cache_t了解
缓存的什么?
cache_t中缓存的是方法的imp和sel通过哈希算法处理之后的key;
为什么要缓存?
在调用方法的时候,如果每次都要在类和父类(元类和元类的父类)中进行查找,是很耗时间的,所以每次找到这个方法,填充到cache中,这样下次调用,通过快速查找可以很快的找到,加快了运算处理速度。
cache_t结构

cache_t是一个结构体,其中包含三个属性:
_buckets**:bucket_t 结构体指针,也可以理解为指向一个数组(链表)的首地址;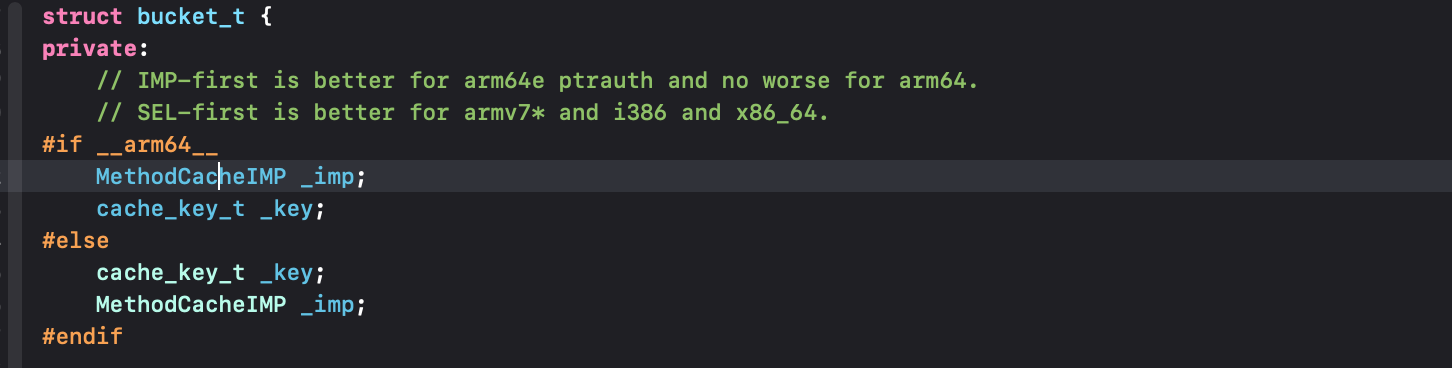
MethodCacheIMP:函数地址;
cache_key_t:这个可以认为是sel通过哈希算法将sel转为的整型key,这样读取运算比较方便、速度快;
_mask**:可以视为哈希算法的“盐”,可以认为是寻址bucket的一个必须条件,大小:总容量-1;
_occupied:表示当前占用的容量;
还有一个词需要知道:capacity:总容量;
缓存流程和原理
关于什么时候填充到缓存的了解,参考方法的查找流程,这里直接从调用cache填充的方法,通过源码来讲流程和原理。
主线流程分析
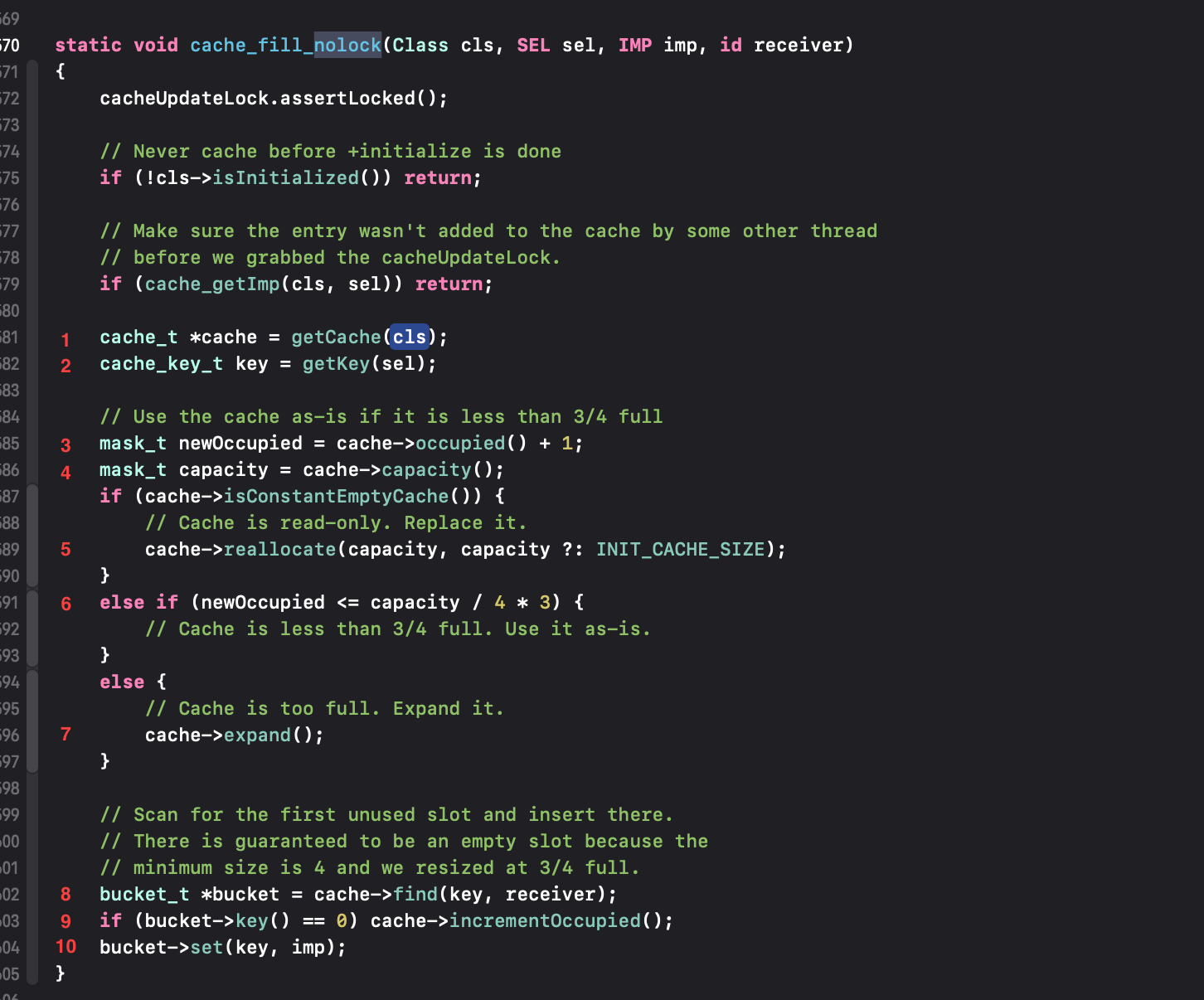
// Never cache before +initialize is doneif (!cls->isInitialized()) return;// Make sure the entry wasn't added to the cache by some other thread// before we grabbed the cacheUpdateLock.if (cache_getImp(cls, sel)) return;
这两句return可以直接过,就是做一步安全的判断。
下面根据序号开始讲解:
1、根据cls,拿到这个类的cache_t属性(类的结构中有cache_t属性);
