集群架构的介绍
分布式 和 集群是不一样的
分布式一定是集群 集群不一定是分布式
分布式:将一个系统的功能模块 拆分成多个模块
集群: 一个功能模块 部署成多分 一个应用复制多分构成集群
一致性hash
hash算法应用场景
安全加密领域
数据存储查找过程中 较多使用的场景
为啥需要使用hash
场景
负载均衡
存储定位
普通hash存在的问题
求余数的算法 但是数量变了 需要从新hash
我们需要一致性hash来解决这个问题
一致性hash算法
核心的概念 : 环,2的32次方-1 ,地址,虚拟hash节点
一个节点负责一个hash 段
每个节点 的hash 段要均衡
手写一致性hash 算法
public static void main(String[] args) {// 定义客户端IPString[] clients = new String[]{"10.78.12.3","113.25.63.1","126.12.3.8"};// 定义服务器数量int serverCount = 5;// (编号对应0,1,2)// hash(ip)%node_counts=index//根据index锁定应该路由到的tomcat服务器for(String client: clients) {int hash = Math.abs(client.hashCode()); // 重要int index = hash%serverCount; // 重要System.out.println("客户端:" + client + " 被路由到服务器编号为:" + index);}}
public static void main(String[] args) {
//step1 初始化:把服务器节点IP的哈希值对应到哈希环上
// 定义服务器ip
String[] tomcatServers = new String[]{"123.111.0.0","123.101.3.1","111.20.35.2","123.98.26.3"};
SortedMap<Integer,String> hashServerMap = new TreeMap<>();
for(String tomcatServer: tomcatServers) {
// 求出每一个ip的hash值,对应到hash环上,存储hash值与ip的对应关系
int serverHash = Math.abs(tomcatServer.hashCode());
// 存储hash值与ip的对应关系
hashServerMap.put(serverHash,tomcatServer);
}
//step2 针对客户端IP求出hash值
// 定义客户端IP
String[] clients = new String[]{"10.78.12.3","113.25.63.1","126.12.3.8"};
for(String client : clients) {
int clientHash = Math.abs(client.hashCode());
//step3 针对客户端,找到能够处理当前客户端请求的服务器(哈希环上顺时针最近)
// 根据客户端ip的哈希值去找出哪一个服务器节点能够处理()
// 关键信息
SortedMap<Integer, String> integerStringSortedMap = hashServerMap.tailMap(clientHash); // 返回大于这个key的全部内容
if(integerStringSortedMap.isEmpty()) {
// 取哈希环上的顺时针第一台服务器
Integer firstKey = hashServerMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}else{
Integer firstKey = integerStringSortedMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}
}
}
--------------------------------------------------------------------------------------------------------------------------------------------
// 关键信息
SortedMap<Integer, String> integerStringSortedMap = hashServerMap.tailMap(clientHash); // 返回大于这个key的全部内容
if(integerStringSortedMap.isEmpty()) { //
// 取哈希环上的顺时针第一台服务器
Integer firstKey = hashServerMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}else{
