概述
为支持中医抗击新冠肺炎疫情,也为帮助岐黄数据AI工作站的新用户熟悉产品功能,我们以简单的用药前后中医舌图的差异性分析为例,编写了本研究范例,包括舌图定性判读的差异性分析和舌图客观定量参数的差异性分析,具体步骤包括以下5步:
- 采集患者中医舌图
- 新建舌图研究项目
- 整理舌图研究数据
- 创建舌图数据表格
- 开展舌图差异分析
采集患者中医舌图
使用国医慧联APP采集患者中医舌图,具体操作方法请查看【如何使用国医慧联APP采集中医舌图数据】
新建舌图研究项目
使用岐黄数据AI工作站的【数据管理-研究项目】建立中医舌图研究项目,本范例将研究项目配置简化为仅涉及1个研究分组、1次访视和2个CRF量表,您可以根据您真实的研究方案进行对应调整。本范例的具体操作方法如下所述。想要更多了解如何创建项目,您也可以进一步查看【如何创建研究项目】操作指南
视频教程

图文教程
登陆岐黄数据AI工作站,点击进入【数据管理-研究项目】页面,在页面右上角点击【创建项目】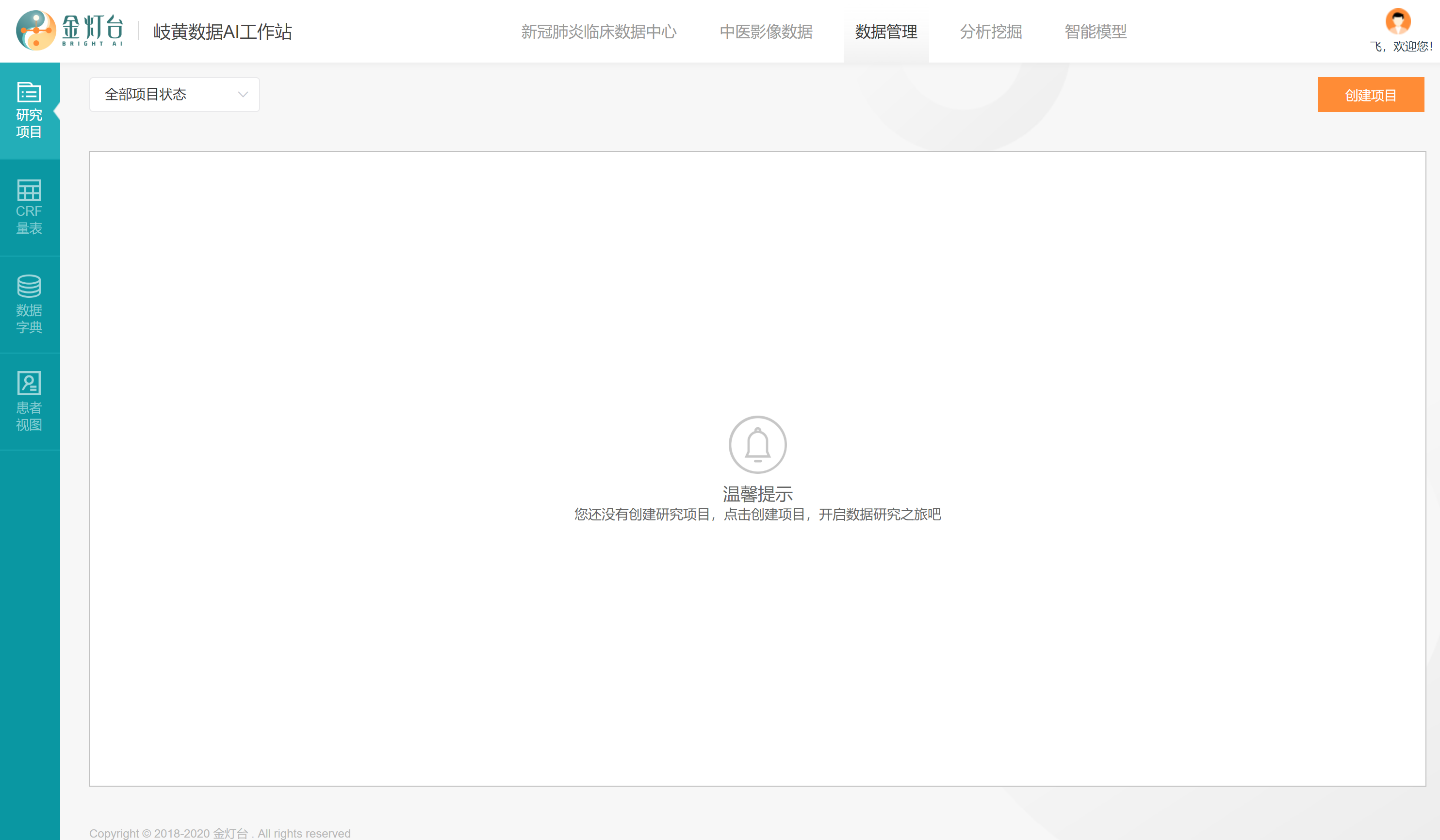
创建过程分为3步,第1步完善项目基本信息,例如项目名称填写“新冠肺炎中医舌图研究”、主要研究者填写“李医生”,完成后点击【下一步】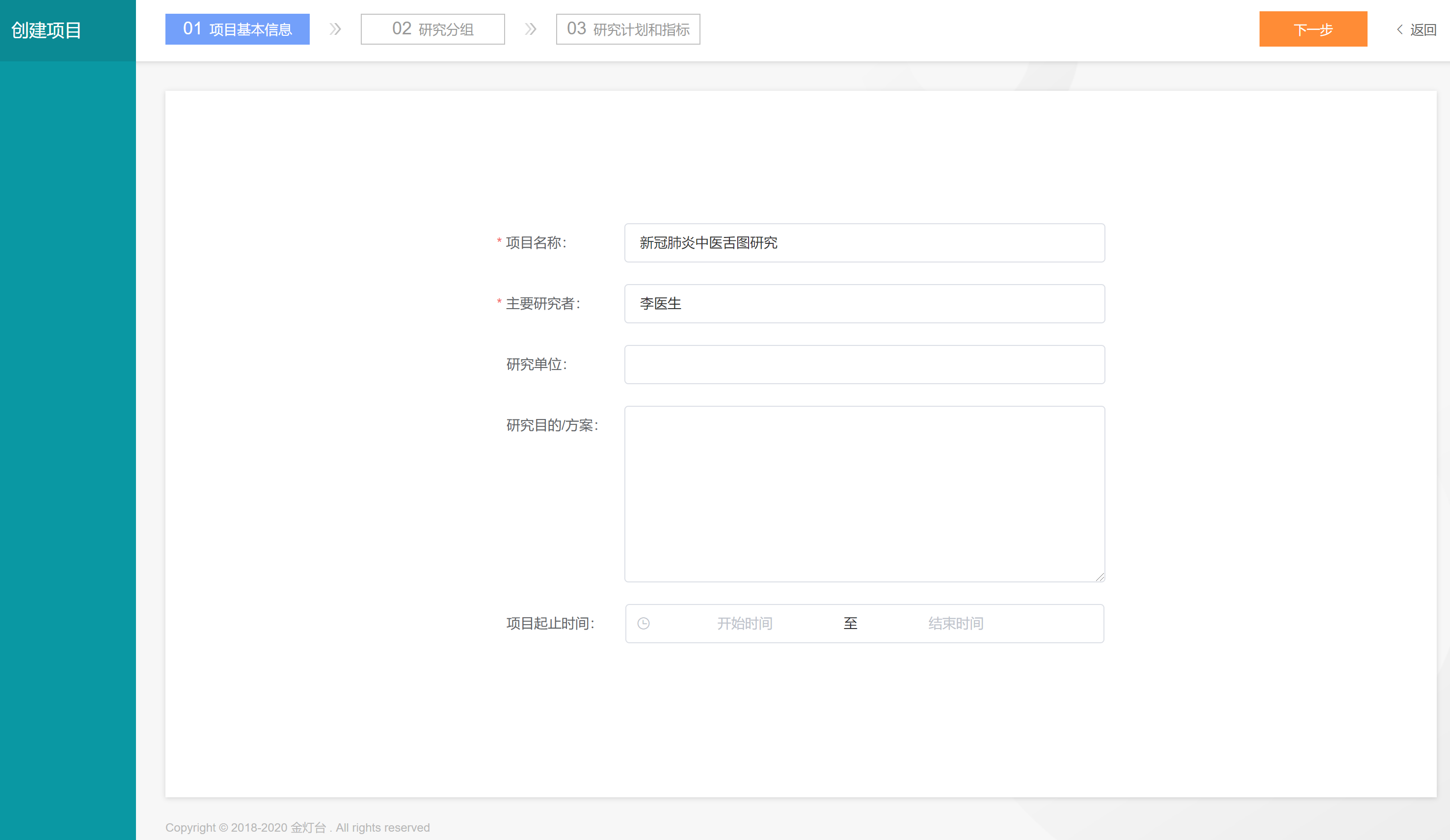
第2步添加研究分组,本范例中我们直接使用工作站默认生成“分组1”,因此直接点击【下一步】