cache_t *getCache(Class cls){assert(cls);return &cls->cache;}
2、通过哈希算法将“sel”转为“cache_key_t”类型即“uintptr_t”类型,在操作中比字符串的读取要方便;
cache_key_t getKey(SEL sel){assert(sel);return (cache_key_t)sel;}
3、拿到occupied并做“+1”的操作赋值给newOccupied,因为在这里我们要做缓存,占用需要加一,先拿到加一之后的占用量和总容量去做判断更安全;
4、拿到capacity总容量;
接下来开始对cache进行判断isConstantEmptyCache(),如果是空的就要申请开辟:
bool cache_t::isConstantEmptyCache(){returnoccupied() == 0 &&buckets() == emptyBucketsForCapacity(capacity(), false);}
5、cache空的,申请开辟—-reallocate(capacity, capacity ?: INIT_CACHE_SIZE);后边单独分析;
6、cache的缓存有一个原则,就是newOccupied <= capacity / 4 * 3 如果占用的不大于总容量的四分之三,就可以填充,如果占用的超过了就要扩充,四分之三防止占满导致溢出等一些问题;
7、占用的大于总容量的四分之三,需要扩容—-cache->expand();后边单独分析;
8、调用find()方法返回一个bucket的指针—-find();后边单独分析;
9、incrementOccupied()将占用加一,条件判断后边分析;
void cache_t::incrementOccupied(){_occupied++;}
10、为bucket赋值imp和key,这样,新的方法缓存完成。
