你好,我是你的数据库老师周彦伟,欢迎来到第 10 课时“MySQL 亿级数据库项目实战”,这是本系列课程的最后一课时,本课时的主要内容包含 MySQL 典型数据库架构介绍、MySQL 主流数据库架构对比等理论性知识,然后从“订单、用户”两个项目实战,抛砖引玉,介绍亿级互联网业务数据库项目如何设计。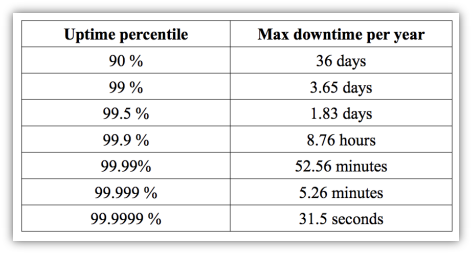
MySQL 典型数据库架构
数据库架构
我们想要更好地规划和设计 MySQL 数据库架构,首先需要了解典型的数据库架构,它通常由三部分组成:
数据库[原生]架构
高可用组件
中间件
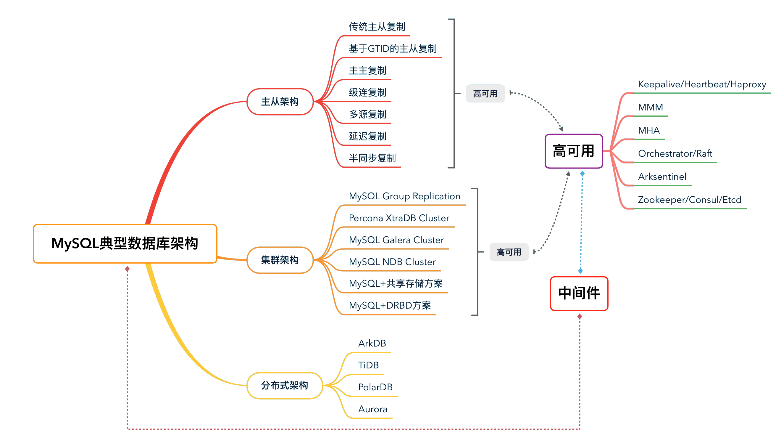
然而,数据库架构又可以分为三大类:主从架构、集群架构和分布式架构。在主从架构类别中,又可以分 7 小类,分别是。
传统主从复制,有时候也称为:异步复制(希望大家再复习下 MySQL 中的各种存储引擎,要注意它们的特性)。
基于 GTID 的主从复制,从 MySQL 5.6 版本后,推荐使用这种方式的复制,原因前面的课程中已经有讲解。
主主复制,这个还有不少传统企业仍在使用。
级连复制,面试的时候特别容易问到关于复制的各种变换,用的就是级连复制,注意技巧,工作中也经常用。
多源复制,MySQL 5.7 版本的一个特性,在某些特殊场景中会用到。
延迟复制,备份中会用到,尤其是当数据量特别大的情况。
半同步复制,对数据一致性要求比较高的业务场景,可以考虑用。
在集群架构类别中,又可以分为 6 小类,分别是:
MySQL Group Replication;
Percona XtraDB Cluster;
MySQL Galera Cluster;
MySQL NDB Cluster,有时候也称为 MySQL Cluster;
MySQL + 共享存储方案;
MySQL + DRBD 方案。
在分布式架构类别中,又可以分为 2 小类,分别是:
基于分布式事务的数据库,如 Google Cloud Spanner 和 TiDB。
基于分布式存储的数据库,如极数云舟的 ArkDB、Aurora、PolarDB。
数据库高可用
在前面第 7 课时中,我们详细介绍了几种常用的 MySQL 数据库高可用解决方案,这里再给大家罗列出来了,如果这里列的在前面的课程中没有介绍到,大家可以自行去学习。主要有下面 6 种:
Keepalive、Heartbeat、Haproxy;
MMM;
MHA;
Orchestrator、Raft;
极数云舟的 Arksentinel;
Zookeeper、Consul、Etcd。
数据库中间件
关于数据库中间件,第 9 课时中有详细介绍,这里不再赘述了。
在做架构设计时,一方面,要提醒大家的是:数据库架构、数据库高可用组件和数据库中间件既可以独立使用又可以彼此配合使用。另一方面,要提醒大家了解的是,我们常说的服务的可用性能达到多少个 9,那么它们各自允许服务宕机的具体时间又是多少呢?
