间不足时可以中断,释放已占用的Unroll空间。
如果最终Unroll成功,当前Partition所占用的Unroll空间被转换为正常的缓存 RDD的存储空间,如下图所示。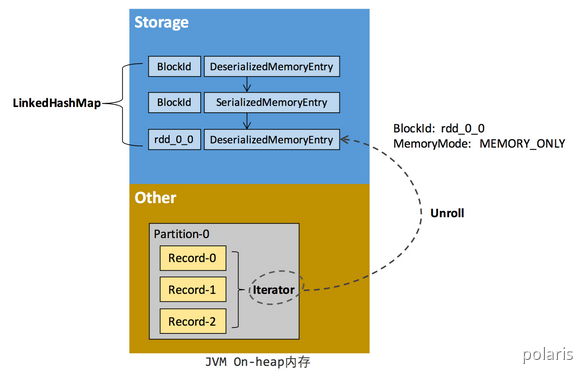
在静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的,统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。6.3.3 淘汰与落盘
由于同一个Executor的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对LinkedHashMap中的旧Block进行淘汰(Eviction),而被淘汰的Block如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该Block。
存储内存的淘汰规则为:
Ø 被淘汰的旧Block要与新Block的MemoryMode相同,即同属于堆外或堆内内存;
Ø 新旧Block不能属于同一个RDD,避免循环淘汰;
Ø 旧Block所属RDD不能处于被读状态,避免引发一致性问题;
Ø 遍历LinkedHashMap中Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新Block所需的空间。其中LRU是LinkedHashMap的特性。
落盘的流程则比较简单,如果其存储级别符合_useDisk为true的条件,再根据其_deserialized判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在Storage模块中更新其信息。6.4 执行内存管理
执行内存主要用来存储任务在执行Shuffle时占用的内存,Shuffle是按照一定规则对RDD数据重新分区的过程,我们来看Shuffle的Write和Read两阶段对执行内存的使用:6.4.1. Shuffle Write
若在map端选择普通的排序方式,会采用ExternalSorter进行外排,在内存中存储数据时主要占用堆内执行空间。
若在map端选择 Tungsten 的排序方式,则采用ShuffleExternalSorter直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。6.4.2. Shuffle Read
在对reduce端的数据进行聚合时,要将数据交给Aggregator处理,在内存中存储数据时占用堆内执行空间。
如果需要进行最终结果排序,则要将再次将数据交给ExternalSorter 处理,占用堆内执行空间。
在ExternalSorter和Aggregator中,Spark会使用一种叫AppendOnlyMap的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从MemoryManager 申请到新的执行内存时,Spark就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Shuffle Write 阶段中用到的Tungsten是Databricks公司提出的对Spark优化内存和CPU使用的计划(钨丝计划),解决了一些JVM在性能上的限制和弊端。Spark会根据Shuffle的情况来自动选择是否采用Tungsten排序。
Tungsten 采用的页式内存管理机制建立在MemoryManager之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。
每个内存页用一个MemoryBlock来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。
堆内的MemoryBlock是以long型数组的形式分配的内存,其obj的值为是这个数组的对象引用,offset是long型数组的在JVM中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;堆外的 MemoryBlock是直接申请到的内存块,其obj为null,offset是这个内存块在系统内存中的64位绝对地址。Spark用MemoryBlock巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个Task申请到的内存页。
Tungsten 页式管理下的所有内存用64位的逻辑地址表示,由页号和页内偏移量组成:页号:占13位,唯一标识一个内存页,Spark在申请内存页之前要先申请空闲页号。 页内偏移量:占51位,是在使用内存页存储数据时,数据在页内的偏移地址。
有了统一的寻址方式,Spark 可以用64位逻辑地址的指针定位到堆内或堆外的内存,整个Shuffle Write排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和CPU使用效率带来了明显的提升。
Spark的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark用一个LinkedHashMap来集中管理所有的Block,Block由需要缓存的 RDD的Partition转化而成;而对于执行内存,Spark用AppendOnlyMap来存储 Shuffle过程中的数据,在Tungsten排序中甚至抽象成为页式内存管理,开辟了全新的JVM内存管理机制。

若有收获,就点个赞吧
0 人点赞
