部署
主机规划
| NN | JN | ZKFC | ZK | DN | RM | NM | hive server | hive cli | spark sql | spark server2 | spark beeline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| node01 | * | * | * | * | * | |||||||
| node02 | * | * | * | * | * | * | * | * | * | |||
| node03 | * | * | * | * | * | |||||||
| node04 | * | * | * | * |
原来的hadoop机群RM在node03和node04
Standalone
master node01 node02
worker node02 node03 node04
node01cd /opttar xzvf spark-2.3.4-bin-hadoop2.6.tgzmv spark-2.3.4-bin-hadoop2.6 spark-2.3.4配置环境变量cd /opt/spark-2.3.4/conf//配置worksmv slaves.template slavesvi slavesnode02node03node04//环境参数spark-env.shexport HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoopexport SPARK_MASTER_HOST=node01 # 每台master改成自己的主机名export SPARK_MASTER_PORT=7077export SPARK_MASTER_WEBUI_PORT=8080export SPARK_WORKER_CORES=4export SPARK_WORKER_MEMORY=4g//配置高可用cp spark-defaults.conf.template spark-defaults.confvi spark-defaults.confspark.deploy.recoveryMode ZOOKEEPERspark.deploy.zookeeper.url node02:2181,node03:2181,node04:2181spark.deploy.zookeeper.dir /bryansparkspark.eventLog.enabled truespark.eventLog.dir hdfs://mycluster/spark_logspark.history.fs.logDirectory hdfs://mycluster/spark_log//复制到其他主机scp -r spark-2.3.4 node02:`pwd`scp -r spark-2.3.4 node03:`pwd`scp -r spark-2.3.4 node04:`pwd`node01:start-dfs.sh //只启动hdfssbin/start-all.sh //启动master和slavesnode02sbin/start-master.sh测试 node01spark-shell --master spark://node01:7077,node02:7077scala> sc.textFile("hdfs://mycluster/usr/bryan/wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)(jim,1)(bryan,2)(lily,1)(peter,2)(hello,2)(msb,2)(pp,1)(jiam,1)必须要加collect回收数据,要不然不能显示spark-shell 只能client模式
spark-shell
查看各节点角色
spark-shell在哪个节点启动的,SparkSubmit进程(driver)就在哪里
node01[root@node01 ~]# jps4848 SparkSubmit3569 ResourceManager4451 Master3460 DFSZKFailoverController3289 JournalNode5066 Jps3087 NameNodenode02[root@node02 spark-2.3.4]# jps2368 QuorumPeerMain3456 Worker2626 DataNode4035 Jps3572 Master2839 DFSZKFailoverController2922 NodeManager3114 ResourceManager2555 NameNode3867 CoarseGrainedExecutorBackend2717 JournalNodenode03[root@node03 ~]# jps2196 QuorumPeerMain2406 JournalNode3334 Jps3143 CoarseGrainedExecutorBackend2504 NodeManager2317 DataNode2877 Workernode04[root@node04 ~]# jps2212 DataNode2326 NodeManager2103 QuorumPeerMain2920 CoarseGrainedExecutorBackend3131 Jps2670 Worker
spark-submit client
//创建提交脚本,用官方例子vi submit.sh#!/bin/bashjar=$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.4.jarmaster=spark://node01:7077,node02:7077#master=yarnmode=clientclass=org.apache.spark.examples.SparkPi$SPARK_HOME/bin/spark-submit \--master $master \--deploy-mode $mode \--class $class \$jar \1000node03./submit在node03节点有SparkSubmit进程
spark-submit cluster
mode=cluster
node03
./submit
此时这个client把程序提交到集群然后退出,集群某个节点启动driver,继续跑!