一个 9(90%),全年 36 天。
两个 9(99%),全年 3.65 天。
两个 9.5(99.5%),全年 1.83 天。
三个 9(99.9%),全年 8.76 天。
四个 9(99.99%),全年 52.56 分钟。
五个 9(99.999%),全年 5.26 分钟。
六个 9(99.9999%),全年 31.5 秒。
主从架构
下面分别介绍 MySQL 的各种数据库架构。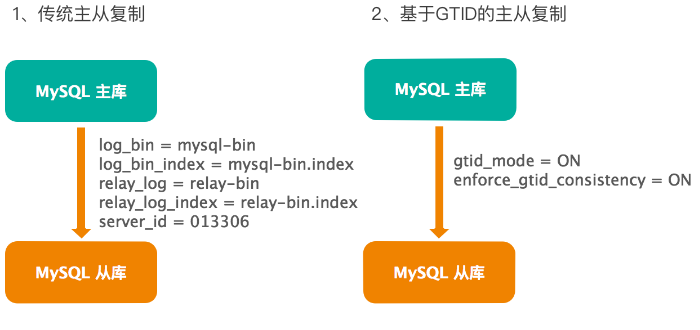
第一个是传统主从复制,架构简单,部署方便,注意配置必要的参数,如开启 binlog、relay_log 和 server_id,学习其基本原理,了解常见的故障和处理方法。
第二个是基于 GTID 的主从复制,开启的方法是设置 gtid_mode = ON 和 enforce_gtid_consistency = ON,要认真学习其原理和主从配置方式,以及故障处理的不同。
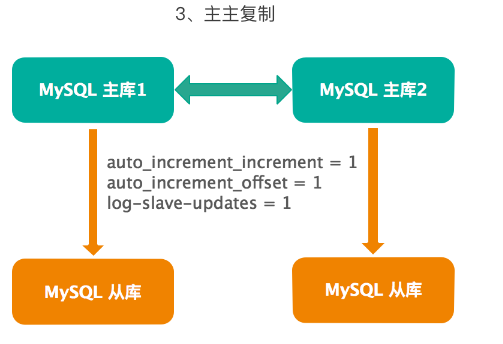
第三个是主主复制,这个主要是在前面两种架构的基础上的衍生,需要充分了解复制的基本原理。配置时,需要注意 auto_increment_increment、auto_increment_offset、log-slave-updates 三个参数的设置,互为主从的主库 1 和主库 2 的 auto_increment_increment 设置不同的值,比如分别设置为 1 和 2。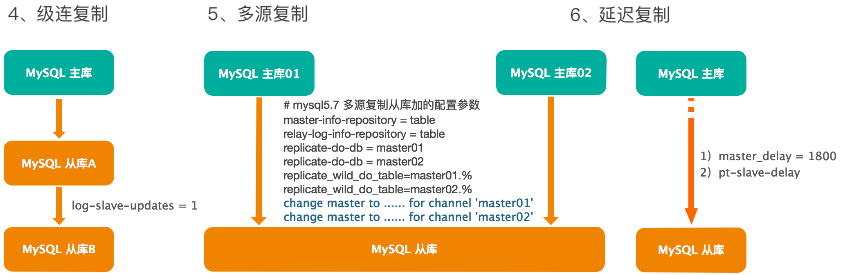
第四个是级连复制,其核心参数是 log-slave-updates,如图中的从库 A,必须要设置。要至少会实现在传统主从复制和基于 GTID 复制下的主从架构变换,比如把图中的从库 B 挂到主库上,实现 A-B-C 的级连为 A-B、A-C。
第五种是多源复制,多源复制在 MySQL 官方社区是从 5.7 版本开始有的,多源复制其实在MariaDB 中出现的时间要早。使用多源复制,一方面要注意其参数设置,另一方面要注意使用规范,如主从链接时的 change master 语句的不同。在参数设置时,需要在从库中配置:
master-info-repository = table
relay-log-info-repository = table
