1. ArrayList
ArrayList的扩容规则
- 无参的ArrayList的容量为0,底层是一个空数组
```java
List
list1 = new ArrayList<>();
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() { // 初始化一个空数组 this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }
2. 有参的ArrayList会使用指定容量的数组```javaList<Integer> list1 = new ArrayList<>(10);public ArrayList(int initialCapacity) {if (initialCapacity > 0) {// 初始化数组的长度this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}
- add(Object o)首次扩容为10,再次扩容为上次的1.5倍
ArrayList的add源码阅读
@Testpublic void test01() {ArrayList<Integer> list1 = new ArrayList<>(10);// 第一次扩容,容量为10, volume = 10;list1.add(0);list1.add(1);list1.add(2);list1.add(3);list1.add(4);list1.add(5);list1.add(6);list1.add(7);list1.add(8);list1.add(9);// 第二次扩容,容量为上次的1.5倍,volume += volume >> 1; volume = 15;list1.add(10);list1.add(11);list1.add(12);list1.add(13);list1.add(14);// 第三次扩容,容量为上次的1.5倍 volume += volume >> 1; volume = 22;list1.add(15);}
public boolean add(E e) {// 扩容,初始size = 0ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}// 第一次扩容minCapacity = 1private void ensureCapacityInternal(int minCapacity) {// 先计算列表容量ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static final int DEFAULT_CAPACITY = 10;// 计算列表容量:这个函数只是当第一次添加元素时,将数组长度初始化为1-private static int calculateCapacity(Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {// 第一次添加,为空列表,返回默认容量DEFAULT_CAPACITY = 10return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;}// 验证扩容的容量是否满足添加元素后的容量private void ensureExplicitCapacity(int minCapacity) {modCount++; // 记录列表被修改的次数// 如果容量不够,扩容if (minCapacity - elementData.length > 0)grow(minCapacity);}
private void grow(int minCapacity) {int oldCapacity = elementData.length; // 原始数组容量int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容为原始数组容量的1.5倍if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); // 将原来的数组拷贝到一个新的数组中,容量为扩容后的容量}
可视化过程List<Integer> list1 = new ArrayList<>();
无参时,第一次添加扩容为10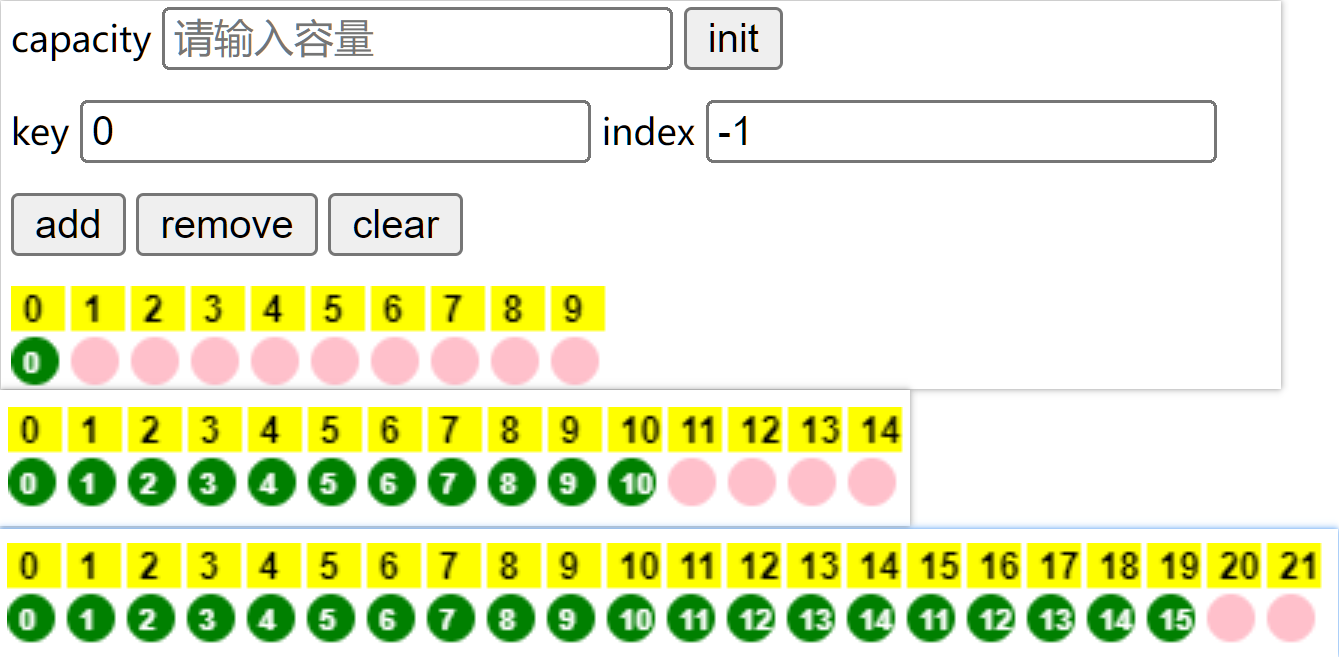
List<Integer> list1 = new ArrayList<>(0);
