- 消息队列
- 用过(吗)哪些消费队列?*
- kafka是什么,主要应用场景有哪些
- 和其他消息队列相比,kafka的优势在哪里
- 什么是producer、consumer、broker、topic、partition
- kafka的多副本机制了解吗
- kafka的多分区(partition)以及多副本(replica)机制有什么好处呢
- zookeeper在kafka中的作用知道吗
- kafka如何保证消息的消费顺序
- kafka如何保证消息不丢失
- kafka判断一个结点是否还活着有哪两个条件
- producer是否直接将数据发送到broker的leader(主节点)
- kafka consumer是否可以消费指定分区的消息?
- kafka高效文件存储设计特点是什么
- partition的数据如何保存到硬盘
- kafka生产数据时数据的分组策略是怎样的?
- consumer是推还是拉?
- kafka维护消费状态跟踪的方法有什么?
- 用过(吗)哪些消费队列?
- kafka是什么,主要应用场景有哪些
- 和其他消息队列相比,kafka的优势在哪里
- 什么是producer、consumer、broker、topic、partition
- kafka的多副本机制了解吗
- kafka的多分区(partition)以及多副本(replica)机制有什么好处呢
- zookeeper在kafka中的作用知道吗
- kafka如何保证消息的消费顺序
- kafka如何保证消息不丢失
- kafka判断一个结点是否还活着有哪两个条件
- producer是否直接将数据发送到broker的leader(主节点)
- kafka consumer是否可以消费指定分区的消息?
- kafka高效文件存储设计特点是什么
- partition的数据如何保存到硬盘
- kafka生产数据时数据的分组策略是怎样的?
- consumer是推还是拉?
- kafka维护消费状态跟踪的方法有什么?
消息队列
用过(吗)哪些消费队列?*
kafka是什么,主要应用场景有哪些
kafka是一个分布式流式处理平台。
流平台具有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是kafka被归类为消息队列的原因
- 容错的持久方式存储记录消息流:kafka会把消息持久化到磁盘,有效避免了信息丢失的风险
- 流式处理平台:在消息发布的时候进行处理,kafka提供了一个完整的流失处理类库
kafka主要有两大应用场景:
- 消息队列:建立实时流数据管道,可靠的再系统或应用程序之间获取数据。
-
和其他消息队列相比,kafka的优势在哪里
我们现在经常提到kafka的时候已经默认它是一个非常优秀的消息队列了,也经常会拿它跟rocketMQ、rabbitMQ对比。我觉得kafka相比其他消息队列主要的优势如下:
极致的性能: 基于scala和java语言开发,设计中大量使用了批量处理和异步的思想,最高可以处理千万级别的消息
- 生态系统兼容性好:kafka与周边生态系统的兼容性是最好的,尤其是在大数据和流计算领域。
实际上在早期的时候,kafka并不是一个合格的消息队列,早期的kafka在消息队列领域就像是一个衣衫褴褛的孩子,功能不完备并且有一些小问题比如丢失消息、不保证可靠性等。当然,这也和LinkedIn最早开发kafka用于处理海量的日志有很大关系,人家最开始本来就不是为了作为消息队列。
什么是producer、consumer、broker、topic、partition
kafka将生产者发布的消息发送到Topic(主题)中,需要这些消息的消费者可以订阅这些Topic(主题)。kafka比较重要的几个概念:
- Producer(生产者):产生消息的一方
- Consumer(消费者):消费消息的一方
- Broker(代理):可以看做是一个独立的kafka实例。多个kafka Broker 组成一个kafka cluster。
- Topic(主题):producer将消息发送到特定的主题,consumer通过订阅特定的topic来消费消息
partition(分区):partition属于topic的一部分。一个topic可以有多个partition,并且同一个topic下的partition可以分布在不同的broker上,这就表明一个topic可以横跨多个broker。这正如我上面所画的一样
kafka的多副本机制了解吗
kafka为分区引入了多副本(replica)机制。分区中的多个副本之间会有一个叫做leader的家伙,其他副本成为follower。我们发送的消息会被发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步。
生产者和消费者只与leader副本交互。你可以理解为其他副本只是leader副本的拷贝,他们的存在只是为了保证消息存储的安全性。当leader副本发生故障时会从follower中选举出一个leader,但是follower中如果有和leader同步程度达不到要求的参加不了leader的竞选。kafka的多分区(partition)以及多副本(replica)机制有什么好处呢
kafka通过给特定topic指定多个partition,而各个partition可以分布在不同的broker上,这样便能提供比较好的并发能力(负载均衡)
partition可以指定对应的replica数,这也极大的提高了消息存储的安全性和容灾能力,不过也相应地增加了所需要的存储空间。
zookeeper在kafka中的作用知道吗
broker注册:在zookeeper上会有一个专门用来进行broker服务器列表记录的节点。每个broker在启动时,都会到zookeeper上进行注册,即到/brokers/ids下创建属于自己的节点。每个broker就会将自己的ip地址和端口等信息记录到该节点中去。
- topic注册:在kafka中,同一个topic的消息会被分成多个分区并将其分布在多个broker上,这些分区信息及与broker的对应关系也都是由zookeeper在维护。比如我创建了一个名为my-topic的主题并且它有两个分区,对应到zookeeper中会创建这些文件夹:
- /brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1
