基础
- 切片是什么?
- 切片是建立在固定大小的数组上,以提供灵活,可扩展的数据结构
- A slice is a data structure describing a contiguous section of an array stored separately from the slice variable itself. A slice is not an array. A slice describes a piece of an array.
- 切片在运行时表现为 reflect.SliceHeader:
// 源码路径:/go/src/reflect/value.go// SliceHeader is the runtime representation of a slice.// It cannot be used safely or portably and its representation may// change in a later release.// Moreover, the Data field is not sufficient to guarantee the data// it references will not be garbage collected, so programs must keep// a separate, correctly typed pointer to the underlying data.// 此外,“数据”字段不足以保证不会对其进行垃圾回收,因此程序必须保留一个单独的,正确键入的指向底层数据的指针。type SliceHeader struct {Data uintptrLen intCap int}
- 而在源码文件
/go/src/runtime/slice.go中有:
type slice struct {array unsafe.Pointerlen intcap int}
- 由以上可知,切片是一种封装好的抽象数据结构,底层是数组,额外的属性还有长度和容量
- cap表明底层数组的容量或者长度(对数组来说容量和长度这两个概念都一样,都是指元素数量);
- len 表明(上游的、抽象的、封装好的) sliceHeader 已经有多少个元素。
- 关于 sliceHeader
- 因为sliceHeader本质上还是一个结构体,所以赋值或者参数传递,本质上还是值传递
- 时刻记住,Go语言的赋值和函数传参规则很简单,除了闭包函数以引用的方式对外部变量访问之外,其它赋值和函数传参数都是以传值的方式处理
- 切片的声明,带着问题:不同声明方式分别会分配多少容量呢?
var (a []int // nil切片, 和 nil 相等, (len:0,cap:0) 一般用来表示一个不存在的切片b = []int{} // 空切片, 和 nil 不相等, 一般用来表示一个空的集合(len:0,cap:0)c = []int{1, 2, 3} // 有3个元素的切片, len和cap都为3 (3,3)c1 = []int{1, 2, 3,4,5} // 有5个元素的切片, len和cap都为5 (5,5)d = c[:2] // 左闭右开,c[:2]=c[0:2], c[0]=1,c[1]=2 ,所以 d= []int{1,2} len=2,但是底层数组还是c,所以cap=3 (2,3)e = c[0:2:cap(c)] // e = c[0:2:3] , 有2个元素的切片, len为2, cap为3,e=[]int{1,2}f = c[:0] // c[:0]=c[0:0],有0个元素的切片, len为0, cap为3 (0,3)g = make([]int, 3) // 有3个元素的切片, len和cap都为3 ,g=[]int{0,0,0}h = make([]int, 2, 3) // 有2个元素的切片, len为2, cap为3 ,h=[]int{0,0}i = make([]int, 0, 3) // 有0个元素的切片, len为0, cap为3 ,i=[]int{ })
- 空切片 和 nil 切片
- 空切片指向的地址不是nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。
- 不管是使用 nil 切片还是空切片,对其调用内置函数 append,len 和 cap 的效果都是一样的。
- 切片支持的操作有:
- reslice : 切分(或截取),如 a=b[start:end:cap]
- append:需要了解其机制,涉及扩容原理,go官方博客也有作解说,下文开新的标题记录重点,这里做简要总结:
- 在容量不足的情况下,append的操作会导致重新分配内存,可能导致巨大的内存分配和复制数据代价
- 即使容量足够,依然需要用append函数的返回值来更新切片本身,因为新切片的长度(sliceHeader.len)已经发生了变化,那么因为结构体值传递,所以需要接收append返回值。
- 底层数组的大小不够用时继续使用append,就会触发自动扩容((怎么扩容?就是将sliceHeader.Data 指向新分配的的、更大长度的数组)):
- 扩容策略
- 当所需最低容量小于两倍原容量时:
- 并且如果旧长度小于1024,那么取两倍旧容量;
- 否则每次增加0.25倍,直到大于等于所需容量
- 当所需最低容量大于两倍原容量时:直接取所需容量
- 最后,都需要经过向上取整,确定新容量
- 当所需最低容量小于两倍原容量时:
- 当底层数组不够用时,扩容在操作系统层面上,本质上是重新申请一片连续空间,用来构造一个新的更大的数组,把旧数组copy过去
- 为什么呢?不能傻傻地以为:“数组不够用,操作系统新分配内存空间,追加在数组尾巴后面就好了”。
- 现实是,操作系统中学习的内存管理,分配一个数组都是进程通过系统调用去申请一片连续空间的,你要多少系统就给你分配多少;为了内存利用率高,都是碎片化利用的,所以才有那些内存碎片整理算法。
- 后面你想扩容了,不能说系统继续追加容量给到你指定的内存地址的,你怎么知道往下的一片连续空间是不是别的进程在用的呢?
- 所以只能重新找一片连续空间,拷贝。
- 扩容策略
- copy:其实就是封装了这么一个逻辑:手动遍历源数组一个个赋值到目标数组中
- 索引:如同数组使用中括号和index:a[i]
- 迭代:通过 for range
reslice 切分数组
- 形如
a=a[1:3:5]什么意思?如下图解就能看懂了。就是切分a的一段连续部分,重新赋值给a本身。
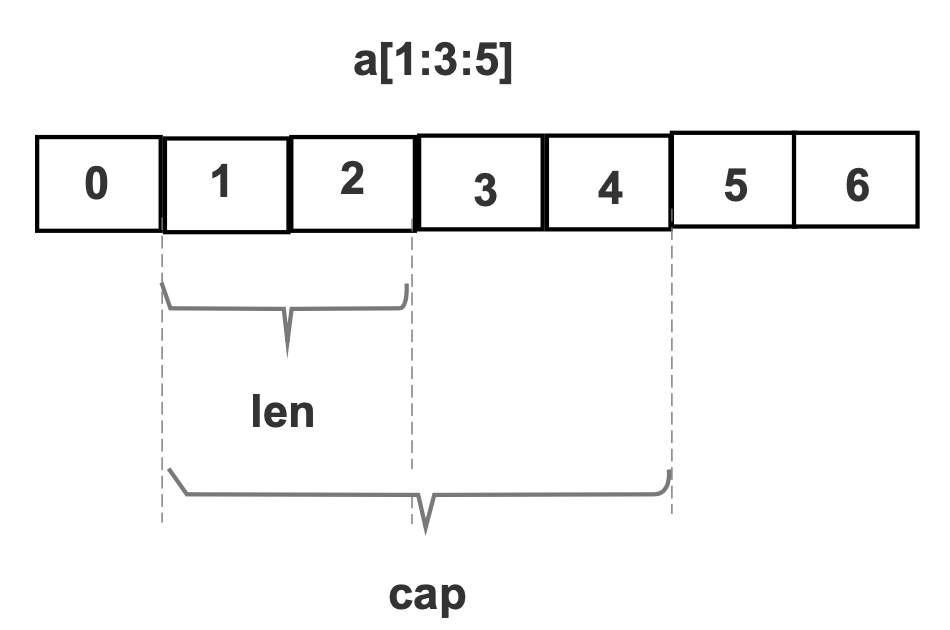
// 搞懂字面量声明格式到底什么鬼 a[1:3:5]func test5() {array :=[...]int{10, 20, 30, 40,50,60,70}fmt.Printf("len(array)=%v, cap(array)=%v, \n array变量指向的目标变量的值=%v,array自身的地址为&c=%p \n", len(array), cap(array), array, &array)slice := array[1:3:5]fmt.Printf("len(slice)=%v, cap(slice)=%v, \n slice变量指向的目标变量的值=%v,slice自身的地址为&c=%p,slice变量指向的目标变量的地址=%p \n", len(slice), cap(slice), slice, &slice, slice)/*结果:len(array)=7, cap(array)=7,array变量指向的目标变量的值=[10 20 30 40 50 60 70],array自身的地址为&c=0xc00001a140len(slice)=2, cap(slice)=4,slice变量指向的目标变量的值=[20 30],slice自身的地址为&c=0xc00000c060,slice变量指向的目标变量的地址=0xc00001a148*/}
- 切分数组或切分有什么用?