有参时,不会初始化扩容为10,容量就是0,每次扩容为之前的1.5倍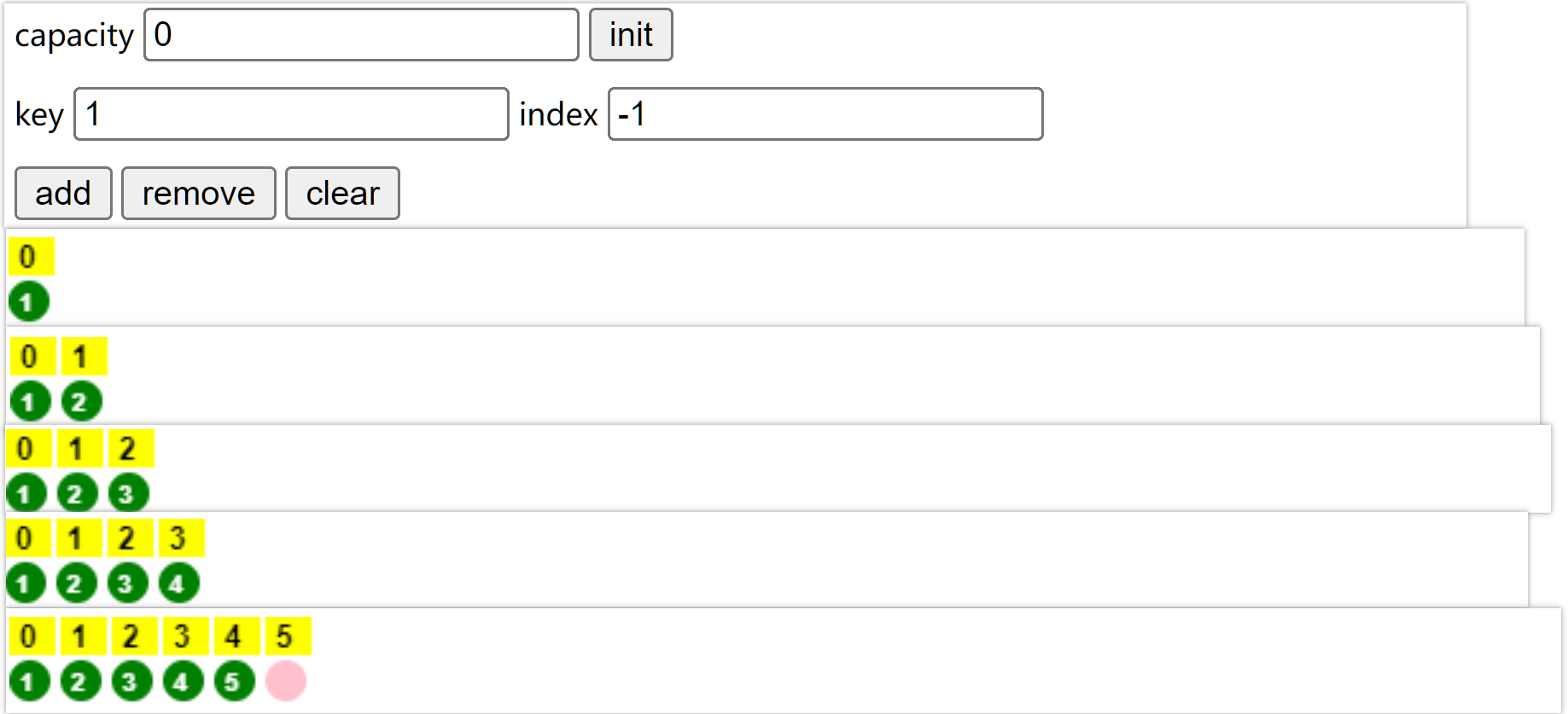
- addAll(Collection c)的扩容规则
- 无元素时:扩容为Math.max(10, 添加后元素的个数);
- 有元素时: 扩容为Math.max(原容量1.5倍,添加后元素的个数);
ArrayList与LinkedList的区别
- ArrayList基于数组,需要连续的内存;LinkedList基于双向链表,不需要连续的内存。
- ArrayList的随机访问速度快,只需要根据下表就可以实现O(1)事件的访问速度;LinkedList则需要沿着链表遍历,所以随机访问速度慢,空间复杂度为O(n)。
- ArrayList的尾部插入删除性能高,但头部插入及其他部分插入由于需要大量的移动数据,性能较低。LinkedList的头尾插入删除都具有较高的性能,但是中间部分的插入删除,由于需要遍历链表定位插入删除元素的位置,导致性能也很低。
- 同时ArrayList由于底层使用数组实现,可以利用CPU缓存的局部性原理,提高数据数据的读取性能,而LinkedList由于存储不连续,则不能实现类似的高性能数据读入。
- LinkedList由于内部结点存储了链表的指针等信息,导致其占用内存比ArrayList大
什么是CPU的局部性原理
CPU局部性原理就是CPU在访问内存时,所访问的存储单元总是趋近于一块较小的内存区域,因此在将内存中的数据读入缓存中时,通常会将要访问存储单元附近连续的一小段内存数据存入缓存中,这样就可以提高数据读取的效率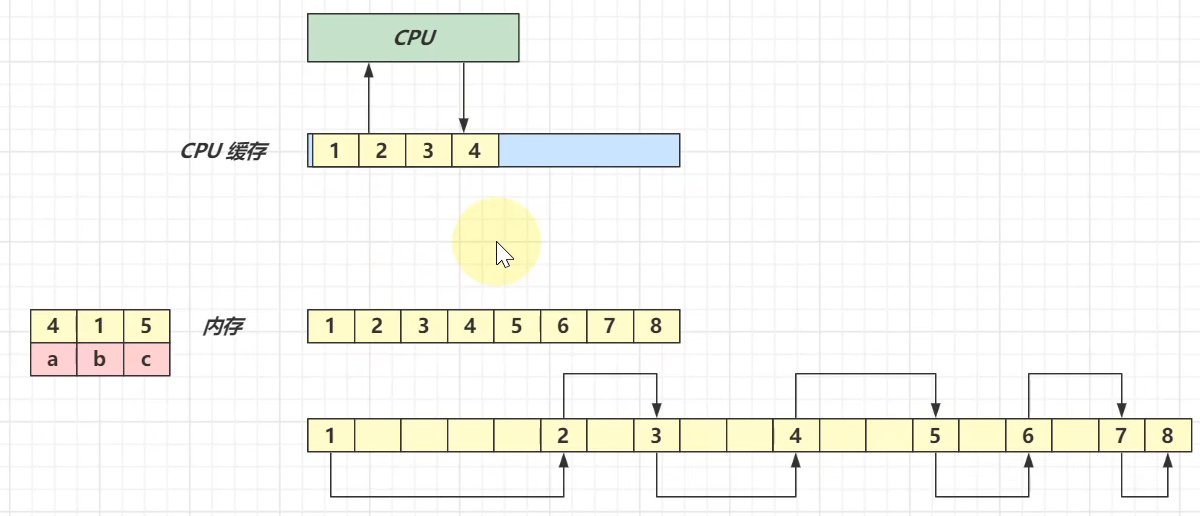
Fail-Fast和Fail-Safe是两种容错机制
- Fail-Fast: 快速故障;遇到故障,立即停止;例如在ArrayList中遍历的同时不能修改,一旦修改尽快失败
- Fail-Safe: 故障安全;遇到故障,可以忽略;如CopyOnWriteArrayList 通过读写分离实现了在遍历的同时修改列表
2. HashMap
HashMap的数据结构
