Redis单机
安装C语言的编译环境
yum install centos-release-scl scl-utils-buildyum install -y devtoolset-8-toolchainscl enable devtoolset-8 bash--测试 gcc版本gcc --version

--上传redis安装包到optmulu--解压tar -zxvf redis-6.2.1.tar.gz--解压完成后进入解压后的目录,执行make命令,这里make只是编译cd redis-6.2.1makemake install--安装目录:/usr/local/bin

- redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何
- redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
- redis-check-dump:修复有问题的dump.rdb文件
- redis-sentinel:Redis集群使用
- redis-server:Redis服务器启动命令
- redis-cli:客户端,操作入口
启动
后台启动:
--copy redis.conf 到其他目录mkdir redis6379mv redis.conf /usr/local/soft/redis6379/cd /usr/local/binredis-server /usr/local/soft/redis6379/redis.confps -ef | grep redis

--客户端放完redis-cli--多端口访问redis-cli -p 6379
Redis集群
Redis集群模式
1、主从模式
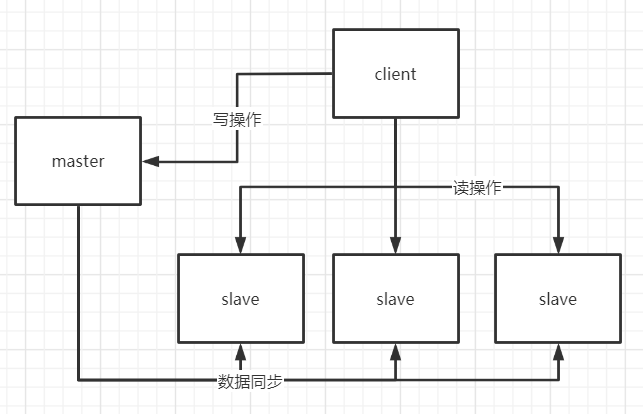
在主从复制中,数据库分为两类:主数据库(master)和从数据库(slave)。主要有以下特点:
* 主数据库可进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库* 从数据库是只读的,并且接收主数据库同步过来的数据* 一个master可以拥有多个slave,但是一个slave只能对应一个master* slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来* master挂了以后,不影响slave的读,但redis不再提供写服务,master重启后redis将重新对外提供写服务* master挂了以后,不会在slave节点中重新选一个master
工作机制
1、当slave启动后,主动向master发送SYNC命令;
2、master接收到SYNC命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令;
3、然后将保存的快照文件和缓存的命令发送给slave。
4、slave接收到快照文件和命令后加载快照文件和缓存的执行命令。
5、复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。
主从模式搭建
--将redis.conf 复制三份cp redis6379.conf redis6380.confcp redis6379.conf redis6381.conf--修改配置文件内容bind 127.0.0.1 #监听ip,多个ip用空格分隔daemonize yes #允许后台启动logfile "/usr/local/redis/redis.log" #日志路径dir /data/redis #数据库备份文件存放目录masterauth 123456 #slave连接master密码,master可省略requirepass 123456 #设置master连接密码,slave可省略replicaof 127.0.0.1 6379 # 从机配置,监听主机ip 和 端口appendonly yes #在/data/redis/目录生成appendonly.aof文件,将每一次写操作请求都追加到appendonly.aof 文件中--启动后查看集群状态redis-cli -h 127.0.0.1 -a 123456127.0.0.1:6379> info replication# Replicationrole:masterconnected_slaves:2slave0:ip=127.0.0.1,port=6380,state=online,offset=70,lag=0slave1:ip=127.0.0.1,port=6381,state=online,offset=70,lag=1master_failover_state:no-failovermaster_replid:c6a34fd1a770d28fb7fb72310244927da2855900master_replid2:0000000000000000000000000000000000000000master_repl_offset:70second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:70