第3步配置访视计划和指标,本范例中为简化操作,我们不建立复杂的访视计划,直接使用工作站为“分组1”默认生成的“访视1”,如下图页面左侧边栏所示。点击右上角的【添加CRF量表】按钮,可以给【分组1-访视1】添加研究指标。本范例添加两个CRF量表:【舌象数据量表】(包含中医舌图及其相关专家判读结果和图像量化参数)和【中药诊治情况量表】。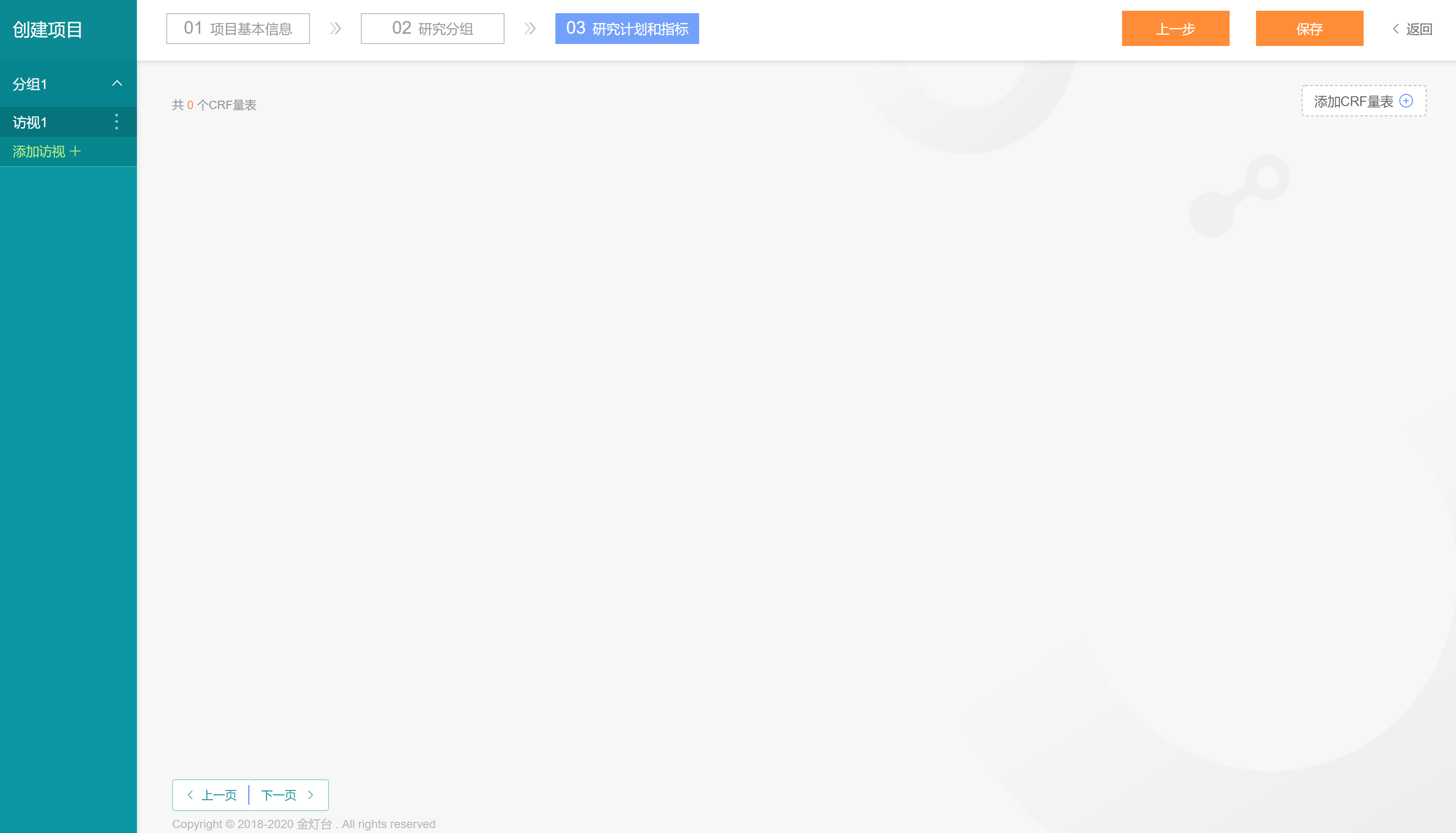
我们首先添加【舌象数据量表】,点击【添加CRF量表】按钮进入【从已有项目中选择CRF量表】弹出页面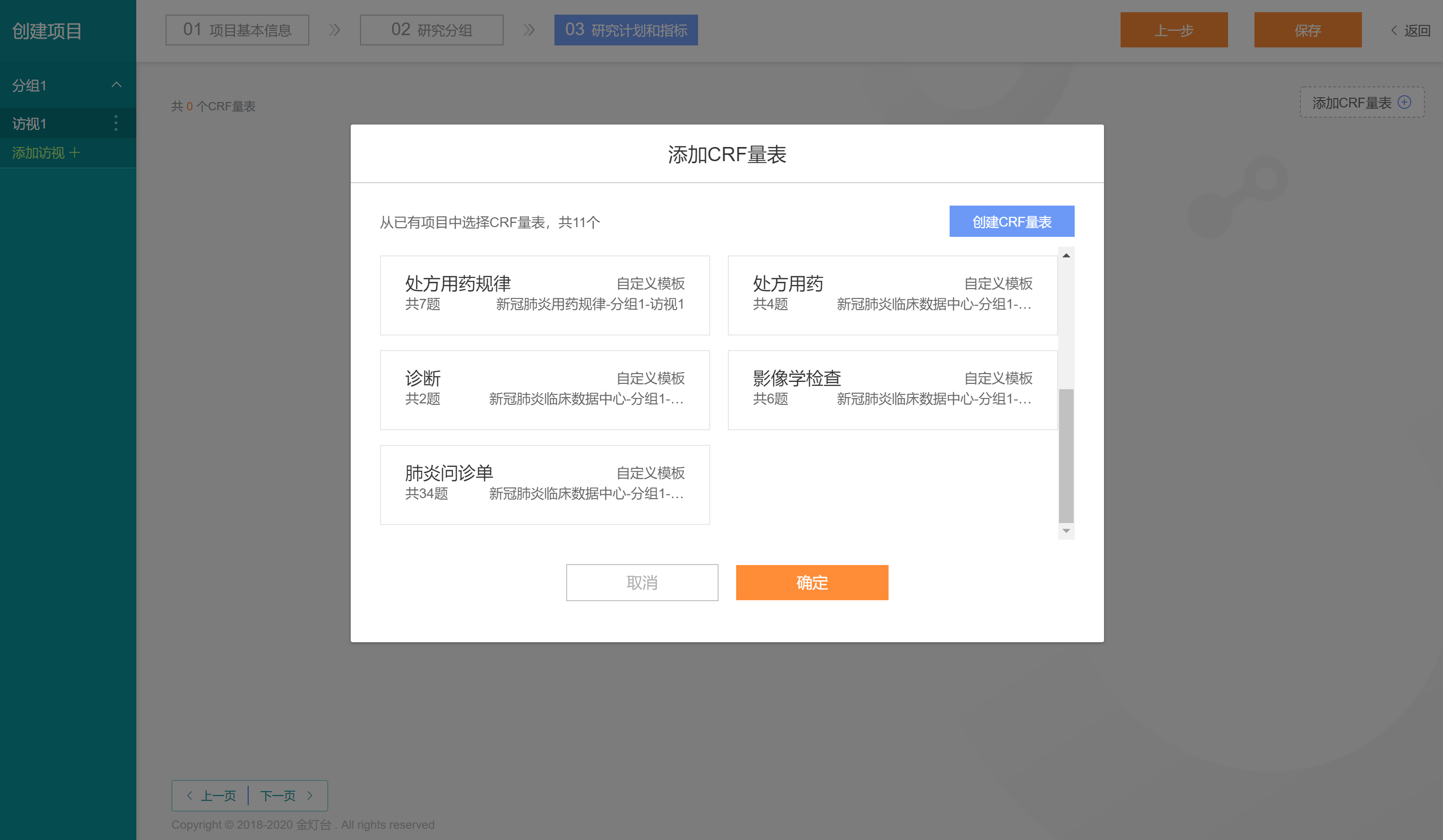
在弹出页面中继续点击【创建CRF量表】按钮,进入【创建CRF量表】页面,默认显示【数据字典】子页面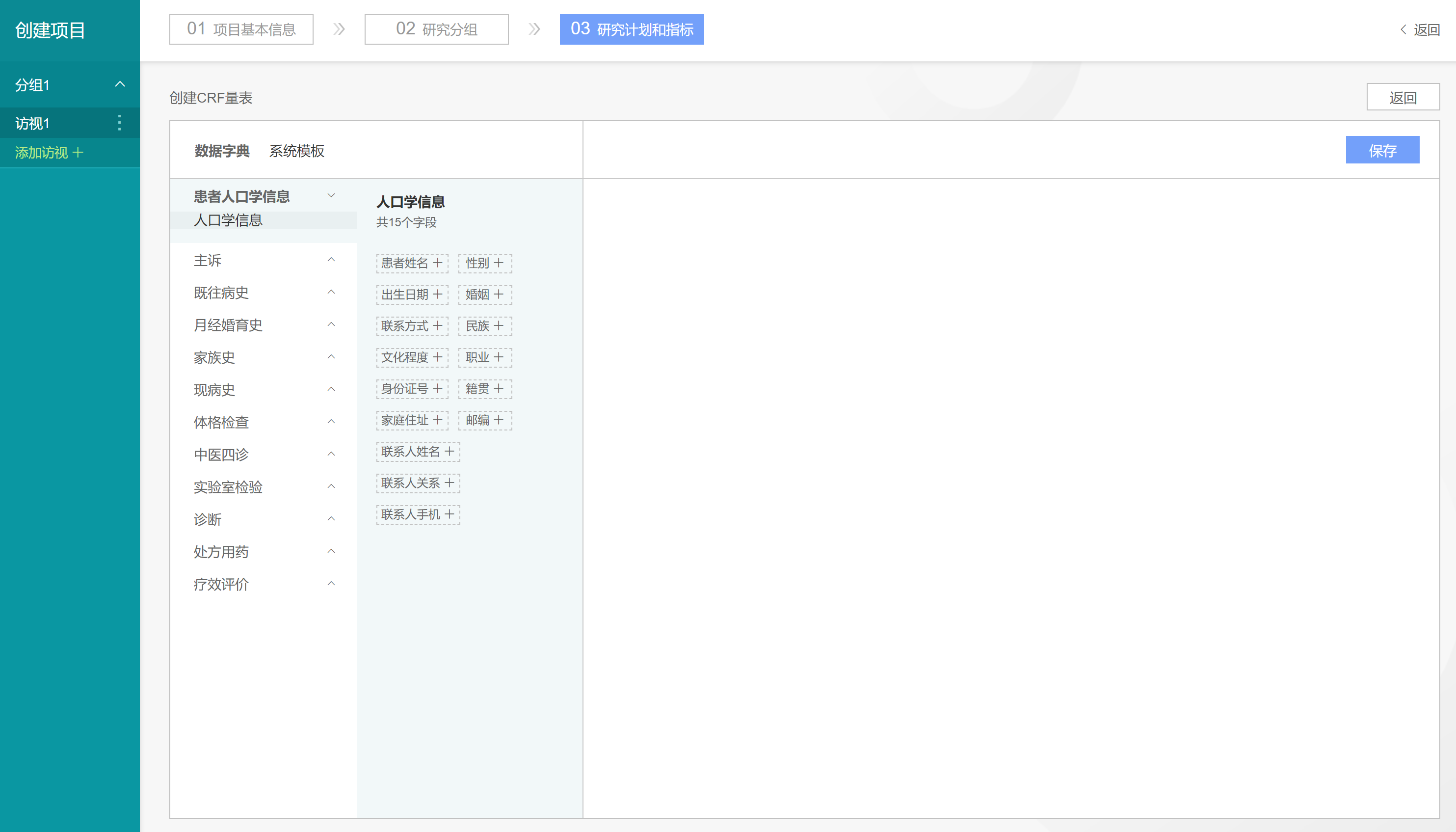
点击【系统模板】按钮,从【数据字典】子页面切换到【系统模板】子页面,在该页面我们选择默认的【舌象数据】系统模板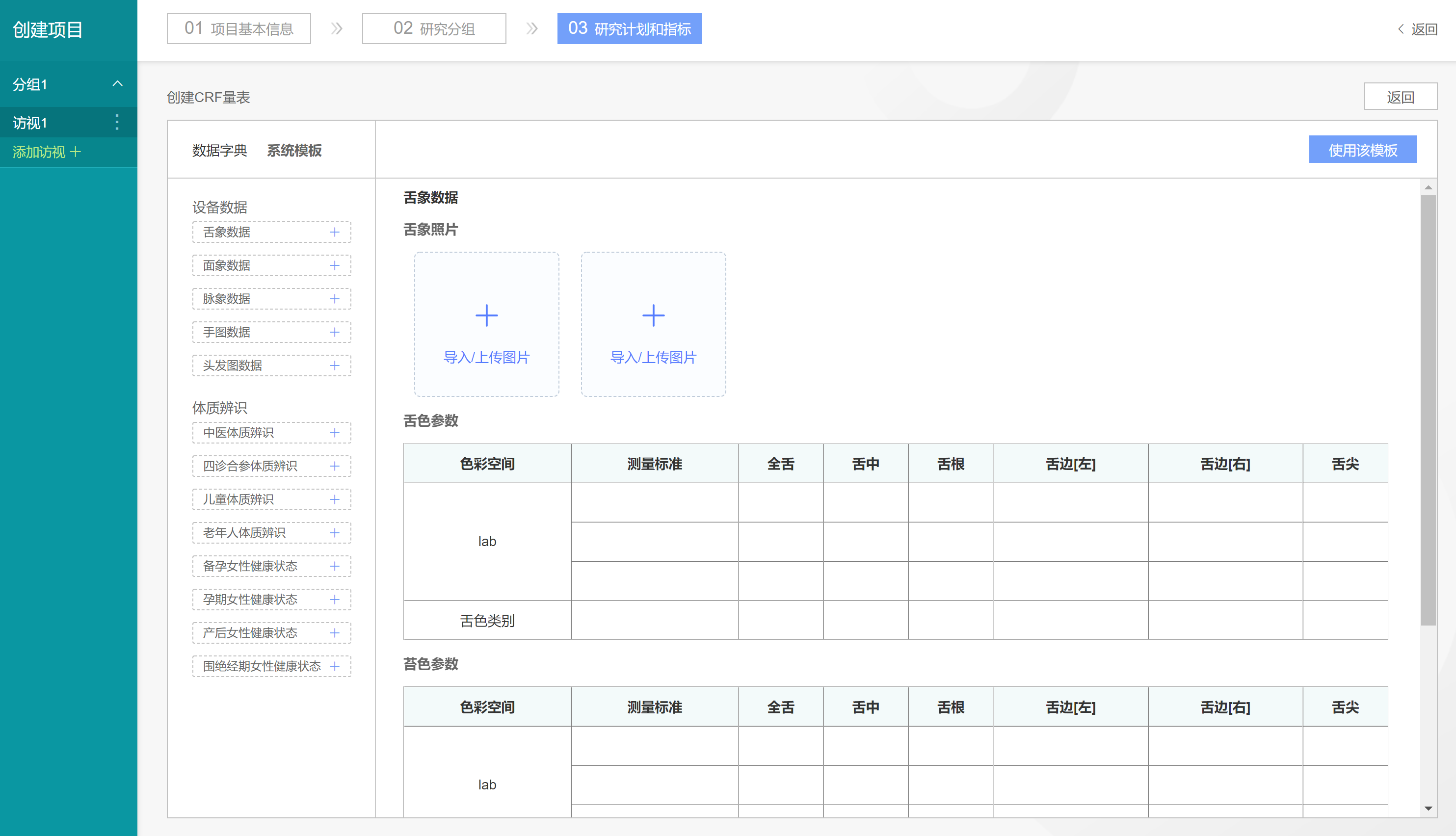
点击【使用该模板】按钮,即可将【舌象数据】系统模板添加到【分组1-访视1】中
我们继续添加【中药诊治情况量表】,再次点击【添加CRF量表】按钮,在弹出页面中点击【创建CRF量表】按钮,进入【创建CRF量表】页面,在数据字典中选择【处方用药-中药饮片信息】菜单,在右侧出现的相关字段中点击【是否用药】,将该字段添加到自定义的CRF量表中
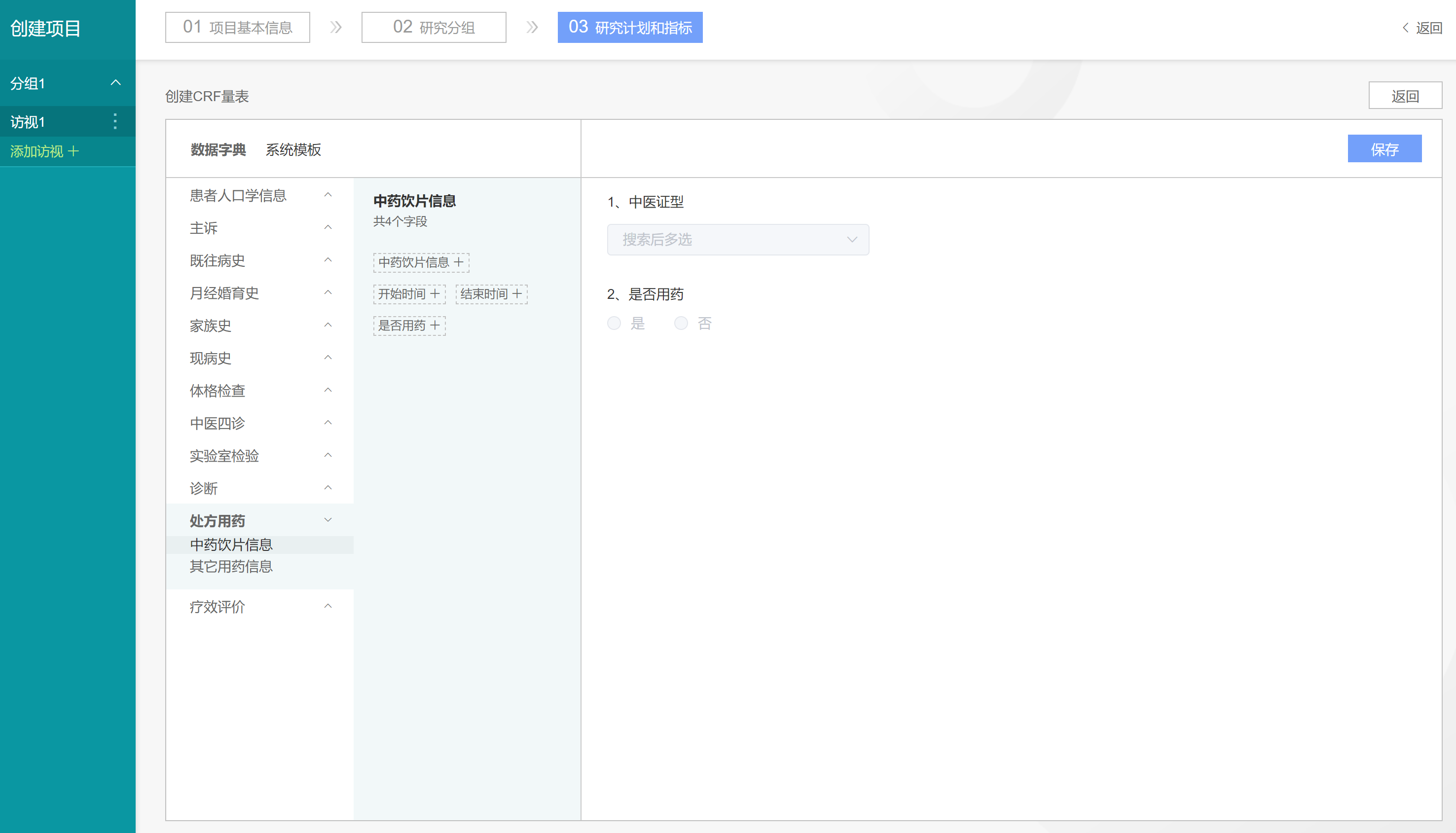