在jdk1.8在之前HashMap使用了数组+链表,HashMap通过key的hashcode获取hash值,然后对数组的长度取余,获取元素存放的桶下表(也就是存放的位置)。如果当前位置不存在元素则直接放入;如果存在元素的话,遍历链表,比较链表中的元素与当前元素的hash值是否相等,如果不相等,就插入到链表后面,如果相等,再比较两者的key是否相同,相同直接覆盖,不相同就将原素插入到链表后面。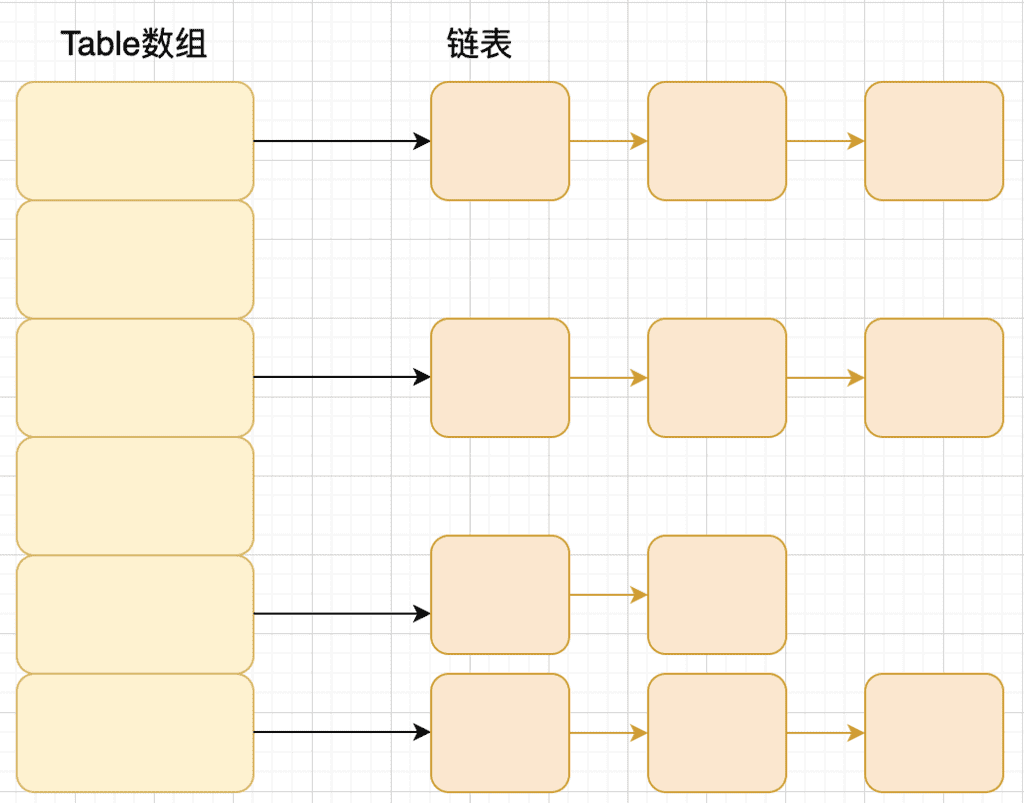
拉链法:将数组与链表结合,数组中的每一格存储的都是链表,当遇到哈希冲突时,直接将冲突的值插入链表后面即可
在jdk1.8中HashMap使用了数组+红黑树,jdk1.8以后HashMap在解决哈希冲突上做了较大的改变,当链表的长度大于8,并且数组的程度大于64时,链表将转化为红黑树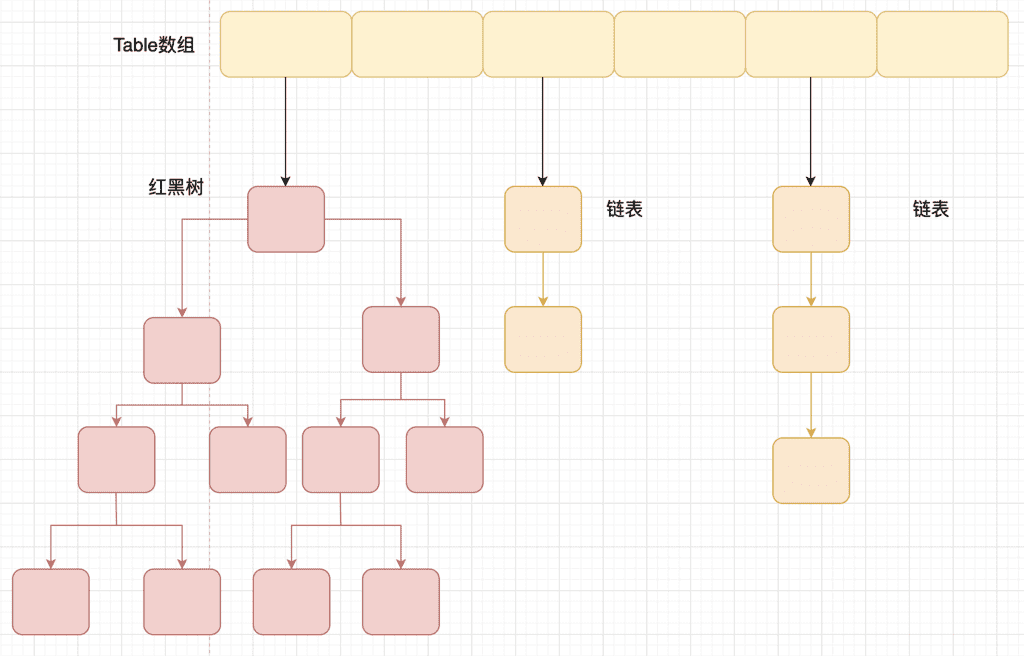
红黑树
HashMap中链表过长的解决方案
- 数组扩容
HashMap中第一次插入数据时,数组的默认长度为16,触发扩容有两种情况:
- 当插入的数据的长度大于数组原始长度的0.75倍,将会扩容一倍


- 当链表的长度大于8,并且数组长度小于64时将会触发扩容


// 数组的默认长度static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 1 << 4 = 16// 负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 扩容的阈值,负载因子*原始容量newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
- 转为红黑树
HashMap链表转为红黑树的条件:
链表的长度大于8,并且数组的长度大于64

树化的意义?
为什么不直接使用红黑树?
在链表长度较短时,直接使用链表的性能要更高,因为红黑树的查询、插入更复杂;而且红黑树中结点占用的内存也比链表中的结点占用的内存高;
链表的长度为什么要选择8?
首先,链表过长过短都不好。链表过长的话,会使得查询性能下降;链表过短的话,又会频繁的树化也会导致性能下降,所以应尽可能降低树化的概率;如果哈希值速购随机,链表长度超过8的概率将会非常小,这样使得正常情况下不会频繁的树化。
红黑树退化为链表的条件?
