数据库调优
数据库调优目标
- 尽可能 节省系统资源 ,以便系统可以提供更大负荷的服务。(吞吐量更大)
- 合理的结构设计和参数调整,以提高用户操作 响应的速度 。(响应速度更快)
- 减少系统的瓶颈,提高MySQL数据库整体的性能。
如何定位调优问题
- 用户反馈
- 日志分析
- 服务器资源监控
- 数据库内部监控
- 其他:比如事务、锁等待进行监控
调优的维度和步骤
- 数据库调优的对象是整个数据库管理系统,不仅包含SQL语句,还包含数据库的部署配置、架构等等。
选择合适的数据库
- 对事务处理以及安全性要求较高可以选择商用的数据库产品
- 对于MySQL数据库,需要根据具体业务选择具体的存储引擎
优化表设计
- 尽量遵循第三范式。让数据结构更加清晰规范,减少冗余字段
- 尽量减少多表联合查询的方式
- 表字段数据类型的选择,关系到查询效率的高低以及存储空间的大小。一般来说,可以采用数值类型就不要用字符类型;字符长度尽可能短;对于字符类型,长度固定使用CHAR,长度不固定就用VARCHAR
优化逻辑查询
- 对SQL语句进行优化,比如子查询优化、连接消除等等
优化物理查询
- 正确使用索引
- 使用Redis作为缓存,避免每次都查询数据库
库级优化
- 读写分离
- 分库分表
MySQL服务器优化
优化服务器硬件
- 配置较大的内存:通过增加缓冲区容量减少磁盘IO
- 配置高速磁盘系统:减少读盘等待时间,提高响应速度
- 合理分布磁盘IO:将磁盘IO分散到多个设备上,减少资源竞争
- 配置多处理器:提升MySQL并发能力
优化MySQL参数
innodb_buffer_pool_size:这个参数是Mysql数据库最重要的参数之一,表示InnoDB类型的 表 和索引的最大缓存 。它不仅仅缓存 索引数据 ,还会缓存 表的数据 。这个值越大,查询的速度就会越快。但是这个值太大会影响操作系统的性能。key_buffer_size:表示 索引缓冲区的大小 。索引缓冲区是所有的 线程共享 。增加索引缓冲区可以得到更好处理的索引(对所有读和多重写)。当然,这个值不是越大越好,它的大小取决于内存的大小。如果这个值太大,就会导致操作系统频繁换页,也会降低系统性能。对于内存在 4GB 左右的服务器该参数可设置为 256M 或 384M 。table_cache:表示 同时打开的表的个数 。这个值越大,能够同时打开的表的个数越多。物理内存越大,设置就越大。默认为2402,调到512-1024最佳。这个值不是越大越好,因为同时打开的表太多会影响操作系统的性能。