replicate-do-db = master01
replicate-do-db = master02
replicate_wild_do_table = master01.%
replicate_wild_do_table = master02.%
在主从复制时,命令如下:
change master to …… for channel ‘master01’
change master to …… for channel ‘master02’
第六种是延迟复制,这是一种特殊的复制,常用于备份的场景,其目的是让复制结构中的从库允许延后多长时间(单位:秒)从主库进行复制,这在数据量特别大时(如 TB 级),是很有用的。使用时有两种实现方式,一种是设置 master_delay=1800,这个参数在较新的版本中才有。另一种是用 Percona 公司开发的 pt-slave-delay 工具实现。如果在生产环境中,有许多需要设置延迟复制的情况,建议用后者,方便集中统一管理。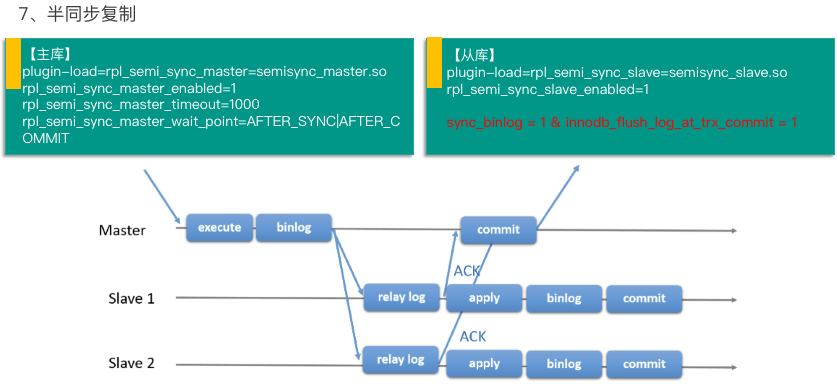
第七种是半同步复制,这个是需要重点关注的,面试中被问的也是最多的,它是通过插件的方式工作在数据库中,使用时,需要在主库和从库分别设置。
在主库上:
plugin-load=rpl_semi_sync_master=semisync_master.so
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
rpl_semi_sync_master_wait_point=AFTER_SYNC|AFTER_COMMIT
在从库上:
plugin-load=rpl_semi_sync_slave=semisync_slave.so
rpl_semi_sync_slave_enabled=1
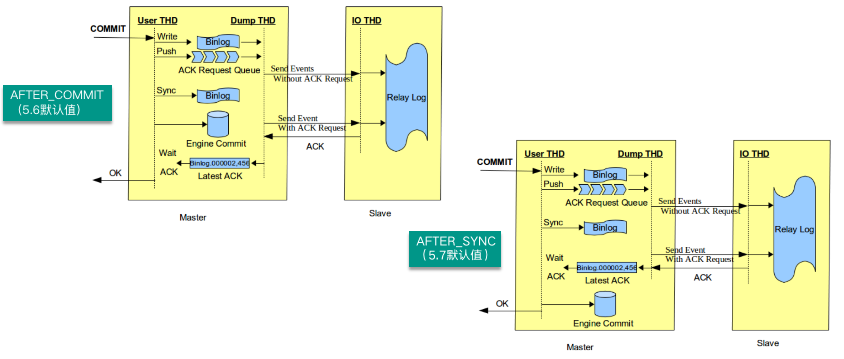
这里需要特别注意 AFTER_SYNC 和 AFTER_COMMIT 模式的区别,在 MySQL 5.7 版本以后,默认采用 AFTER_SYNC 模式,这种方式结合 MySQL 中“双 1”设置,即sync_binlog = 1、innodb_flush_log_at_trx_commit = 1 配合使用的场景在交易系统或者对数据一致性要求比较高的场景中被推荐使用。
集群架构