- 在扩容拆分树时,树的元素个数 <= 6会退化为链表
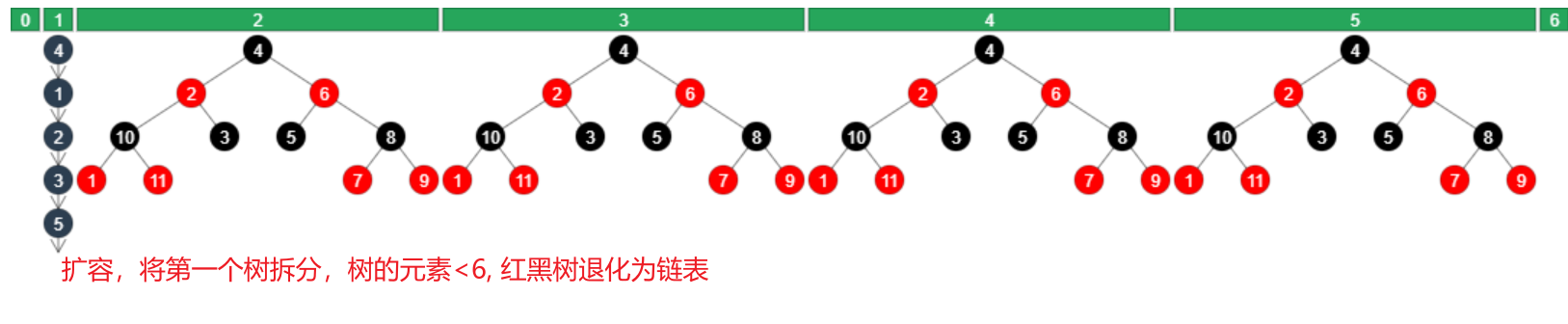
- remove节点时,如果root,root.left,root.right,root.left.left有一个为null,也会退化为链表


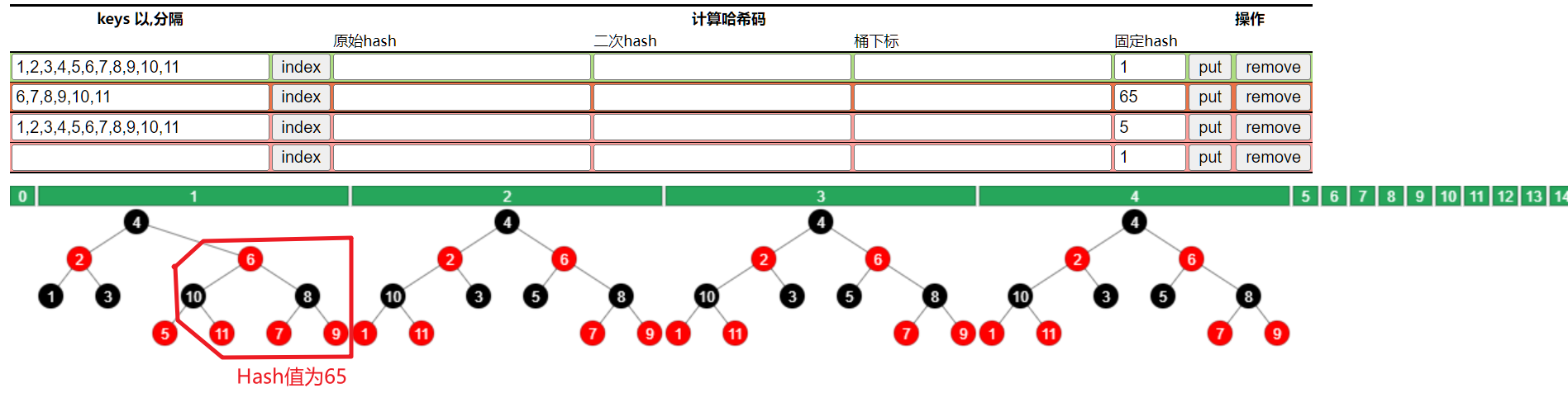
HashMap的索引如何计算?
首先计算key的hashcode,然后经过hash()方法进行二次hash,最后将计算出的哈希值与数组的长度取模计算HashMap的索引(取模使用的位操作(n - 1) & hash)
// 索引计算p = tab[i = (n - 1) & hash]static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
为什么要二次hash?
数组容量为什么是2的n次幂?
- 在计算索引,使用哈希码对数组长度取模时,HashMap使用了(n - 1) & hash的位运算提高计算效率,因此使用2的n次幂,可以使得这样的位运算与取模运算等价。
- 在扩容时,采用了2的n次幂,也可以使得元素的移动效率效率更高。如果hash & oldCap == 0 的话,表明hash值小于原来的容量值,扩容后,索引值不变直接保留在原来的位置即可,如果hash & oldCap != 0的话,hash值大于原来的容量,元素就需要移动到新的位置。新位置 = 旧位置 + odlCap
HashMap的负载因子为什么要设成0.75呢?
- 负载因子设为0.75是为了在内存占用和查询时间上取得较好的权衡
- 如果负载因子比较大,哈希冲突较多,链表会比较长,影响查询性能
如果负载因子比较小,哈希冲突变少了,但是扩容更加频繁,内存占用更多,空间利用率吧也比较小
HashMap在jdk1.7和1.8中的区别?