- 最直接的就是用来截取部分数组
- 配合append可以实现:删除数组元素、在i位置添加元素等技巧,下文会做总结。(在这篇官方wiki也有讲到)
append 方法
在开头添加元素
var a = []int{1,2,3}a = append([]int{0}, a...) // 在开头添加1个元素a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片
删除第i个元素
- 1.使用字面量
a := []int{0, 1, 2, 3, 4}//删除第i个元素i := 2a = append(a[:i], a[i+1:]...)
- 2.使用copy
- 造一个新的切片,除去要删除的元素,把剩下的赋值过去
append 内建函数
append方法需要接收返回值
- Append returns the updated slice. It is therefore necessary to store the result of append, often in the variable holding the slice itself:
slice = append(slice, elem1, elem2) - 即使容量足够,依然需要用append函数的返回值来更新切片本身,因为新切片的长度已经发生了变化。
- 为什么?上一句新手会有疑问的
- 通过下面实验1理解:
- slice类型的变量,也是要占用内存空间存放的。
b := append(a, 5)这一方法执行后,内存分配了一块新的空间存放b,b和a同样指向同一块底层数组,只不过,b他的长度扩大了哦,a没被赋值,a没有任何改动哦,所以a长度还是不变。
- slice类型的变量,也是要占用内存空间存放的。
实验一:
func test6() {var a = make([]int, 2, 10)fmt.Printf("len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)// len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 0],a自身的地址为&c=0xc000088020,a变量指向的目标变量的地址=0xc00009a000b := append(a, 5)fmt.Printf("len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)//len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 0],a自身的地址为&c=0xc000088020,a变量指向的目标变量的地址=0xc00009a000fmt.Printf("len(b)=%v, cap(b)=%v, \n b变量指向的目标变量的值=%v,b自身的地址为&c=%p,b变量指向的目标变量的地址=%p \n", len(b), cap(b), b, &b, b)//len(b)=3, cap(b)=10,// b变量指向的目标变量的值=[0 0 5],b自身的地址为&c=0xc000088080,b变量指向的目标变量的地址=0xc00009a000b[1] = 8fmt.Printf("len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)fmt.Printf("len(b)=%v, cap(b)=%v, \n b变量指向的目标变量的值=%v,b自身的地址为&c=%p,b变量指向的目标变量的地址=%p \n", len(b), cap(b), b, &b, b)//len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 8],a自身的地址为&c=0xc000088020,a变量指向的目标变量的地址=0xc00009a000//len(b)=3, cap(b)=10,// b变量指向的目标变量的值=[0 8 5],b自身的地址为&c=0xc000088080,b变量指向的目标变量的地址=0xc00009a000a = append(a, 7)fmt.Printf("len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)fmt.Printf("len(b)=%v, cap(b)=%v, \n b变量指向的目标变量的值=%v,b自身的地址为&c=%p,b变量指向的目标变量的地址=%p \n", len(b), cap(b), b, &b, b)//len(a)=3, cap(a)=10,// a变量指向的目标变量的值=[0 8 7],a自身的地址为&c=0xc000088020,a变量指向的目标变量的地址=0xc00009a000//len(b)=3, cap(b)=10,// b变量指向的目标变量的值=[0 8 7],b自身的地址为&c=0xc000088080,b变量指向的目标变量的地址=0xc00009a000}
通过函数传递切片
- 所以说,切片这种结构不过是个普通的值传递的struct,只不过结构里内嵌了指向数组的引用,你传进去某个函数,改动了他的底层数组的某些元素,那确实可以在函数外也发生改变;
- 但是如果你在里面改动了切片的长度(如容量够的时候用append)或者改动了sliceHeader.Data指向地址(如容量不够用append,那么底层数组都改了),那外面可是不生效的。下面的实验2验证了这一点。
- 所以简单说就是,传参到函数a,在函数a里面使用append,函数return后,不return这个改动后的slice的话,那是不会在函数外改动生效的!
func test7() {var a = make([]int, 2, 10)fmt.Printf("【打印数组信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)//【打印数组信息】//len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 0],a自身的地址为&c=0xc000088020,a变量指向的目标变量的地址=0xc00009a000handle(a)fmt.Printf("【打印数组信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)//【打印数组信息】//len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 0],a自身的地址为&c=0xc000088020,a变量指向的目标变量的地址=0xc00009a000}func handle(a []int) {fmt.Printf("【打印数组信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)//【打印数组信息】//len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 0],a自身的地址为&c=0xc000088080,a变量指向的目标变量的地址=0xc00009a000a = append(a, 4555)fmt.Printf("【打印数组信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)//【打印数组信息】//len(a)=3, cap(a)=10,// a变量指向的目标变量的值=[0 0 4555],a自身的地址为&c=0xc000088080,a变量指向的目标变量的地址=0xc00009a000}
实在想要在函数内改变切片头部(slice header,有经验的gopher都这么叫),可以用传递切片的指针:
func handleSliceByPointer(a *[]int) {(*a)[1] = 3444*a = append(*a, 3)}func test8() {var a = make([]int, 2, 10)fmt.Printf("【打印数组信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)// len(a)=2, cap(a)=10,// a变量指向的目标变量的值=[0 0],a自身的地址为&c=0xc00000c060,a变量指向的目标变量的地址=0xc00001e050handleSliceByPointer(&a)fmt.Printf("【打印数组信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)// len(a)=3, cap(a)=10,// a变量指向的目标变量的值=[0 3444 3],a自身的地址为&c=0xc00000c060,a变量指向的目标变量的地址=0xc00001e050}
append 实现复制切片
// Make a copy of a slice (of int).slice3 := append([]int(nil), slice...)fmt.Println("Copy a slice:", slice3)
append 为什么要以内建函数提供?
A weakness of Go is that any generic-type operations must be provided by the run-time. Some day that may change, but for now, to make working with slices easier, Go provides a built-in generic append function. It works the same as our int slice version, but for any slice type. Go 的一个缺点是任何泛型操作只能在运行时提供。 以后可能会提供泛型,但是现在,为了简化切片操作,Go 提供了一个内置的通用的 append 方法。
- 因为 append 函数的定义是这样的:
func append(slice []Type, elems ...Type) []Type - Type 说明支持各种类型,但是现在这种泛型只能在运行时提供。
- (更详细还不懂:例如为什么运行时就可以知道 type 是什么类型?用反射吗?,待研究 todo)
append 实现原理(包含扩容机制)
append 实现雏形
引用自官方博客
// Append appends the elements to the slice.// Efficient version.func Append(slice []int, elements ...int) []int {n := len(slice)total := len(slice) + len(elements)if total > cap(slice) {// Reallocate. Grow to 1.5 times the new size, so we can still grow.newSize := total*3/2 + 1newSlice := make([]int, total, newSize)copy(newSlice, slice)slice = newSlice}slice = slice[:total]copy(slice[n:], elements)return slice}
- 这里的教学例子只可以当做一个雏形
扩容的源码
在 /go/src/runtime/slice.go 文件中:
// 摘抄 go1.13// growslice handles slice growth during append.// It is passed the slice element type, the old slice, and the desired new minimum capacity,func growslice(et *_type, old slice, cap int) slice {...newcap := old.capdoublecap := newcap + newcapif cap > doublecap {newcap = cap} else {if old.len < 1024 {newcap = doublecap} else {// Check 0 < newcap to detect overflow// and prevent an infinite loop.for 0 < newcap && newcap < cap {newcap += newcap / 4}// Set newcap to the requested cap when// the newcap calculation overflowed.if newcap <= 0 {newcap = cap}}}// ...capmem = roundupsize(uintptr(newcap)) // 这个方法实际上是在一个switch中执行,但是每个分支都会执行到,所以直接放外面助于理解// ...newcap = int(capmem)// ...return slice{p, old.len, newcap}}
实际例子看扩容源码
- 看完下图main函数中三行代码,按理说新容量最低需要5个元素,大于2倍原容量,新容量应该是5,但是输出却是6,为什么呢?