2、哨兵(sentinel)模式
主从模式的弊端就是不具备高可用性,当master挂掉以后,Redis将不能再对外提供写入操作,因此sentinel应运而生。
sentinel中文含义为哨兵,顾名思义,它的作用就是监控redis集群的运行状况,特点如下:
* sentinel模式是建立在主从模式的基础上,如果只有一个Redis节点,sentinel就没有任何意义* 当master挂了以后,sentinel会在slave中选择一个做为master,并修改它们的配置文件,其他slave的配置文件也会被修改,比如slaveof属性会指向新的master* 当master重新启动后,它将不再是master而是做为slave接收新的master的同步数据* sentinel因为也是一个进程有挂掉的可能,所以sentinel也会启动多个形成一个sentinel集群* 多sentinel配置的时候,sentinel之间也会自动监控* 当主从模式配置密码时,sentinel也会同步将配置信息修改到配置文件中* 一个sentinel或sentinel集群可以管理多个主从Redis,多个sentinel也可以监控同一个redis* sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了
工作机制
- 每个sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个 PING 命令
- 如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被sentinel标记为主观下线。
- 如果一个master被标记为主观下线,则正在监视这个master的所有sentinel要以每秒一次的频率确认master的确进入了主观下线状态
- 当有足够数量的sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态, 则master会被标记为客观下线
- 在一般情况下, 每个sentinel会以每 10 秒一次的频率向它已知的所有master,slave发送 INFO 命令
- 当master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送 INFO 命令的频率会从 10 秒一次改为 1 秒一次
- 若没有足够数量的sentinel同意master已经下线,master的客观下线状态就会被移除;若master重新向sentinel的 PING 命令返回有效回复,master的主观下线状态就会被移除
sentinel搭建
配置文件修改:
# sentinel.conf 文件daemonize yeslogfile "/usr/local/redis/sentinel.log"dir "/usr/local/redis/sentinel" #sentinel工作目录sentinel monitor mymaster 127.0.0。1 6379 2 #判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数sentinel auth-pass mymaster 123456sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30s# sentinel auth-pass mymaster 123456需要配置在sentinel monitor mymaster 192.168.30.128 6379 2下面,否则启动报错# 启动哨兵/usr/local/bin/redis-sentinel
3、Cluster模式
sentinel模式基本可以满足一般生产的需求,具备高可用性。但是当数据量过大到一台服务器存放不下的情况时,主从模式或sentinel模式就不能满足需求了,这个时候需要对存储的数据进行分片,将数据存储到多个Redis实例中。cluster模式的出现就是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能,所以如果配置两个副本三个分片的话,就需要六个Redis实例。因为Redis的数据是根据一定规则分配到cluster的不同机器的,当数据量过大时,可以新增机器进行扩容。使用集群,只需要将redis配置文件中的`cluster-enable`配置打开即可。每个集群中至少需要三个主数据库才能正常运行,新增节点非常方便。
cluster集群特点:
* 多个redis节点网络互联,数据共享* 所有的节点都是一主一从(也可以是一主多从),其中从不提供服务,仅作为备用* 不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为* 支持在线增加、删除节点* 客户端可以连接任何一个主节点进行读写
