<br />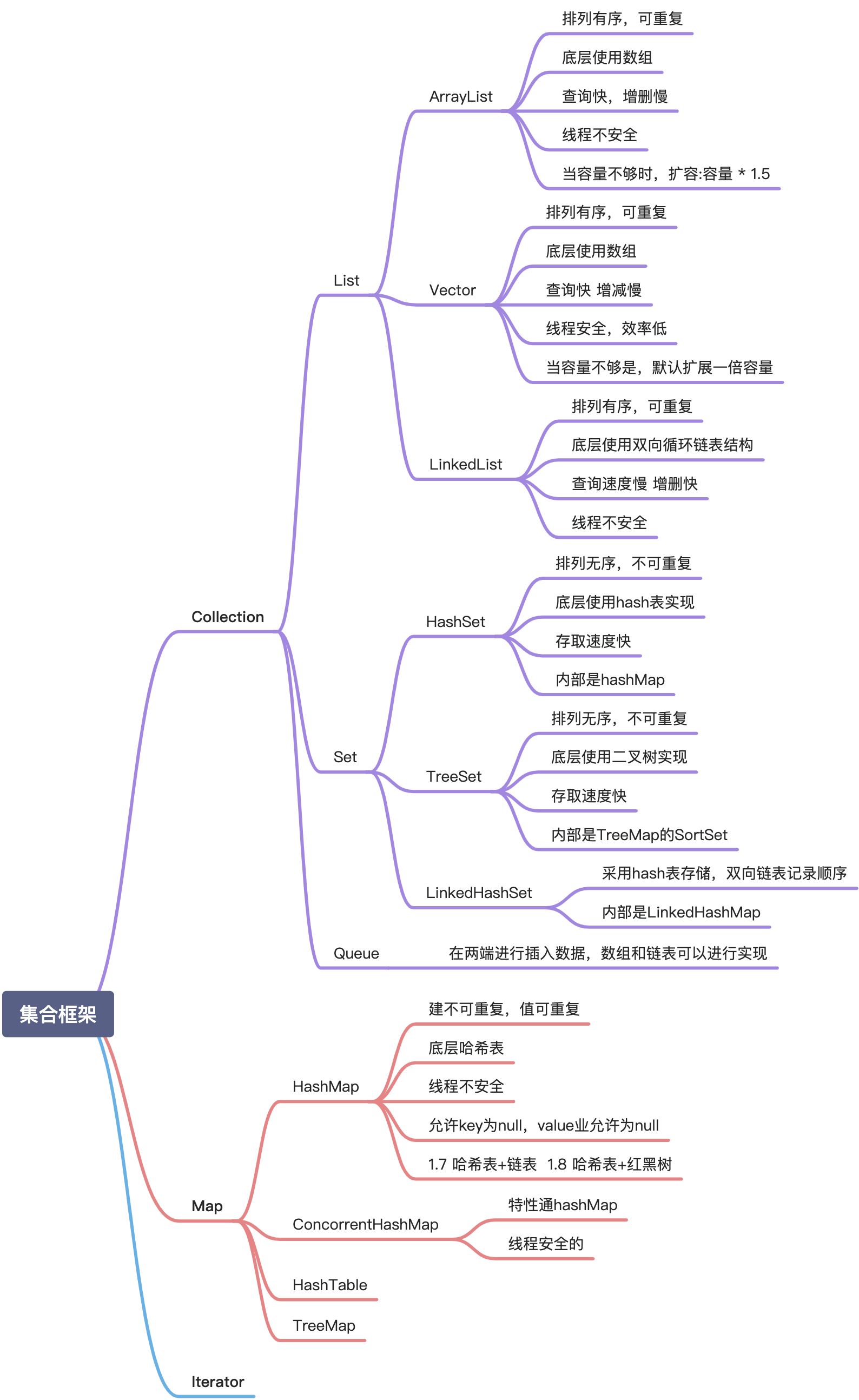
一、List
1、ArrayList
- 容量不够,新的容量将会是 size * 1.5 ,源码如下,附带部分注释进行解读:
public boolean add(E e) {// size 表示当前线性链表中的实际元素数量ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}private void ensureCapacityInternal(int minCapacity) {// 如果数组为空,那么初始化数组大小会是10if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);}private void ensureExplicitCapacity(int minCapacity) {modCount++;// 如果新增的元素所需空间 超过数组的长度 则进行数组长度增长if (minCapacity - elementData.length > 0)grow(minCapacity);}private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;// 新的数组长度 是 old + old/2 = 1.5 * oldint newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
- 扩容因子为什么是1.5倍 而不是2倍或者1.2 1.8倍
- 如果扩容因子是2倍的话 新开辟的空间永远大于等于2,那么新容量永远大于过去所有废弃的容量的总和
- 扩容因子为什么不是固定数值,因为固定数值有可能会太大,有可能也会太小 无法有效的规避扩容次数
- 扩容因子为什么不是1.2倍或者1.8倍,因为如果是1.5倍的话刚好是比特右移一位产生,计算快捷节省时间
2、Vector
线程安全策略:
// 通过synchronized关键字修饰实现线程安全public synchronized void addElement(E obj) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = obj;}
扩容增长策略:
- 如果定义的增长容量大于0 则按照增长容量进行增长,否则进行原容量的倍数增长
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity);}
3、HashMap
- 如果定义的增长容量大于0 则按照增长容量进行增长,否则进行原容量的倍数增长
hashMap的数据结构
- 1.7 数组+链表
- 1.8 数组+链表+红黑树
- hashMap的扩容原理
- 扩容为什么两倍扩容
- 扩容因子为什么是0.75
- 如果扩容因子是1的话容易产生哈希碰撞
- 如果扩容因子是0.5的话不利于空间的使用
- 扩容条件是等于 当前容量 * 扩容因子的大小即扩容
- hashMap的线程不安全的原理 - 因为在resize()在多线程执行的情况下会出现多值覆盖情况
hashMap源码解析:
基本属性
/*** The default initial capacity - MUST be a power of two.* 初始容量是2的4次方也就是16的大小 默认*/static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** The maximum capacity, used if a higher value is implicitly specified* by either of the constructors with arguments.* MUST be a power of two <= 1<<30.* 最大容量不能超过2的30次方*/static final int MAXIMUM_CAPACITY = 1 << 30;/*** The load factor used when none specified in constructor.* 负载因子是0.75*/static final float DEFAULT_LOAD_FACTOR = 0.75f;