点击【保存】按钮,在弹出窗口中填写量表名称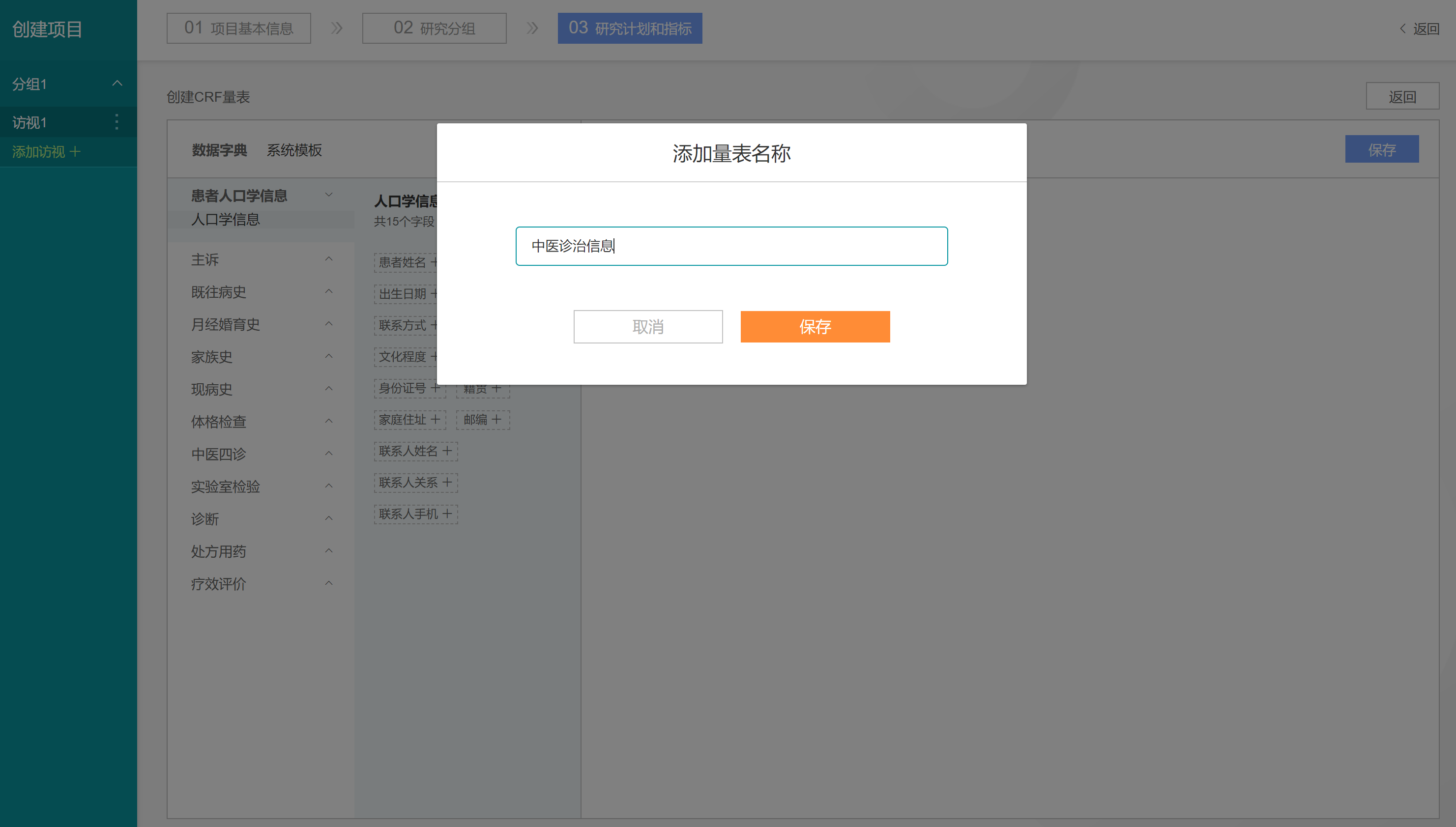
再次点击【保存】按钮,即可将【中药诊治情况】自定义量表添加到【分组1-访视1】中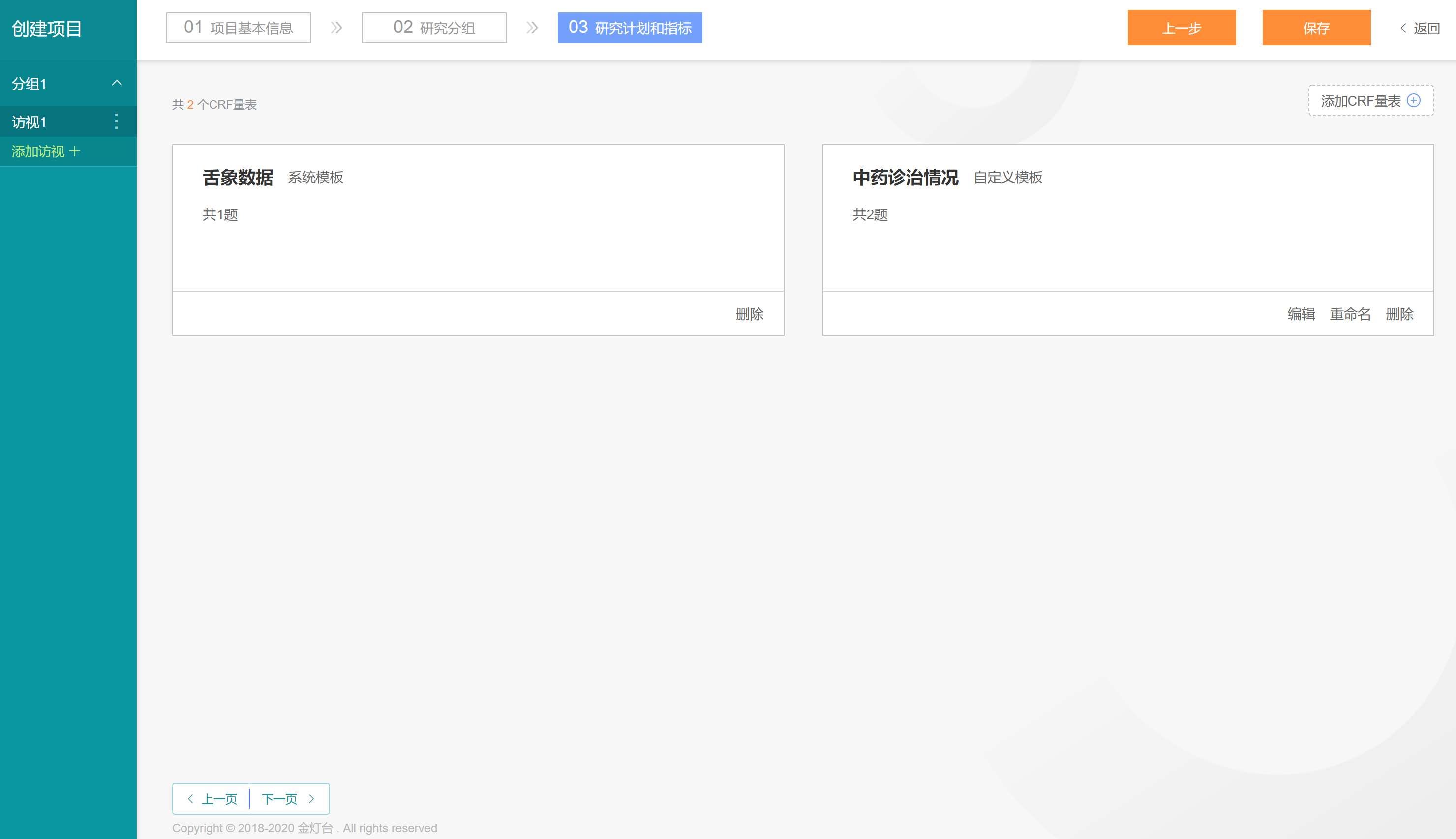
此时点击【创建项目】页面的【保存】按钮,完成新冠肺炎中医舌图研究项目创建。
整理舌图研究数据
新建好的研究项目中数据还是空的,接下来我们需要把采集的患者舌图导入研究项目中,并补充每张舌图对应患者是否用药的信息。
视频教程

图文教程
点击刚刚新建的【新冠肺炎中医舌图研究】项目,进入【研究项目详情】页面,点击【添加研究对象】菜单,选择从【中医影像数据中心添加】
进入【添加研究对象-从中医影像数据中心导入】页面,手动或通过高级筛选择要导入的患者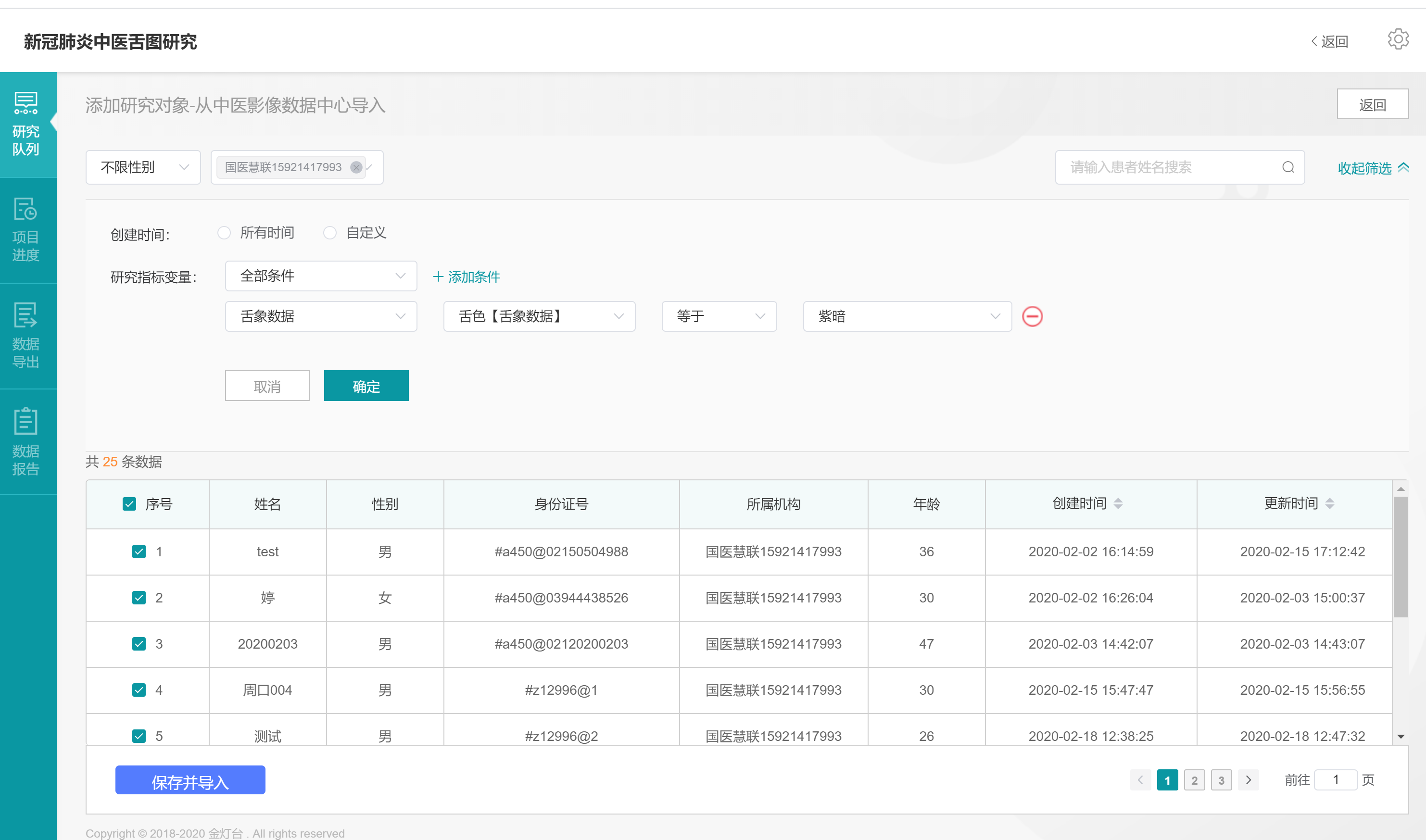
点击【保存并导入】,选择要导入的分组【分组1】,再点击【保存】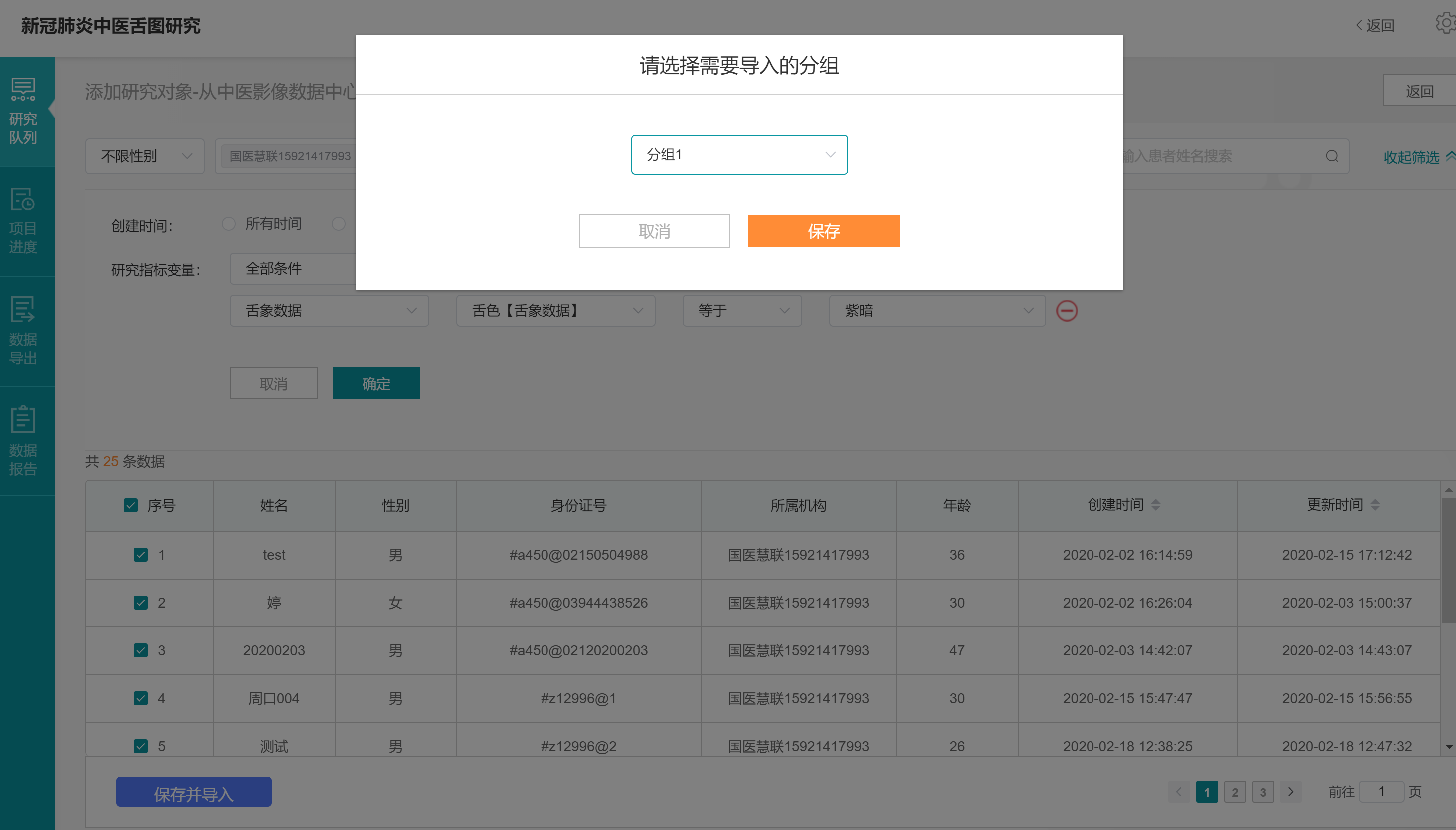
完成从【中医影像数据中心】导入我们之前通过国医慧联APP采集过中医舌图的患者信息,此时可以看到【患者信息列表】中【研究内容-访视1】的进度条状态为0%,因为此时我们仅仅导入了研究对象,还未导入研究数据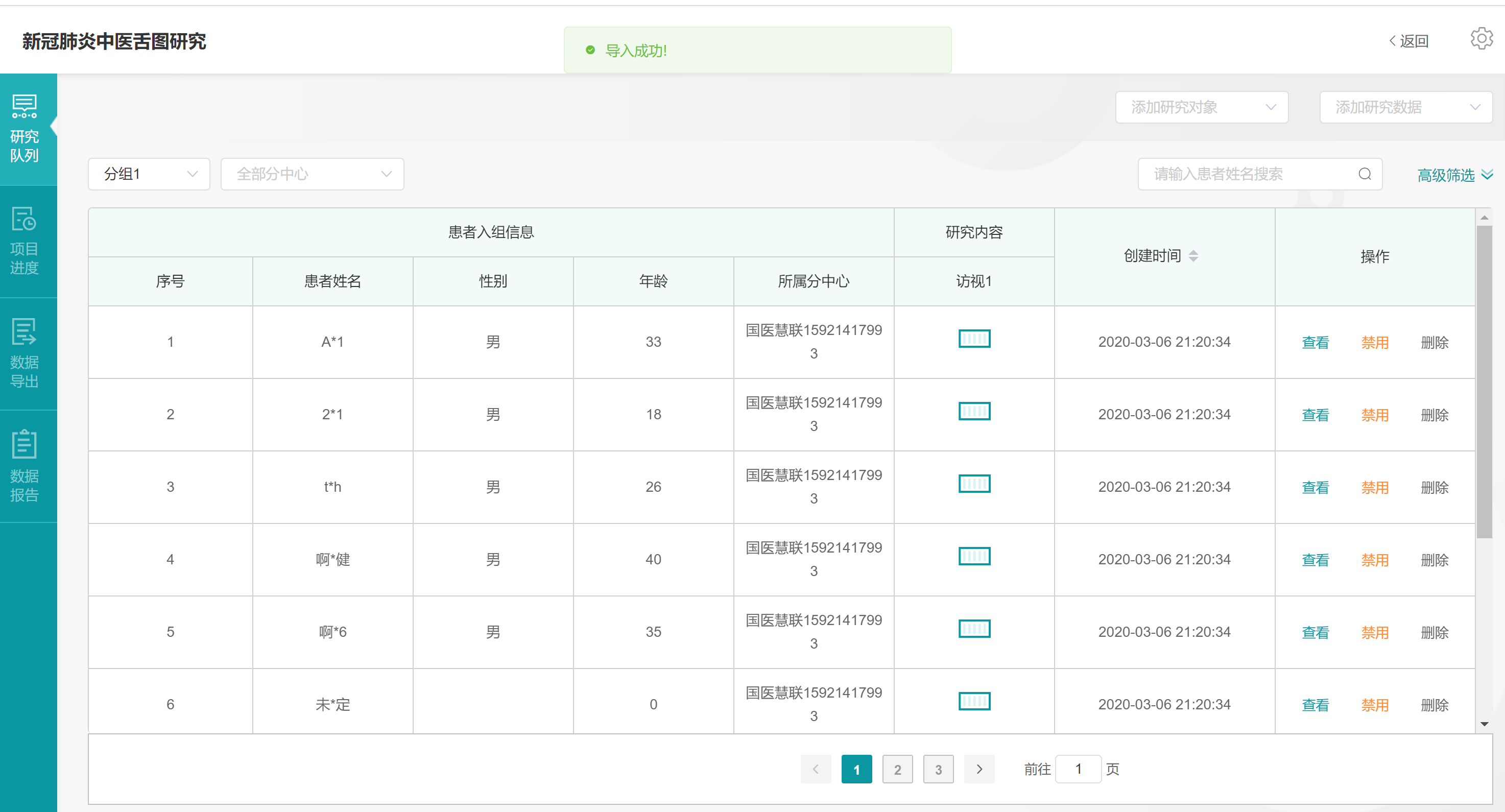
点击【添加研究数据】,选择【从中医影像数据中心添加】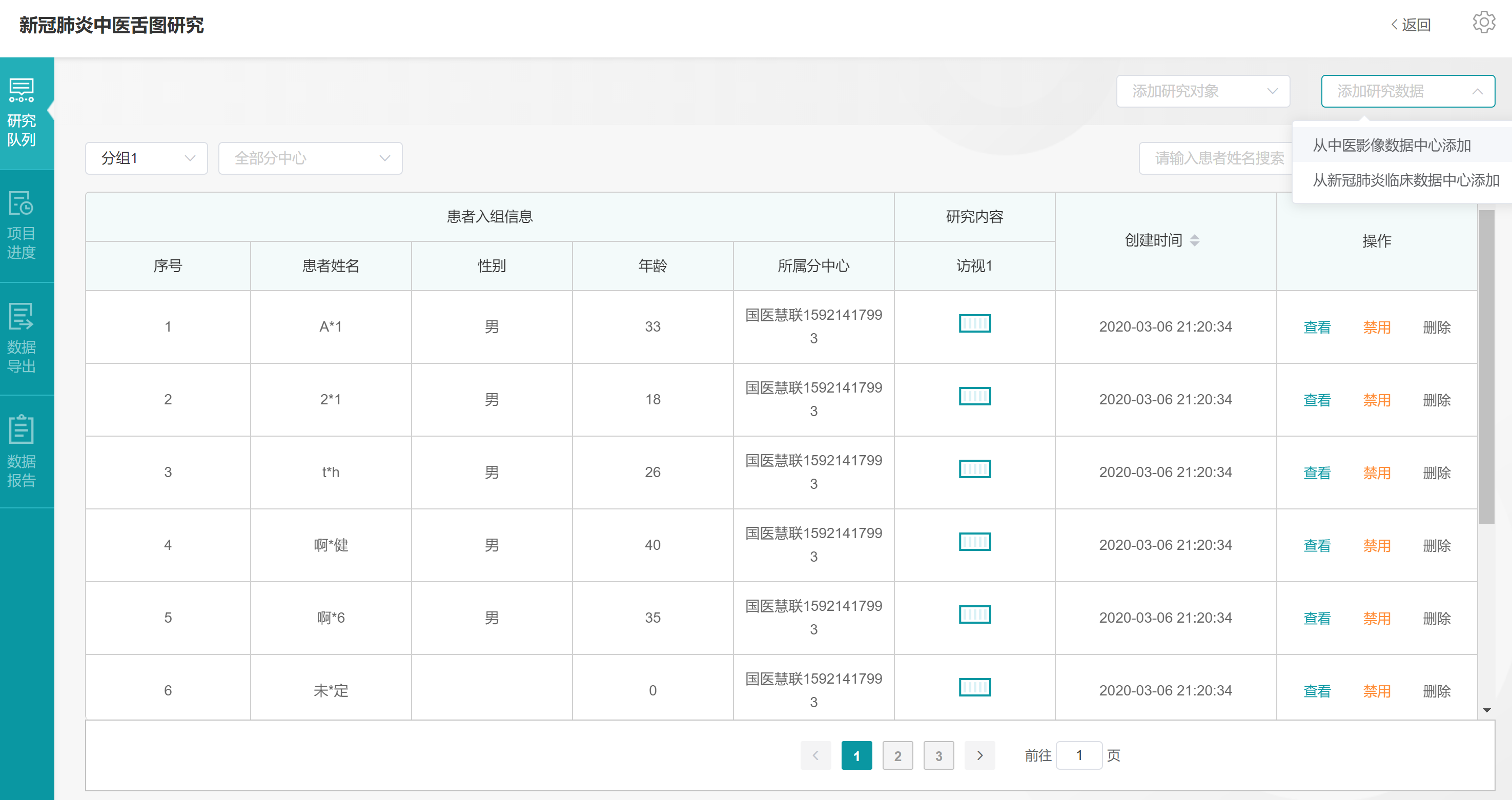