集群搭建
# vi /usr/local/redis/cluster/redis_7001.conf# bind 127.0.0.1port 7001daemonize yespidfile "/var/run/redis_7001.pid"logfile "/usr/local/redis/cluster/redis_7001.log"dir "/data/redis/cluster/redis_7001"masterauth 123456requirepass 123456appendonly yescluster-enabled yescluster-config-file nodes_7001.confcluster-node-timeout 15000# vi /usr/local/redis/cluster/redis_7002.conf# bind 127.0.0.1port 7002daemonize yespidfile "/var/run/redis_7002.pid"logfile "/usr/local/redis/cluster/redis_7002.log"dir "/data/redis/cluster/redis_7002"masterauth "123456"requirepass "123456"appendonly yescluster-enabled yescluster-config-file nodes_7002.confcluster-node-timeout 15000#如果redis版本比较低,则需要安装ruby。任选一台机器安装ruby即可#安装ruby并创建集群(低版本)5.0以上跳过yum -y groupinstall "Development Tools"yum install -y gdbm-devel libdb4-devel libffi-devel libyaml libyaml-devel ncurses-devel openssl-devel readline-devel tcl-develmkdir -p ~/rpmbuild/{BUILD,BUILDROOT,RPMS,SOURCES,SPECS,SRPMS}wget http://cache.ruby-lang.org/pub/ruby/2.2/ruby-2.2.3.tar.gz -P ~/rpmbuild/SOURCESwget http://raw.githubusercontent.com/tjinjin/automate-ruby-rpm/master/ruby22x.spec -P ~/rpmbuild/SPECSrpmbuild -bb ~/rpmbuild/SPECS/ruby22x.specrpm -ivh ~/rpmbuild/RPMS/x86_64/ruby-2.2.3-1.el7.x86_64.rpmgem install redis #目的是安装这个,用于配置集群cp /usr/local/redis/src/redis-trib.rb /usr/bin/redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1::7002 127.0.0.1::7003 127.0.0.1::7004 127.0.0.1::7005 127.0.0.1::7006# 创建集群redis-cli -a 123456 --cluster create 127.0.0.1::7001 127.0.0.1::7002 127.0.0.1:7003 127.0.0.1::7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383Adding replica 192.168.30.129:7004 to 127.0.0.1:7001Adding replica 192.168.30.130:7006 to 127.0.0.1:7003Adding replica 192.168.30.128:7002 to 127.0.0.1:7005M: 80c80a3f3e33872c047a8328ad579b9bea001ad8 127.0.0.1:7001slots:[0-5460] (5461 slots) masterS: b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 127.0.0.1:7002replicates 6788453ee9a8d7f72b1d45a9093838efd0e501f1M: 4d74ec66e898bf09006dac86d4928f9fad81f373 127.0.0.1:7003slots:[5461-10922] (5462 slots) masterS: b6331cbc986794237c83ed2d5c30777c1551546e 127.0.0.1:7004replicates 