[root@node01 spark-2.3.4]# jps3569 ResourceManager10755 Jps3460 DFSZKFailoverController3289 JournalNode7438 Master3087 NameNode[root@node02 spark-2.3.4]# jps2368 QuorumPeerMain10961 CoarseGrainedExecutorBackend2626 DataNode9411 Master6854 HistoryServer2839 DFSZKFailoverController5960 Worker2922 NodeManager3114 ResourceManager2555 NameNode11004 Jps2717 JournalNode[root@node03 ~]# jps5105 Worker9522 SparkSubmit //client提交进程2196 QuorumPeerMain2406 JournalNode9591 Jps2504 NodeManager9577 CoarseGrainedExecutorBackend2317 DataNode[root@node04 ~]# jps8192 DriverWrapper //driver2212 DataNode2326 NodeManager2103 QuorumPeerMain4666 Worker8250 CoarseGrainedExecutorBackend8266 Jps[root@node04 ~]# jps2212 DataNode2326 NodeManager2103 QuorumPeerMain4666 Worker8367 Jps
内存与CPU参数
--deploy-mode--driver-memory 1024m driver#有能力拉取计算结果回自己的jvm#driver、executor jvm中会存储中间计算过程的数据的元数据--driver-cores # cluster mode ,默认1--total-executor-cores #standalone--executor-cores 1 # standalone默认每节点一个executor并占用全部核,如果设置此参数每个node会出现多个executor yarn 每executor 1 core--executor-memory 1024m--num-executors NUM 默认2 yarn专属standalone 3个worker,假设CPU足够--total-executor-cores每个节点 一个exector 2个核--total-executor-cores--executor-cores 1每个节点 二个exector 每executor 1个核
History
master一重启,历史记录就不存在了
vi spark-defaults.confhdfs dfs -mkidr -p /spark_logspark.eventLog.enabled truespark.eventLog.dir hdfs://mycluster/spark_log //存的,目录要提前创建spark.history.fs.logDirectory hdfs://mycluster/spark_log //取的a)修改配置一定要分发、重启服务b)计算层会自己将自己的计算日志存入hdfsc)手动启动:./sbin/start-history-server.sh ,用来取日志e)访问 启动有 history-server主机的主机名 默认端口是 18080
Spark on Yarn
spark-env.shexport HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoopspark-defaults.confspark.eventLog.enabled truespark.eventLog.dir hdfs://mycluster/spark_logspark.history.fs.logDirectory hdfs://mycluster/spark_logspark.yarn.jars hdfs://mycluster/work/spark_lib/jars/*将spark的jar包上传到hdfs,要不然yarn每次都要上传hdfs dfs -mkdir -p /work/spark_lib/jars/opt/spark-2.3.4/jarshdfs dfs -put ./* /work/spark_lib/jars没配置jars[root@node01 conf]# hdfs dfs -ls /user/root/.sparkStaging/application_1627546735806_0006Found 3 items-rw-r--r-- 2 root supergroup 190850 2021-07-29 16:34 /user/root/.sparkStaging/application_1627546735806_0006/__spark_conf__.zip-rw-r--r-- 2 root supergroup 232507850 2021-07-29 16:34 /user/root/.sparkStaging/application_1627546735806_0006/__spark_libs__5988972910506987504.zip-rw-r--r-- 2 root supergroup 1991004 2021-07-29 16:34 /user/root/.sparkStaging/application_1627546735806_0006/spark-examples_2.11-2.3.4.jars配置之后[root@node01 conf]# hdfs dfs -ls /user/root/.sparkStaging/application_1627546735806_0005Found 2 items-rw-r--r-- 2 root supergroup 221760 2021-07-29 16:33 /user/root/.sparkStaging/application_1627546735806_0005/__spark_conf__.zip-rw-r--r-- 2 root supergroup 1991004 2021-07-29 16:33 /user/root/.sparkStaging/application_1627546735806_0005/spark-examples_2.11-2.3.4.jarclient:ExecutorLaunchercluster:ApplicationMasterspark-shell 只支持 client模式spark-submit 跑非repl 的可以是client、cluster
yarn-site.xml<property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
client
//创建提交脚本,用官方例子vi submit.sh#!/bin/bashjar=$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.4.jar#master=spark://node01:7077,node02:7077master=yarnmode=clientclass=org.apache.spark.examples.SparkPi$SPARK_HOME/bin/spark-submit \--master $master \--deploy-mode $mode \--class $class \$jar \1000node03./submit.sh
角色查看
[root@node01 spark-2.3.4]# jps3460 DFSZKFailoverController15320 Jps3289 JournalNode14109 ResourceManager3087 NameNode[root@node02 spark-2.3.4]# jps2368 QuorumPeerMain2626 DataNode6854 HistoryServer2839 DFSZKFailoverController16505 Jps2555 NameNode2717 JournalNode15117 NodeManager15214 ResourceManager[root@node03 ~]# jps13970 CoarseGrainedExecutorBackend2196 QuorumPeerMain12773 NodeManager2406 JournalNode13768 SparkSubmit //driver2317 DataNode14030 Jps[root@node04 ~]# jps2212 DataNode2103 QuorumPeerMain12137 CoarseGrainedExecutorBackend12186 Jps11148 NodeManager12095 ExecutorLauncher //appmaster