jdk1.7的底层数据结构使用的是数组+链表,jdk1.8中使用的是数组+链表/红黑树
- jdk1.7中链表插入结点是头插法,jdk1.8中是尾插法
- jdk1.7是在大于等于阈值并且没有空位时才扩容,jdk1.8是大于阈值就扩容
-
jdk1.8扩容源码分析
```java @Test public void test03() {
HashMap
// 首先加入11个元素,索引为0-11 for(int i = 1; i <= 11; i++) {
map.put(i,i);
} // 插入第12个元素,索引为7 map.put(151, 151);
// 插入第13个元素,开始扩容 map.put(13, 13);
}
**元素添加过程:**<br /><br /><br /><br />**扩容具体过程:**<br /><br /><br />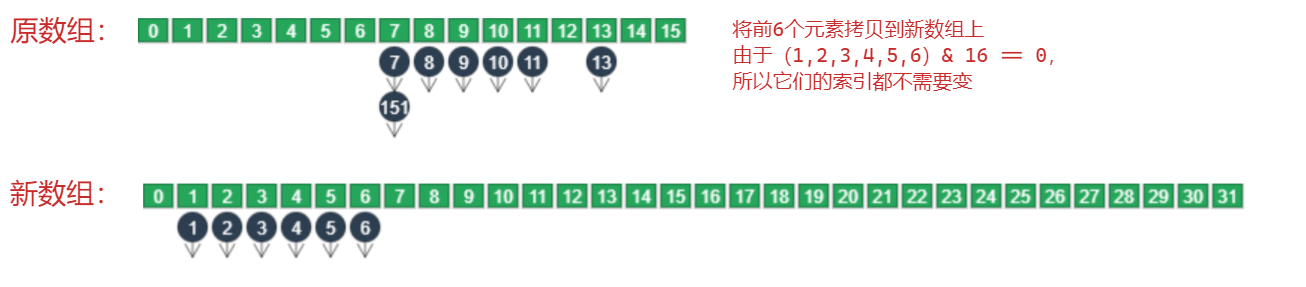<br /><br />```java// 创建一个新的数组,容量为扩容后的新容量Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;// 旧数组不为空,需要将旧数组中的值拷贝到新数组中if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {// 指向当前结点的指针Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null; // 清理原数组中的垃圾if (e.next == null) // e.next == null,表明链表上只有一个结点// 将原数组中的元素存储在新数组中,这里都直接存储在旧的索引上,后面还要计算新的索引newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {// 处理链表结点数不为1的哈希冲突情况// 新建链表,用来保存不用调整索引的元素和要调整索引的元素Node<K,V> loHead = null, loTail = null; // 存储低位元素的索引Node<K,V> hiHead = null, hiTail = null; // 存储高位元素的索引Node<K,V> next;do {next = e.next;// e.hash & oldCap) == 0,无须调整索引,保留在低位if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {// e.hash & oldCap) != 0 调整索引,保留到高位if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;// 存储在低位的链表:原来的索引newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;// 存储在高位的链表:原来的索引 + 加上扩容的容量newTab[j + oldCap] = hiHead;}}}}}
HashMap并发丢失数据
HashMap在并发操作时,可能会出现丢失数据的线程安全问题
