1. 为什么要有索引
一般的应用系统,读大于写,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,是一些复杂的查询操作,因此查询效率格外重要,这个时候就要用到索引。
2. 索引是什么
官⽅介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯⼀一索引等,没有特别说明,默认都是使用 B+树 结构组织的索引。
2.1. 索引的优势和劣势
优势:
- 可以提高数据检索的效率,降低数据库的IO成本,类似于书的⽬目录。
- 通过索引列对数据进行行排序,降低数据排序的成本,降低了了CPU的消耗。
- 被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些。
- 如果按照索引列的顺序进行排序,对应order by语句句来说,效率就会提高很多。
- where 索引列在存储引擎层处理覆盖索引,不需要回表查询
劣势:
- 索引会占据磁盘空间
索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不仅要保存数据,还要保存或者更新对应的索引文件
3. 索引分类
3.1. 单列索引
普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值
- 主键索引:是一种特殊的唯一索引,不允许有空值
- 全文索引: 只有在MyISAM引擎、InnoDB(5.6以后)上才能使用,而且只能在CHAR,VARCHAR,TEXT类型字段上使⽤用全⽂文索引。
3.2. 组合索引
在表中的多个字段组合上创建的索引,组合索引的使用,需要遵循左前缀原则。一般情况下,建议使用组合索引代替单列索引(主键索引除外)
左前缀原则
索引(name,age,gendar),实际上是创建了三个索引。(name)、(name,age),(name,age,gendar),所以要使用组合索引,第一个字段必须使用
4. 索引的存储结构
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
MyISAM和InnoDB存储引擎:只⽀支持B+ TREE索引, 也就是说默认使用B+TREE,不能够更换
MEMORY/HEAP存储引擎:支持HASH和BTREE索引
Hash索引把数据以hash形式组织起来,因此当查找某一条记录的时候,速度非常快。但是因为hash结构,每个键只对应一个值,而且是散列的方式分布。所以它并不支持范围查找和排序等功能。 B+Tree是mysql使用最频繁的一个索引数据结构,是InnoDB和MyISAM存储引擎模式的索引类型。相对Hash索引,B+Tree在查找单条记录的速度比不上Hash索引,但是因为更适合排序等操作,所以它更受欢迎。毕竟不可能只对数据库进行单条记录的操作。
B树和B+树
参考网站 : https://segmentfault.com/a/1190000020416577
数据结构示例:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B树
B树又名平衡多路查找树(查找路径不只两个),不同于常见的二叉树,它是一种多叉树,我们常见的使用场景一般是在数据库索引技术里,大量使用者B树和B+树的数据结构。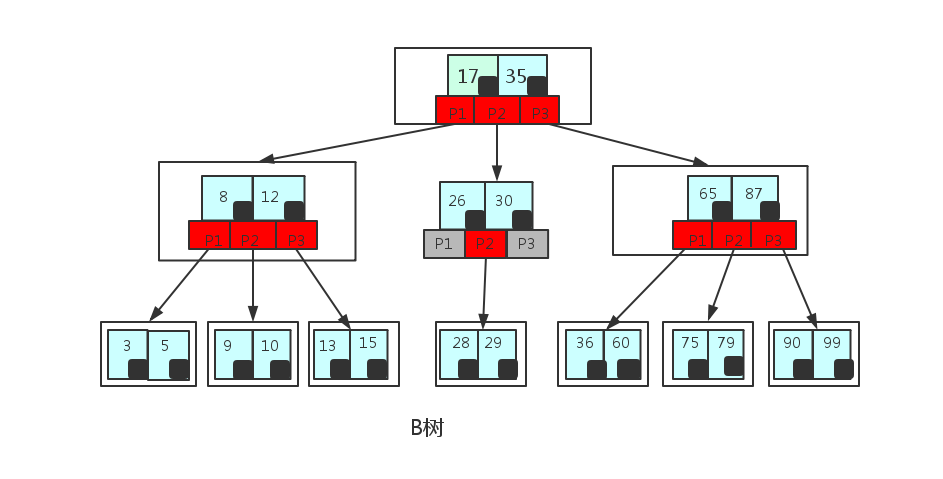
B树大多用在磁盘上用于查找磁盘的地址。因为磁盘会有大量的数据,有可能没有办法一次将需要的所有数据加入到内存中,所以只能逐一加载磁盘页,每个磁盘页就对应一个节点,而对于B树来说,B树很好的将树的高度降低了,这样就会减少IO查询次数,虽然一次加载到内存的数据变多了,但速度绝对快于二插查找数或是红黑树的。
B树的高度一般都是在2-4级 , 树的高度直接影响读写的次数 如果是三层树结构存储的数据量可以达到20G , 四层树结构存储的数据量可以达到几十T
B+树
B树和B+树的最大区别在于非叶子节点是否存储数据。
- B树是非叶子节点和叶子节点都会存储数据。