cluster
将mode改成cluster
角色查看
[root@node01 opt]# jps3460 DFSZKFailoverController16552 Jps3289 JournalNode14109 ResourceManager3087 NameNode[root@node02 spark-2.3.4]# jps2368 QuorumPeerMain2626 DataNode6854 HistoryServer2839 DFSZKFailoverController18010 Jps2555 NameNode2717 JournalNode15117 NodeManager15214 ResourceManager[root@node03 ~]# jps2196 QuorumPeerMain12773 NodeManager15141 SparkSubmit //client2406 JournalNode15222 Jps2317 DataNode[root@node04 ~]# jps13426 ApplicationMaster //driver和appmaster都在这一个进程13474 Jps2212 DataNode2103 QuorumPeerMain11148 NodeManager
SparkSQL
将hive-site.xml复制到spark/conf文件中
hive-site.xml
<property><name>hive.metastore.uris</name><value>thrift://node03:9083</value></property>
hive metastore
node03
hive —service metastore
hive cli
node04
hive
spark sql cli
spark-sql --master yarn
spark thrft-server
相当于hiveserver2
node01
$SPARK_HOME/sbin/start-thriftserver.sh --master yarn
beeline
node02
$SPARK_HOME/bin/beeline!connect jdbc:hive2://node01:10000
分区分表实验
数据准备
part1.txt1 小明1 lol,book,movie beijing:mashibing,shanghai:pudong2 小明2 lol,book,movie beijing:mashibing,shanghai:pudong3 小明3 lol,book,movie beijing:mashibing,shanghai:pudong4 小明4 lol,book,movie beijing:mashibing,shanghai:pudong5 小明5 lol,movie beijing:mashibing,shanghai:pudong6 小明6 lol,book,movie beijing:mashibing,shanghai:pudong7 小明7 lol,book beijing:mashibing,shanghai:pudong8 小明8 lol,book beijing:mashibing,shanghai:pudong9 小明9 lol,book,movie beijing:mashibing,shanghai:pudong10 小明10 lol,book,skill beijing:mashibing,shanghai:pudongpart2.txt11 小明11 lol,book,movie beijing:mashibing,shanghai:pudong12 小明12 lol,book,movie beijing:mashibing,shanghai:pudong13 小明13 lol,book,movie beijing:mashibing,shanghai:pudong14 小明14 lol,book,movie beijing:mashibing,shanghai:pudong15 小明15 lol,movie beijing:mashibing,shanghai:pudong16 小明16 lol,book,movie beijing:mashibing,shanghai:pudong17 小明17 lol,book beijing:mashibing,shanghai:pudong18 小明18 lol,book beijing:mashibing,shanghai:pudong19 小明19 lol,book,movie beijing:mashibing,shanghai:pudong20 小明20 lol,book,skill beijing:mashibing,shanghai:pudongpart3.txt21 小明21 lol,book,movie beijing:mashibing,shanghai:pudong22 小明22 lol,book,movie beijing:mashibing,shanghai:pudong23 小明23 lol,book,movie beijing:mashibing,shanghai:pudong24 小明24 lol,book,movie beijing:mashibing,shanghai:pudong25 小明25 lol,movie beijing:mashibing,shanghai:pudong26 小明26 lol,book,movie beijing:mashibing,shanghai:pudong27 小明27 lol,book beijing:mashibing,shanghai:pudong28 小明28 lol,book beijing:mashibing,shanghai:pudong29 小明29 lol,book,movie beijing:mashibing,shanghai:pudong30 小明30 lol,book,skill beijing:mashibing,shanghai:pudongpart4.txt41 小明41 lol,book,movie beijing:mashibing,shanghai:pudong42 小明42 lol,book,movie beijing:mashibing,shanghai:pudong43 小明43 lol,book,movie beijing:mashibing,shanghai:pudong44 小明44 lol,book,movie beijing:mashibing,shanghai:pudong45 小明45 lol,movie beijing:mashibing,shanghai:pudong46 小明46 lol,book,movie beijing:mashibing,shanghai:pudong47 小明47 lol,book beijing:mashibing,shanghai:pudong48 小明48 lol,book beijing:mashibing,shanghai:pudong49 小明49 lol,book,movie beijing:mashibing,shanghai:pudong50 小明50 lol,book,skill beijing:mashibing,shanghai:pudong
仅分区
内部表