public static void main(String[] args) throws InterruptedException {HashMap<String, Object> map = new HashMap<>();Thread t1 = new Thread(() -> {map.put("a", new Object()); // 97 => 1}, "t1");Thread t2 = new Thread(() -> {map.put("1", new Object()); // 49 => 1}, "t2");t1.start();t2.start();t1.join();t2.join();System.out.println(map);}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)/*** 在这里并发操作可能会出现线程安全问题* t1线程已经判断tab[1] == null,进入此处,但是t2线程抢到事件片开始执行* t2线判断tab[1] == null, 执行tab[2] = newNode('1');* t1再次执行是tab[1] = newNode('a'),直接将newNode('1')覆盖掉导致数据丢失**/tab[i] = newNode(hash, key, value, null);else {...}return null;}
执行结果:{a=java.lang.Object@133314b},其中'1'丢失!
jdk1.7中HashMap的扩容死链问题
死链产生原因:HashMap线程不安全,并发情况下触发了扩容,由于jdk 1.7中添加元素为头插法,导致了扩容死链问题。
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {// e指向当前要迁移的结点while(null != e) {// next指向下一个要迁移的结点Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}}
用语言描述一下扩容死链问题:在并发情况下,有两个线程同时操作HashMap,并且触发了扩容过程。在jdk1.7的HashMap中,就有两个线程要将原始数组中的元素迁移至扩容后的数组中,由于jdk 1.7添加元素使用的是头插法,加入原数组中的一个链表的顺序为
a -> b->null,假设线程2已经迁移了过去,那么链表的顺序将会编程b->a->null,此时线程1的引用,e指向a,next指向b,将a->b迁移过去后,形成了b->a,b的next又指向a,就会再一次将a插入b的前面,由此形成了a->b->a即死链循环。

HashMap的put源码分析
- HashMap是懒惰创建数组的,首次调用才会创建数组,初始化数组长度为16
- 往HashMap中添加元素,首先会计算key的hashCode,然后经过二次hash获取哈希值,将哈希值对数组长度取余集合计算出元素在HashMap中的桶下表,即索引
- 判断当前索引有没有元素,如果没有元素,直接插入,创建Node,结束
- 如果有元素,则要判断当前元素的结点是链表结点还是红黑树结点,如果是红黑树结点,就走红黑树的插入逻辑;如果是链表结点,就将结点插到链表最后面,同时判断链表长度是否超过树化阈值,超过的话,要转化为红黑树
- 最后检查HashMap容量是否超过扩容阈值,一旦超过进行扩容
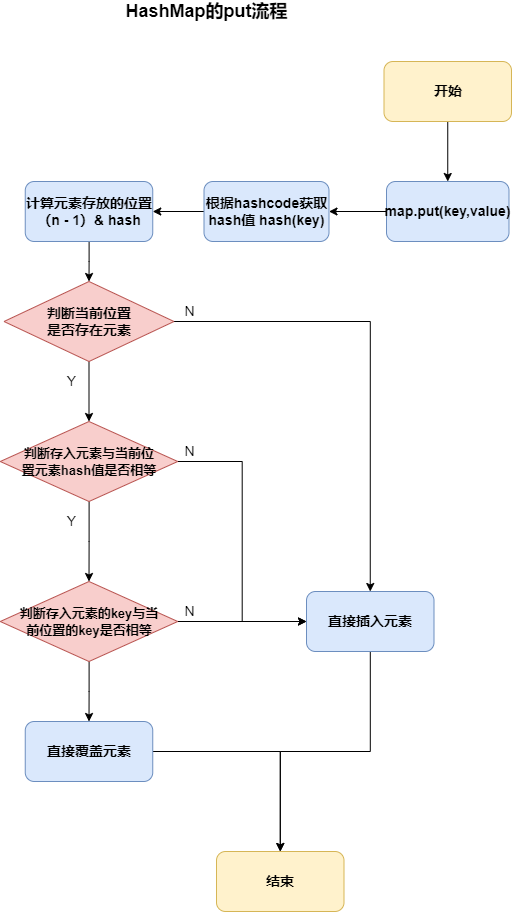