- B+树只有叶子节点才会存储数据,而且存储的数据都是在⼀行上,而且这些数据都是有指针指向的,也就是有顺序的。
5. 存储引擎
存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。
不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能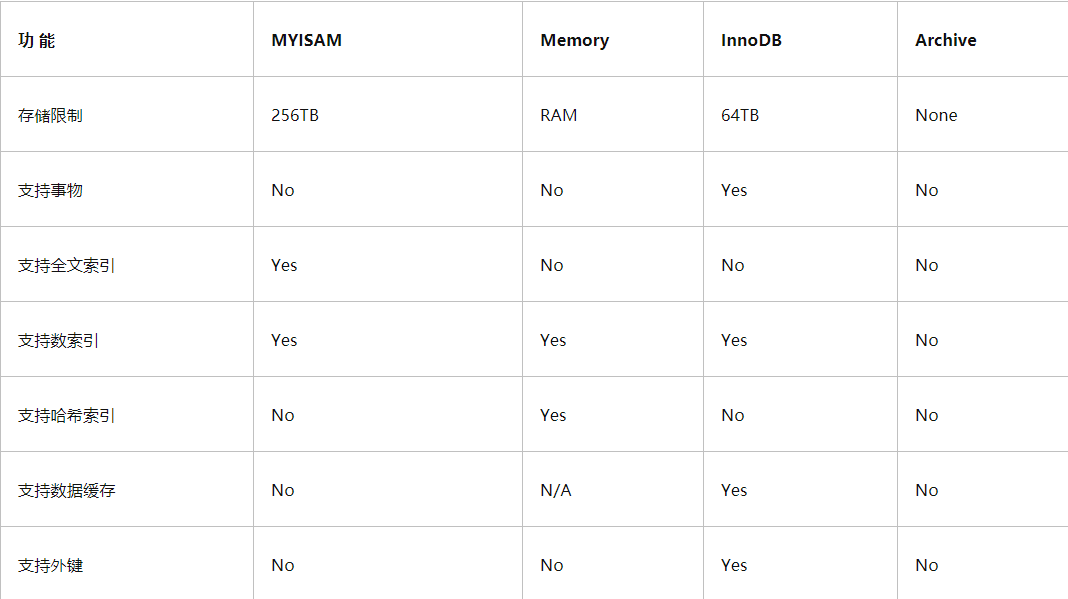
Mysql数据库默认使用InnoDB存储引擎
6. 非聚集索引
在使用MyISAM存储引擎的时候, B+树叶子节点只会存储数据行的指针,简单来说数据和索引不在一起
主键索引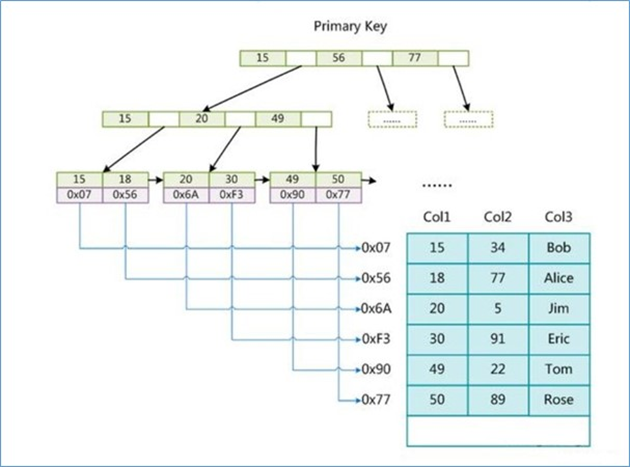
这里假设表一共有三列,假设我们以 Col1 为主键,则上图是一个 MyISAM 表的主索引(Primary key)示意。
可以看出 MyISAM 的索引文件仅仅保存数据记录的地址。
辅助索引
在 MyISAM 中,主键索引和辅助索引在结构上没有任何区别, 只是主键索引要求 key 是唯一的, 而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示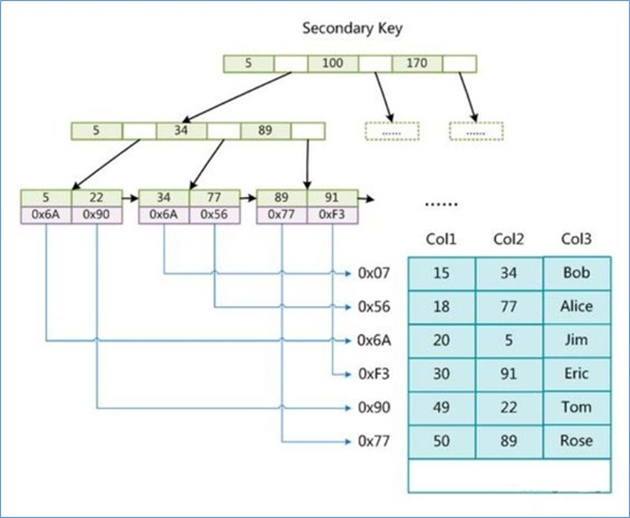
同样也是一颗B+Tree,data 域保存数据记录的地址。因此,MyISAM 中索引检索的算法为首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其data 域的值 , 然后以 data 域的值为地址,读取相应数据记录。
总结 : 以上这种索引和数据单独存储, 索引节点中保存数据存储地址的索引方式称之为非聚集索引
7. 聚集索引
在使用InnoDB存储引擎的时候, B+树叶子节点会存储数据行记录,简单来说数据和索引在一起存储
主键索引
InnoDB 要求表必须有主键 , 如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键, 类型为长整形。
上图是 InnoDB 主键索引(同时也是数据文件)的示意图,可以看到叶子节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身按主键聚集
辅助索引
与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话说 , InnoDB 的所有辅助索引都引用主键索引的data 域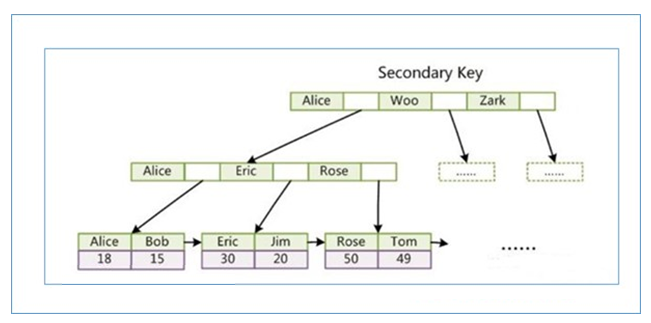
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键 , 然后用主键到主索引中检索获得记录。
8. 回表查询
如上述示例中所说 , 当我们为一张表的name字段建立了索引 , 执行如下查询语句 :
select name,age from user where name='Alice'
那么获取到数据的过程为 :
- 根据
name='Alice'查找索引树 , 定位到匹配数据的主键值为id=18 - 根据
id=18到主索引获取数据记录 (回表查询)
先定位主键值,再定位行记录就是所谓的回表查询,它的性能较扫一遍索引树低
9. 覆盖索引
覆盖索引是指只需要在一棵索引树上就能获取SQL所需的所有列数据 , 因为无需回表查询效率更高
实现覆盖索引的常见方法是:将被查询的字段,建立到联合索引里去。如上列所示, 执行如下查询语句 :select name,age from user where name='Alice'
因为要查询 name和 age二个字段 , 那么我们可以建立组合索引
create index index_name_age on user(name,age)
那么索引存储结构如下 :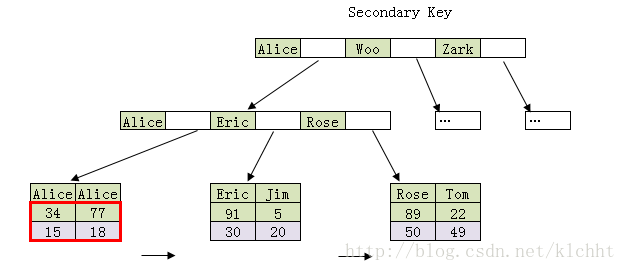
