- 消息系统:消息队列具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。此外,Kafka 还提供了消息顺序性保障及回溯消费的功能。
- 存储系统:把消息数据持久化到磁盘。(默认7天,修改保留策略为“永久”或启用主题的日志压缩)。
流式处理平台:提供一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
概念
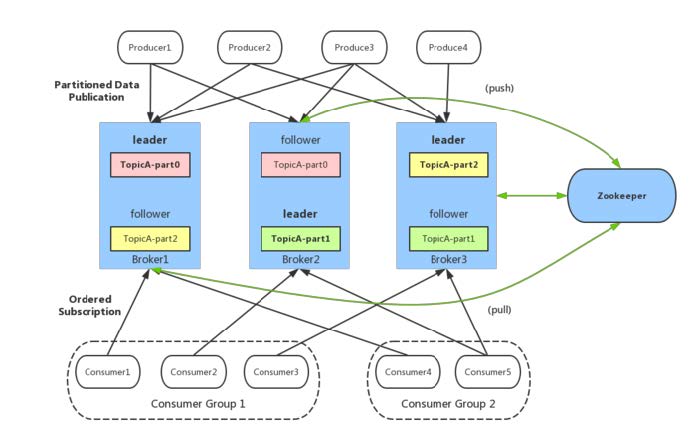
Producer:消息生产者
- Consumer:消息消费者
- Consumer Group:消费者分组,每个Consumer必须属于一个group
- Broker:Kafka 服务代理节点,负责消息存储和转发
- Topic:主题,按 topic 对消息分类
- Partition:topic 的分区,一个topic可以包含多个分区,不同分区消息不同;在存储层面可看作一个可追加的日志( Log )文件
- Offset:消息在被追加日志文件中会被配一个特定偏移量,代表消息在分区中的唯一标识;offset 不跨越分区
- Replica:副本,增加副本数量可以提升容灾能力(同一时刻,副本之间数据并非完全一样)
- Zookeeper:保存着集群broker、topic、partition等元(meta)数据;另外,还负责broker故障发现,partition leader 选举,负载均衡等功能
- AR:Assigned Replicas,分区中的所有副本。AR=ISR+OSR
- ISR:In-Sync Replicas,与 leader 副本保持 ‘一定程度’ 同步的副本(包括 leader 副本)
- OSR:Out-of-Sync Replicas,与 leader 副本同步 ‘滞后过多’ 的副本(不包扩 leader 副本)
生产者和消费者只与 leader 副本进行交互,而 follow 副本只负责消息的同步。leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当 follower 副本落后或失效时,leader 副本会把它从 ISR 集合中剔除; 如 OSR 集合中有 follower 副本 “追上” leader 副本,那么 leader 副本 它从 OSR 集合转移至 ISR 集合
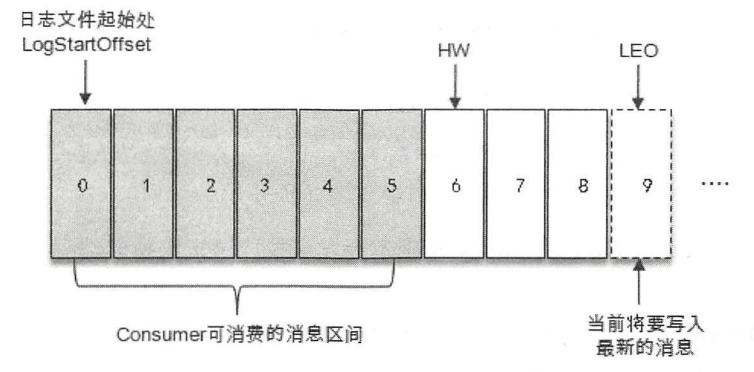
13. HW:High Watermark(高水位),一个特定的 offset,消费者只能拉取到这个 offset 之前的消息
14. LEO:Log End Offset,下一条待写入消息 offset
操作命令
下载
wget https://dlcdn.apache.org/kafka/2.8.0/kafka_2.13-3.1.0.tgztar -xzf kafka_2.13-3.1.0.tgz
修改配置文件server.properties
broker.id=0 listeners=PLAINTEXT://172.27.0.229:9092 advertised.listeners=PLAINTEXT://172.27.0.229:9092 log.dirs=/home/quant_group/data/kafka/kafka_datas zookeeper.connect=172.27.0.229:2181,172.27.0.243:2181,172.27.0.193:2181Start service