选择数据要导入的研究分组为【分组1】,要导入访视为【访视1】,要导入CRF量表为【舌象数据】,点击确定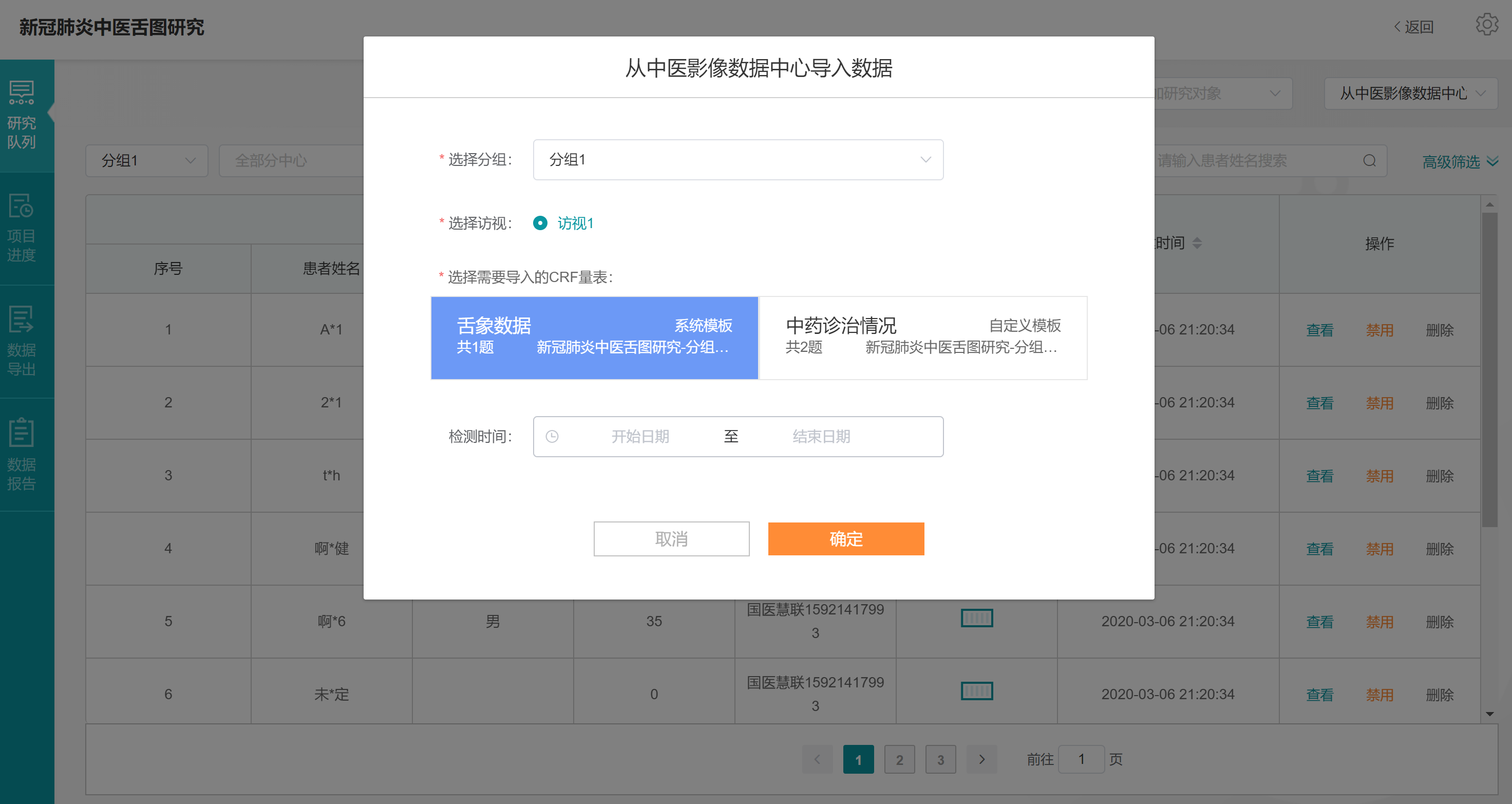
舌象数据导入成功,【研究内容-访视1】的进度条状态变成了50%左右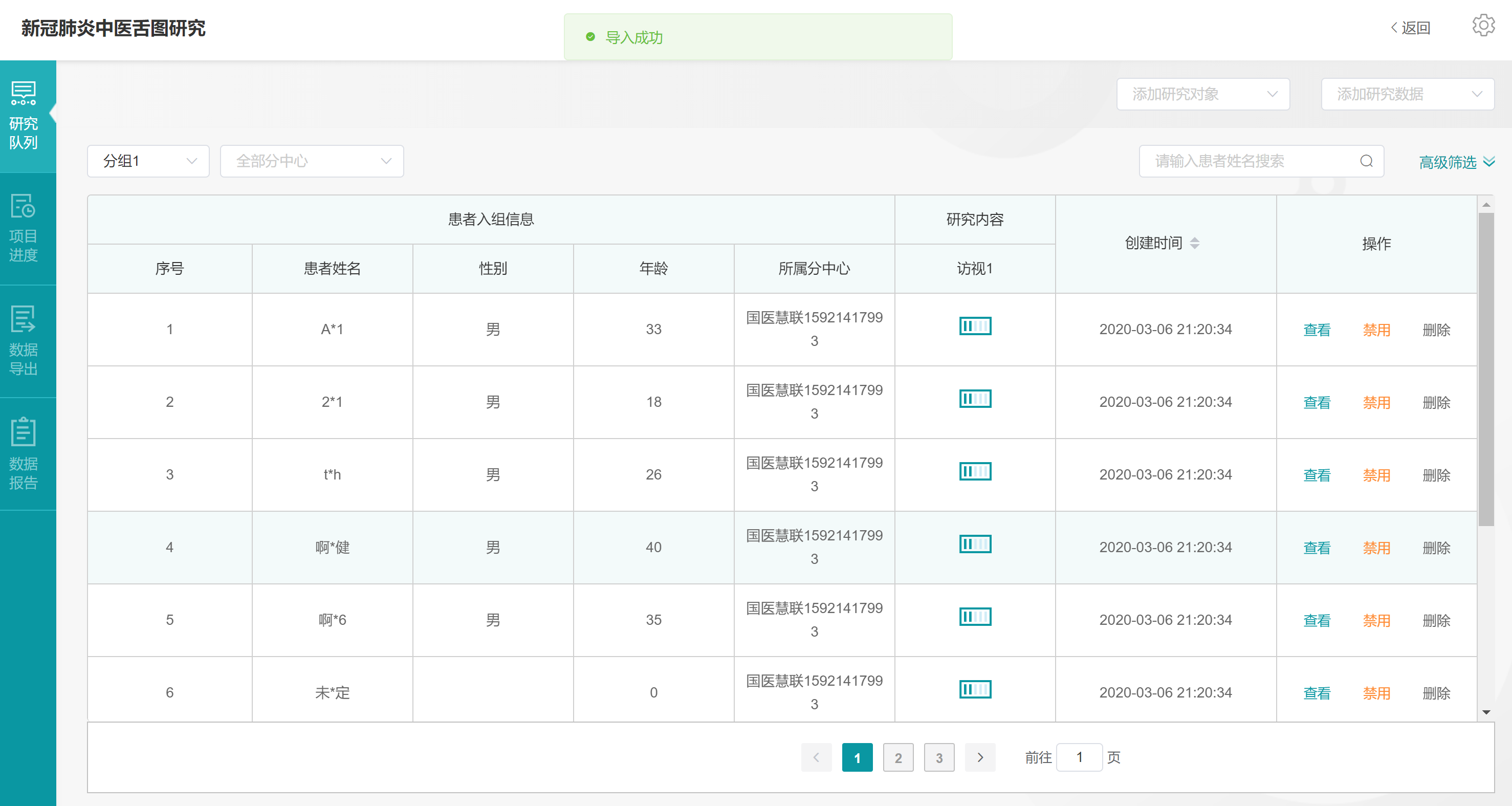
因为我们只用国医慧联APP采集了中医舌图,这里只能继续手动补充每张中医舌图属于“用药前”还是“用药后”。点击患者列表中任意一名患者的【查看】按钮,进入患者详情页,默认进入的是【患者基本信息】标签页
点击【访视1】菜单展开访视1相关的CRF量表列表,点击【舌象数据】,可以看到导入的中医舌图及其专家判读和图像参数等数据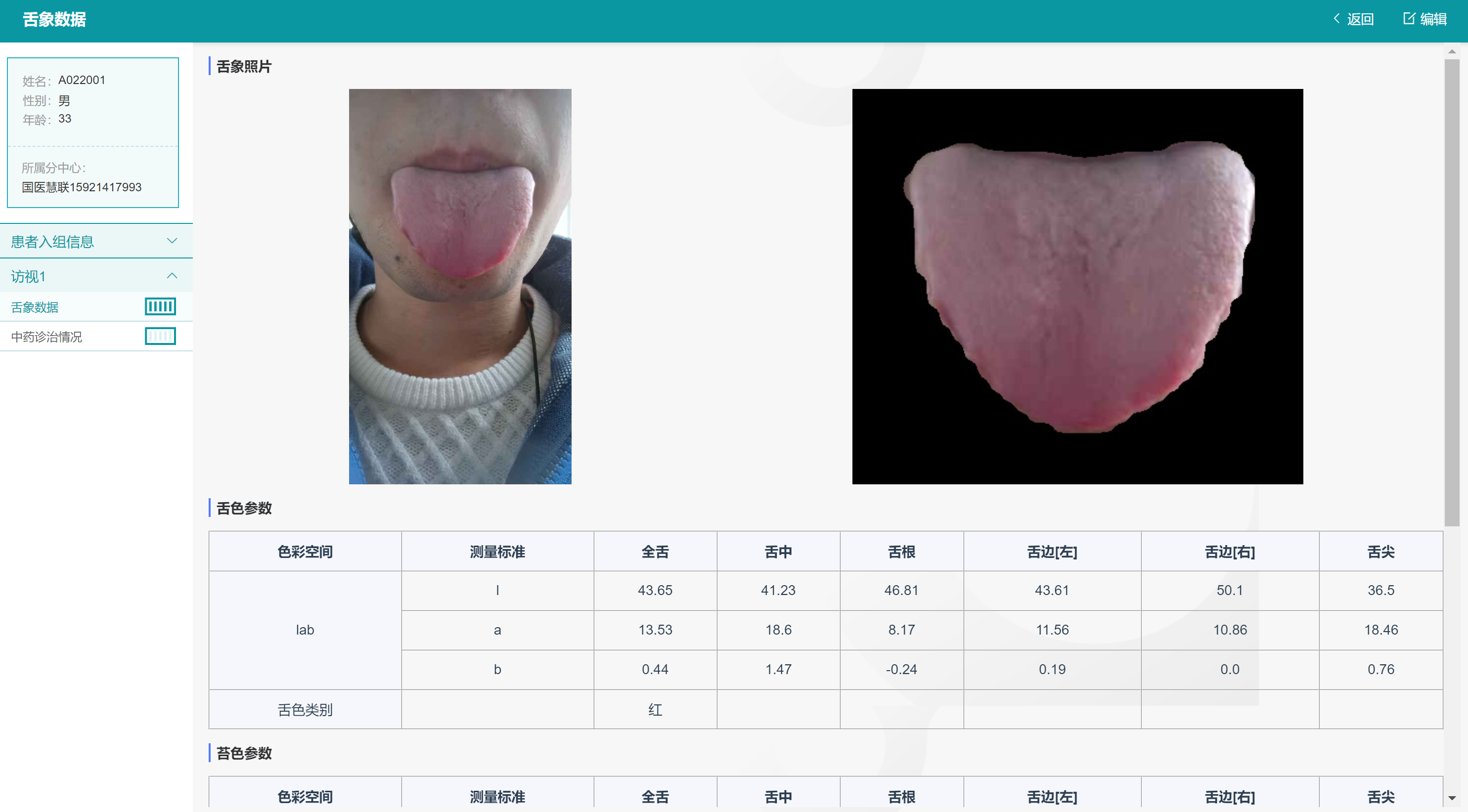
点击【中药诊治情况】打开中药诊治情况量表,默认为查看页面,点击右上角的【编辑】按钮即可编辑补充患者中医证型情况和是否用药情况,点击【保存】按钮完成该记录数据补充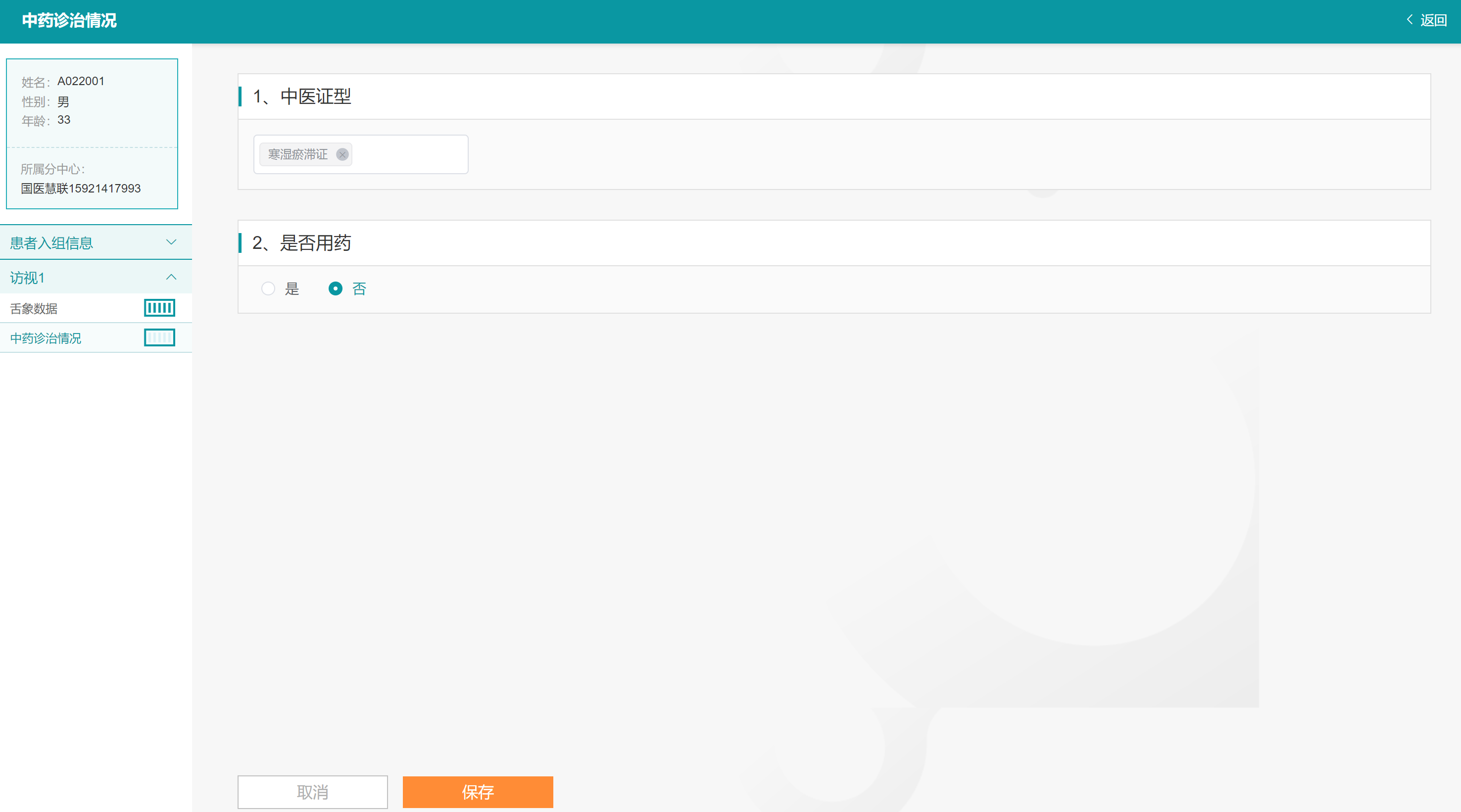
依次查看所有患者数据,补充中药诊治情况量表数据,直至所有患者【研究内容-访视1】的进度条状态变为100%
创建舌图数据表格
在完成数据整理后,我们需要创建结构化的研究数据表格,通过数据表格开展后续分析挖掘。
视频教程

图文教程
点击左侧栏的【数据导出】菜单,在【数据导出】页面点击右上角【创建数据表格】按钮进入【创建数据表格】页面
