- 进阶4:常见函数
- 1、简单 的使用
- 2、参数支持哪些类型
- 3、是否忽略null
- 4、和distinct搭配
- 5、count函数的详细介绍
- 6、和分组函数一同查询的字段有限制
- 1.简单的分组
- 案例1:查询每个工种的员工平均工资
- 案例2:查询每个位置的部门个数
- 2、可以实现分组前的筛选
- 案例1:查询邮箱中包含a字符的 每个部门的最高工资
- 案例2:查询有奖金的每个领导手下员工的平均工资
- 3、分组后筛选
- 案例:查询哪个部门的员工个数>5
- ①查询每个部门的员工个数
- ②筛选刚才①结果
- 案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
- 案例3:领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资
- 4.添加排序
- 案例:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
- 5.按多个字段分组
- 案例:查询每个工种每个部门的最低工资,并按最低工资降序
进阶4:常见函数
概念
类似于java的方法,将一组逻辑语句封装在方法体中,对外暴露方法名
好处
- 隐藏了实现细节
- 提高代码的重用性
调用**select 函数名(实参列表) [from 表];**
特点
①叫什么(函数名)
②干什么(函数功能)
分类
- 单行函数
如 concat、length、ifnull等
- 分组函数
单行函数
字符函数
**length()** 获取字节个数(utf-8一个汉字代表3个字节,gbk为2个字节)**concat()** 拼接**substring()** 截取子串**upper()** 转换成大写**lower()** 转换成小写**trim()** 去前后指定的空格或指定字符**ltrim()** 去左边空格**rtrim()** 去右边空格**replace()** 全部替换**lpad()** 左填充**rpad()** 右填充**instr()** 返回子串第一次出现的索引,找不到返回0
#1.length 获取参数值的字节个数SELECT LENGTH('john');SELECT LENGTH('张三丰hahaha');SHOW VARIABLES LIKE '%char%'#2.concat 拼接字符串SELECT CONCAT(last_name,'_',first_name) 姓名 FROM employees;#3.upper、lowerSELECT UPPER('john');SELECT LOWER('joHn');#示例:将姓变大写,名变小写,然后拼接SELECT CONCAT(UPPER(last_name),LOWER(first_name)) 姓名 FROM employees;#4.substr/substring注意:索引从1开始#截取从指定索引处后面所有字符SELECT SUBSTRING('李莫愁爱上了陆展元', 7) out_put; #陆展元#截取从指定索引处指定字符长度的字符SELECT SUBSTRING('李莫愁爱上了陆展元', 1, 3) out_put; #李莫愁#案例:姓名中首字符大写,其他字符小写然后用_拼接,显示出来SELECT CONCAT(UPPER(SUBSTR(last_name,1,1)),'_',LOWER(SUBSTR(last_name,2))) out_putFROM employees;#5.instr 返回子串第一次出现的索引,如果找不到返回0SELECT INSTR('杨不悔爱上了殷六侠','殷六侠') AS out_put;#6.trimSELECT LENGTH(TRIM(' 张翠山 ')) AS out_put;#🔴不仅可以去空格,还能去指定字符SELECT TRIM('aa' FROM 'aaaaaaaaa张aaa翠山aaaaaaaaaaaaaa') AS out_put;#7.lpad 用指定的字符实现左填充指定长度SELECT LPAD('殷素素',2,'*') AS out_put; #殷素#8.rpad 用指定的字符实现右填充指定长度SELECT RPAD('殷素素',12,'ab') AS out_put; #殷素素ababababa#9.replace 全部替换替换SELECT REPLACE('周芷若周芷若周芷若周芷若张无忌爱上了周芷若','周芷若','赵敏') AS out_put;
数学函数
**round()** 四舍五入**floor()** 向下取整**ceil()** 向上取整**mod()** 取余**truncate()** 截断**rand()** 产生0-1之间的一个随机数
#round 四舍五入SELECT ROUND(-1.55);SELECT ROUND(1.567, 2); #1.57#ceil 向上取整,返回>=该参数的最小整数SELECT CEIL(-1.02);#floor 向下取整,返回<=该参数的最大整数SELECT FLOOR(-9.99);#truncate 截断,第二个参数为保留几位小数SELECT TRUNCATE(1.69999, 1);#mod取余/*mod(a,b) : a-a/b*bmod(-10,-3):-10- (-10)/(-3)*(-3)=-1*/SELECT MOD(10,-3);SELECT 10%3;
日期函数
