在之前的文章中我们曾提到一大问题,那就是我们如何来衡量一个条件作为分裂标准是否合适呢?在决策树中有不少用于分裂的指标,它们可以很好地衡量一个条件是否适合作为分裂标准。决策树既可以用来解决回归问题,也可以用来解决分类问题。对于分类问题,我们常用的分裂指标是基尼系数(Gini),信息增益,信息增益率。对于回归问题,我们常用的分裂指标是MSE。
首先我们来谈谈基尼系数,基尼系数的概念是在1912年由意大利的社会学家Corrado Gini,它被广泛地用于衡量社会财富的平均问题。在决策树中,我们把每个节点想象成一个社会,节点中的样本想象成公民,如果一个节点中的所有样本都足够相似,那么可以认为这个节点的纯度足够高。判断纯度的标准就是基尼系数,我们通过计算分裂前节点的基尼系数和分裂后多节点的总基尼系数,可以发现基尼系数会变小。基尼系数是用来表示纯度的指标,越低表示越平均,越高表示越不平均,我们要尽可能地使我们的节点中的样本更平均。基尼系数公式如下。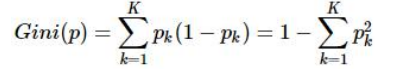 。pk代表的是按照某个维度划分后节点中某一特征的样本所占总样本的比例。多节点的基尼系数的计算公式如下。
。pk代表的是按照某个维度划分后节点中某一特征的样本所占总样本的比例。多节点的基尼系数的计算公式如下。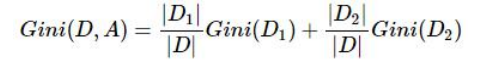 ,可以看出多节点的基尼系数计算与节点的样本数有关,节点中的样本数越多,权重越大。
,可以看出多节点的基尼系数计算与节点的样本数有关,节点中的样本数越多,权重越大。
接下来介绍信息增益,信息增益事实上也是用来判断纯度的标准,只是信息增益与基尼系数的数学表达不同而已。但事实上二者不管在物理意义还是在数学意义上都是有联系的。我们首先要引入信息熵的概念,信息熵代表着信息的可传递量,信息熵越大,所能传递的信息越多,信息熵越小,所能传递的信息越少。信息增益就是节点分裂前的信息熵与节点分裂后的信息熵之差。信息增益的公式如下。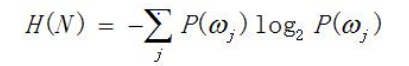 可以看出,信息增益与基尼系数有一定的相似度,事实上,基尼系数是信息增益中-logP在P=1处泰勒展开后的结果,所以二者都可以用来度量数据集的纯度,用于描述决策树节点的纯度。信息增益的缺点就是它会向着维度多的指标倾斜。因为维度越多,信息熵就会更大。
可以看出,信息增益与基尼系数有一定的相似度,事实上,基尼系数是信息增益中-logP在P=1处泰勒展开后的结果,所以二者都可以用来度量数据集的纯度,用于描述决策树节点的纯度。信息增益的缺点就是它会向着维度多的指标倾斜。因为维度越多,信息熵就会更大。
接着来介绍信息增益率,信息增益率是为了解决信息增益对多维度的偏好问题而产生的,信息增益率就是信息增益与类别本身的熵之比,也就是说含有样本量多的节点对信息增益有更多的贡献,含有样本量少的节点对信息增益有更少的贡献,这样可以很好地解决信息增益的多维度偏好问题。
最后我们需要提到的是MSE,MSE多用于回归问题。形式如下。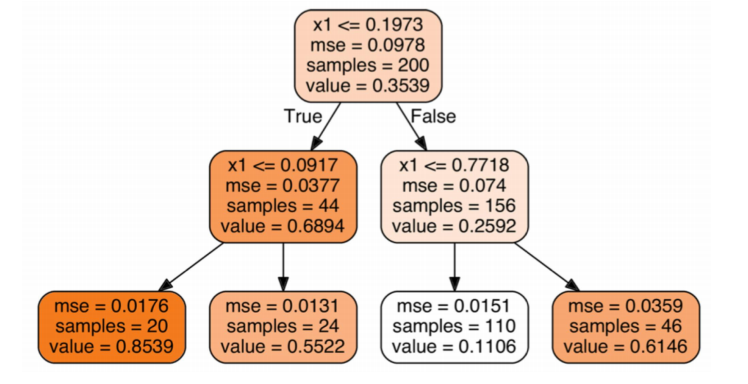

若有收获,就点个赞吧
0 人点赞