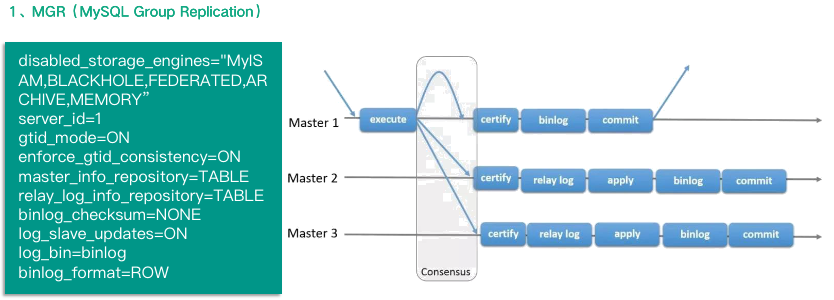

下面开始介绍六种集群架构,其中 MGR、PXC 或 MGC 在前面的课程中有非常详细的介绍,这里简单带过。首先是 MGR,即 MySQL Group Replication,是 MySQL 5.7 版本出现的新特性,是 MySQL 官方于 2016 年 12 月推出的一个全新的高可用与高扩展的解决方案。它提供了高可用、高扩展、高可靠的 MySQL 集群服务。MGR 分单主模式和多主模式。
在单主模式下, 组复制具有自动选主功能,每次只有一个 server 成员接受读写。
在多主模式下,所有的 server 成员都可以同时接受读写。
MGR 目前还处在稳定性验证阶段,在生产环境中使用时,建议使用单主模式。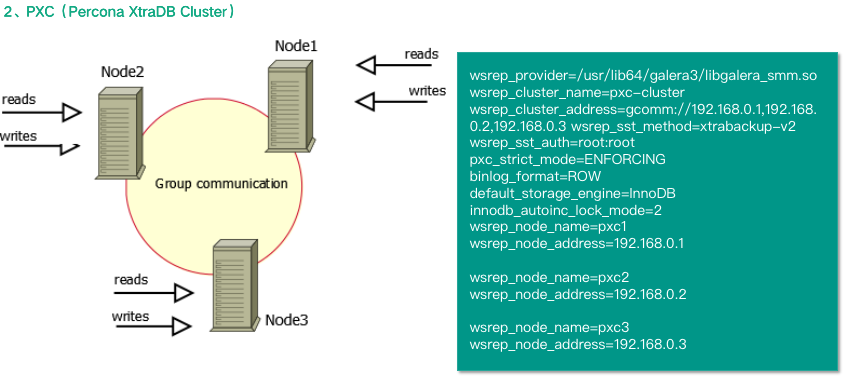
第二种是 PXC,即 Percona XtraDB Cluster,从名称中可以看出,这是 Percona 公司推出的一个高可用与高扩展的解决方案,它是以 codership 公司研发的 galera cluster 插件方式为 MySQL 提供高可用集群解决方案的,跟 PXC 类似的产品还有 MariaDB Cluster。特点是具有高可用性,方便扩展,并且可以实现多个 MySQL 节点间的数据同步复制与读写,可保障数据库的服务高可用及数据强一致性。跟 MGR 一样,也分单主模式和多主模式。
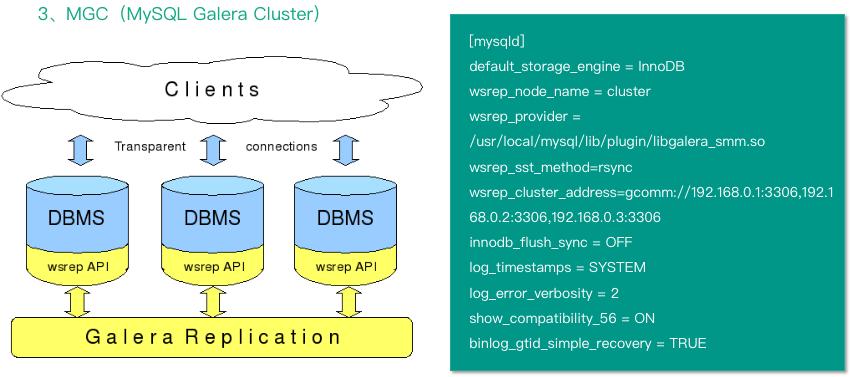
第三种是 MGC,即 MySQL Galera Cluster,这是 codership 公司开发的数据库高可用插件,是一种新型的数据不共享的高度冗余的高可用方案,通常以 PXC 或 MariaDB Cluster 的方式使用,当然也可以独立使用,就是自己配置。相比传统的主从复制架构,Galera Cluster 解决的最核心问题是在三个实例节点之间,它们能以对等的,multi-master(多主)并存的方式存在,在多节点同时写入的时候,能够保证整个集群数据的一致性、完整性与正确性。具有支持多主架构、同步复制、并发复制、故障切换、热插拔、自动节点克隆和对应用透明的特点。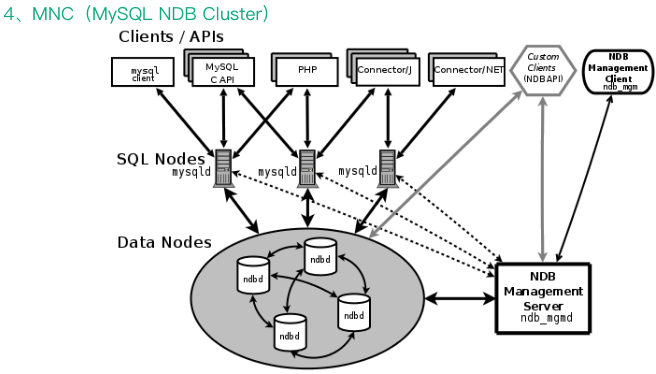