这种情况下, 执行select name,age from user where name='Alice' , 会先根据name='Alice', 找到二条记录 , 这两条记录的索引上刚好又包含了 age 数据 , 直接把 Bob 34 ; Alice 77数据返回 , 就不会执行回表查询 , 这就是覆盖索引
10. 左前缀原则
在mysql建立联合索引时会遵循左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,组合索引的第一个字段必须出现在查询组句中,这个索引才会被用到 ;
例如 : create index index_age_name_sex on tb_user(age,name,sex);
上述SQL语句对 age,name和sex建一个组合索引index_age_name_sex,实际上这条语句相当于建立了(age) , (age,name) , (age,name,sex)三个索引 .
select * from tb_user where age = 49 ; -- 使用索引
select * from tb_user where age = 49 and name = 'Alice' ; -- 使用索引
select * from tb_user where age = 49 and name = 'Alice' and sex = 'man'; -- 使用索引
select * from tb_user where age = 49 and sex = 'man'; -- 使用索引 , 但是只有 age 匹配索引 sex没有走索引
select * from tb_user where name = 'Alice' and age = 49 and sex = 'man' ; -- 使用索引 , 因为MySQL的查询优化器会自动调整 where 子句的条件顺序以使用适合的索引
select * from tb_user where name = 'Alice' and sex = 'man' ; -- 不会使用索引
11. 索引的设计原则
在进行索引设计的时候,应该保证索引字段占用的空间越小越好,这只是一个大的方向,还有一些细节点需要注意下:
1、适合索引的列是出现在where字句中的列,或者连接子句中指定的列
2、基数较小的表,索引效果差,没必要创建索引
3、在选择索引列的时候,越短越好,可以指定某些列的一部分,没必要用全部字段的值
4、不要给表中的每一个字段都创建索引,并不是索引越多越好
5、定义有外键的数据列一定要创建索引
6、更新频繁的字段不要有索引
7、创建索引的列不要过多,可以创建组合索引,但是组合索引的列的个数不建议太多
8、大文本、大对象不要创建索引
12、索引失效情况
范围查询
mysql 会一直从左向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。范围列可以用到索引,但是范围列后面的列无法用到索引。like 语句
如果通配符 % 不出现在开头,则可以用到索引,like “value%”可以使用索引,但是 like “%value%”不会使用索引,走的是全表扫描
3.列上使用函数或表达式
如果查询条件中含有函数或表达式,将导致索引失效而进行全表扫描
4.根据null值查询
只要列中包含有 NULL 值都将不会被包含在索引中,复合索引中只要有一列含有 NULL 值,那么这一列对于此复合索引就是无效的。所以在数据库设计时不要让字段的默认值为 NULL
- 查询条件包含or,可能导致索引失效
- 如何字段类型是字符串,where时一定用引号括起来,否则索引失效
- like通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用mysql的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql估计使用全表扫描要比使用索引快,则不使用索引。
13、索引分析