- 因为还要考虑内存分配算法,5个元素,一个元素占用8个字节(int类型,笔者是64位OS),所以本需要40Bytes,经 roundupsize 方法向上取整后是48Bytes,那么切片的新容量是48/8=6。

- 草稿图解参考该文章https://juejin.im/post/5ca2b75f51882543ea4b81c8#heading-7
- 总结下来就是:
- 如果双倍原容量都满足不了你现在需要的最低容量
- 那么新切片的容量=你现在需要的最低容量(代码已验证)
- 否则
- 如果切片原长度(注意不是容量)小于1024,那么直接翻倍(代码已验证)
- 如果长度大于1024,那么 每次加上四分之一的旧容量,直到大于等于你现在需要的最低容量(可以使用vscode用sudo权限更改相应的源码打断点调试验证)
- 最后,还要考虑扩容时分配到的内存块大小,即源码中的 roundupsize 函数!它比对你需要的容量和golang内存管理中预设好的小内存块,向上取整,才能得出最终新容量
- 比如说,你扩容算出来需要40byte的内存空间,但是golang预设的空间块有32的,48的,反正没有40的,那么就要向上取整取48了,在反过来计算回去是多少个元素,48/8=6个元素;
- 那为什么是8、16、32、48…这样的序列呢?(就是那两个魔法数组怎么来的),猜测是golang的内存管理这么预设好的了,就不用每次频繁向操作系统申请内存了。todo
- roundupsize 方法的代码提交作者认为: When growing slice take into account size of the allocated memory block. 来自stackoverflow该问题
- 这篇博客也有讲解到向上取整这一点:http://www.phpxs.com/post/7380
- 如果双倍原容量都满足不了你现在需要的最低容量
再来看大于阈值时的roundupsize函数
- 其中,
a &^ b位运算的作用是:将a与b相异的位保留,相同位清零
func test4444(){a:=make([]int,1025)fmt.Printf("cap(a)=%v\n",cap(a))a=append(a,make([]int,9999)...)// 1025+9999=11024// 11024*8=88192// 88192向上取整为90112 (源码中的取整公式 (n + a - 1) &^ (a - 1) a=8192固定常量)// 最终容量为 90112/8=11264fmt.Printf("cap(a)=%v\n",cap(a))}
append后底层是新数组还是旧数组的验证实验
直接通过代码来验证,验证过程遇到的问题都记录下来。
第一次验证试验,代码如下。append后还是赋值给c
- 结果c的地址不变
func main() {var c=make([]int,2,2)fmt.Printf(" len(c)=%v, cap(c)=%v, c=%v,&c=%p\n",len(c),cap(c),c,&c)c = append(c, 45,34,45)fmt.Printf(" len(c)=%v, cap(c)=%v, c=%v,&c=%p\n",len(c),cap(c),c,&c)}// 结果len(c)=2, cap(c)=2, c=[0 0],&c=0xc000088020len(c)=5, cap(c)=6, c=[0 0 45 34 45],&c=0xc000088020
- 容易产生疑问:为什么不变?不是说容量不够引发扩容产生新底层数组吗?
- 有这种疑问是有误区,理解不到位导致的。
- c 是一个引用类型的变量,这个变量存放的数据是:
【所引用的变量】的地址 - 然而 c 本身既然是是变量,那它也有地址,这个地址就是 &c=0xc000088020
- 那怎么查看 c 指向的或者 c 指向的变量的地址呢?用这个:
fmt.Printf("c=%p",c),而不要用%v
第二次验证试验,用新变量接收append的返回值
func main() {var c=make([]int,2,2)fmt.Printf(" len(c)=%v, cap(c)=%v, c=%v,&c=%p\n",len(c),cap(c),c,&c)new_c:= append(c, 45,34,45)fmt.Printf(" len(new_c)=%v, cap(new_c)=%v, new_c=%v,&new_c=%p\n",len(new_c),cap(new_c),new_c,&new_c)}// 结果:len(c)=2, cap(c)=2, c=[0 0],&c=0xc000088020len(new_c)=5, cap(new_c)=6, new_c=[0 0 45 34 45],&new_c=0xc000088060
- 第一次验证试验看懂了后,这个也能懂。
- new_c 地址和 c 不一样,所以说明是返回了新数组对吗?不对!
- new_c 是一个新的引用类型变量,所以地址肯定不一样啦,这个试验压根就没验证到。
第三次验证试验
func main() {testSlice()}func testSlice() {var c = make([]int, 0, 2)fmt.Printf("[testEnoughSlice1] len(c)=%v, cap(c)=%v, c变量指向的目标变量的值=%v,c自身的地址为&c=%p,c变量指向的目标变量的地址=%p \n", len(c), cap(c), c, &c,c)c = append(c, 3)fmt.Printf("[testEnoughSlice2] len(c)=%v, cap(c)=%v, c变量指向的目标变量的值=%v,c自身的地址为&c=%p,c变量指向的目标变量的地址=%p \n", len(c), cap(c), c, &c,c)c = append(c, 4)fmt.Printf("[testEnoughSlice3] len(c)=%v, cap(c)=%v, c变量指向的目标变量的值=%v,c自身的地址为&c=%p,c变量指向的目标变量的地址=%p \n", len(c), cap(c), c, &c,c)c = append(c, 5)fmt.Printf("[testEnoughSlice4] len(c)=%v, cap(c)=%v, c变量指向的目标变量的值=%v,c自身的地址为&c=%p,c变量指向的目标变量的地址=%p \n", len(c), cap(c), c, &c,c)c = append(c, 5,6,6,6,6,6,6,6,6,6,6,6,6,6,6)fmt.Printf("[testEnoughSlice5] len(c)=%v, cap(c)=%v, c变量指向的目标变量的值=%v,c自身的地址为&c=%p,c变量指向的目标变量的地址=%p \n", len(c), cap(c), c, &c,c)}// 结果[testEnoughSlice1] len(c)=0, cap(c)=2, c变量指向的目标变量的值=[],c自身的地址为&c=0xc00000c060,c变量指向的目标变量的地址=0xc00001c070[testEnoughSlice2] len(c)=1, cap(c)=2, c变量指向的目标变量的值=[3],c自身的地址为&c=0xc00000c060,c变量指向的目标变量的地址=0xc00001c070[testEnoughSlice3] len(c)=2, cap(c)=2, c变量指向的目标变量的值=[3 4],c自身的地址为&c=0xc00000c060,c变量指向的目标变量的地址=0xc00001c070[testEnoughSlice4] len(c)=3, cap(c)=4, c变量指向的目标变量的值=[3 4 5],c自身的地址为&c=0xc00000c060,c变量指向的目标变量的地址=0xc0000161a0[testEnoughSlice5] len(c)=18, cap(c)=18, c变量指向的目标变量的值=[3 4 5 5 6 6 6 6 6 6 6 6 6 6 6 6 6 6],c自身的地址为&c=0xc00000c060,c变量指向的目标变量的地址=0xc00008e000
- 这次完美验证了。
并发下使用slice
- 方法一:并发下可以通过加锁,否则可能写操作相互覆盖
- 方法二: 由于 slice 并发读与写不冲突,所以可以利用 chanel 让读写分离即可达到我们的预期:
// channel 解决并发读写 slicefunc test25() {msgCh := make(chan int, 500)slice := make([]int,0,1000)go func() {for {a := <-msgChslice = append(slice, a)}}()go func() {for i := 0; i < 100; i++ {time.Sleep(1 * time.Second)msgCh<-i}}()for i := 0; i < 100; i++ {time.Sleep(1 * time.Second)fmt.Printf("slice=%v",slice)}}
- 但是map就不行了,map不能并发读写,否则panic。
slice 是引用类型吗?