创建数据表格分为2步,首先在页面左侧【筛选研究对象】,设置数据表格名称后,可以按研究分组筛选、按分中心筛选、按创建时间范围筛选,更可以按研究指标变量进行高级筛选,例如筛选舌象数据CRF量表中舌色等于“紫暗”并且中药诊治情况量表中是否用药情况等于“是”的数据。在本范例中,我们设置数据表格名称为“用药前后中医舌图分析数据表格”,研究分组选择我们创建的“分组1”,分中心只选择我们采集中医舌图使用国医慧联APP账号,创建时间选择“所有时间”,研究指标变量不配置。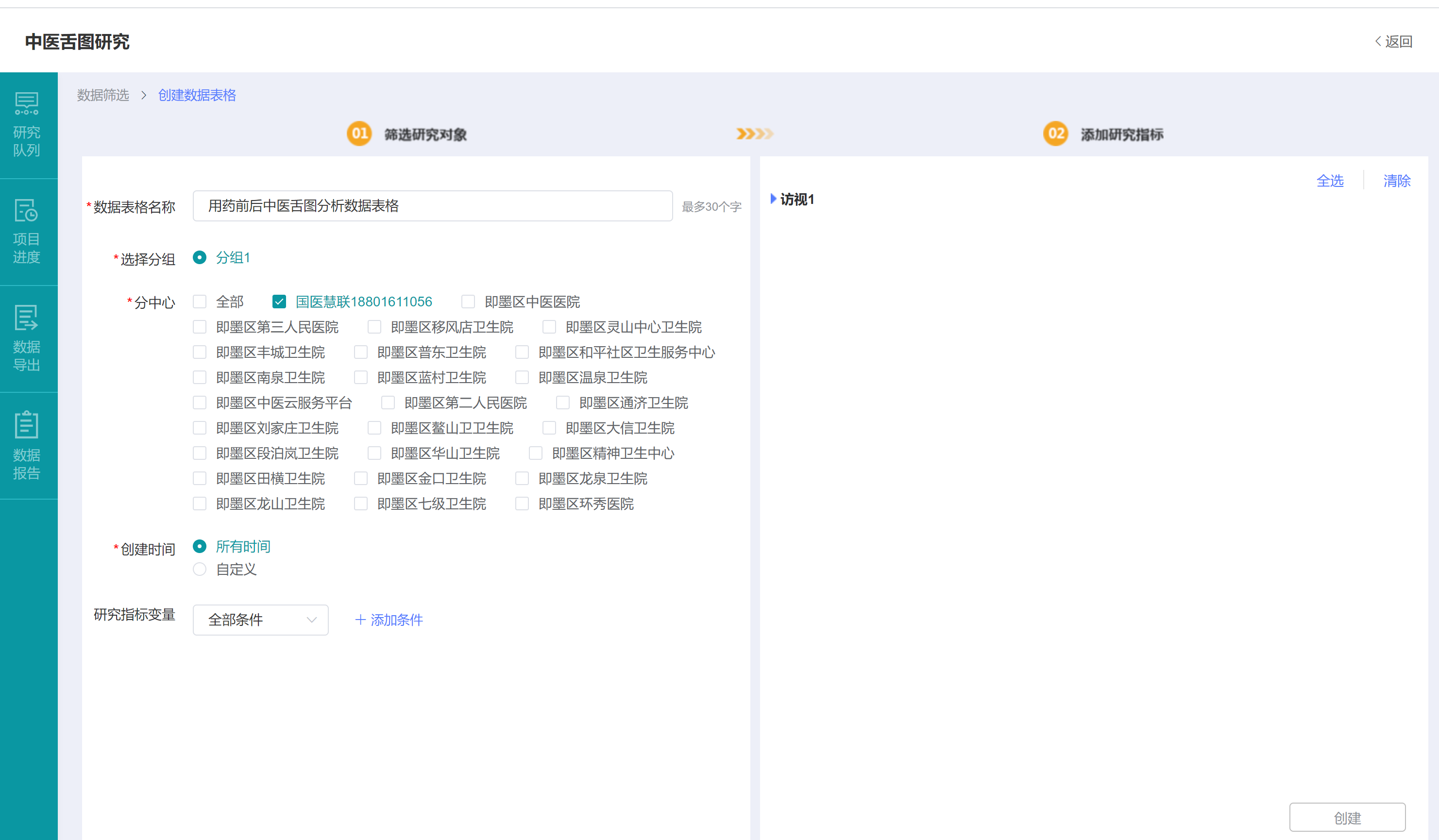
接下来,在页面右侧【添加研究指标】,您可以只选择特定的数据字段导出到新建的数据表格中。本范例中,我们选择全部CRF量表中的全部数据字段,如下图,之后点击右下角的【创建】按钮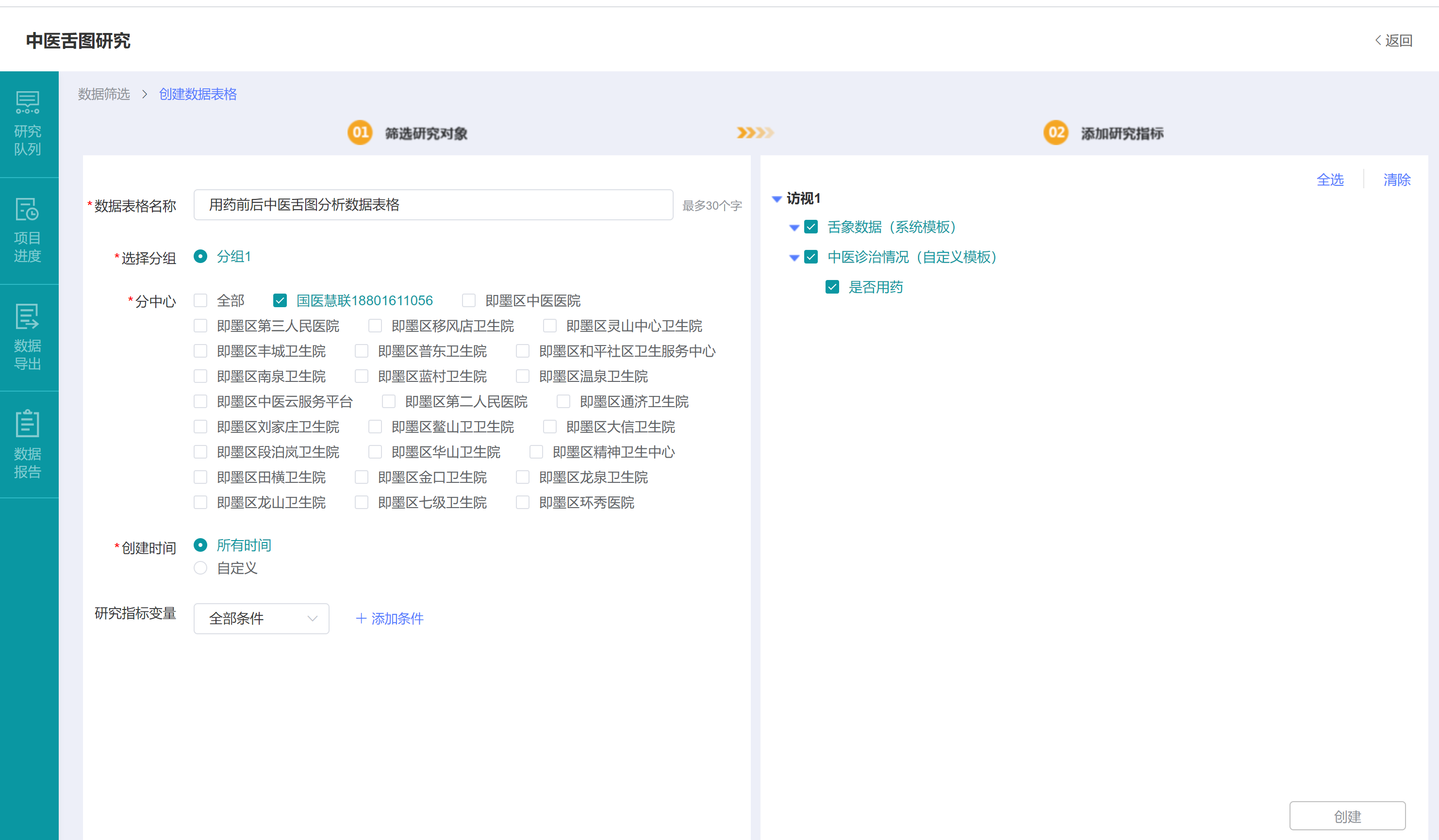
此时数据表格创建成功,并且弹出【预览数据】页面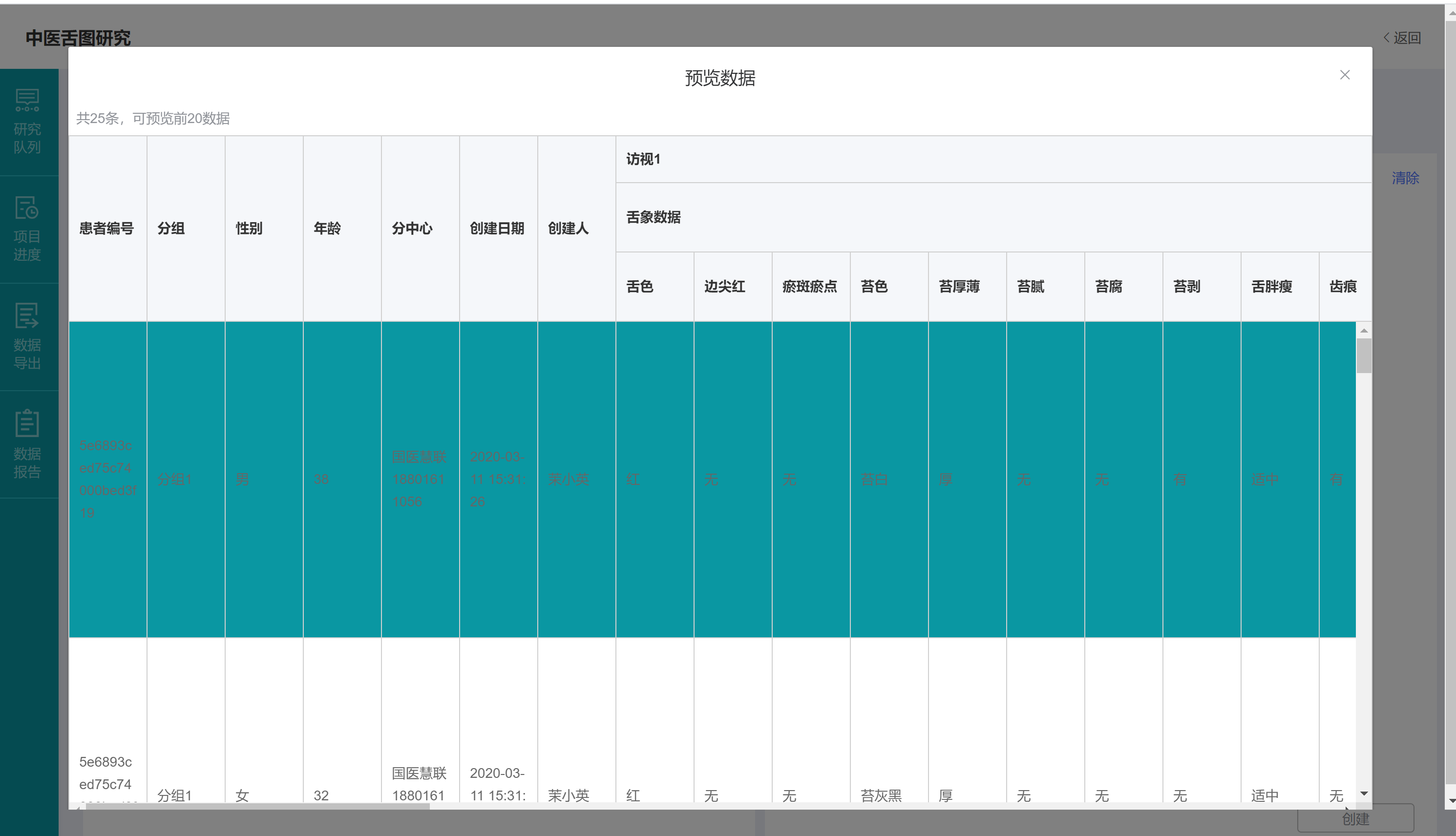
关闭【预览数据】弹出窗口,即可以看到我们新建的数据表格,并且可以点击【查看】预览数据、点击【导出】下载为EXCEL格式文件、点击【删除】删除对应数据表格。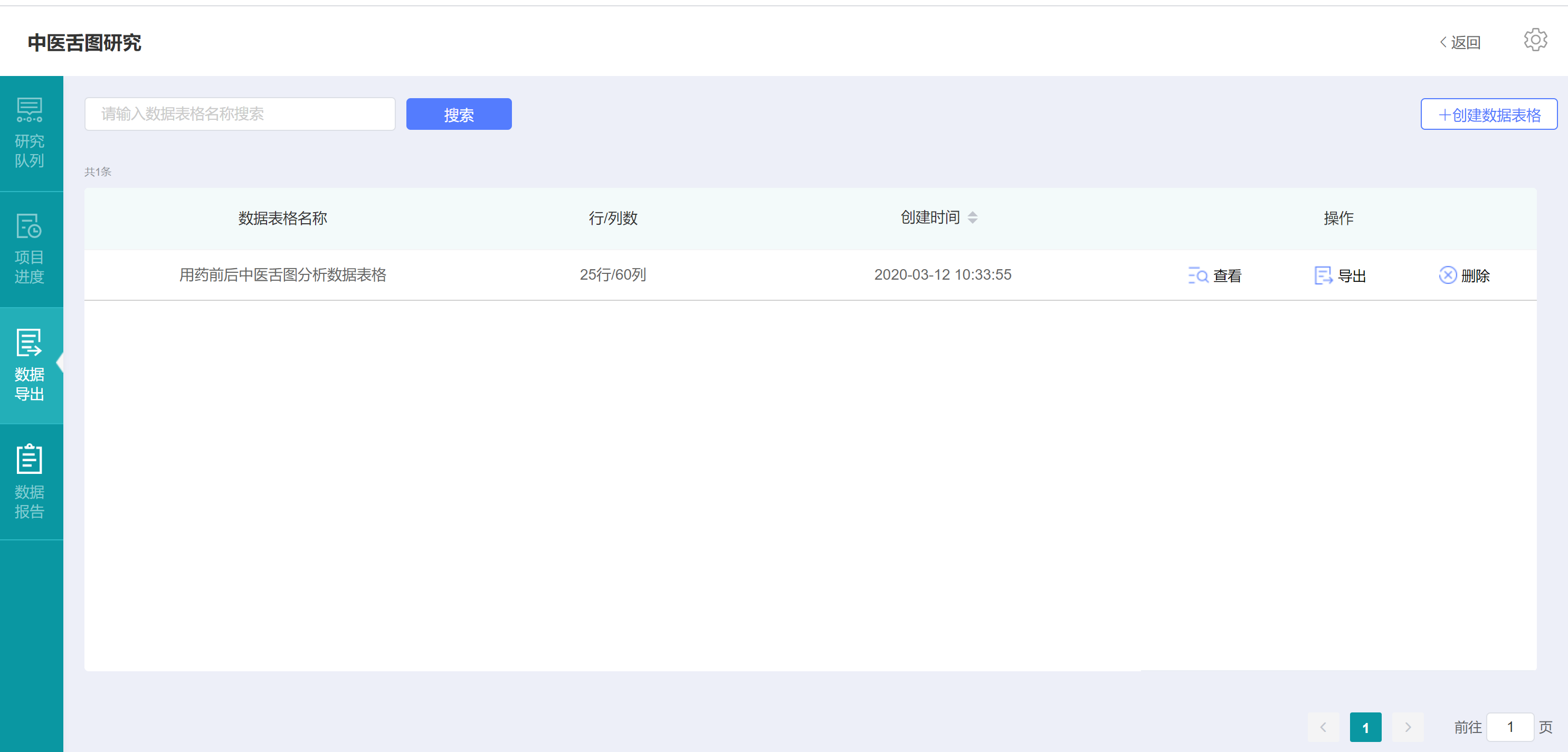
开展舌图差异分析
完成“用药前后中医舌图分析数据表格”创建后,我们现在可以基于该数据表格开展数据分析挖掘了。
视频教程

图文教程
返回主界面,点击头部主菜单栏中的【分析挖掘】,进入到【分析挖掘】界面,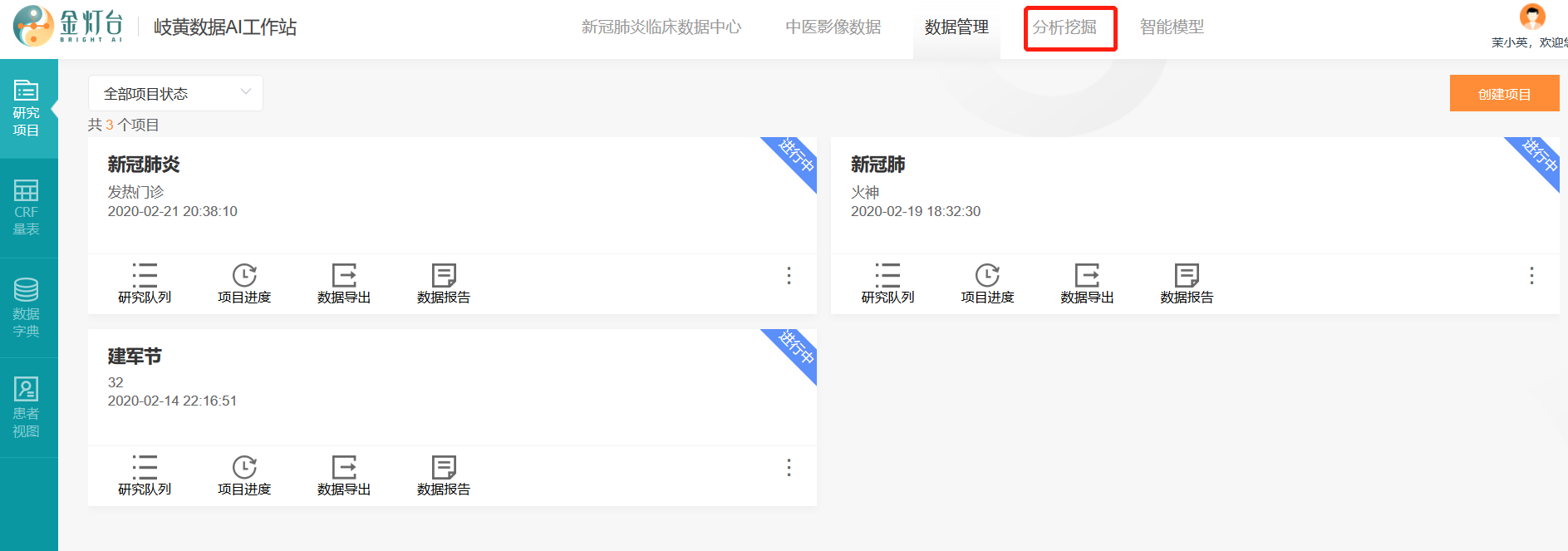