MySQL 提供了⼀个 EXPLAIN命令, 它可以对 SELECT 语句的执⾏计划进⾏分析, 并输出 SELECT 执⾏的 详细信息, 以供开发⼈员针对性优化. 使⽤explain这个命令来查看⼀个这些SQL语句的执行计划,查看该SQL语句有没有使⽤上了索引,有没有做全表扫描,这都可以通过explain命令来查看。 可以通过explain命令深⼊了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访 问策略的细节,以及当运⾏SQL语句时哪种策略预计会被优化器采⽤。 EXPLAIN 命令⽤法⼗分简单, 在 SELECT 语句前加上 explain 就可以了, 例如:
explain select * from tb_user where name = 'Alice';
环境准备
-- 用户表
create table tb_user
(
id int auto_increment
primary key,
age int null,
name char(32) null,
sex char(10) null,
deptId int null,
addrId int null
);
INSERT INTO tb_user (age, name, sex, deptId, addrId) VALUES (34, 'Bob', 'man', 1, 2);
INSERT INTO tb_user (age, name, sex, deptId, addrId) VALUES (77, 'Alice', 'women', 1, 1);
INSERT INTO tb_user (age, name, sex, deptId, addrId) VALUES (5, 'Jim', 'man', 2, 1);
INSERT INTO tb_user (age, name, sex, deptId, addrId) VALUES (91, 'Eric', 'woman', 2, 2);
INSERT INTO tb_user (age, name, sex, deptId, addrId) VALUES (22, 'Tom', 'man', 2, 2);
INSERT INTO tb_user (age, name, sex, deptId, addrId) VALUES (89, 'Rose', 'woman', 1, 3);
-- 部⻔表
create table tb_dep
(
id int not null
primary key,
name varchar(100) null
);
INSERT INTO tb_dep (id, name) VALUES (1, '咨询部');
INSERT INTO tb_dep (id, name) VALUES (2, '人事部');
INSERT INTO tb_dep (id, name) VALUES (3, '学工部');
-- 地址表
create table tb_addr
(
id int not null
primary key,
address varchar(100) null
);
INSERT INTO tb_addr (id, address) VALUES (1, '湖北省');
INSERT INTO tb_addr (id, address) VALUES (2, '湖南省');
INSERT INTO tb_addr (id, address) VALUES (3, '北京市');
-- 创建普通索引
alter table tb_user add index idx_dep(did);
-- 创建唯⼀索引
alter table tb_user add unique index idx_name(name);
-- 创建组合索引
alter table tb_user add index idx_name_age_sex(name,age,sex);
-- 创建全⽂索引
alter table tb_addr add fulltext ft_addr(address);
参数说明
expain 出来的信息有10列,分别是