- 官方在这篇 Go maps in action 文章提到了“引用类型”
- 本文明确指出,map,指针和slice都是引用类型。 而且似乎也暗示了任何零值为nil的类型也是引用类型。
Map types are reference types, like pointers or slices, and so the value of m above is nil; …
- 官方还有一个提到“引用”(仅仅是引用而不是引用类型)的地方是在 Go FAQ
Why are maps, slices, and channels references while arrays are values? There’s a lot of history on that topic. Early on, maps and channels were syntactically pointers and it was impossible to declare or use a non-pointer instance. Also, we struggled with how arrays should work. Eventually we decided that the strict separation of pointers and values made the language harder to use. Changing these types to act as references to the associated, shared data structures resolved these issues. This change added some regrettable complexity to the language but had a large effect on usability: Go became a more productive, comfortable language when it was introduced. 关于这个话题有很多历史。 早期,映射和通道在语法上是指针,并且不可能声明或使用非指针实例。 此外,我们在数组应如何工作方面也遇到了困难。 最终,我们决定严格区分指针和值,使该语言更难使用。 更改这些类型以用作对关联的共享数据结构的引用解决了这些问题。 这项更改使该语言增加了一些令人遗憾的复杂性,但对可用性产生了很大影响:引入后 Go 成为一种更具生产力,更舒适的语言。
- go101 作者对Go引用类型的看法:https://github.com/go101/go101/wiki/About-the-terminology-“reference-type”-in-Go
- 还有篇博文:https://www.tapirgames.com/blog/golang-has-no-reference-values
- 综上总结,既然Go官方已经表明他们是引用类型,那就说明Golang和Python一样,将含有指向底层内存空间指针的抽象结构体,可以视为引用类型。
而其他一些语言中,引用的本质其实是 struct 中包含指针,比如 Python。下面的 C 结构是 Python 中列表类型的底层结构。 现在看来,引用的实现主要有两种。一是 C++ 的思路,引用其实一种便于使用指针的语法糖,和我们想象中的别名含义一致。二是类似 Python 中的实现,底层结构中包含指向实际内容的指针。 当然,或许还有其他的实现方式,但核心应该是不变的。 ——《一文理清 Go 引用的常见疑惑》
易错点:make一个0长度但指定容量的切片,然后赋值
正确赋值示例:
s := make([]int, 0, 3)for i := 0; i < 5; i++ {s = append(s, i)fmt.Printf("cap %v, len %v, %p\n", cap(s), len(s), s)}
结果:
cap 3, len 1, 0x1040e130cap 3, len 2, 0x1040e130cap 3, len 3, 0x1040e130cap 6, len 4, 0x10432220cap 6, len 5, 0x10432220
错误赋值示例
func main() {var c=make([]int,0,10)fmt.Printf("var c=make([]int,0,10)\n len(c)=%v,cap(c)=%v,c=%v\n",len(c),cap(c),c)c[0]=3}
结果:
len(c)=0,cap(c)=10,c=[]panic: runtime error: index out of range [0] with length 0
- 怎么理解这个错误使用方式?
- 因为 slice[n] 能访问到或者能被赋值的前提是首先切片这个数据结构要存在这个元素,现在就是没有存在这个元素呀,只能用append。
- 那只能:要么分配有长度然后每个元素默认初始化为零值然后再赋值,要么分配0长度但是使用append吗?
还可以这样:(append方法就是这么干的)
// 探究 0 长度但是容量够的切片怎么赋值?func test23(){var a = make([]int,0,10)a=a[0:3]a[2]=5fmt.Printf("a=%v,len(a)=%v;cap(a)=%v",a,len(a),cap(a))// 打印结果 a=[0 0 5],len(a)=3;cap(a)=10}
字符串string 、字节切片[]byte、数组array
- Go语言中数组、字符串和字节切片三者是密切相关的数据结构
- 他们在底层原始数据有着相同的内存结构,在上层,因为语法的限制而有着不同的行为表现
array 数组
- Go语言的数组是一种值类型,虽然数组的元素可以被修改,但是数组本身的赋值和函数传参都是以整体复制的方式处理的,也即值传递
string 字符串
- Strings are actually very simple: they are just read-only slices of bytes with a bit of extra syntactic support from the language.
- 即是说,字符串是一个只读的(且值传递的)字节切片;再加上额外一点语法支持
- 那是什么语法支持?
- 语法上限制不能修改字符串底层数组的元素
- 和字节切片互转时自动复制一个字符串底层数组
- string 被设计为不能更改,所以它也没有cap属性!记住!
- Go语言字符串底层数据也是对应的字节数组,但是字符串的只读属性禁止了在程序中对底层字节数组的元素的修改,下面代码验证了这点。
func test1(){var a ="abcdefg"// a[0]='f' // 编译不通过:cannot assign to a[0]println(a[0]) // 打印结果为 97}
- 并且字符串是值类型,赋值将导致数据复制,量多的时候对内存不友好
- 字符串其他只读操作可以和字节切片一样:
usr := "/usr/ken"[0:4] // usr="/usr"
- string和[]byte互转类型
str := string(slice)和slice := []byte(usr)string和[]byte可以互转- The array underlying a string is hidden from view; there is no way to access its contents except through the string. That means that when we do either of these conversions, a copy of the array must be made. Go takes care of this, of course, so you don’t have to. After either of these conversions, modifications to the array underlying the byte slice don’t affect the corresponding string.
- 字符串的底层数组是被隐藏的; 除了通过字符串,无法访问其内容。
- 这意味着当我们将string和[]byte可以互转时,都必须复制该数组。
- 当然,Go会照顾好这一点,因此gopher不必这样做。
- 两个类型互转后,对字节切片底层数组的修改不会影响原始字符串
- 这里待代码验证!todo
- An important consequence of this slice-like design for strings is that creating a substring is very efficient. All that needs to happen is the creation of a two-word string header. Since the string is read-only, the original string and the string resulting from the slice operation can share the same array safely.