create table part_in (id int,name string,likes array<string>,address map<string,string>)partitioned by(data_dt string,channel int)row format delimitedfields terminated by '\t'collection items terminated by ','map keys terminated by ':';分区字段相当于虚字段,实际数据中不存在,但hive查询时会显示分区列本地路径,复制文件到hdfsload data local inpath '/opt/part1.txt' into table part_in partition (data_dt='20210701',channel=110);load data local inpath '/opt/part2.txt' into table part_in partition (data_dt='20210701',channel=120);load data local inpath '/opt/part3.txt' into table part_in partition (data_dt='20210702',channel=110);load data local inpath '/opt/part4.txt' into table part_in partition (data_dt='20210702',channel=120);hdfs移动文件到hive表load data inpath '/data/part1.txt' into table part_in partition (data_dt='20210701',channel=110);直接insert into xx values这样插入,效率低会产生以下这种copy文件,每插入一次,产生一个000000_0_copy_1000000_0_copy_2

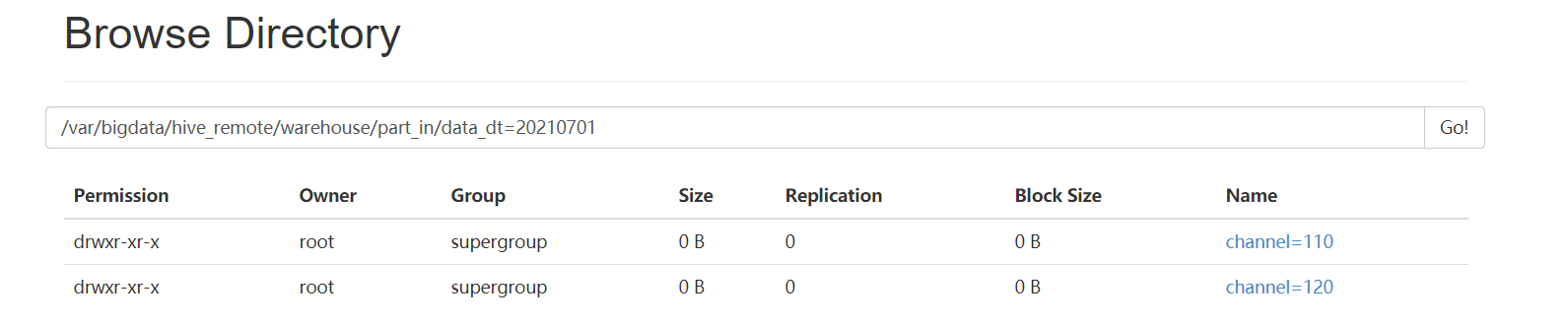

查询
hive> select * from part_in;OK1 小明1 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1102 小明2 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1103 小明3 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1104 小明4 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1105 小明5 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1106 小明6 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1107 小明7 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1108 小明8 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1109 小明9 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 11010 小明10 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 11011 小明11 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12012 小明12 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12013 小明13 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12014 小明14 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12015 小明15 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12016 小明16 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12017 小明17 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12018 小明18 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12019 小明19 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12020 小明20 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12021 小明21 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11022 小明22 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11023 小明23 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11024 小明24 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11025 小明25 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11026 小明26 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11027 小明27 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11028 小明28 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11029 小明29 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11030 小明30 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11041 小明41 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12042 小明42 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12043 小明43 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12044 小明44 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12045 小明45 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12046 小明46 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12047 小明47 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12048 小明48 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12049 小明49 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12050 小明50 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120Time taken: 0.14 seconds, Fetched: 40 row(s)//用分区列查找,只加载对应文件,速度快hive> select * from part_in where data_dt=20210701;OK1 小明1 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1102 小明2 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1103 小明3 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1104 小明4 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1105 小明5 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1106 小明6 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1107 小明7 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1108 