负载均衡:上面也说过了Kafka通过给特定topic指定多个partition,而各个partition可以分布在不同的broker上,这样便能提供比较好的并发能力。对于同一个topic的不同partition,kafka会尽力将这些partition分布到不同的broker服务器上。当生产者产生消息后也会尽量投递到不同broker的partition里。当consumer消费的时候,zookeeper可以根据当前的partition数量以及consumer数量来实现动态负载均衡。
kafka如何保证消息的消费顺序
我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了两个消息,这两个消息对应的操作分别对应的数据库操作时:
更改会员等级
- 根据会员等级计算订单价格
- 假如这两条消息的消费顺序不一样造成的最终结果就会截然不同
kafka中partition是真正保存消息的地方,我们发送的消息都被存放在了这里。而我们的分区又存在于topic这个概念中,并且我们可以给特定的topic指定多个partition。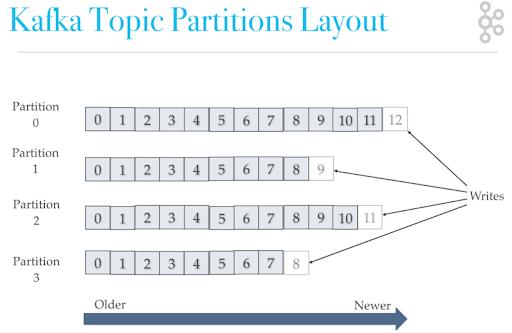
每次添加消息到partition的时候都会采用尾加法,如上图所示。kafka只能为我们保证partition中的消息有序。
消息在被追加到partition的时候都会分配一个特定的偏移量(offset)。kafka通过偏移量来保证消息在分区内的顺序性。所以,我们就有一种简单的保证消费顺序的方法:1个topic只对应一个partition。这样当然可以解决问题,但是破坏了kafka的设计初衷。kafka中发送1条消息的时候,可以指定topic、partition、key、data 这4个参数。如果你发送消息的时候指定了partition的话,所有消息都会被发送到指定的partition。并且同一个key的消息可以保证只发送到同一个partition,这个我们可以采用表/对象的id来作为key
总结一下,对于如何保证kafka中消息消费的顺序,有了一下两种方法
- 1个topic对应一个partition
-
kafka如何保证消息不丢失
生产者丢失信息的情况
生产者(producer)调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是kafka生产者使用send方法发送消息实际上是异步操作,我们可以通过get()方法获取调用结果,但是这样也让他变为同步操作
消费者丢失消息的情况
我们直到消息在被追加到partition的时候都会被分配一个特定的偏移量。偏移量标识consumer当前消息到的partition所在的位置。kafka通过偏移量可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到了这个消息准备进行消费的时候,突然挂掉了,消息实际上并没有被消费,但是offset已经被自动提交了。
解决办法也比较粗暴,就是关闭自动提交offset,每次在真正消费完信息之后再手动提交offset。但是,这样又会带来消息被重新消费的问题。比如你刚消费完还没提交offset就挂掉了,那么这个消息理论上就会被消费两次。kafka判断一个结点是否还活着有哪两个条件
节点必须可以维护和zookeeper的链接,zookeeper通过心跳机制检查每个节点的链接
如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
producer是否直接将数据发送到broker的leader(主节点)
producer直接将数据发送到broker的leader(主节点),不需要在多个节点进行分发。为了帮助producer做到这点,所有的kafka节点都可以及时的告知:哪些节点是活动的,目标topic目标分区的leader在哪。这样producer就可以直接将消息发送到目标地方了。
kafka consumer是否可以消费指定分区的消息?
kafka consumer消费消息时,向broker发出“fetch”请求去消费特定分区的消息,consumer指定消息在日志中的偏移量,就可以消费从这个位置开始的消息,consumer拥有了offset的控制权,可以向后回滚重新去消费之前的消息,这是很有意义的。
kafka高效文件存储设计特点是什么
kafka把topic中一个partition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完的文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作
- 通过index文件稀疏存储,可以大幅降低index文件元数据占用空间大小
partition的数据如何保存到硬盘
topic中的多个partition以文件夹的形式保存到broker,每个分区序号从0递增,且消息有序
partition文件下有多个segment(xxx.index, xxx.log)
segment文件里的大小和配置文件大小一致可以根据要求修改,默认为1G。如果大小大于1G时,会滚动一个新的segment,并且以上一个segment最后一条消息的偏移量命名kafka生产数据时数据的分组策略是怎样的?
生产者决定数据产生到集群的哪个partition中,每一条消息都是以(key,value)格式,key是由生产者发送数据传入,所以生产者(key)决定了数据产生到集群的哪个partitionconsumer是推还是拉?
producer将消息推送到broker,consumer从broker拉取消息。如果是push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由于broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终kafka还是选取了传统的pull模式。kafka维护消费状态跟踪的方法有什么?
大部分消息系统在broker端维护消息被消费的记录:一个消息被分发到了consumer后,broker就马上进行标记或等待consumer的通知后进行标记。这样也可以在消息在消费后马上就删除以减少空间占用。

若有收获,就点个赞吧
0 人点赞