id
每个 SELECT语句都会⾃动分配的⼀个唯⼀标识符. 表示查询中操作表的顺序,有三种情况:
- id相同:执⾏顺序由上到下
- id不同:如果是⼦查询,id号会⾃增,id越⼤,优先级越⾼。
- id相同和不同同时存在
id列为null的就表示这是⼀个结果集,不需要使⽤它来进⾏查询。
例如 :
explain select (select name from tb_user) from tb_user ;

select_type
查询类型,主要⽤于区别普通查询、联合查询(union、union all)、⼦查询等复杂查询。
simple
表示不需要union操作或者不包含⼦查询的简单select查询。有连接查询时,外层的查询为simple,且 只有⼀个
例如 :
primary
⼀个需要union操作或者含有⼦查询的select,位于最外层的单位查询的select_type即为primary。且只 有⼀个
例如 :
subquery
除了from字句中包含的⼦查询外,其他地⽅出现的⼦查询都可能是subquery
例如 :
dependent subquery
与
dependent union类似,表示这个subquery的查询要受到外部表查询的影响例如 :
union
union连接的两个select查询,第⼀个查询是PRIMARY,除了第⼀个表外,第⼆个以后的表select_type 都是union
例如 :
dependent union
与union⼀样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
例如 :
union result
包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
derived
from字句中出现的⼦查询,也叫做派⽣表,其他数据库中可能叫做内联视图或嵌套select
例如 :







explain select * from tb_user
explain select (select name from tb_user) from tb_user ;
explain select * from tb_user where id = (select max(id) from tb_user);
explain select id,name,(select name from tb_dep a where a.id=b.deptId) from tb_user b;
explain select * from tb_user where sex='man' union select * from tb_user where sex='2';
explain select * from tb_user where sex in (select sex from tb_user where sex='1' union select sex from tb_user where sex='2');
explain select * from (select * from tb_user where sex='man') b;
table
显示的查询表名,
- 如果查询使⽤了别名,那么这⾥显示的是别名
- 如果不涉及对数据表的操作,那么这显示为null
- 如果显示为尖括号括起来的就表示这个是临时表,后边的N就是执⾏计划中的id,表示结果来⾃于 这个查询产⽣
- 如果是尖括号括起来的,与
type
索引的使用类型 , 性能由好到差依次为 : system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL
除了all之外,其他的type都可以使⽤到索引,除了index_merge之外,其他的type只可以⽤到⼀个索引
如果想让一条SQL的效率高, 那么最起码要使用到range级别
system
表中只有⼀⾏数据或者是空表。
const
使⽤唯⼀索引或者主键,返回记录⼀定是1⾏记录的等值where条件时,通常type是const。其他数据库 也叫做唯⼀索引扫描