小明8 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1109 小明9 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 11010 小明10 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 11011 小明11 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12012 小明12 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12013 小明13 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12014 小明14 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12015 小明15 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12016 小明16 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12017 小明17 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12018 小明18 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12019 小明19 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12020 小明20 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120Time taken: 0.784 seconds, Fetched: 20 row(s)
外部表
删除外部表只会删除元数据,不会删数据,安全性高。数仓一般这样用
create external table part_out (id int,name string,likes array<string>,address map<string,string>)partitioned by(data_dt string,channel int)row format delimitedfields terminated by '\t'collection items terminated by ','map keys terminated by ':'location '/var/bigdata/hive_remote/warehouse/part_out';本地路径,复制文件到hdfsload data local inpath '/opt/part1.txt' [overwrite] into table part_out partition (data_dt='20210701',channel=110);load data local inpath '/opt/part2.txt' [overwrite] into table part_out partition (data_dt='20210701',channel=120);load data local inpath '/opt/part3.txt' [overwrite] into table part_out partition (data_dt='20210702',channel=110);load data local inpath '/opt/part4.txt' [overwrite] into table part_out partition (data_dt='20210702',channel=120);hdfs移动文件到hive表load data inpath '/data/part1.txt' into table part_out partition (data_dt='20210701',channel=110);
分区操作
--给分区表添加分区列的值alter table table_name add partition(col_name=col_value)--删除分区列的值alter table table_name drop partition(col_name=col_value)/*注意:1、添加分区列的值的时候,如果定义的是多分区表,那么必须给所有的分区列都赋值2、删除分区列的值的时候,无论是单分区表还是多分区表,都可以将指定的分区(多分区指定一个分区可以级联删除)进行删除,级联删除在已有数据目录,建立外部分区表,需要修改分区--修复分区msck repair table psn7;
动态分区
仅分桶
create table part_bucket (id int,name string,likes array<string>,address map<string,string>)clustered by (id) into 4 bucketsrow format delimitedfields terminated by '\t'collection items terminated by ','map keys terminated by ':';//不能用load datainsert into table part_bucket select id,name,likes,address from part_in where data_dt='20210701' and channel=110;insert into table part_bucket select id,name,likes,address from part_in where data_dt='20210701' and channel=120;
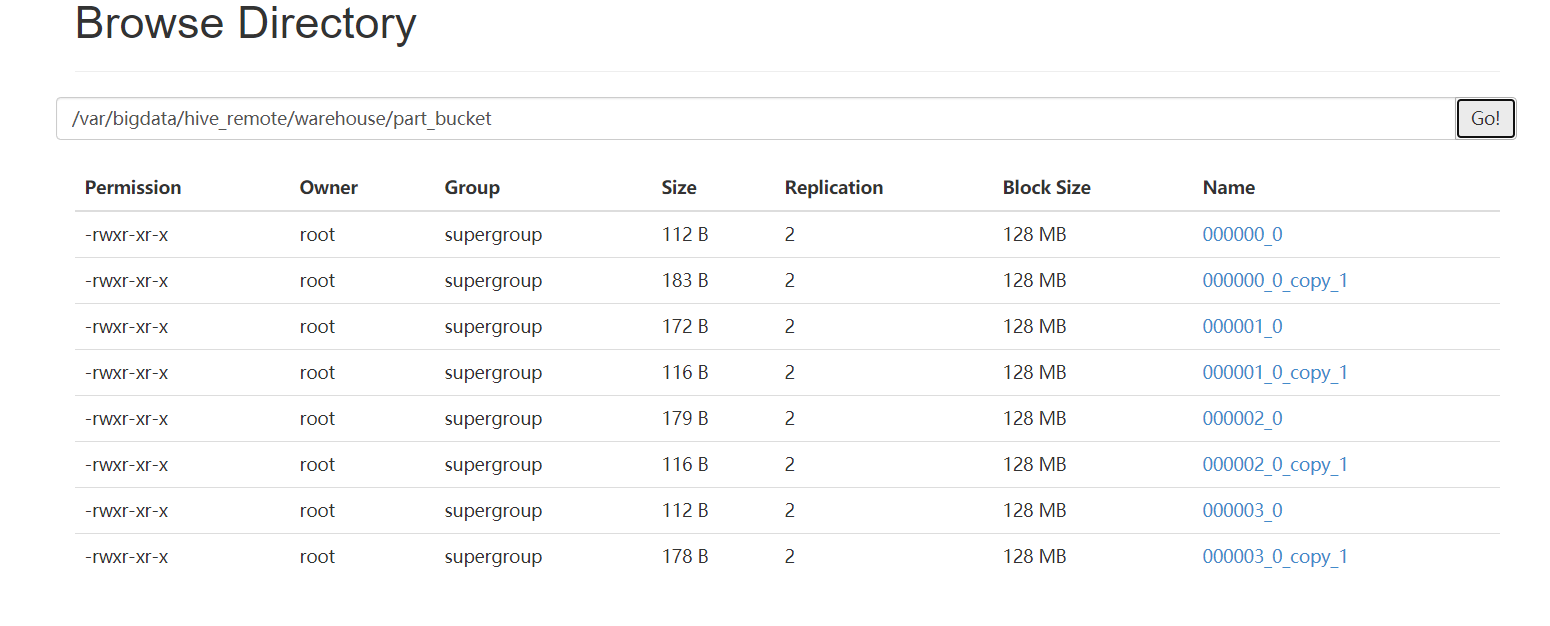
分区再分桶
内部表
create table part_in_bucket (id int,name string,likes array<string>,address map<string,string>)partitioned by(data_dt string,channel int)clustered by (id) into 4 bucketsrow format delimitedfields terminated by '\t'collection items terminated by ','map keys terminated by ':';//不能用load datainsert overwrite table part_in_bucket partition (data_dt='20210701',channel=110)select id,name,likes,address from part_in where data_dt='20210701' and channel=110;//不能select * ,会产生6个字段,包括分区列 overwrite是覆盖insert overwrite table part_in_bucket partition (data_dt='20210701',channel=120)select id,name,likes,address from part_in where data_dt='20210701' and channel=120;insert overwrite table part_in_bucket partition (data_dt='20210702',channel=110)select id,name,likes,address from part_in where data_dt='20210702' and channel=110;insert overwrite table part_in_bucket partition (data_dt='20210702',channel=120)select id,name,likes,address from part_in where data_dt='20210702' and channel=120;