第四种是 MNC,即 MySQL NDB Cluster,有时又称为 MySQL Cluster,是 MySQL 官方推出的一个适用于分布式计算环境的高可用性、高冗余的 MySQL 集群解决方案。主要由使用 NDB 引擎的 SQL 节点、数据存储节点和 NDB 管理节点三部分组成。NDB 是一个内存存储引擎,提供高可用的数据持久化功能,可以配置故障转移和负载均衡等策略,因其管理复杂,目前在国内除中国移动等个别公司在使用外,使用的相对比较少,国外使用的比较多,尤其是电信行业。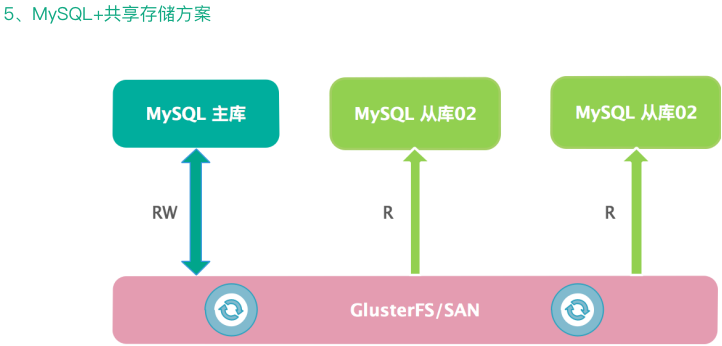
第五种是共享存储方案,MySQL 主从数据库共享同一份数据,但是在同一个集群中,只有一个库提供读写服务,其他的库提供只读服务,其性能也受限于分布式共享存储,在实际环境中基于 SAN 或 GlusterFS 的应用较多,但是前者成本昂贵,生产环境中使用的不多。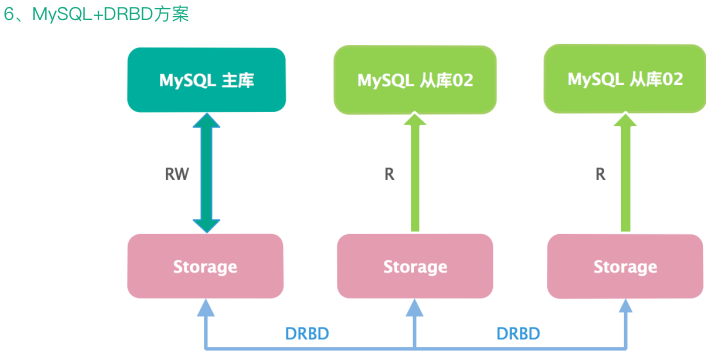
第六种是基于 DRBD 的方案,DRBD 的全称是 Distributed ReplicatedBlock Device(分布式块设备复制),是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。它的功能实现是由 Linux 系统中的 DRBD 内核模块和相关脚本构成的,用来构建存储高可用集群。跟上面共享存储方案有异曲同工之妙,只是实现方式有所不同。也是一写多读,生产中基本不用。
分布式架构
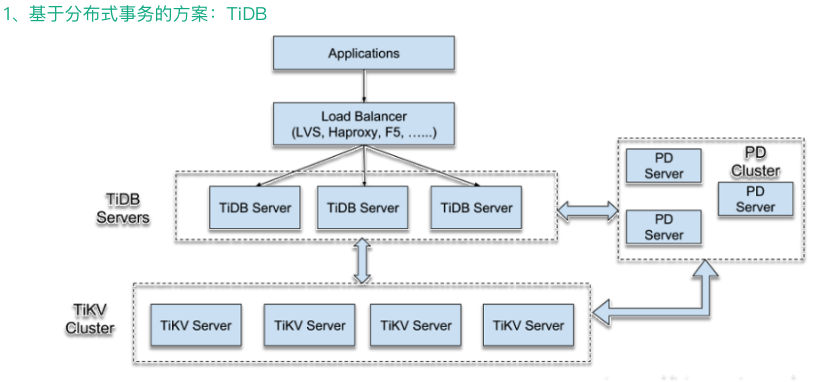
第一种是基于分布式事务的方案,以 TiDB 为例。
第二种是基于分布式存储的方案,以 ArkDB 为例。
在第 9 课中已经详细介绍了这两种方案,这里不一一赘述了,大家对其有所了解即可。
MySQL 典型数据库架构方案对比

前面简单介绍了 MySQL 使用过程中存在的三大类共 15 种架构方案,这里整理归纳对其中 5 种典型架构进行对比,分别从部署配置、运维管理(易用性)、高可用、性能、复制延迟、多点写入支持、数据一致性、扩展性、大数据量支持、性能比、跨云支持等方面对比,仅一家之言,供参考。
亿级互联网业务数据库设计
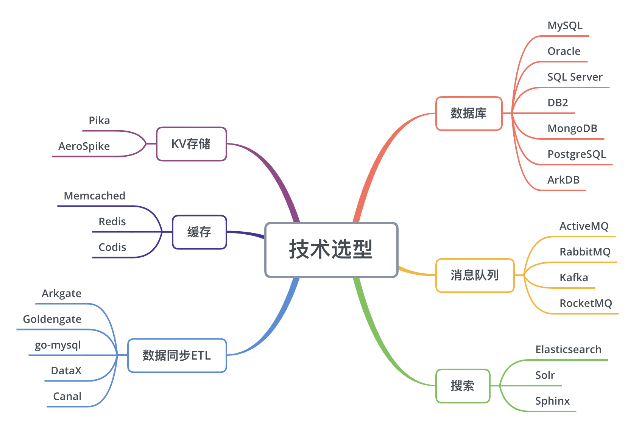