# 启动zookeeper bin/zookeeper-server-start.sh -daemon config/zookeeper.properties # 启动Kafka bin/kafka-server-start.sh -daemon config/server.propertiestopic命令
# 查看topic列表 bin/kafka-topics.sh --bootstrap-server 172.27.0.229:9092,172.27.0.193:9092,172.27.0.243:9092 --list # 创建topic bin/kafka-topics.sh --bootstrap-server 172.27.0.229:9092 --create --partitions 1 --replication-factor 3 --topic first # 查看topic详情 bin/kafka-topics.sh --bootstrap-server 172.27.0.229:9092 --describe --topic first # 修改分区数(注意:分区数只能增加,不能减少) bin/kafka-topics.sh --bootstrap-server 172.27.0.229:9092 --alter --topic first --partitions 3 # 删除 topic bin/kafka-topics.sh --bootstrap-server 172.27.0.229:9092 --delete --topic first生产者
bin/kafka-console-producer.sh --bootstrap-server 172.27.0.229:9092 --topic first消费者/组
# 消费主题中的数据 bin/kafka-console-consumer.sh --bootstrap-server 172.27.0.229:9092 --topic first # 消费历史数据(从头开始) --from-beginning # 查看消费者组IP bin/kafka-consumer-groups.sh --bootstrap-server 172.27.0.229:9092,172.27.0.193:9092,172.27.0.243:9092 --list生产者
生产者原理
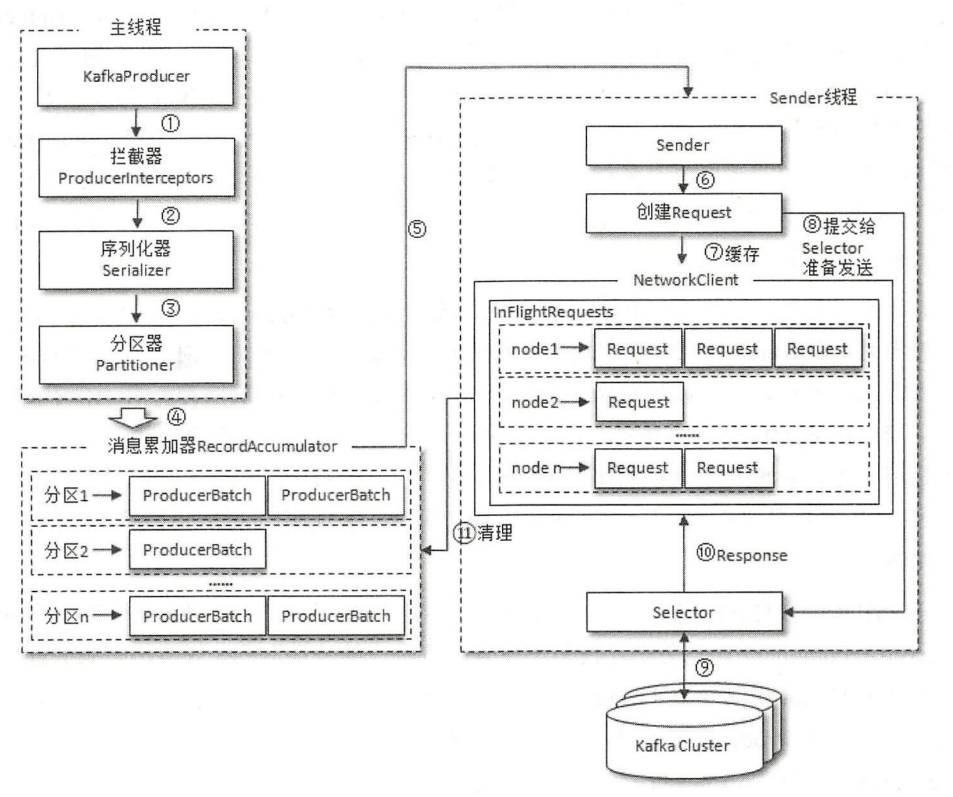
生产者客户端由
主线程+Sender线程构成。主线程中由KafkaProducer生产消息,然后经过拦截器、序列化器分区器作用后缓存到RecordAccumulator(消息累加器);Sender线程负责从 RecordAccumulator 中获取消息并发送到 Kafka 中。- RecordAccumulator:缓存消息以便 Sender线程 批量发送,进而减少网络传输次数提升整体吞吐量。默认缓存大小
buffer.memory=32M。RecordAccumulator的内部为每个分区都维护一个双端队列:Deque<ProducerBatch>,消息追加到队列尾部,Sender从队列头部读取消息。ProducerBatch指一个消息批次,包含多个ProducerRecord。 - BufferPool:RecordAccumulator内部会维护一个
BufferPool,减少频繁的创建和释放ByteBuffer。只针对特定大小ByteBuffer进行管理,默认batch.size=16KB - Sender 线程获取消息后,会进一步将原本