eq_ref
关键字: 连接字段为主键或者唯⼀性索引。
此类型通常出现在多表的 join 查询, 表示对于前表的每⼀个结果, 都只能匹配到后表的⼀⾏结果. 并且查 询的⽐较操作通常是 ‘=’, 查询效率较⾼
ref
针对⾮唯⼀性索引,使⽤等值(=)查询⾮主键。或者是使⽤了最左前缀规则索引的查询。
fulltext
全⽂索引检索,要注意,全⽂索引的优先级很⾼,若全⽂索引和普通索引同时存在时,mysql不管代 价,优先选择使⽤全⽂索引
ref_or_null
与ref⽅法类似,只是增加了null值的⽐较。
unique_subquery
⽤于where中的in形式⼦查询,⼦查询返回不重复值唯⼀值
index_subquery
⽤于in形式⼦查询使⽤到了辅助索引或者in常数列表,子查询可能返回重复值,可以使⽤索引将子查询去重。
range
索引范围扫描,常⻅于使⽤>,<,is null,between ,in ,like等运算符的查询中。
index_merge
表示查询使⽤了两个以上的索引,最后取交集或者并集,常⻅and ,or的条件使⽤了不同的索引,官⽅ 排序这个在ref_or_null之后,但是实际上由于要读取多个索引,性能可能⼤部分时间都不如range
index
索引全表扫描,把索引从头到尾扫⼀遍,常见于使用索引列就可以处理不需要读取数据⽂件的查询、可 以使⽤索引排序或者分组的查询。
all
这个就是全表扫描数据⽂件,然后再在server层进⾏过滤返回符合要求的记录。








explain select * from (select * from tb_user where id=1) a;
explain select * from tb_user where name = 'Bob';
explain select a.id from tb_user a left join tb_dep b on a.deptId=b.id;
explain select * from tb_user where name = 'Bob';
explain select * from tb_addr where match(address) against('bei');
explain select * from tb_user where name like 'B%';
explain select name from tb_user;
explain select * from tb_user;
possible_keys
此次查询中可能选⽤的索引,⼀个或多个
key
查询真正使⽤到的索引,select_type为index_merge时,这⾥可能出现两个以上的索引,其他的 select_type这⾥只会出现⼀个。
key_len
⽤于处理查询的索引⻓度,如果是单列索引,那就整个索引⻓度算进去,如果是多列索引,那么查询不⼀定都能使⽤到所有的列
key_len只计算where条件⽤到的索引⻓度,⽽排序和分组就算⽤到了索引,也不会计算到 key_len中。
计算规则 :
- 所有的索引字段,如果没有设置not null,则需要加一个字节。
- 定长字段,int占四个字节、date占三个字节、char(n)占n个字符。
- 对于变成字段varchar(n),则有n个字符+两个字节。
- 不同的字符集,一个字符占用的字节数不同。latin1编码的,一个字符占用一个字节,gbk编码的,一个字符占用两个字节,utf8编码的,一个字符占用三个字节。
key_len越小 索引效果越好
ref
如果是使⽤的常数等值查询,这⾥会显示const
如果是连接查询,被驱动表的执⾏计划这⾥会显示驱动表的关联字段
如果是条件使⽤了表达式或者函数,或者条件列发⽣了内部隐式转换,这⾥可能显示为func
rows
这⾥是执⾏计划中估算的扫描⾏数,不是精确值
Extra
这个列包含不适合在其他列中显示单⼗分重要的额外的信息,这个列可以显示的信息⾮常多,有⼏⼗ 种,常⽤的有
using temporary
表示使⽤了临时表存储中间结果。