主线思维就是这1-10,总结起来就是,找到cache,对cache的容量和占用进行判断,该开辟开辟,该扩容扩容,然后找到一个可以存储方法的bucket,然后给他里边的imp和key赋值,就完成了存储方法的操作。后边单独分析的,是为了先了解主线流程,再分开解剖。
开辟空间
reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
INIT_CACHE_SIZE 就是4
/* Initial cache bucket count. INIT_CACHE_SIZE must be a power of two. */enum {INIT_CACHE_SIZE_LOG2 = 2,INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2)};
看一下reallocate源码,然后就能理解两个参数,按照序号讲解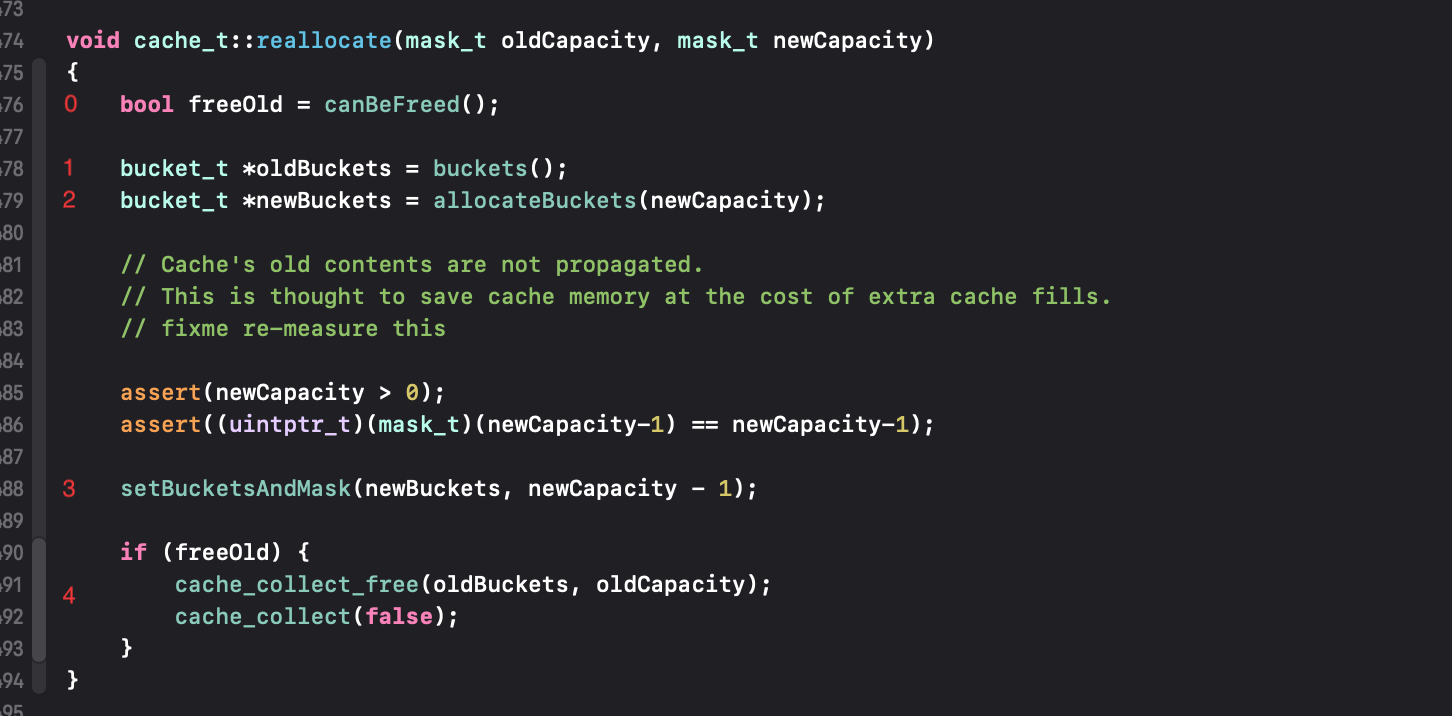
0、只要不是空的,就标记上,后边给他清空,看源码:
bool cache_t::canBeFreed(){return !isConstantEmptyCache();}
1、 拿到以前的bucket指针,直接将这个指针当做是数组的起始指针;
2、根据容量开辟新的空间,并返回指针,这个指针也就是新的一篇数组的起始指针;看下allocateBuckets:
根据容量开辟了一片新的内存(可以理解为一定尺寸的数组),并返回第一个指针;
开辟了新的之后,就要重置mask和bucket:
3、设置新的buckets和mask(新的mask就是容量减一),新的内存,占用_occupied为0;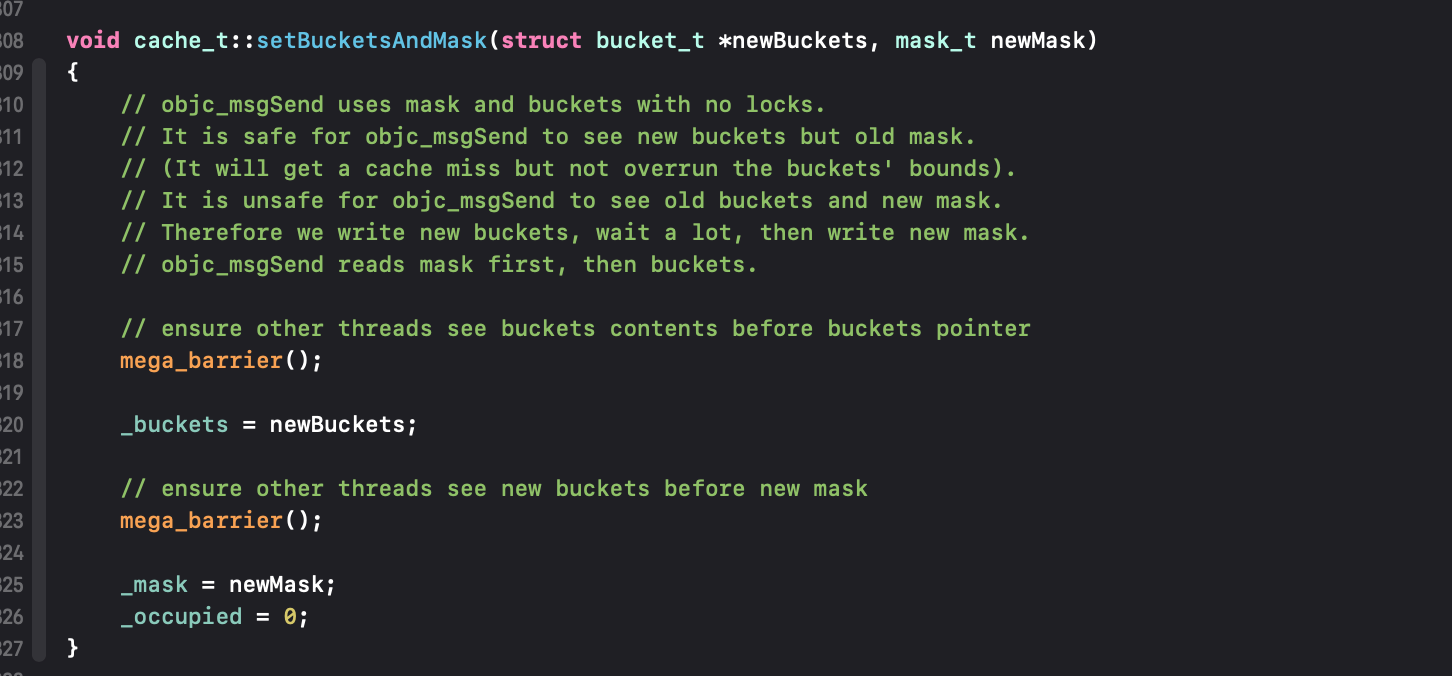
新的内存设置好了,以前的内存,如果被开辟的,占用过,留着就是浪费空间,所以就free,来到序号4。如果是首次开辟(freeOld = false)就无须释放。
扩容
当占用超出容量的四分之三,就要扩容:
看了源码是不是很简单,就是将原来的空间判断,进行2倍扩大,然后走reallocate(oldCapacity, newCapacity);释放旧的,开辟新的,上边讲到的freeOld就是针对这种情况。