使用【自定义分析】功能,选择项目和数据为之前创建的“新冠肺炎中医舌图研究”和“用药前后中医舌图分析数据表格”,选择统计分析方法为“差异性分析”,因为我们的样本未配对,所以选择分析指标为“独立样本”
接下来我们点击【分组变量】选择框,选择分组变量为“是否用药”,点击【分析变量】选择框,在弹出的舌图特征列表中任意选择想要分析的舌图变量,例如我们选择“苔色”变量,再选择校验水准为“0.05”,点击【开始分析】按钮,右侧即显示“用药”和“未用药”两类人群的苔色差异性分析报告。
- 报告首先显示【变量设置】,包括分组变量、分析变量、检验水准。
- 接下来显示【分析方法】,因为苔色是多分类离散变量,工作站智能选择并调用国际学术期刊认可且推荐的【R语言RxC卡方检验统计方法】进行差异性分析。并且工作站智能剔除了苔色判读情况为空的缺失样本。
- 接下来显示【结果解释】,包括3个表,第1个表是【差异性分析总表】,显示本次差异性分析的总体情况,包括“用药”分组和“未用药”分组的有效样本总数、苔白样本数、苔无样本数等,并且显示“用药”分组和“未用药”分组的苔色整体差异性P值为0,小于0.05,因此两分组有显著差异。
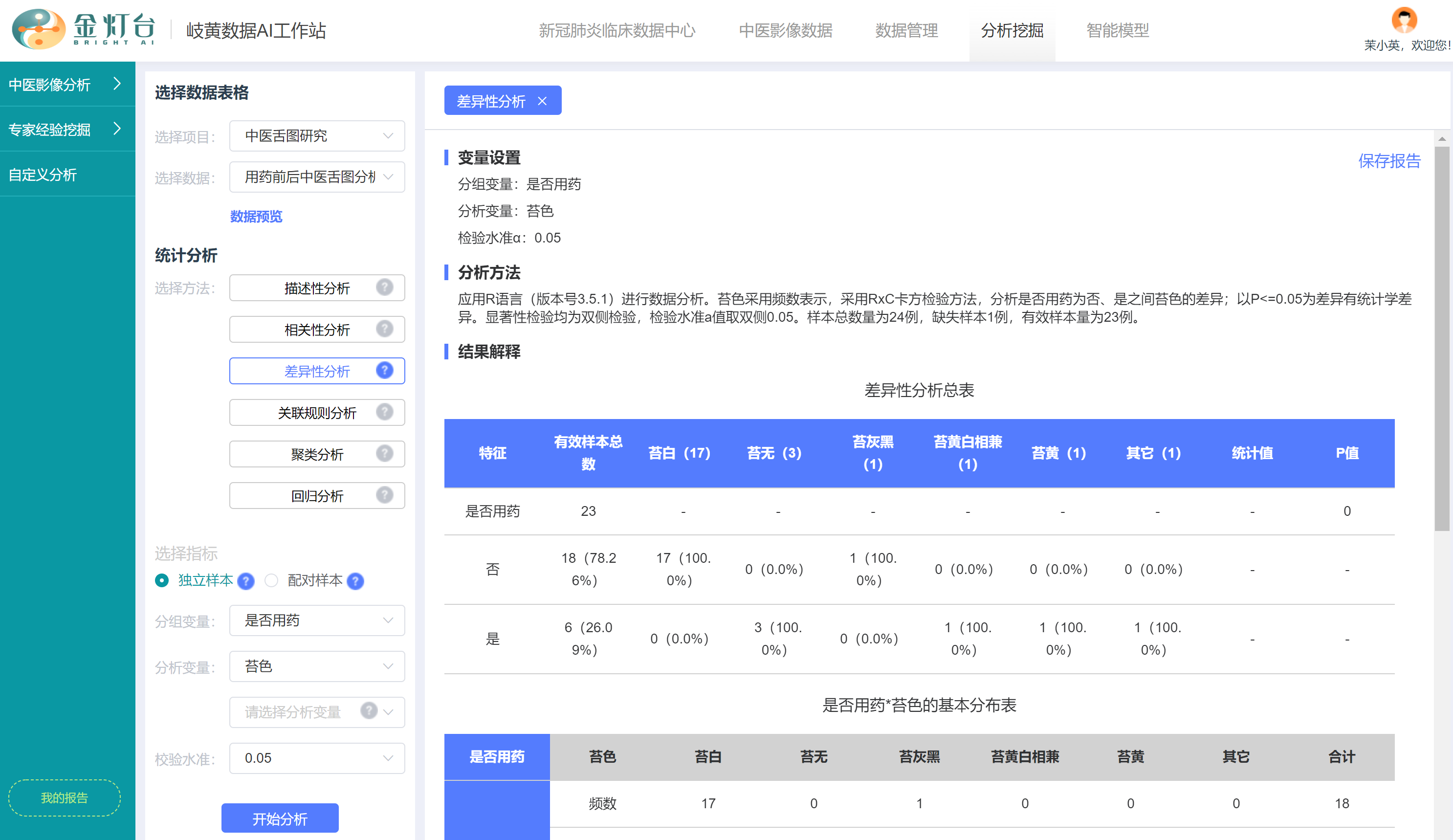
向下滚动鼠标查看更多报告信息
- 【结果解释】的第2个表是【基本分布表】,更详细的显示了“用药”分组和“未用药”分组的苔色分布情况,包括频数、行占比、列占比等