using filesort
排序时⽆法使⽤到索引时,就会出现这个。常⻅于order by和group by语句中
说明MySQL会使⽤⼀个外部的索引排序,⽽不是按照索引顺序进⾏读取。
MySQL中⽆法利⽤索引完成的排序操作称为“⽂件排序”
using index
查询时不需要回表查询,直接通过索引就可以获取查询的数据。
- 表示相应的SELECT查询中使⽤到了覆盖索引(Covering Index),避免访问表的数据⾏,效率不 错!
- 如果同时出现Using Where ,说明索引被⽤来执⾏查找索引键值
- 如果没有同时出现Using Where ,表明索引⽤来读取数据⽽⾮执⾏查找动作。
using where
表示存储引擎返回的记录并不是所有的都满⾜查询条件,需要在server层进⾏过滤


explain select * from tb_addr order by address;
explain select name,age,sex from tb_user where name like '%B';
14、需要创建索引情况
- 主键自动建立主键索引
- 频繁作为查询条件的字段应该创建索引
- 多表关联查询中,关联字段应该创建索引 (on 两边都要创建索引)
- 查询中排序的字段,应该创建索引
- 频繁查找字段 , 应该创建索引
- 查询中统计或者分组字段,应该创建索引
15、不要创建索引情况
- 表记录太少
- 经常进⾏行行增删改操作的表
- 频繁更新的字段
- where条件里使用频率不高的字段
16、多使用组合索引
在多个列上建立索引 , 这种索引叫做复合索引(组合索引) , 复合索引在数据库操作期间所需的开销更小, 可以代替多个单一索引
17、InnoDB与MyISAM的区别
InnoDB支持事务,MyISAM不支持事务
InnoDB支持外键,MyISAM不支持外键
InnoDB 支持 MVCC(多版本并发控制),MyISAM 不支持
select count(*) from table时,MyISAM更快,因为它有一个变量保存了整个表的总行数,可以直接读取,InnoDB就需要全表扫描。
Innodb不支持全文索引,而MyISAM支持全文索引(5.7以后的InnoDB也支持全文索引)
InnoDB支持表、行级锁,而MyISAM支持表级锁。
InnoDB表必须有主键,而MyISAM可以没有主键
Innodb表需要更多的内存和存储,而MyISAM可被压缩,存储空间较小,。
Innodb按主键大小有序插入,MyISAM记录插入顺序是,按记录插入顺序保存。
InnoDB 存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全,与 MyISAM 比 InnoDB 写的效率差一些,并且会占用更多的磁盘空间以保留数据和索引
18、数据库索引的原理,为什么要用 B+树,为什么不用二叉树
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数,为什么不是二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是B+树呢?
为什么不是一般二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快啦。
那为什么不是B树而是B+树呢?
1)B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
2)B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
19、聚集索引与非聚集索引的区别
- 一个表中只能拥有一个聚集索引,而非聚集索引一个表可以存在多个。
- 聚集索引,索引中键值的逻辑顺序决定了表中相应行的物理顺序;非聚集索引,索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
- 聚集索引:物理存储按照索引排序;非聚集索引:物理存储不按照索引排序;

若有收获,就点个赞吧
0 人点赞