**now()** 当前系统日期+时间**curdate()** 当前系统日期**curtime()** 当前系统时间**str_to_date()** 将字符转换成日期**date_format()** 将日期转换成字符**year()****month()****monthname()****day()****hour()****minute()****second()****datediff()**返回两个时间差了多少天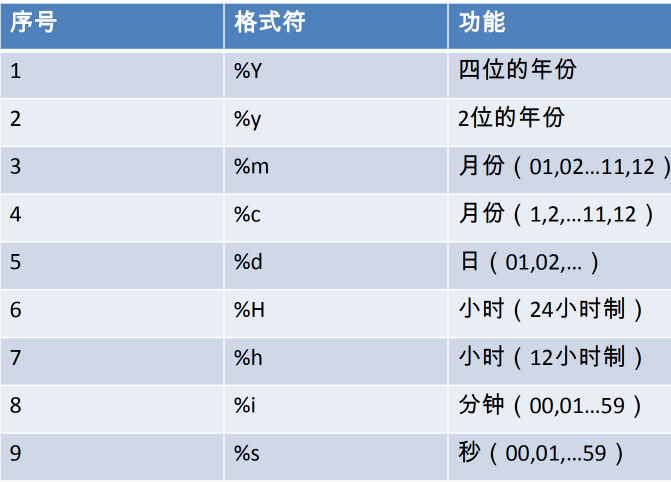
#now 返回当前系统日期+时间SELECT NOW();#curdate 返回当前系统日期,不包含时间SELECT CURDATE();#curtime 返回当前时间,不包含日期SELECT CURTIME();#🔴可以获取指定的部分,年、月、日、小时、分钟、秒SELECT YEAR(NOW()) 年;SELECT YEAR('1998-1-1') 年;SELECT YEAR(hiredate) 年 FROM employees;SELECT MONTH(NOW()) 月;SELECT MONTHNAME(NOW()) 月;#str_to_date 将字符通过指定的格式转换成日期SELECT STR_TO_DATE('1998-3-2','%Y-%c-%d') AS out_put;#查询入职日期为1992-4-3的员工信息SELECT * FROM employees WHERE hiredate = '1992-4-3';SELECT * FROM employees WHERE hiredate = STR_TO_DATE('4-3 1992','%c-%d %Y');#date_format 将日期转换成字符SELECT DATE_FORMAT(NOW(),'%y年%m月%d日') AS out_put;#查询有奖金的员工名和入职日期(xx月/xx日 xx年)SELECT last_name, DATE_FORMAT(hiredate,'%m月/%d日 %y年') 入职日期FROM employeesWHERE commission_pct IS NOT NULL;
其他函数
**version()** 版本**database()** 当前库**user()** 当前连接用户**password("用户名")** 返回字符的密码形式**md5()** 同上
#四、其他函数SELECT VERSION();SELECT DATABASE();SELECT USER();SELECT PASSWORD("root");
流程控制函数
if() 处理双分支
case语句 处理多分支
情况1:处理等值判断
情况2:处理条件判断
#1.if函数: if else 的效果SELECT IF(10<5,'大','小');SELECT last_name,commission_pct,IF(commission_pct IS NULL,'没奖金,呵呵','有奖金,嘻嘻') 备注FROM employees;#2.case函数的使用一: switch case 的效果/*java中switch(变量或表达式) {case 常量1:语句1;break;...default:语句n;break;}mysql中case 要判断的字段或表达式when 常量1 then 要显示的值1或语句1; #语句时才用分号when 常量2 then 要显示的值2或语句2;...else 要显示的值n或语句n;end*//*案例:查询员工的工资,要求部门号=30,显示的工资为1.1倍部门号=40,显示的工资为1.2倍部门号=50,显示的工资为1.3倍其他部门,显示的工资为原工资*/SELECT salary 原始工资, department_id,CASE department_idWHEN 30 THEN salary * 1.1WHEN 40 THEN salary * 1.2WHEN 50 THEN salary * 1.3ELSE salaryEND AS 新工资FROM employees;#3.case 函数的使用二:类似于 多重if/*java中:if(条件1){语句1;}else if(条件2){语句2;}...else{语句n;}mysql中:casewhen 条件1 then 要显示的值1或语句1when 条件2 then 要显示的值2或语句2...else 要显示的值n或语句nend*/#案例:查询员工的工资的情况如果工资>20000,显示A级别如果工资>15000,显示B级别如果工资>10000,显示C级别否则,显示D级别SELECT salary,CASEWHEN salary > 20000 THEN 'A'WHEN salary > 15000 THEN 'B'WHEN salary > 10000 THEN 'C'ELSE 'D'END AS 工资级别FROM employees;
分组函数
**sum()**求和**max()**最大值**min()**最小值**avg()**平均值**count()**计数
特点
- sum和avg一般用于处理数值型
max、min、count可以处理任何数据类型
- 以上五个分组函数都忽略null值
- 都可以搭配distinct使用,用于统计去重后的结果
- count的参数可以支持:
字段、、常量值(一般放1)
建议使用 count()
- 和分组函数一同查询的字段要求是group by后的字段
```sql
1、简单 的使用
SELECT SUM(salary) FROM employees; SELECT AVG(salary) FROM employees; SELECT MIN(salary) FROM employees; SELECT MAX(salary) FROM employees; SELECT COUNT(salary) FROM employees; SELECT SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数 FROM employees; SELECT SUM(salary) 和, ROUND(AVG(salary),2) 平均, COUNT(salary) 个数 FROM employees;
2、参数支持哪些类型
SELECT SUM(last_name), AVG(last_name) FROM employees; #无意义 SELECT SUM(hiredate), AVG(hiredate) FROM employees; #无意义 SELECT MAX(last_name), MIN(last_name) FROM employees; SELECT MAX(hiredate), MIN(hiredate) FROM employees; SELECT COUNT(commission_pct) FROM employees; SELECT COUNT(last_name) FROM employees;