基本方法
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}该方法是 |= 该符号的意思是二进制计算中相同进制位都为0则为零,否则就是1, >>> 无符号右移,所以上述方法是为了得到指定cap大小的最大bit位的值,举例:如果cap = 17 则 n = 16也就是 二进制 10000第一次无符号右移1位 |= 的结果为 10000 |= 01000 结果是 11000第二次无符号右移2位 |= 的结果为 11000 |= 00110 结果是 11110最终变为 11111这种模式 再 +1 也就是 100000 也就是 32的大小,所以cap= 17需要 32的初始容量大小
核心方法 ```java final TreeNode
int h, K k, V v) {// map 当前Hashmap对象//tab Hashmap对象中的table数组//h hash值// K key// V valueClass<?> kc = null;boolean searched = false; //标识是否被收索过TreeNode<K,V> root = (parent != null) ? root() : this; // 找到root根节点for (TreeNode<K,V> p = root;;) { //从根节点开始遍历循环int dir, ph; K pk;// 根据hash值 判断方向if ((ph = p.hash) > h)// 大于放左侧dir = -1;else if (ph < h)// 小于放右侧dir = 1;// 如果key 相等 直接返回该节点的引用 外边的方法会对其value进行设置else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;/***下面的步骤主要就是当发生冲突 也就是hash相等的时候* 检验是否有hash相同 并且equals相同的节点。* 也就是检验该键是否存在与该树上*///说明进入下面这个判断的条件是 hash相同 但是equal不同// 没有实现Comparable<C>接口或者 实现该接口 并且 k与pk Comparable比较结果相同else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {//在左右子树递归的寻找 是否有key的hash相同 并且equals相同的节点if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))//找到了 就直接返回return q;}
//说明红黑树中没有与之equals相等的 那就必须进行插入操作//打破平衡的方法的 分出大小 结果 只有-1 1dir = tieBreakOrder(k, pk);}//下列操作进行插入节点//xp 保存当前节点TreeNode<K,V> xp = p;//找到要插入节点的位置if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;//创建出一个新的节点TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)//小于父亲节点 新节点放左孩子位置xp.left = x;else//大于父亲节点 放右孩子位置xp.right = x;//维护双链表关系xp.next = x;x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;//将root移到table数组的i 位置的第一个节点//插入操作过红黑树之后 重新调整平衡。moveRootToFront(tab, balanceInsertion(root, x));return null;}}}
4、concurrentHashMap

若有收获,就点个赞吧
0 人点赞