在进行数据库架构设计之前,我们需要了解普适的数据库技术选型,显然这里没有进行扩展,如果想要了解数据库家族产品,可以回到开篇课了解更多内容。正所谓“工欲善其事,必先利其器”,“磨刀不误砍柴工”,了解了各种技术,有利于进行设计时的有的放矢。企业中常用的有:
数据库
MySQL
Oracle
SQL Server
DB2
MongoDB
PostgreSQL
ArkDB等
消息队列
ActiveMQ
RabbitMQ
Kafka
RocketMQ
MemcacheQ等
搜索引擎
ES
Solr
Sphinx等
KV存储
Pika
Aerospike等
缓存
Memcached
Redis
Codis等
数据同步ETL
Arkgate
Goldengate
go-mysql
DataX
Canal等
中间件
中间件在第9课中有详细介绍
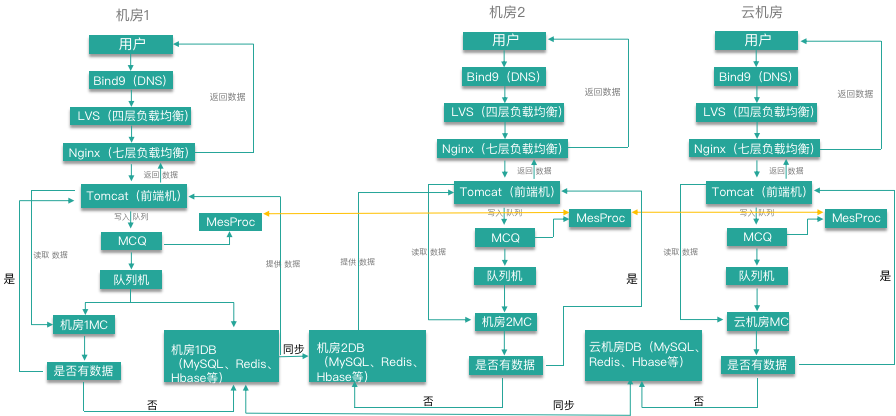
这里举一个生产环境的多数据中心的业务架构拓扑例子,很具有典型性,在这个例子中有两个本地机房和一个云机房(可以理解为公有云、行业云或自建私有云),我们着重关注一下业务后端资源(数据库)的部署,这是一个单写的多活的业务场景,显然机房 1 为核心机房,所有的业务数据都从机房 1 写入,大量的写操作通过消息队列异步更新到缓存和数据库中,数据库通过复制方式同步到其他两个机房提供读服务,每个机房有各自的缓存服务用于应对高并发的读请求,缓存的更新是在本地的数据库中,提供数据库的最终一致性。当然,如果业务中不存在数据更新冲突的可能,也可以实现多写的多活,比如外卖业务。对于一些特殊的业务场景,在三个数据中心中可以单独实现一套队列处理程序,从队列中抽取数据进行协同处理,比如抽取订单数据转存到 ES 中用于查询、大数据分析等操作。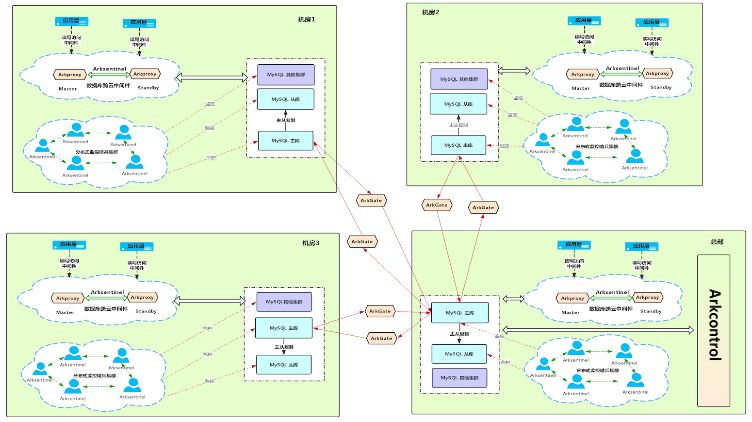
这里聚焦在 MySQL 数据库的两地三中心的规划和使用中,如图所示,在总部机房中,业务层通过中间代理层访问后端的 MySQL 数据库集群,这里说的 MySQL 的集群可以是前面介绍的任何一种 MySQL 集群。MySQL 集群的高可用通过分布式监控系统 Arksentinel 提供故障检测和故障切换。其他三个机房也有着相同的部署方案,四个机房之间的数据流通是通过数据库实时数据同步系统 Arkgate 来提供服务,完成数据在不同机房间的流通。