- 这种类似切片的字符串设计的一个重要成果是,创建子字符串非常有效:所有需要发生的就是创建两个字的 string header。
- 由于该字符串是只读的,因此 原始字符串 和 “切片操作产生的字符串” 可以安全地共享同一数组。
- 官方博客讲解string:https://blog.golang.org/strings
陷阱
仅需要底层数组的一小部分,却在内存中保留了整个数组
// 对切片进行重新切片不会复制基础数组。 完整的数组将保留在内存中,直到不再被引用为止// 然后,这段代码表示,如果需要的数据只是切片中的一小部分,但是 Find 方法应该是新建了slice指向那个底层数组的(todo:这个find就不能copy一个新的slice返回?),又被引用了// 导致为了一点点的几个元素,却保留了整个底层数组在内存中造成浪费func test11() []byte {a := []byte{'3','4','c','c','x'}fmt.Printf("【打印切片信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)// 【打印切片信息】// len(a)=5, cap(a)=5,// a变量指向的目标变量的值=[51 52 99 99 120],a自身的地址为&c=0xc00000c080,a变量指向的目标变量的地址=0xc00001c05ab := regexp.MustCompile("[0-9]+").Find(a)fmt.Printf("【打印切片信息】\n len(b)=%v, cap(b)=%v, \n b变量指向的目标变量的值=%v,b自身的地址为&b=%p,b变量指向的目标变量的地址=%p \n", len(b), cap(b), b, &b, b)//【打印切片信息】// len(b)=2, cap(b)=2,// b变量指向的目标变量的值=[51 52],b自身的地址为&b=0xc00000c0e0,b变量指向的目标变量的地址=0xc00001c05areturn b}func main() {t := test11()fmt.Printf("【打印切片信息】\n len(b)=%v, cap(t)=%v, \n t变量指向的目标变量的值=%v,t自身的地址为&t=%p,t变量指向的目标变量的地址=%p \n", len(t), cap(t), t, &t, t)//【打印切片信息】// len(b)=2, cap(t)=2,// t变量指向的目标变量的值=[51 52],t自身的地址为&t=0xc00000c060,t变量指向的目标变量的地址=0xc00001c05a}
上面的代码,说明了两个问题:
- 第一:
- golang语言中,在函数里面定义的变量,是存放在栈区没错,按理说是函数返回即刻释放;
- 但是上述代码,test11方法中的b变量的底层数组是在函数内创建的,但是在return后,main方法中t的底层数组指针指向b的底层数组,而且在main方法仍能访问到这个底层数组。所以return后被引用到了;
- 综上,验证了golang会对栈区中的变量进行判断,如果有被引用,就不会释放栈区中的变量所占的空间。
- 第二:
- 对切片进行重新切片不会复制基础数组。 完整的数组将保留在内存中,直到不再被引用为止
- 然后,这段代码表示,如果需要的数据只是切片中的一小部分,但是 Find 方法应该是新建了slice指向那个底层数组的(todo:这个find就不能copy一个新的slice返回?),又被引用了
- 导致为了一点点的几个元素,却保留了整个底层数组在内存中造成浪费
针对第二个问题,做改进,可以用 copy 或者 append 解决,代码如下
- 使用copy
// 使用 copy 优化 test11 的问题func test11_v2() []byte{a := []byte{'3','4','c','c','x'}fmt.Printf("【打印切片信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&c=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)// 【打印切片信息】// len(a)=5, cap(a)=5,// a变量指向的目标变量的值=[51 52 99 99 120],a自身的地址为&c=0xc000088040,a变量指向的目标变量的地址=0xc000098002b := regexp.MustCompile("[0-9]+").Find(a)fmt.Printf("【打印切片信息】\n len(b)=%v, cap(b)=%v, \n b变量指向的目标变量的值=%v,b自身的地址为&b=%p,b变量指向的目标变量的地址=%p \n", len(b), cap(b), b, &b, b)//【打印切片信息】// len(b)=2, cap(b)=2,// b变量指向的目标变量的值=[51 52],b自身的地址为&b=0xc0000880a0,b变量指向的目标变量的地址=0xc000098002// 改进:仅复制需要的元素到新开辟的空间result:=make([]byte,len(b))copy(result,b)return result}func main() {t := test11_v2()fmt.Printf("【打印切片信息】\n len(b)=%v, cap(t)=%v, \n t变量指向的目标变量的值=%v,t自身的地址为&t=%p,t变量指向的目标变量的地址=%p \n", len(t), cap(t), t, &t, t)//【打印切片信息】// len(b)=2, cap(t)=2,// t变量指向的目标变量的值=[51 52],t自身的地址为&t=0xc000088020,t变量指向的目标变量的地址=0xc000098048}
- 使用append
···result:=make([]byte,0,len(b))result=append(result,b...)···
扩容导致底层数组改变的例子
以下代码带着问题看:
a[2]和b[2]相等吗?为什么?- a追加0元素时,扩容为2;追加2时又扩容到4,由于b是指向扩容到4前的a的底层数组,所以,从a追加2时,A和B就指向不同的底层数组了。
c[3]和d[3]相等吗?为什么?- c 追加0元素时,扩容到4,d这时候指向c的底层数组,分别追加,这时候都是同一个底层数组,所以谁最后改,结果就是谁的修改值
func test13() {a := []int{0}a = append(a, 0)b := a[:]a = append(a, 2)b = append(b, 1)fmt.Printf("【打印切片信息】\n len(a)=%v, cap(a)=%v, \n a变量指向的目标变量的值=%v,a自身的地址为&a=%p,a变量指向的目标变量的地址=%p \n", len(a), cap(a), a, &a, a)fmt.Printf("【打印切片信息】\n len(b)=%v, cap(b)=%v, \n b变量指向的目标变量的值=%v,b自身的地址为&a=%p,b变量指向的目标变量的地址=%p \n", len(b), cap(b), b, &b, b)c := []int{0, 0}c = append(c, 0)d := c[:]c = append(c, 2)d = append(d, 1)fmt.Printf("【打印切片信息】\n len(c)=%v, cap(c)=%v, \n c变量指向的目标变量的值=%v,c自身的地址为&c=%p,c变量指向的目标变量的地址=%p \n", len(c), cap(c), c, &c, c)fmt.Printf("【打印切片信息】\n len(d)=%v, cap(d)=%v, \n d变量指向的目标变量的值=%v,d自身的地址为&c=%p,d变量指向的目标变量的地址=%p \n", len(d), cap(d), d, &d, d)// 结果:// 【打印切片信息】// len(a)=3, cap(a)=4,// a变量指向的目标变量的值=[0 0 2],a自身的地址为&a=0xc00000c060,a变量指向的目标变量的地址=0xc000016180//【打印切片信息】// len(b)=3, cap(b)=4,// b变量指向的目标变量的值=[0 0 1],b自身的地址为&a=0xc00000c080,b变量指向的目标变量的地址=0xc0000161a0//【打印切片信息】// len(c)=4, cap(c)=4,// c变量指向的目标变量的值=[0 0 0 1],c自身的地址为&c=0xc00000c120,c变量指向的目标变量的地址=0xc0000161c0//【打印切片信息】// len(d)=4, cap(d)=4,// d变量指向的目标变量的值=[0 0 0 1],d自身的地址为&c=0xc00000c140,d变量指向的目标变量的地址=0xc0000161c0}
防止内存拷贝
filter类,根据过滤条件原地删除切片元素的算法
根据过滤条件原地删除切片元素的算法,都可以采用如下方式处理(因为是删除操作不会出现内存不足的情形):
func Filter(s []byte, fn func(x byte) bool) []byte {b := s[:0]for _, x := range s {if !fn(x) {b = append(b, x)}}// 如果是元素为指针类型,还要记得释放无用元素所占用的空间,下文也会开小标题讲到for i := len(b); i < len(s); i++ {s[i] = nil // or the zero value of T}return b}
切片高效操作的要点是:
- 尽量保证append操作不会超出cap的容量,
- 降低触发内存分配的次数和每次分配内存大小。
insert类操作
- 如下操作目的是,将 x 元素插入到 a 切片的第 i 处
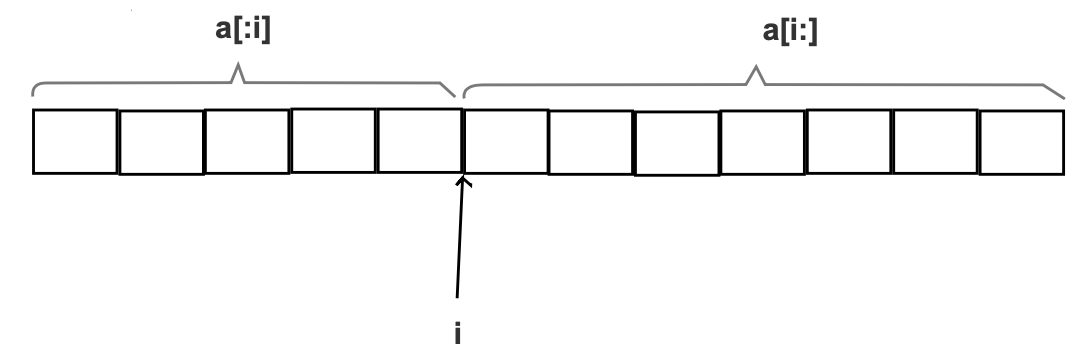
a = append(a[:i], append([]T{x}, a[i:]...)...)