- 【结果解释】的第3个表是【组间比较表】,更详细的显示了所使用的假设检验统计方法,工作站智能根据数据分布情况,选择【Pearson卡方检验】而不是【Fisher确切概率法】进行了分析,并显示更详细的检验结果,包括统计量为卡方值,卡方值为23,自由度为4,P值为0,有统计学差异
- 最后,分析报告显示了简要的分析【结论】,运用Pearson卡方检验分析结果显示,P=0。在α=0.05水平上拒绝H0,不同“是否用药”之间苔色有统计学差异
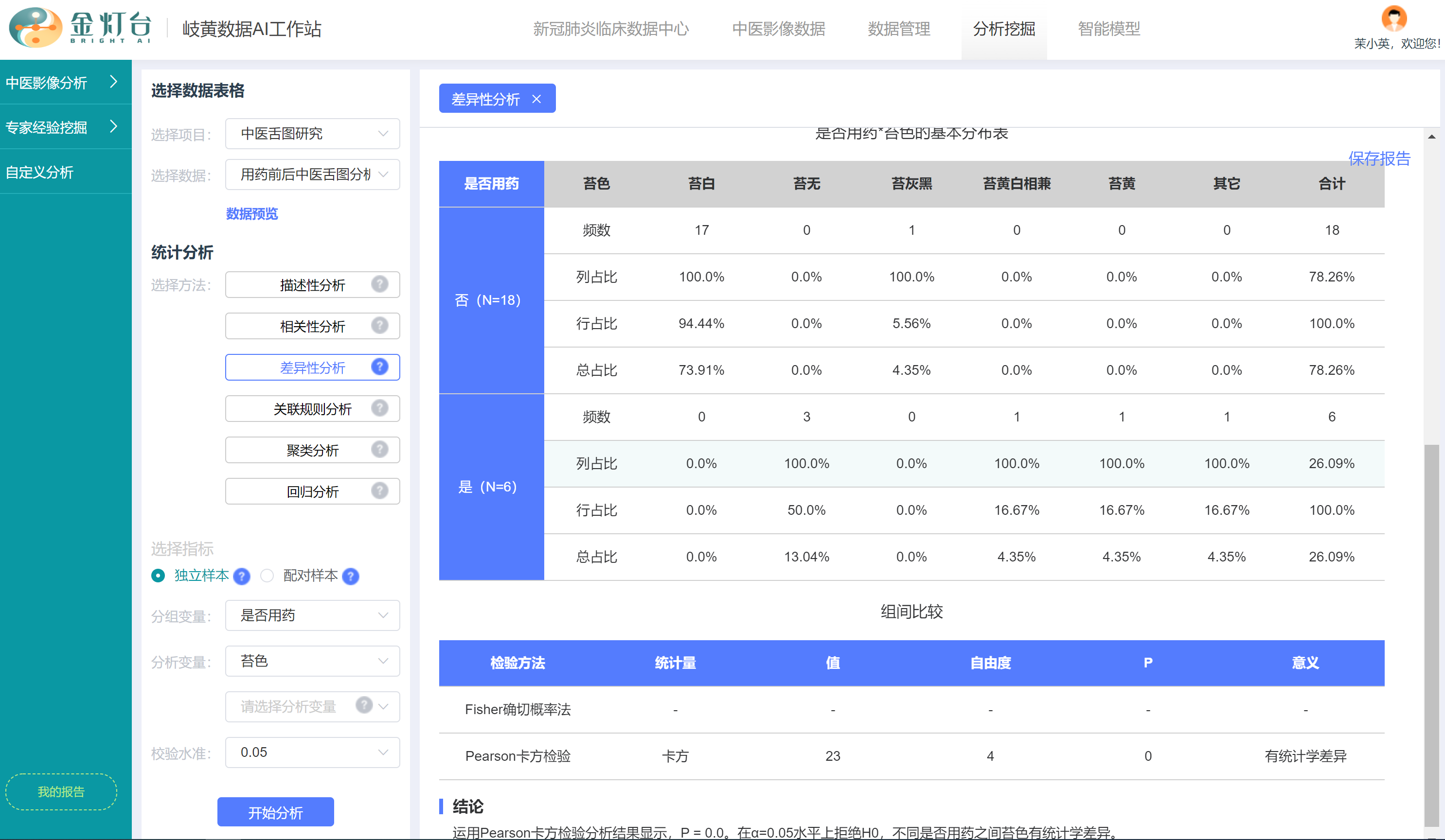
对于类似苔色的多分类离散变量,工作站还提供【子变量分析功能】,即在【分析变量】选择框中选择了“苔色”之后,可以看到下方出现了新的【子分析变量】选择框,我们可以选择苔色多个分类变量值中的其中1个,针对性地进行二分类差异性分析,例如我们选择“苔白”变量,即可分析“用药”和“未用药”两组舌图“苔白”和“非苔白”情况的差异性,报告详情说明如前述“苔色”的差异性分析报告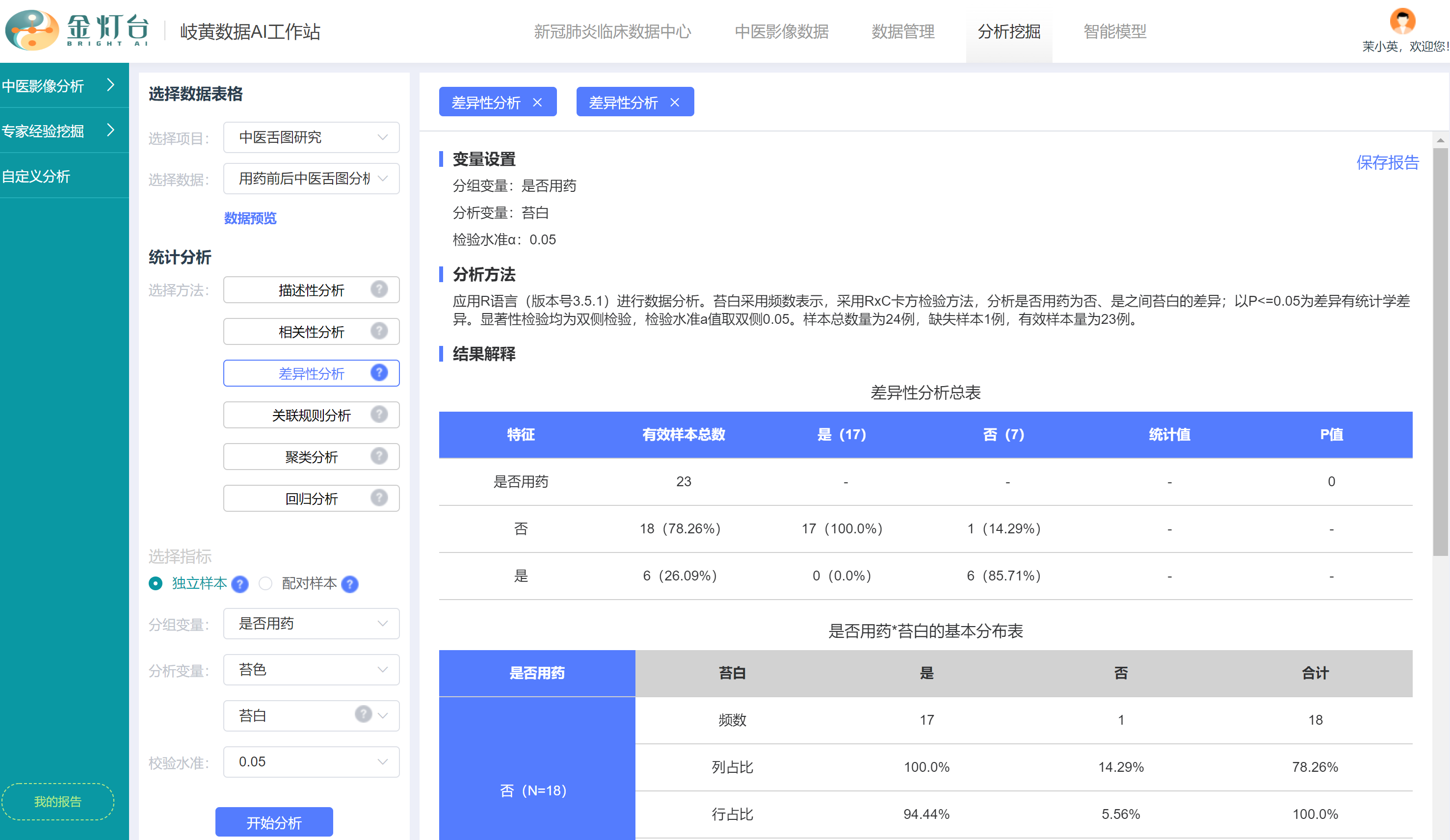
除了对舌图的专家定性判读进行分析,工作站还支持对舌图客观定量参数进行分析。在【分析变量】选择框中下拉,找到舌色或苔色的Lab参数,例如我们可以选择“全舌Lab-L”,然后点击开始分析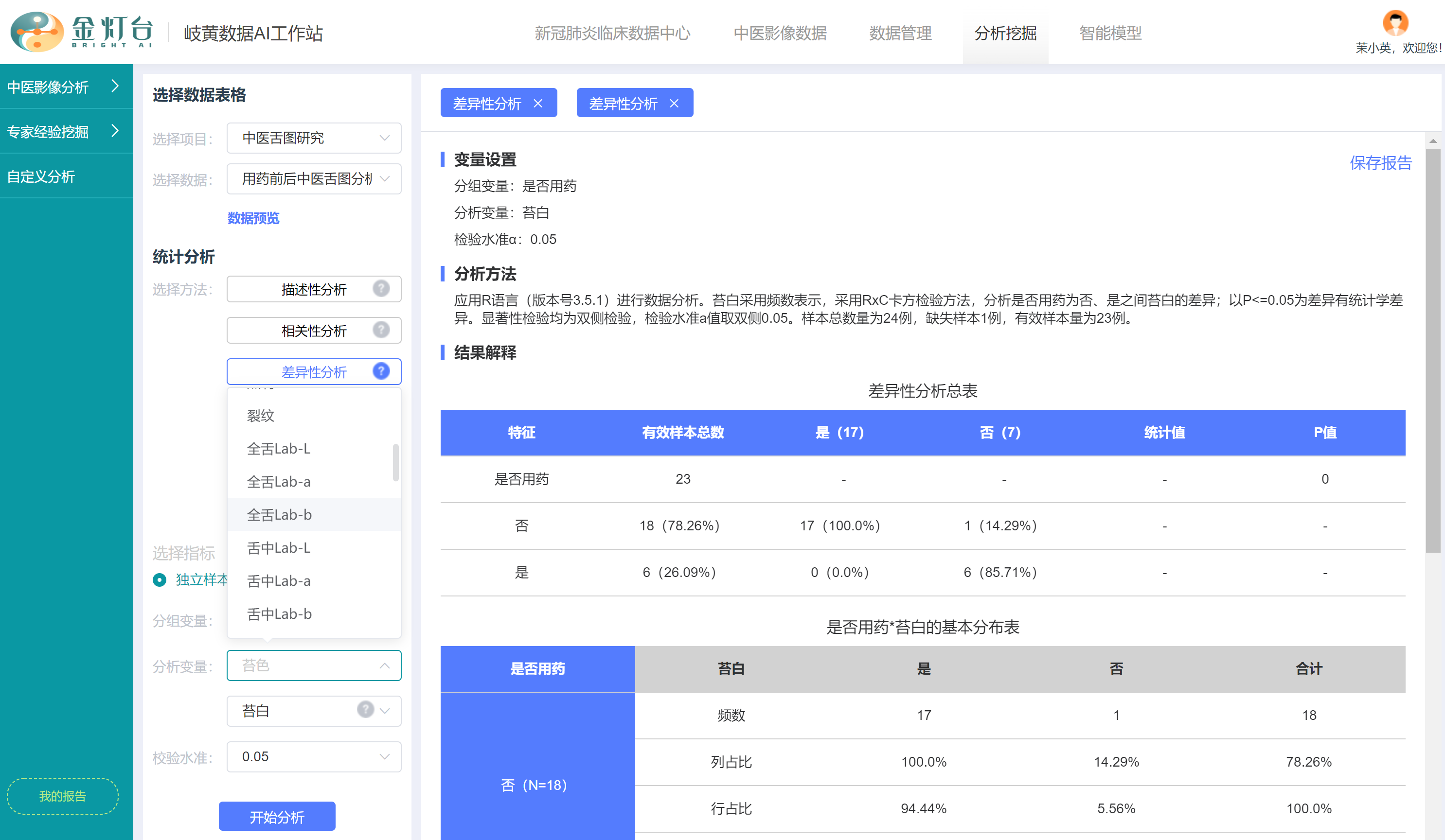
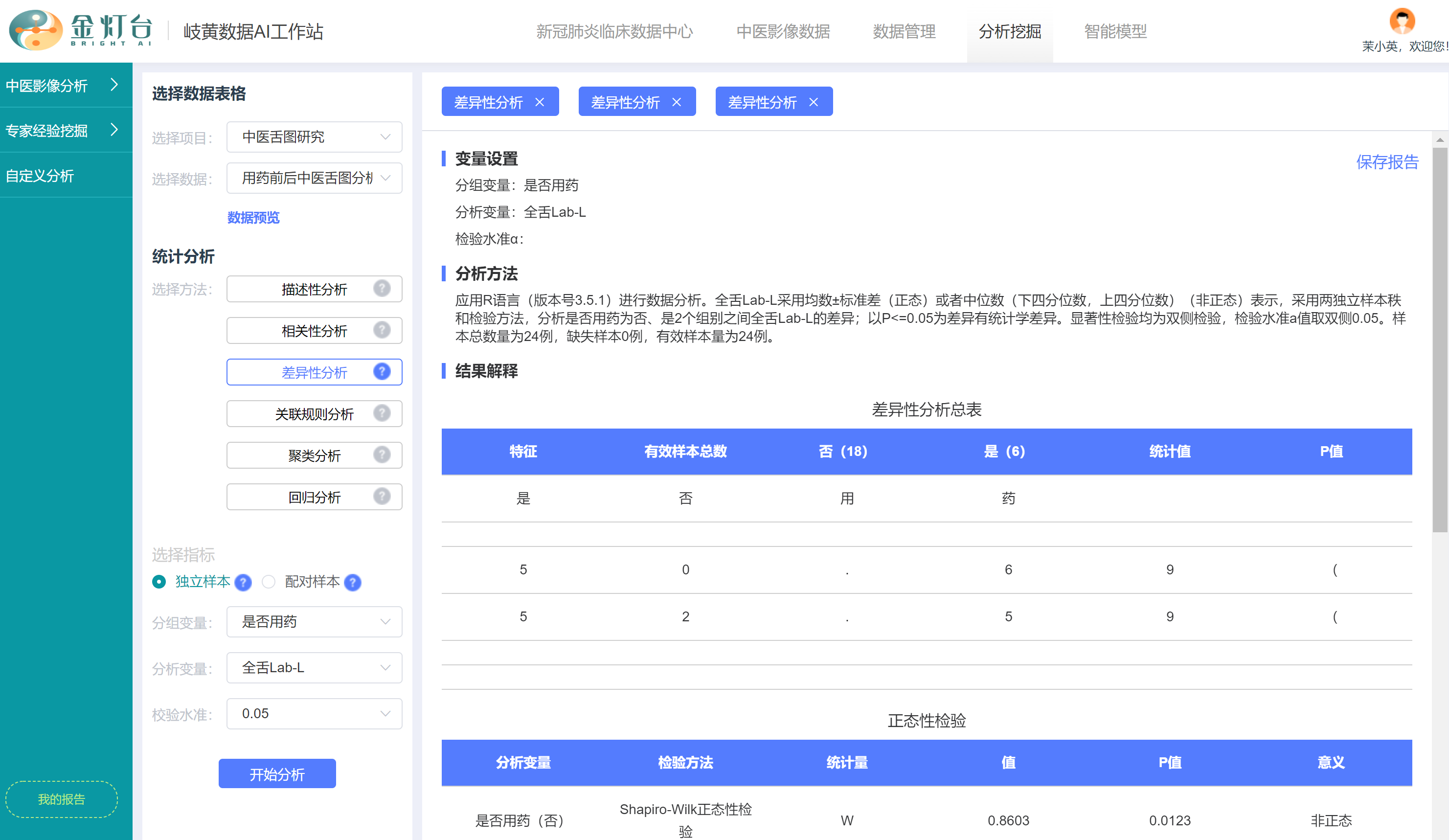
右侧即显示“用药”和“未用药”两类人群的“全舌Lab-L”差异性分析报告。