在一般的企业需求中,都是总部中心机房负责业务数据读写,而其他三个机房都是只读,但是对于一些特殊的场景,数据不存在冲突的场景,是可以实现多机房写入的,Arkgate 内部可以设置 ETL 冲突处理的逻辑,从而避免数据回环的产生。需要注意的是,在每个机房又可以有自己独立的 MySQL 集群,处理边缘业务或者一些特殊的业务,但是数据最终都要汇总和归档到总部中心机房进行持久化永久存储。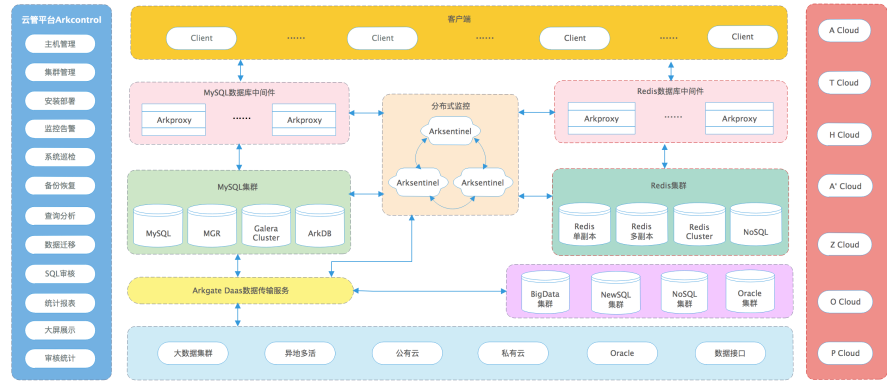
在总部数据中心图中,有一个组件是 Arkcontrol,它是一个数据库自动化运维管理平台。试想一下,动辄数百个实例的数据库或者是数百套数据库集群的资源,如果用传统的 Excel 方式手工管理,其工作量和维护成本有多高,一套可以管理多种数据库资源的管理平台的重要性显得格外重要,一方面可以破解企业内部复杂的数据库管理流程,极大地提高工作效率,降低企业成本;另一方面还能规避生产过程中数据库运维操作的安全性;再有就是可以快速构建起企业级数据库全维度的管理体系,让数据库的运行更具感知性。这需要在日后的工作中逐步积累,持续迭代,拥有对类似平台的研发能力,也是对新时代 DBA 的考核要求,起码要知道其实现原理。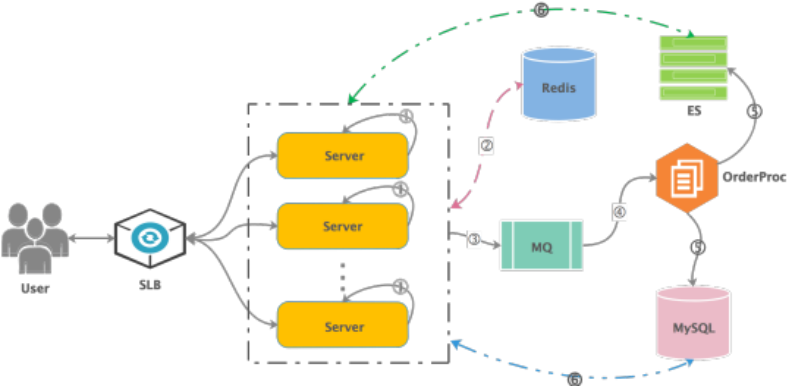
具体到一个订单业务场景中,比如:火车票、机票预定,大量用户的订单请求通过负载均衡分散路由到业务处理层 Server,业务处理层会先从预分配好的资源中进行分配,并做减库存、生成订单等系列操作,当某个 Server 的资源不足或分配完后,会从总库存 Redis 中进行调取,这里的 Redis 提供统一的库存管理,其目的是充分发挥 Redis 丰富的数据结构和高性能的特性。然后生产的订单和订单状态等信息写入消息队列 MQ,订单处理程序 OrderProc 接受并处理消息,分别存储到 MySQL 和 ES 中,存储到 MySQL 中是为了方便数据库的持久化存储,也会提供给 Server 做资源信息的查询使用,比如对账等。存储到 ES 中,是为了方便用户对订单进行查询,这里也包括对航班和车次、余票等信息的查询。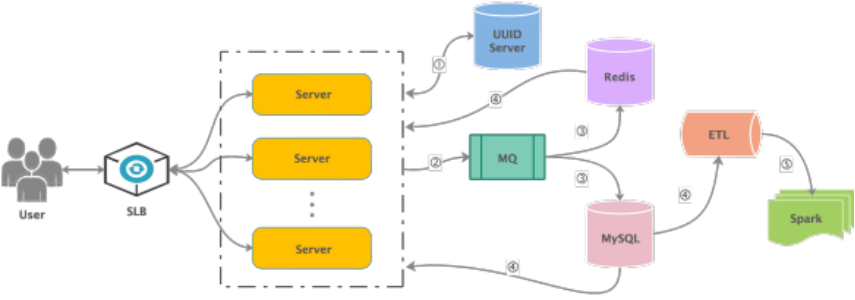
