任务原理
此次任务是基于RoFormer的微调阶段去做的和Bert模型结构类似,输入句子获取这个句子的向量,然后计算两个句子的余弦距离得到两个句子的相似度。
完成任务的前提希望能对Bert有了解。在此不做介绍。下图是Bert的embedding阶段。它会经过Bert的预训练的Masked LM 和Next Sentence Prediction (NSP)这个2个任务完成。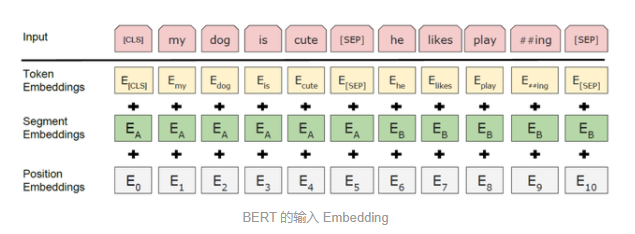
所以我们只需要将句子整理成Bret的输入格式,[CLS] 的向量就可以表示这个句子。
实战
- 首先加载模型,预训练模型可以自行到GitHub上下载RoFormer_pytorch。
import torchimport torch.nn as nnfrom transformers import RoFormerModelclass RoFormerModel(nn.Module):def __init__(self):super().__init__()self.bert = RoFormerModel.from_pretrained("../bert_pretrain")self.bert.training = Falsefor param in self.bert.parameters():param.requires_grad = Falsedef forward(self, x):pooled = self.bert(**x).last_hidden_statepooled = pooled[0][0].reshape(-1, 768)return pooled
BertTokenizer对句子进行切分
tokenizer = RoFormerTokenizer.from_pretrained("../bert_pretrain")token = tokenizer("你好, 世界")print(token)
输出结果:
{'input_ids': tensor([[ 101, 38183, 13598, 4209, 2229, 1101, 11667, 10120, 1401, 2110,33354, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
还可以通过以下方式获取这个句子的token_id
pt_inputs_1 = tokenizer.tokenize(text1)print(tokenizer.convert_tokens_to_ids(pt_inputs_1))
输出结果:
[38183, 13598, 4209, 2229, 1101, 11667, 10120, 1401, 2110, 33354]
这就是Bert微调模型的输入数据,后续输入到BretModel模型中就可以得到表示这个句子的向量了
项目的完整代码 ```python class SentenceSimilarity():
def init(self):
self.tokenizer = RoFormerTokenizer.from_pretrained("../bert_pretrain")self.model = RoFormerModel()# 预测模式self.model.eval()
def sentence_similarity(self, text_1, text_2):
sentence1_token = self.tokenizer(text_1, return_tensors="pt")sentence2_token = self.tokenizer(text_2, return_tensors="pt")sentence1_token_vector = self.model(sentence1_token)sentence2_token_vector = self.model(sentence2_token)cosine = torch.cosine_similarity(sentence1_token_vector, sentence2_token_vector)data = {"txt_1": text_1,"txt_2": text_2,"cosine": cosine}return data
def run(self):
text1 = input()text2 = input()print(self.sentence_similarity(text1, text2))
if name == ‘main‘: SentenceSimilarity().run()
<a name="cmXTU"></a>### 测试效果例1:
{‘txt_1’: ‘赵立坚回应英方在华为安插情报人员’, ‘txt_2’: ‘外交部回应英方在华为内部安插间谍’, ‘cosine’: tensor([0.9383])}
例2:
{‘txt_1’: ‘汤加火山喷发首例死者身份确认’, ‘txt_2’: ‘在汤加失联山东教授夫妇确认平安’, ‘cosine’: tensor([0.8254])}
例3:
{‘txt_1’: ‘31省份昨日新增127例本土确诊’, ‘txt_2’: ‘31省份新增本土确诊127例 天津18例’, ‘cosine’: tensor([0.9420])}
例子4:
{‘txt_1’: ‘汤加火山喷发首例死者身份确认’, ‘txt_2’: ‘31省份新增本土确诊127例 天津18例’, ‘cosine’: tensor([0.7073])} ```

若有收获,就点个赞吧
0 人点赞
