统计学习及监督学习概论
监督学习
书中定义:从标注数据中学习模型的机器学习问题,是统计学习或机器学习的重要组成部分。监督学习主要用于分类、标注与回归问题
统计学习
概念
书中定义:是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测和分析的而一门学科。
统计学习是计算机通过运用数据及统计方法提高系统性能的机器学习。
统计学习的对象
统计学习的目的
通过构建概率统计模型实现对数据的预测和分析,尤其是未知数据的预测和分析。
统计学习的方法
基于数据构建概率统计模型从而对数据进行预测和分析。
实现统计学习方法的步骤
1.得到一个有限的训练数据集合(训练数据集)
2.确定包含所有可能的模型的假设空间,即学习模型的集合(这是说的是模型吗?比如tf,pytorch这种? 不是!!!)
2022.7.8更新补充:
https://zhuanlan.zhihu.com/p/159189617?utm_source=wechat_session
机器学习的准则:期望风险,经验风险,结构风险
假设空间:是假定的未知的隐射函数y = f(x) 或者条件概率分布 p(y|x),机器学习的目标是找到一个模型来近似真实映射函数  或真实条件概率分布
或真实条件概率分布  。由于我们不知道真实的映射函数
。由于我们不知道真实的映射函数  或条件概率分布
或条件概率分布  的具体形式,只能根据经验来确定一个假设函数集合
的具体形式,只能根据经验来确定一个假设函数集合  ,这个集合称为假设空间(hypothesis space)。
,这个集合称为假设空间(hypothesis space)。
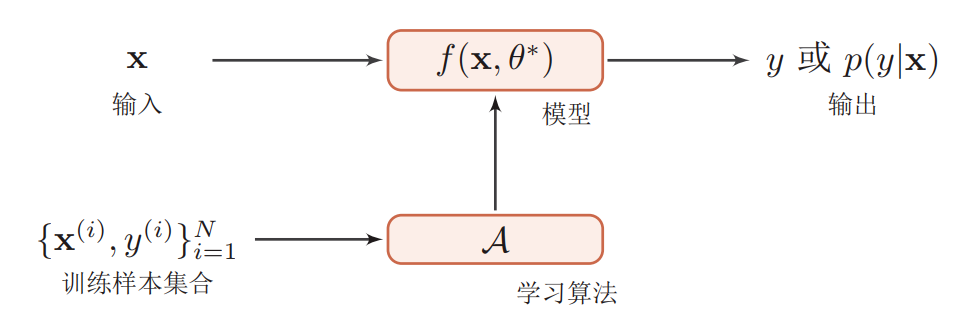
3.确定模型选择的准则,即学习策略
4.实现求解最优模型的算法,即学习的算法
5.通过学习方法选择最优模型(这几步是选取模型利用现有部分数据训练模型,并预测部分现有数据观察现象的过程吗)
6.利用学习的最优模型对数据进行预测或分析
统计学习的分类
基本分类
按模型分类
1.概率模型与非概率模型
2.线性模型与非线性模型
3.参数化模型与非参数化模型
按算法分类
在线学习与批量学习
按技巧分
1.贝叶斯学习
2.核方法
统计学习方法三要素
1.模型
2. 策略
风险函数与损失函数
经验风险最小化与结构风险最小化(不太理解!!!)
https://zhuanlan.zhihu.com/p/159189617?utm_source=wechat_session
3.算法
学习模型的具体计算方法
模型评估与模型选择
训练误差与测试误差
统计学习方法具体采用的损失函数未必是评估时使用的损失函数。
训练误差:是模型关于训练数据集的平均损失
测试误差:模型关于测试数据集的平均损失
训练误差对于判定给定的问题是不是一个容易学习的问题是有意义的,但本质是不重要。而测试误差反应了学习方法对于未知的测试数据集的预测能力,比较重要!!!
过拟合与模型选择
所选模型的复杂度比真模型更高,称为过拟合
模型选择时,不仅要考虑对已知数据的预测能力,而且还要考虑对未知数据的预测能力
正则化与交叉验证
正则化
模型选择的典型方法,是结构风险最小化策略的实现,是在经验风险上加一个正则化项或罚项,作用是选择经验风险与模型复杂度同时较小的模型。
在所有可能选择的模型中,能够很好的解释已知数据并且十分简单才是最好的模型
交叉验证
样本数据充足时可以随机的将数据集切分成
训练集
验证集
测试集
在数据不足时,为了选择好的模型,可以使用交叉验证。
思想:重复的使用数据,把给定的数据进行切分,将切分的数据集组合为训练集和测试集,在此基础上反复地进行训练、测试和模型选择。
简单交叉验证、
S折交叉验证:随机将已给数据切分为S个互补相交、大小相同的子集,然后利用S-1个子集的数据训练模型,利用余下的子集进行测试,并将此过程重复进行,最后选定S次评测中平均测试误差最小的模型
留一交叉验证:分成N个数据集,将N-1个数据作为训练集,剩一个作为测试集

若有收获,就点个赞吧
0 人点赞