- 但是上述的操作存在问题:
- 里面的 append 发生了一次拷贝;
- 然后外面的append又发生了一次拷贝
下面做了改进(只有一次拷贝了):
s = append(s, 0) // 使用零值,这里是int,所以零值是0 ; 这里的目的是保证cap足够,否则下一步copy的时候判断到目标数组容量不够,就丢数据了!!copy(s[i+1:], s[i:])s[i] = x
记得释放无用元素占用的内存空间,防止内存泄漏
Cut
a = append(a[:i], a[j:]...)
Delete
a = append(a[:i], a[i+1:]...)// ora = a[:i+copy(a[i:], a[i+1:])]
Delete without preserving order
a[i] = a[len(a)-1]a = a[:len(a)-1]
- 注意,如果元素的类型是指针或带有指针字段的结构,需要进行垃圾收集(如果是普通的int、string,那没事,等着这个 sliceHeader )
- 那上面的Cut和Delete实现有一个潜在的内存泄漏问题:具有值的某些元素仍然被切片a引用(即“无用元素”指向的内存空间仍然被底层数组引用,这片空间有值有数据),因此无法被垃圾回收(这涉及到go内存回收器的知识)
下面是改进方法:
Cut
- 图解:
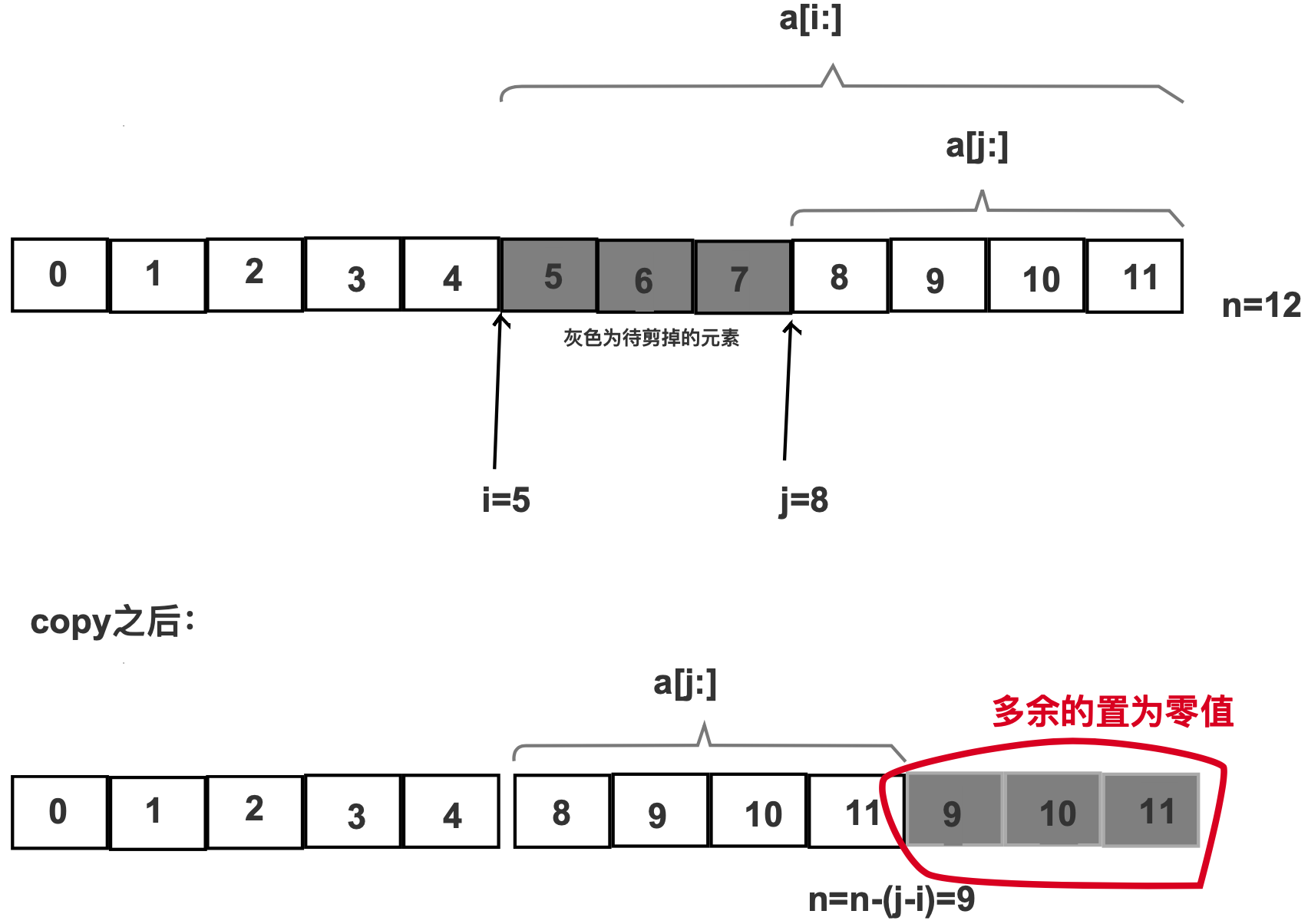
// 注意,这里为了教学使用的是copy,不是append,所以不能写成copy(a[:i],a[j:]);当然和上面一样使用 append(a[:i],a[j:]) 也是可以的copy(a[i:], a[j:])for k, n := len(a)-j+i, len(a); k < n; k++ {a[k] = nil // or the zero value of T}a = a[:len(a)-j+i]
Delete
copy(a[i:], a[i+1:])a[len(a)-1] = nil // or the zero value of Ta = a[:len(a)-1]
Delete without preserving order(不保存顺序的删除。即是说,把要删除的置为最后一个元素的值,然后去掉最后一个元素就好了,这样减少时间复杂度,不用去遍历)
a[i] = a[len(a)-1]a[len(a)-1] = nila = a[:len(a)-1]
slice 使用技巧
翻转