具体到一个用户业务场景中,比如微博粉丝、微信好友,大量的用户信息,包括用户注册、用户信息更新、好友绑定与解绑等信息的更新操作通过负载均衡分散路由到用户信息处理模块 Server 层,如果是用户新注册的话,会从 UUID Server 中请求分配一个新 UID 给这个用户,这个 UID 是永久性的并且是全局唯一的,比如微信有十几亿用户,那么就有十几亿对应的唯一 UID。然后各种大量复杂的请求通过消息队列处理程序处理后,存储到 Redis 和 MySQL 数据库中,比如好友列表,粉丝列表、关注列表、黑名单等存储在 Redis 中,MySQL 中存储全量的用户信息,包括用户昵称、用户名、用户图像、用户签名等。在微博或微信的社交业务中,现在也应用在更广泛的其他相关社交领域,有一种业务用户的“二度关系” ,二度关系是指用户与用户通过关注者为桥梁发现到的关注者之间的关系。目前微博通过二度关系实现了潜在用户的推荐。用户的一度关系包含了关注、好友两种类型,二度关系则得到关注的关注、关注的好友、好友的关注、好友的好友四种类型。这种典型业务有着巨大商业价值,故在各大社交领域大量使用,用户的信息数据,可以通过一个 ETL 从 MySQL 数据库中进行提取,存储到 HBase 中或其他大数据集群中供机器学习使用,如图中举例的 Spark 进行分析使用,生成用户画像等。
重点总结回顾
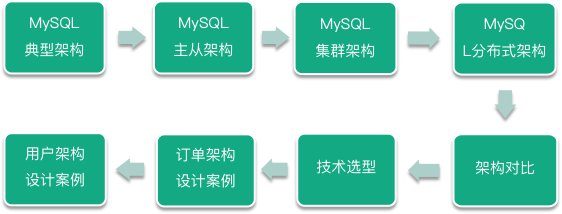
下面我们来回顾一下本课时学习到的知识,首先我们介绍了 MySQL 典型数据库架构,分为三大类 15 小类,然后分解了数据库架构设计中涉及的数据库架构、数据库高可用和数据库中间件三大组成部分,彼此独立又可以相互配合使用。然后再对典型数据库架构一一做了详细介绍,部分架构再指出了使用注意要点。紧接着重点梳理和归纳介绍了 5 种典型架构的对比;在最后的亿级互联网业务数据库设计部分,提出了要注意数据库技术选型的重要,然后分别从多数据中心架构拓扑介绍后端资源的部署和应用场景。最最后主要是从订单和用户这两个代表性业务进行展开说明,讲解了亿级互联网业务数据库设计的相关知识点。
通过本次课程的学习,你至少需要了解 MySQL 数据库架构的常用架构类型和各自优缺点以及应用场景,还需要了解各种架构类型的对比,方便指导数据库架构方案的选择,掌握必要的方式方法,在今后的工作中要逐步提高,能独立完成亿级互联网业务数据库的架构设计,需要多思考多总结,同时还需要不断进行理论与实践相结合的历练。至此,所有的课程内容到此结束,感谢大家的支持!感谢拉勾网的各位老师的全力配合与辛勤付出!

若有收获,就点个赞吧
0 人点赞