hive> select *from part_in_bucket;OK8 小明8 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1104 小明4 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1109 小明9 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1105 小明5 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1101 小明1 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 11010 小明10 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1106 小明6 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1102 小明2 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1107 小明7 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 1103 小明3 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 11020 小明20 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12016 小明16 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12012 小明12 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12017 小明17 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12013 小明13 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12018 小明18 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12014 小明14 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12019 小明19 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12015 小明15 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12011 小明11 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 12028 小明28 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11024 小明24 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11029 小明29 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11025 小明25 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11021 小明21 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11030 小明30 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11026 小明26 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11022 小明22 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11027 小明27 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11023 小明23 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 11048 小明48 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12044 小明44 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12049 小明49 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12045 小明45 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12041 小明41 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12050 小明50 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12046 小明46 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12042 小明42 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12047 小明47 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 12043 小明43 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120Time taken: 0.128 seconds, Fetched: 40 row(s)可以看到同一分区的数据顺序错乱了,按照id hash到了不同的桶中
外部表
create external table part_out_bucket (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(data_dt string,channel int)
clustered by (id) into 4 buckets
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
location '/var/bigdata/hive_remote/warehouse/part_out_bucket';
//不能用load data
insert overwrite table part_out_bucket partition (data_dt='20210701',channel=110)
select id,name,likes,address from part_out where data_dt='20210701' and channel=110;
//不能select * ,会产生6个字段,包括分区列
insert overwrite table part_out_bucket partition (data_dt='20210701',channel=120)
select id,name,likes,address from part_out where data_dt='20210701' and channel=120;
insert overwrite table part_out_bucket partition (data_dt='20210702',channel=110)
select id,name,likes,address from part_out where data_dt='20210702' and channel=110;
insert overwrite table part_out_bucket partition (data_dt='20210702',channel=120)
select id,name,likes,address from part_out where data_dt='20210702' and channel=120;
hive> select * from part_out_bucket;
OK
8 小明8 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
4 小明4 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
9 小明9 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