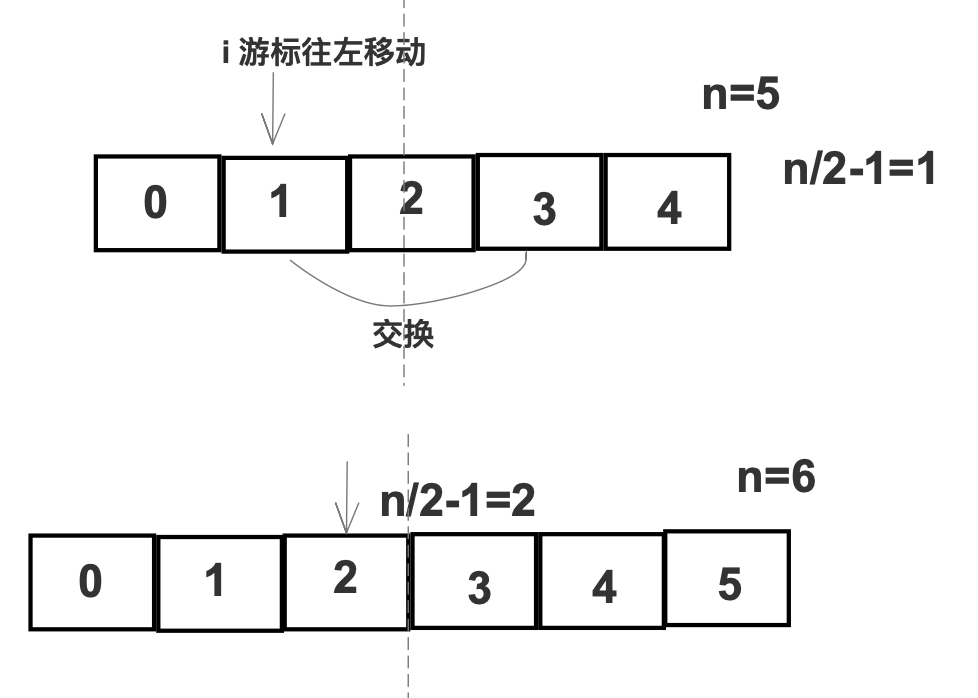
for i := len(a)/2-1; i >= 0; i-- {opp := len(a)-1-ia[i], a[opp] = a[opp], a[i]}// 或者:for left, right := 0, len(a)-1; left < right; left, right = left+1, right-1 {a[left], a[right] = a[right], a[left]}
洗牌
// 算法名称:Fisher–Yates algorithm// Since go1.10, this is available at math/rand.Shufflefunc shuffle(a []int){// 遍历每个元素,每次遍历都产生一个随机索引,"当前遍历到的元素"与"当前随机索引到的元素"交换,即可。for i := len(a) - 1; i > 0; i-- {rand.Seed(time.Now().Unix())j := rand.Intn(i + 1) // 因为此方法返回的值范围是[0,n),所以要加一a[i], a[j] = a[j], a[i]}}
- 注意:使用交换元素可以避免新分配一个切片去存。(新手一般会是这样一个思路:make一个空数组,然后产生随机索引,将这个索引对应的元素添加到空数组中。这样就不如交换好了~)
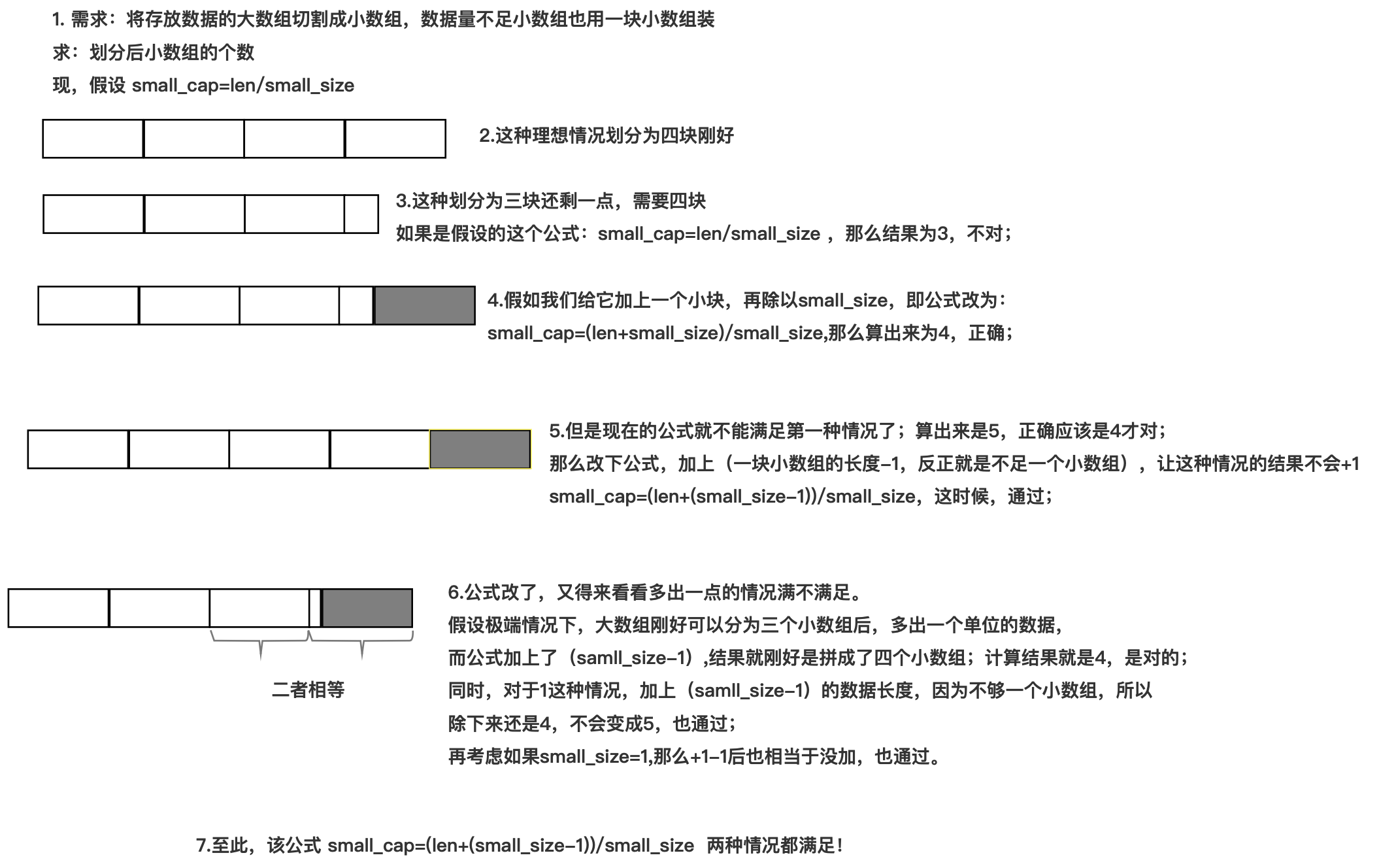
切割大切片为n个小切片
actions := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}batchSize := 3// batches的容量为什么这么计算?batches := make([][]int, 0, (len(actions) + batchSize - 1) / batchSize)// len(actions) 逐渐减少,直到终止循环for batchSize < len(actions) {batches = append(batches, actions[0:batchSize:batchSize])actions = actions[batchSize:]}// 不要忘记把最后剩下的append进去batches = append(batches, actions)// 结果 batches = [ [0 1 2] [3 4 5] [6 7 8] [9] ]
batches的容量为什么这么计算,如何理解?