<分区, Deque<ProducerBatch>>的保存形式转变为<Node, List<ProducerBatch>>,Node代表Kafka的broker节点。之后还会进一步封装成<Node, Request>形式,Request代表Kafka的请求协议。 请求从 Sender 线程发往 Kafka 之前还会保存在
InFlightRequests中,InFlightRequests 中保存的对象形式为Map<NodeId, Deque<Request>>,作用是缓存已经发布去但还没有收到响应的请求,默认缓存5个未响应的请求,max.in.flight.requests.per.connect=5。发送模式
发后即忘(fire-and-forget)
- 异步(async)
- 同步(sync)
生产者客户端
步骤:
1. 配置生产者客户端参数及创建响应生产者实例
2. 构建待发送的消息
3. 发送消息
4. 关闭生产者实例public class Producer { public static void main(String[] args) { // 1. 配置生产者客户端参数及创建响应生产者实例 Properties properties = new Properties(); // 连接集群 bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092"); // 指定对应的key和value的序列化类型 key.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 创建kafka生产者对象 KafkaProducer<String, String> producer = new KafkaProducer<>(properties); // 2. 构建待发送的消息 ProducerRecord<String, String> record = new ProducerRecord<>("first", "Hello, kafka"); // 3. 发送数据 try { // a. 发后即忘。 send() 默认异步 producer.send(record); // b. 异步回调 producer.send(record, new Callback() { // RecordMetadata 与 Exception 存在互斥 @Override public void onCompletion(RecordMetadata metadata, Exception e) { if (e == null){ System.out.println("topic:"+metadata.topic() + " partition:"+ metadata.partition()); } else { // 记录错误日志 或 处理让消息重发 e.printStackTrace(); } } }); // c. 同步 producer.send(record).get(); } catch (InterruptedException | ExecutionException e) { // 记录错误日志 或 处理让消息重发 e.printStackTrace(); } // 4. 关闭资源 producer.close(); } }Ack确认机制
0:生产者发送消息后,不需要等broker响应。吞吐量最大,会丢消息。
1:acks的默认值;生产者会收到leader副本写入成功的响应。如leader副本返回成功响应给生产者的时候,被follow副本拉取前挂了,那么消息还会丢。
-1:或acks=all;生产者发送消息后,需要等ISR中所有副本都成功响应。消息可靠性最高,性能最差。消费者
Broker

若有收获,就点个赞吧
0 人点赞