sort_buffer_size:表示每个 需要进行排序的线程分配的缓冲区的大小 。增加这个参数的值可以提高 ORDER BY 或 GROUP BY 操作的速度。默认数值是2 097 144字节(约2MB)。对于内存在4GB左右的服务器推荐设置为6-8M,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 6 = 600MB。join_buffer_size = 8M:表示 联合查询操作所能使用的缓冲区大小 ,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。read_buffer_size:表示 每个线程连续扫描时为扫描的每个表分配的缓冲区的大小(字节) 。当线程从表中连续读取记录时需要用到这个缓冲区。SET SESSION read_buffer_size=n可以临时设置该参数的值。默认为64K,可以设置为4M。innodb_flush_log_at_trx_commit:表示 何时将缓冲区的数据写入日志文件 ,并且将日志文件写入磁盘中。该参数对于innoDB引擎非常重要。该参数有3个值,分别为0、1和2。该参数的默认值为1。- 值为 0 时,表示 每秒1次 的频率将数据写入日志文件并将日志文件写入磁盘。每个事务的commit并不会触发前面的任何操作。该模式速度最快,但不太安全,mysqld进程的崩溃会导致上一秒钟所有事务数据的丢失。
- 值为 1 时,表示 每次提交事务时 将数据写入日志文件并将日志文件写入磁盘进行同步。该模式是最安全的,但也是最慢的一种方式。因为每次事务提交或事务外的指令都需要把日志写入(flush)硬盘。
- 值为 2 时,表示 每次提交事务时 将数据写入日志文件, 每隔1秒 将日志文件写入磁盘。该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失。
innodb_log_buffer_size:这是 InnoDB 存储引擎的 事务日志所使用的缓冲区 。为了提高性能,也是先将信息写入 Innodb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。max_connections:表示 允许连接到MySQL数据库的最大数量 ,默认值是 151 。如果状态变量connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections 的值。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。