cap=(len(actions) + batchSize - 1) / batchSize)
原地去重
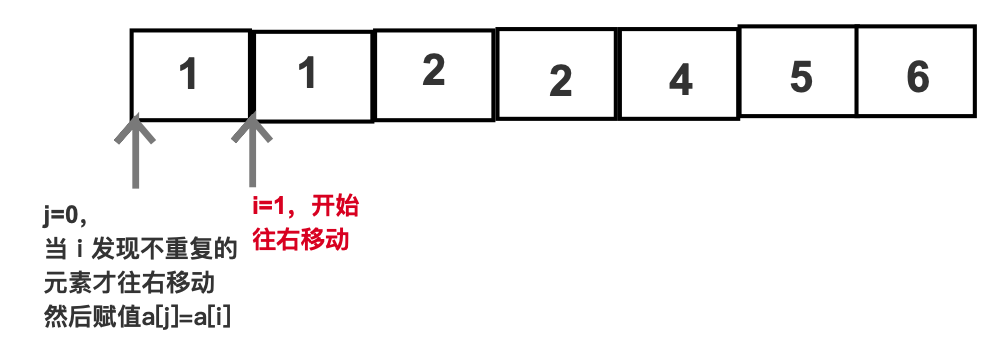
in := []int{3,2,1,4,3,2,1,4,1} // any item can be sorted// 如果没有先排好序,那么sort.Ints(in)j := 0for i := 1; i < len(in); i++ {if in[j] == in[i] {continue}j++in[j] = in[i]}result := in[:j+1]fmt.Println(result) // [1 2 3 4]
将某个元素提到最前面
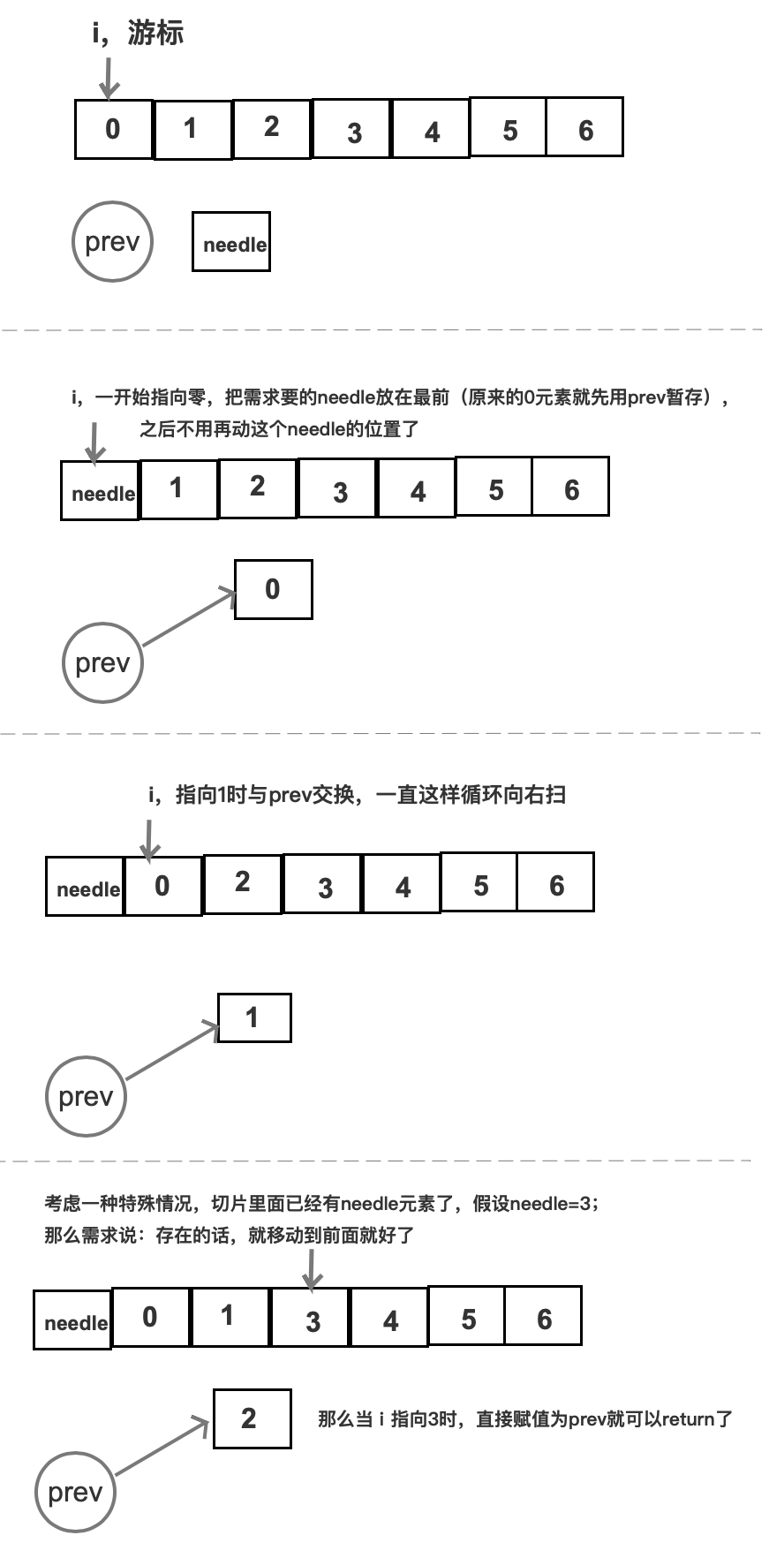
// moveToFront moves needle to the front of haystack, in place if possible.func moveToFront(needle string, haystack []string) []string {if len(haystack) == 0 || haystack[0] == needle {return haystack}var prev stringfor i, elem := range haystack {switch {case i == 0:haystack[0] = needleprev = elemcase elem == needle:haystack[i] = prevreturn haystackdefault:haystack[i] = prevprev = elem}}return append(haystack, prev)}haystack := []string{"a", "b", "c", "d", "e"} // [a b c d e]haystack = moveToFront("c", haystack) // [c a b d e]haystack = moveToFront("f", haystack) // [f c a b d e]
- 使用 switch case 避免太多 if else 影响阅读,是代码实现的一个亮点
滑动窗口
- 下面代码以每次滑动一个元素为例
func slidingWindow(size int, input []int) [][]int {// returns the input slice as the first elementif len(input) <= size {return [][]int{input}}// 为什么这么计算 len(input)-size+1 = len(input)-(size-1)r := make([][]int, 0, len(input)-size+1)for i, j := 0, size; j <= len(input); i, j = i+1, j+1 {r = append(r, input[i:j])}return r}func test22(){a:=[]int{1,2,3,4,5,6}b:=slidingWindow(3,a)fmt.Printf("b=%+v", b)// 打印结果 :b=[ [1 2 3] [2 3 4] [3 4 5] [4 5 6] ]}
- 怎么计算滑动窗口的个数

更多
- Go官方博客解析slice、append:https://blog.golang.org/slices
- slice技巧、slice wiki go官方:https://github.com/golang/go/wiki/SliceTricks
- The Go Slices blog(https://blog.golang.org/go-slices-usage-and-internals) post describes the memory layout details with clear diagrams.
- Russ Cox’s Go Data Structures (https://research.swtch.com/godata) article includes a discussion of slices along with some of Go’s other internal data structures
- 《GO高级编程》https://chai2010.gitbooks.io/advanced-go-programming-book/content/ch1-basic/ch1-03-array-string-and-slice.html

若有收获,就点个赞吧
0 人点赞