80c80a3f3e33872c047a8328ad579b9bea001ad8M: 6788453ee9a8d7f72b1d45a9093838efd0e501f1 127.0.0.1:7005slots:[10923-16383] (5461 slots) masterS: 277daeb8660d5273b7c3e05c263f861ed5f17b92 127.0.0.1:7006replicates 4d74ec66e898bf09006dac86d4928f9fad81f373Can I set the above configuration? (type 'yes' to accept): yes #输入yes,接受上面配置>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the cluster#可以看到127.0.0.1:7001是master,它的slave是127.0.0.1:7004;127.0.0.1:7003是master,它的slave是127.0.0.1:7006;127.0.0.1:7005是master,它的slave是127.0.0.1:7002#登录集群redis-cli -c -h 127.0.0.1 -p 7001 -a 123456 # -c,使用集群方式登录#查看集群信息127.0.0.1:7001> CLUSTER INFO #集群状态cluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6cluster_size:3cluster_current_epoch:6cluster_my_epoch:1cluster_stats_messages_ping_sent:580cluster_stats_messages_pong_sent:551cluster_stats_messages_sent:1131cluster_stats_messages_ping_received:546cluster_stats_messages_pong_received:580cluster_stats_messages_meet_received:5cluster_stats_messages_received:1131#列出节点信息127.0.0.1:7001> CLUSTER NODES #列出节点信息6788453ee9a8d7f72b1d45a9093838efd0e501f1 127.0.0.1:7005@17005 master - 0 1557455176000 5 connected 10923-16383277daeb8660d5273b7c3e05c263f861ed5f17b92 127.0.0.1:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557455174000 6 connectedb4d3eb411a7355d4767c6c23b4df69fa183ef8bc 127.0.0.1:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557455175000 5 connected80c80a3f3e33872c047a8328ad579b9bea001ad8 127.0.0.1:7001@17001 myself,master - 0 1557455175000 1 connected 0-5460b6331cbc986794237c83ed2d5c30777c1551546e 127.0.0.1:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557455174989 4 connected4d74ec66e898bf09006dac86d4928f9fad81f373 127.0.0.1:7003@17003 master - 0 1557455175995 3 connected 5461-10922
数据分区原理
在Redis集群中采用的使虚拟槽分区算法,会把redis集群分成16384 个槽(0 -16383)。
比如:下图所示三个master,会把0 -16383范围的槽可能分成三部分(0-5000)、(5001-11000)、(11001-16383)分别数据三个缓存节点的槽范围。
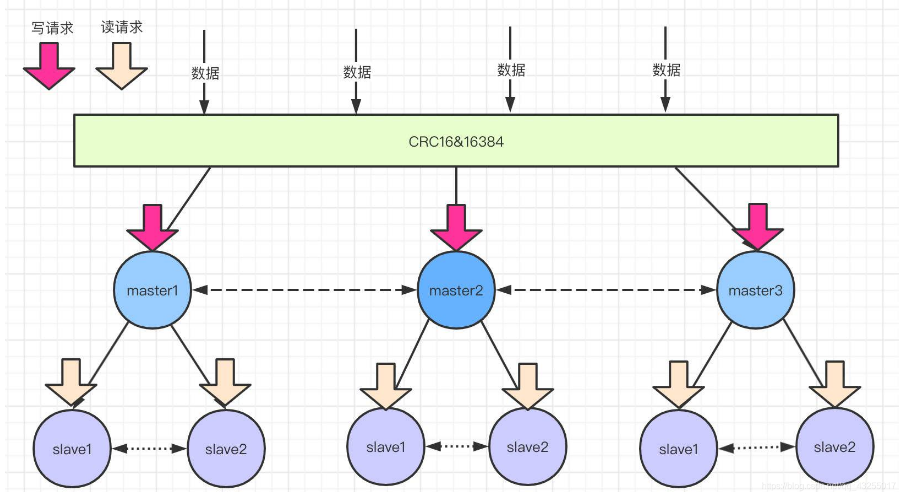
当客户端请求过来,会首先通过对key进行CRC16 校验并对 16384 取模(CRC16(key)%16383)计算出key所在的槽,然后再到对应的槽上进行取数据或者存数据,这样就实现了数据的访问更新。
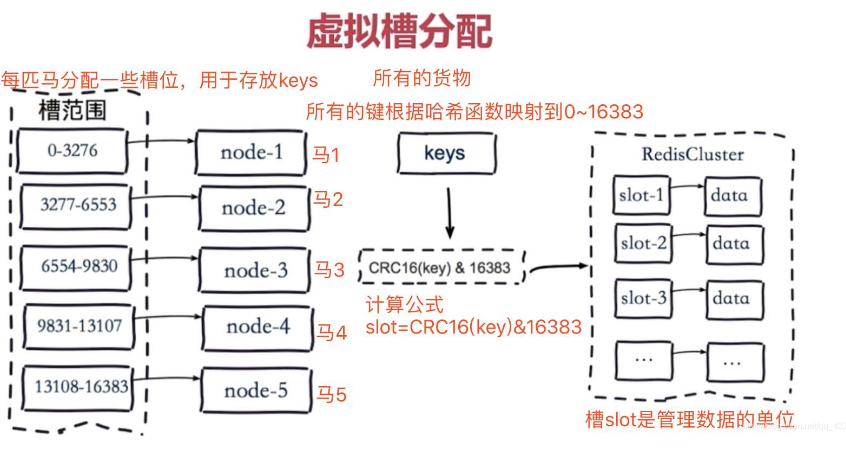
之所以进行分槽存储,是将一整堆的数据进行分片,防止单台的redis数据量过大,影响性能的问题。

若有收获,就点个赞吧
0 人点赞