3、是否忽略null
SELECT SUM(commission_pct), AVG(commission_pct), SUM(commission_pct)/35, SUM(commission_pct)/107 FROM employees; SELECT MAX(commission_pct) ,MIN(commission_pct) FROM employees; SELECT COUNT(commission_pct) FROM employees; SELECT commission_pct FROM employees;
4、和distinct搭配
SELECT SUM(DISTINCT salary), SUM(salary) FROM employees; SELECT COUNT(DISTINCT salary), COUNT(salary) FROM employees;
5、count函数的详细介绍
SELECT COUNT(salary) FROM employees; SELECT COUNT(*) FROM employees; SELECT COUNT(1) FROM employees; #相当于多了一列,值均为1
效率: MYISAM存储引擎下,COUNT()的效率高 INNODB存储引擎下,COUNT()和COUNT(1)的效率差不多,比COUNT(字段)要高一些
6、和分组函数一同查询的字段有限制
SELECT AVG(salary),employee_id FROM employees; #❌无意义
`**DATEDIFF()**` 两个时间相差的天数```sqlSELECT DATEDIFF(MAX(hiredate), MIN(hiredate)) DIFFERENCEfrom employees;SELECT DATEDIFF("2019-7-7", "2016-7-7"); #1095
进阶5:分组查询
语法**select 分组函数 groupby后的字段****from 表****[where 筛选条件]****group by 分组的字段****[having 筛选条件]****[order by 排序的字段];**
特点
- 和分组函数一同查询的字段最好是分组后的字段
分组查询筛选分为两类 | | 数据源 | 位置 | 关键字 | | —- | —- | —- | —- | | 分组前筛选 | 原始表 | group by的前面 | where | | 分组后筛选 | 分组后的结果 | group by的后面 | having |
- 分组函数做条件肯定放在having子句中
- 能用分组前筛选的,就优先考虑分组前筛选,性能考虑
- 支持单个字段分组,也支持多个字段分组,字段之间用逗号隔开,没有顺序要求,也支持函数和表达式
- 可以添加排序,放在分组查询的最后
- group by 和 having 后可以支持别名,但不要用,因为Oracle等不支持
```sql
1.简单的分组
案例1:查询每个工种的员工平均工资
SELECT AVG(salary), job_id FROM employees GROUP BY job_id;
案例2:查询每个位置的部门个数
SELECT COUNT(*), location_id FROM departments GROUP BY location_id;
2、可以实现分组前的筛选
案例1:查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary), department_id FROM employees WHERE email LIKE ‘%a%’ GROUP BY department_id;
案例2:查询有奖金的每个领导手下员工的平均工资
SELECT AVG(salary), manager_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id;
3、分组后筛选
案例:查询哪个部门的员工个数>5
①查询每个部门的员工个数
SELECT COUNT(*), department_id FROM employees GROUP BY department_id;
②筛选刚才①结果
SELECT COUNT(), department_id FROM employees GROUP BY department_id HAVING COUNT()>5;
案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id, MAX(salary) FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING MAX(salary) > 12000;
案例3:领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资
SELECT manager_id, MIN(salary) FROM employees WHERE manager_id > 102 GROUP BY manager_id HAVING MIN(salary) > 5000;
4.添加排序
案例:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
SELECT job_id, MAX(salary) m FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING m>6000 ORDER BY m;
5.按多个字段分组
案例:查询每个工种每个部门的最低工资,并按最低工资降序
SELECT MIN(salary), job_id, department_id FROM employees GROUP BY department_id, job_id ORDER BY MIN(salary) DESC; ```

若有收获,就点个赞吧
0 人点赞