- 报告首先显示【变量设置】,包括分组变量、分析变量、检验水准。
- 接下来显示【分析方法】,因为“全舌Lab-L”是连续变量且不符合正态分布,工作站智能选择并调用国际学术期刊认可且推荐的【R语言两独立样本秩和检验方法】进行差异性分析。
- 接下来显示【结果解释】,包括4个表,第1个表是【差异性分析总表】,显示本次差异性分析的总体情况。
向下滚动鼠标查看更多报告信息
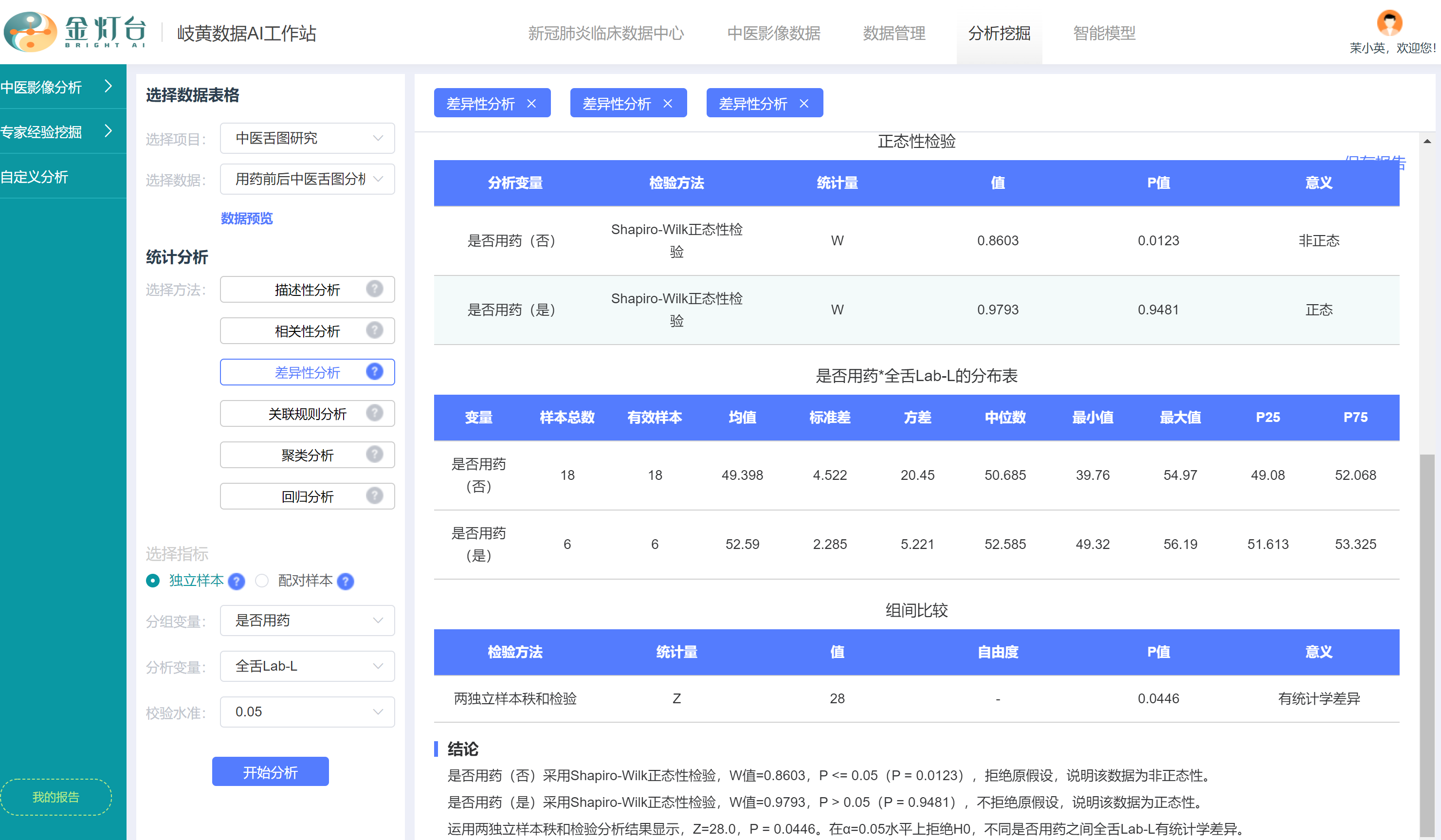
- 【结果解释】的第2个表是【正态性检验】,更详细的显示了“用药”和“未用药”分组“全舌Lab-L”参数的正态性检验结果,发现“未用药”分组符合正态分布,而“用药”分组不符合正态分布,两组没有都满足正态性,客观说明了工作站智能选择秩和检验统计方法而不是T检验统计方法的正确性
- 【结果解释】的第3个表是【分布表】,更详细的显示了“用药”和“未用药”分组的“全舌Lab-L”参数分布情况,包括均值、方差、中位数等
- 【结果解释】的第4个表是【组间比较】,更详细的显示了所使用的假设检验统计方法,工作站根据数据分布情况,智能地选择【两独立样本秩和检验】而不是【T检验】进行了分析,并显示更详细的检验结果,包括统计量为Z值,Z值为28,自由度为4,P值为0.0446,有统计学差异
- 最后,分析报告显示了简要的分析【结论】,P=0.0446。在α=0.05水平上拒绝H0,不同是否用药分组之间“全舌Lab-L”参数具有统计学差异

若有收获,就点个赞吧
0 人点赞