5 小明5 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
1 小明1 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
10 小明10 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
6 小明6 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
2 小明2 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
7 小明7 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
3 小明3 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 110
20 小明20 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
16 小明16 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
12 小明12 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
17 小明17 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
13 小明13 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
18 小明18 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
14 小明14 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
19 小明19 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
15 小明15 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
11 小明11 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210701 120
28 小明28 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
24 小明24 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
29 小明29 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
25 小明25 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
21 小明21 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
30 小明30 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
26 小明26 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
22 小明22 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
27 小明27 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
23 小明23 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 110
48 小明48 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
44 小明44 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
49 小明49 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
45 小明45 ["lol","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
41 小明41 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
50 小明50 ["lol","book","skill"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
46 小明46 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
42 小明42 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
47 小明47 ["lol","book"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
43 小明43 ["lol","book","movie"] {"beijing":"mashibing","shanghai":"pudong"} 20210702 120
Time taken: 0.117 seconds, Fetched: 40 row(s)
spark-sql操作
create table part_in_spark (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(data_dt string,channel int)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
分区字段相当于虚字段,实际数据中不存在,但hive查询时会显示分区列
本地路径,复制文件到hdfs
load data local inpath '/opt/part1.txt' into table part_in_spark partition (data_dt='20210701',channel=110);
create external table part_out_spark (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(data_dt string,channel int)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
location '/var/bigdata/hive_remote/warehouse/part_out_spark';
本地路径,复制文件到hdfs
load data local inpath '/opt/part1.txt' overwrite into table part_out_spark partition (data_dt='20210701',channel=110);
create table part_in_spark_bucket (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(data_dt string,channel int)
clustered by (id) into 4 buckets
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
//不能用load data
//
Error in query: Output Hive table `default`.`part_in_spark_bucket` is bucketed but Spark currently does NOT populate bucketed output which is compatible with Hive.;
2.3.4不支持分桶表的插入
//
insert overwrite table part_in_spark_bucket partition (data_dt='20210701',channel=110)
select id,name,likes,address from part_in_spark where data_dt='20210701' and channel=110;