这个连接数 不是越大 越好 ,因为这些连接会浪费内存的资源。过多的连接可能会导致MySQL服务器僵死。back_log:用于 控制MySQL监听TCP端口时设置的积压请求栈大小 。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 对于Linux系统推荐设置为小于512的整数,但最大不超过900。thread_cache_size: 线程池缓存线程数量的大小 ,当客户端断开连接后将当前线程缓存起来,当在接到新的连接请求时快速响应无需创建新的线程 。这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。那么为了提高性能可以增大该参数的值。默认为60,可以设置为120。wait_timeout:指定 一个请求的最大连接时间 ,对于4GB左右内存的服务器可以设置为5-10。interactive_timeout:表示服务器在关闭连接前等待行动的秒数。
优化数据库结构
拆分表:冷热数据分离
- 拆分表的思路是:把一个包含很多个字段的表拆分成2个或者多个相对较小的表。原因是,表中某些字段的操作频率很高(热数据),经常进行查询或者更新操作,而另外一些字段使用频率却很低(冷数据)。
- 冷热数据分离,减小表的宽度。如果都放在一个表里面,每次将表加载进内存中,会消耗更多的资源。
- 目的是:减少磁盘IO,保证热数据的内存缓存命中率。更有效地利用缓存,避免读入无用的冷数据。
增加中间表
- 对于经常进行JOIN的表,将两个表中经常使用的字段拿出来放到中间表中,避免每次取数据都需要进行表连接
大表优化
当单表数据过大的时候,数据库CRUD性能会明显下降。需要采取一些措施:
限定查询范围,比如查询历史数据添加时间范围
读写分类:主库负责写,从库负责读
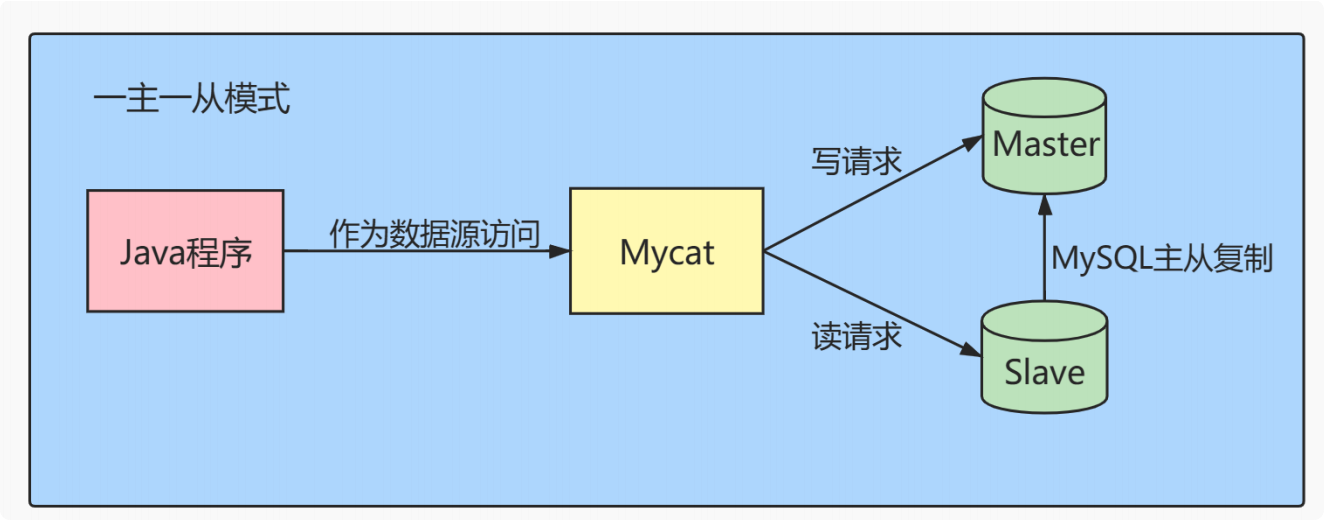
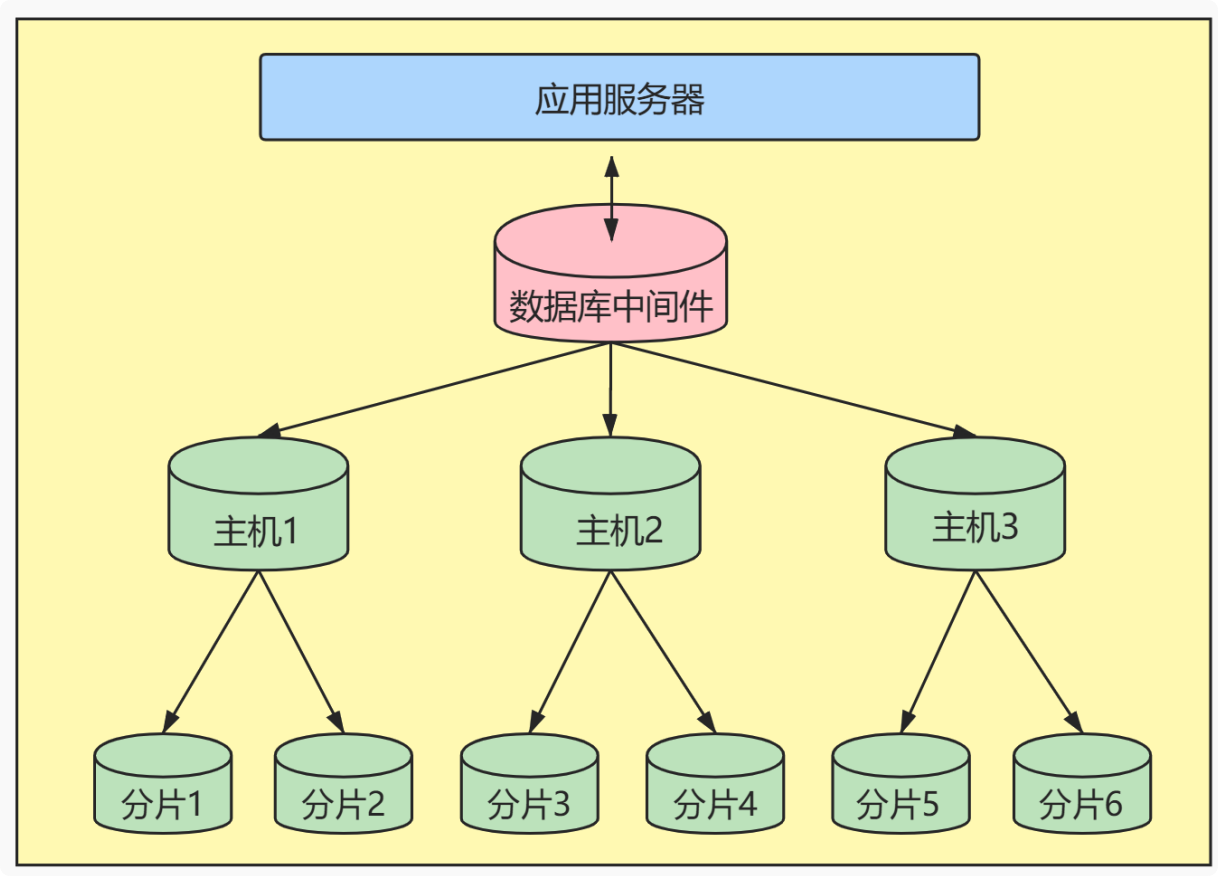
分库分表
- 垂直拆分
分库:将数据库中的表按照业务分布在不同的服务器上
- 垂直拆分
分表:将一张数据表拆分成多张数据表,比如前面的冷热数据分离
优点:使列数据变小,在查询时减少读取的Block数,减少IO次数。简化表的结构,易于维护
缺点:主键会出现冗余,需要管理冗余列,事务将变得复杂等等问题。
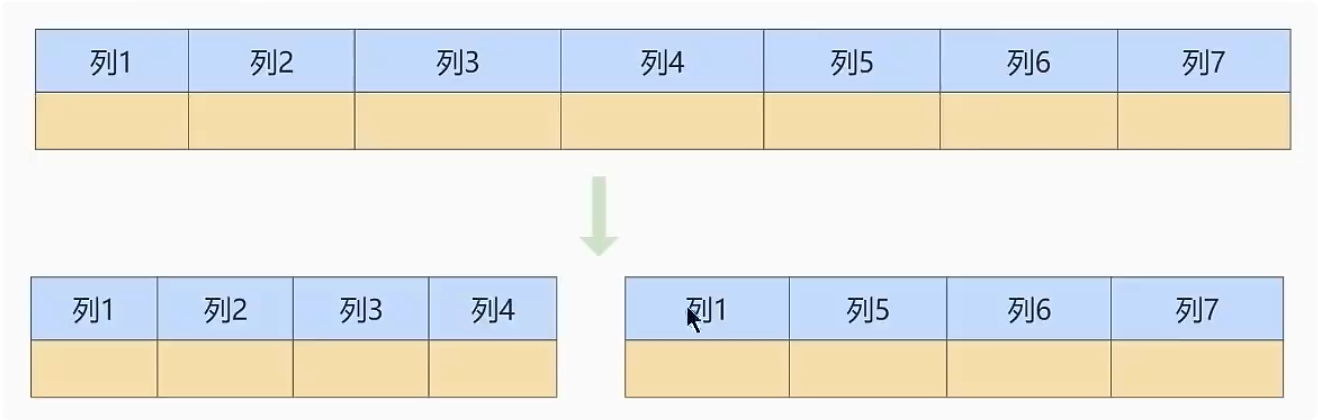
- 水平拆分

若有收获,就点个赞吧
0 人点赞