在上边主线流程分析中调用reallocate方法的上边有一句注释:// Cache is read-only. Replace it.
所以这里要注意一点,当容量超出需要扩容的时候,并不是把原来的内存扩大,而是拿到即将要扩容的容量去开辟一个新的内存,并把以前的内存释放掉。
查找bucket
当判断完成,内存创建或者扩容的逻辑都走完了之后,就要找到bucket来进行填充了:
这个find()中主要就是一个寻找bucket的算法,看注释,然后计算或者跟一下就行,cache_next:
static inline mask_t cache_next(mask_t i, mask_t mask) {return (i+1) & mask;}
这里注意一点,在循环里边的if操作,通过b[i](b就是首地址,通过内存偏移来寻址找到下标为i的bucket)的key属性来判断,如果这个key和传进来的key一样,说明这个bucket用过,返回继续用,key为空,bucket没有用过,返回也可以用。这也就对应了主线流程分析中的序号9 incrementOccupied()方法之前的判断条件,如果返回的bucket以前用到过,直接刷新重新填充,这相当于没有新的占用,occupied无需加一。所以需要满足(bucket->key() == 0)的时候才做incrementOccupied()。之后对这个bucket进行填充。
总结
cache从开辟,判断容量,查找bucket,填充的整个流程就是这些。有两点需要注意:
1、cache缓存可以理解为是有一定容量的数组,每一个元素都是一个bucket,其中cache的buckets属性,就是这个数组的起始指针;
2、cache是只读的,当占用容量超过四分之三的时候,需要扩容。扩容并不是在原来的内存基础上扩大,而是,重新开辟一个新的大容量内存,将buckets指向它,并把原来的内存清空,完成替换的操作;

若有收获,就点个赞吧
0 人点赞