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)// 首次调用HashMap,将容量初始化为16n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)// 当先位置还没有元素,直接添加tab[i] = newNode(hash, key, value, null);else { // 当前位置存在元素Node<K,V> e; K k; // e:结点;k:键// // 检查tab[i]上的hash与插入元素的hash是否相等,然后检查,两者key是否相等if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p; // 相等,直接覆盖tab[i]上的元素// 检查tab[i]是否为红黑树结点else if (p instanceof TreeNode)// 将结点插入至红黑树中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 插入链表结点,并检查是否需要树化else {// 开始遍历tab[i]上的链表for (int binCount = 0; ; ++binCount) {// 到了链表的尾结点,直接将新结点插入链表后面if ((e = p.next) == null) {// 新建结点,新结点插入链表后面p.next = newNode(hash, key, value, null);// 检查是否需要树化if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break; // 插入结点完毕,直接退出循环}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break; // 插入的元素已经在链表中出现,直接跳出循环 goto <标记1>// p指针移动至下一个结点, 遍历链表p = e;}}// <标记1> e不为null,说明插入的元素已经在链表中出现if (e != null) {V oldValue = e.value; // 记录旧元素的值if (!onlyIfAbsent || oldValue == null)e.value = value; // 使用新元素的值直接覆盖旧元素的值afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold) // 大于扩容阈值resize(); // 开始扩容afterNodeInsertion(evict);return null;}
String的hashCode()设计
hashCode()方法是为了使得每个字符串的哈希表更为独特,分布在HashMap的桶中分布的更加均匀,散列计算公式如下:
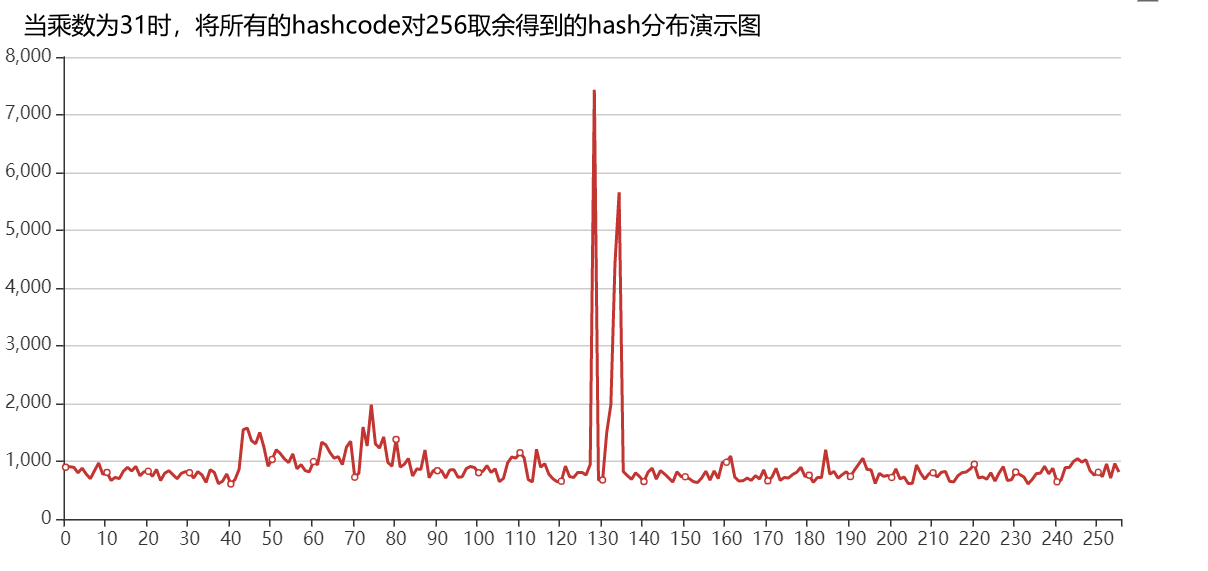
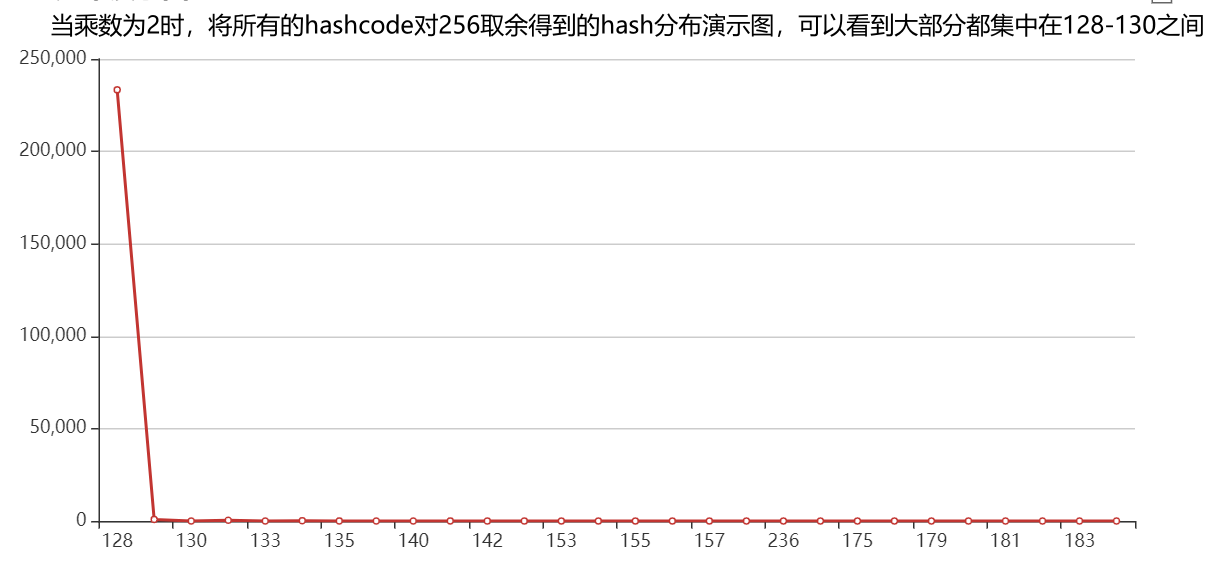
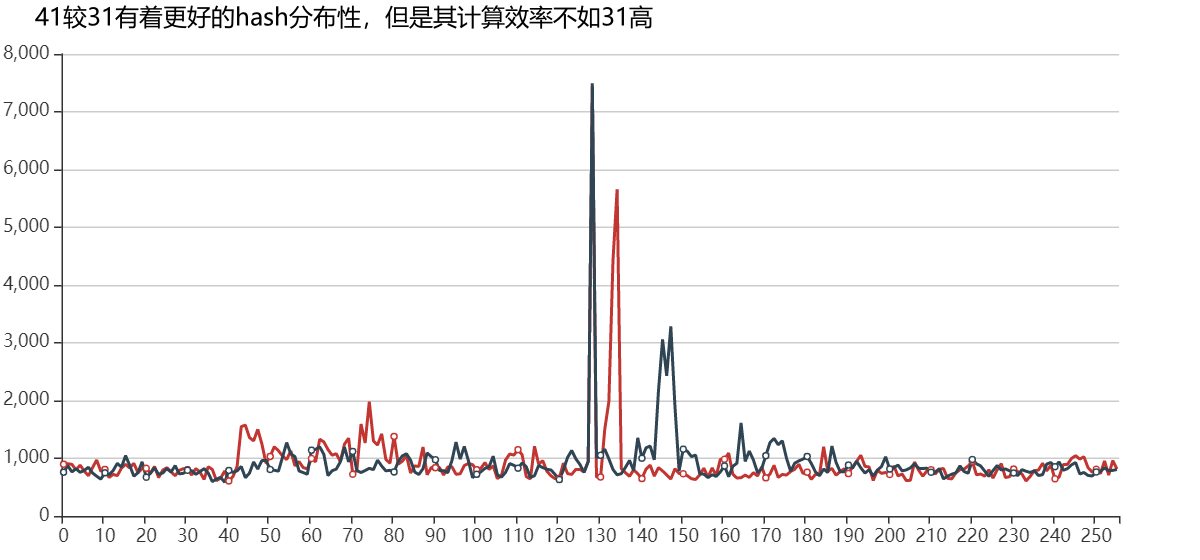
为什么要选择乘以31呢?
- 选用31会有更好的散列特性,使得哈希码分散的更均匀,这样在hashMap中就不会出现一个桶中存在非常多的hash值相同的元素
- 31*h 可以被优化为h << 5 - h, 位运算计算效率更高
关于选用hashCode中选用不同乘数,对hashCode散列特性的影响public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;// hash = S_0 * 31^{n-1} + S_1 * 31^{n-2} + ... + S_{n-1} * 31^{0}for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;}
3 ConcurrentHashMap

若有收获,就点个赞吧
0 人点赞