create external table part_out_spark_bucket (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(data_dt string,channel int)
clustered by (id) into 4 buckets
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
location '/var/bigdata/hive_remote/warehouse/part_out_spark_bucket';
//不能用load data
//
Error in query: Output Hive table `default`.`part_in_spark_bucket` is bucketed but Spark currently does NOT populate bucketed output which is compatible with Hive.;
2.3.4不支持分桶表的插入
//
insert overwrite table part_out_spark_bucket partition (data_dt='20210701',channel=110)
select id,name,likes,address from part_out where data_dt='20210701' and channel=110;
对原有hive表操作
load data local inpath '/opt/part1.txt' into table part_in partition (data_dt='20210701',channel=110);
load data local inpath '/opt/part1.txt' [overwrite] into table part_out partition (data_dt='20210701',channel=110);
关于压缩包格式
textFile可以读取gzip和bzip2压缩的数据
但有个问题,压缩包中文件第一行会带有文件元数据信息以及具体文本内容
比如这样
a1 0000644 0000000 0000000 00000000025 14076475501 010006 0 ustar root root a1a11
a2 a22
a3 a33
b1 0000644 0000000 0000000 00000000025 14076475516 010015 0 ustar root root b1 b11
b2 b22
b3 b33
gzip不能分割,只能一个并行度/分区
bzip2可以分割,可以指定并行度/分区
创建其他表格式
create table pua
(
id int,
name string
)
row format delimited
fields terminated by '\t'
stored as PARQUET
查看当前表格式
desc formatted pua
hive> desc formatted pua;
OK
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: default
Owner: root
CreateTime: Sat Jul 31 14:24:40 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/var/bigdata/hive_remote/warehouse/pua
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1627712680
# Storage Information
SerDe Library: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat // PARQUET
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat //PARQUET
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.057 seconds, Fetched: 32 row(s)
===================================
hive> desc formatted part_in_spark;
OK
# col_name data_type comment
id int
name string
likes array<string>
address map<string,string>
# Partition Information
# col_name data_type comment
data_dt string
channel int
# Detailed Table Information
Database: default
Owner: root
CreateTime: Sat Jul 31 13:57:46 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/var/bigdata/hive_remote/warehouse/part_in_spark
Table Type: MANAGED_TABLE
Table Parameters:
numFiles 1
numPartitions 1
numRows 0
rawDataSize 0
spark.sql.create.version 2.3.4
spark.sql.sources.schema.numPartCols 2
spark.sql.sources.schema.numParts 1
spark.sql.sources.schema.part.0 {\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"likes\",\"type\":{\"type\":\"array\",\"elementType\":\"string\",\"containsNull\":true},\"nullable\":true,\"metadata\":{}},{\"name\":\"address\",\"type\":{\"type\":\"map\",\"keyType\":\"string\",\"valueType\":\"string\",\"valueContainsNull\":true},\"nullable\":true,\"metadata\":{}},{\"name\":\"data_dt\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"channel\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}
spark.sql.sources.schema.partCol.0 data_dt
spark.sql.sources.schema.partCol.1 channel
totalSize 575
transient_lastDdlTime 1627711066
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat // TEXTFILE
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat //TEXTFILE
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim ,
field.delim \t
mapkey.delim :
serialization.format \t
Time taken: 0.097 seconds, Fetched: 48 row(s)
hive>
SparkStreaming
你写的代码都是丢到另一个线程执行的。
_ 作用域分为三个级别:
application
job
rdd:task
直接裸露的代码
println(“aaaaaaa”) //application,只执行一次
val res: DStream[(String, Int)] = format.transform( //每job调用一次
(rdd) => {
//我们的函数式每job级别的
println(“bbbbbbbb”) //job driver
_rdd.map(x=>{
_println(“cccccc”) _//task executor
_x
})
}
)
res
res.print() //job

若有收获,就点个赞吧
0 人点赞