Integer firstKey = integerStringSortedMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}
public static void main(String[] args) {
//step1 初始化:把服务器节点IP的哈希值对应到哈希环上
// 定义服务器ip
String[] tomcatServers = new String[]{"123.111.0.0","123.101.3.1","111.20.35.2","123.98.26.3"};
SortedMap<Integer,String> hashServerMap = new TreeMap<>();
// 定义针对每个真实服务器虚拟出来几个节点
int virtaulCount = 3;
for(String tomcatServer: tomcatServers) {
// 求出每一个ip的hash值,对应到hash环上,存储hash值与ip的对应关系
int serverHash = Math.abs(tomcatServer.hashCode());
// 存储hash值与ip的对应关系
hashServerMap.put(serverHash,tomcatServer);
// 处理虚拟节点
for(int i = 0; i < virtaulCount; i++) {
int virtualHash = Math.abs((tomcatServer + "#" + i).hashCode());
hashServerMap.put(virtualHash,"----由虚拟节点"+ i + "映射过来的请求:"+ tomcatServer);
}
}
//step2 针对客户端IP求出hash值
// 定义客户端IP
String[] clients = new String[]{"10.78.12.3","113.25.63.1","126.12.3.8"};
for(String client : clients) {
int clientHash = Math.abs(client.hashCode());
//step3 针对客户端,找到能够处理当前客户端请求的服务器(哈希环上顺时针最近)
// 根据客户端ip的哈希值去找出哪一个服务器节点能够处理()
SortedMap<Integer, String> integerStringSortedMap = hashServerMap.tailMap(clientHash);
if(integerStringSortedMap.isEmpty()) {
// 取哈希环上的顺时针第一台服务器
Integer firstKey = hashServerMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}else{
Integer firstKey = integerStringSortedMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}
}
}
nginx配置一致性hash负载均衡策略
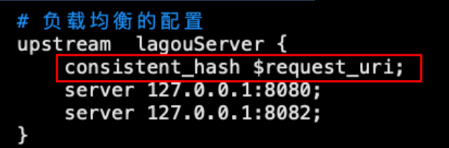 、
、
集群时钟同步
时钟不同步 代表 不同集群上面的本地时间不是一样的
时钟同步的思路:将每个节点都连接到互联网 从一个时间服务器同步系统时间(比如: ntpdate -u ntp.api.bz #从⼀个时间服务器同步时间)
服务不同连接互联网: 指定一个服务器作为时间服务器 定时同步他的时间数据
分布式id方案
分库分表之后id 不能重复
SnowFlake 雪花算法 id 类型是long 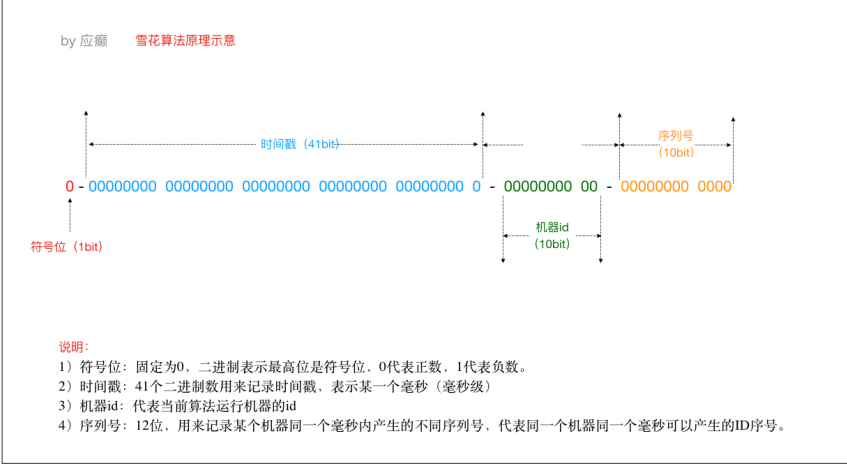
滴滴的:tinyid 基于数据库实现 百度的uidgenerator 基于snowflake 和美团的leaf 基于snowflake 和数据库
redis incr 获取全局的唯一id
分布式调度
运行在分布式集群环境下的定时任务
多个节点同时定时任务(不行 会重复处理)
定时任务 和 消息的区别: 定时任务是时间驱动 消息队列是任务驱动
任务调度框架:quartz 分布式 任务调度框架 elastic-job (依赖zk)
关键解决的问题是 一个任务在集群中不会被重复调用
支持并发调度 任务分片
去中心化
涉及的场景是 leader 选举 。在zk 中创建节点成功的就是leader
根据分片参数 进行任务的分片 where 后面条件过滤
session 共享
集群session 共享
解决方案
ip hash
tomcat 修改配置文件 互相复制自己的session
session 共享 session 集中存储 (redis 缓存) spring session 框架

若有收获,就点个赞吧
0 人点赞
