错误模型
Midori 是用 AOT 编译的,基于 C# 的类型安全语言写的。除了我们的微内核,整个系统都是用它写的,包括驱动,域核心以及所有的用户代码。之前我提及了一些东西,现在是时候面对它们了。这个语言覆盖非常广泛的东西,需要用上一系列的文章。那么从哪里开始呢?错误模型。传播以及处理错误的方式对任何语言来说都是至关重要的,特别是能用于编写可靠的操作系统的语言。像我们在 Midori 做的其他事情一样,一个“整系统”的方法是必须的,花了好几年来进行了好几次迭代,以可以保证它的正确性。我经常听到团队成员说,这是他们在编程方面最想念 Midori 的东西。对我来说,也是如此。所以,闲话少说,让我们开始吧。
介绍
错误模型要回答的基本问题是:“错误”是如何传递给程序员和系统用户的?这不是很简单吗?哦,那只是看着简单。
要回答这个问题的最大挑战之一是定义错误到底是什么。大多数语言将 bug 和可以恢复的错误归到同一类,并使用相同的措施去处理它们。把解 null 引用和数组越界访问,同网络连接问题或者解析错误一样对待。这种一致性咋一看还很不错,不过它有根深蒂固的问题。特别需要提的是,这具有误导性,会经常导致不可靠的代码。
我们的整体解决方案是提供一种双管齐下的错误模型。一方面,对于程序的 bug,你有 fail-fast —— 我们称它为丢弃(abandonment)。另一方面,对于可恢复的错误,你有静态的 checked 异常。这两种是截然不同的,这些不同表现在编程模型,也表现在他们背后的机制。丢弃瞬间就销毁了整个进程,并拒绝执行之后的任何用户代码。(别忘了,典型的 Midori 程序有相当多的细小的轻量级的进程。)对于异常,当然了,它可以被恢复,但需要深入的类型系统支持,来帮助检查和验证。
这段旅程是漫长曲折的。我会把这个故事分为六块:
- 雄心和教训
- Bug 不是可恢复的错误!
- 可靠性,容错性和隔离
- Bugs:丢弃、断言和约定
- 可恢复的错误:类型定向的(Type-Directed)异常
- 回顾和结论
事后看来,某些成果似乎很显而易见。特别现在有了现代的系统语言像 Go 和 Rust 作为对比之后。但有些成果让我们也感到惊讶。我也想尽可能切题,不过在介绍的过程中,我同时也会给出足够的背景故事。我们对多种东西的尝试,虽然很多都无法工作,我认为这些比在尘埃落定时我们得到的结果更有趣。
雄心和教训
让我们从检查我们的架构原则、需求以及从已存在的系统学到的东西开始。
原则
在我们着手这段旅程时,我们提出了一个很好的错误模型需要满足的几个需求:
可用性(Usable)。面对错误,开发人员一定要很容易做出“正确”的事情,就好像不经意的一样。一个著名的同事和朋友称之为成功之坑。该模式不应该给编写常见的代码强加过多的拘束。理想情况下,它是我们目标受众认知上熟悉的。
可靠性(Reliable)。错误模型是整个系统可靠性的基础。毕竟我们正在建造一个操作系统,所以可靠性是最重要的。你甚至可能职责我们痴迷于追求极端的可靠性。我们指导大多数编程模型开发的真言是“通过构建获得正确性”。
高性能(Performant)。通常的情况需要极致的快。这意味着成功路径的开销尽可能接近零。任何失败路径上的开销必须是“pay-for-play”的。不像很多现代系统会过多惩罚错误路径,我们有几个性能关键的组件,这样是不可接受的,所以错误也必须相当的快。
并发(Concurrent)。我们的整个系统是分布式而且高并发的。这关注点通常在其他错误模型的考量点是比较靠后,而在我们系统中是必须靠前而且是中心的。
可诊断性(Diagnosable)。调试错误,无论在交互中还是事后,都需要高效而且容易。
可组合(Composable)。本质上,错误模型是编程语言的一个特性,是开发人员用表达代码的核心。因此,它应当提供与系统的其他特性的正交性和可组合性。集成分别编写的组件必须是自然的,可靠的和可预测的。
这是一个大胆的宣称,然而我的确认为我们在所有的维度都取得了成功。
经验教训
现有的错误模型不满足以上需求,至少不完全满足。若其中一个在一个维度做得好,在另一个维度就做得差。举个例子,错误码有很好的可靠性,但很多程序员发现他们很容易误用;更差的是,它很容易就做了错事 —— 像忘记检查它 —— 这当然违反了“成功之坑”的需求。
鉴于我们寻求的可靠性的极限程度,我们对大多数模型不满意也就没什么好奇怪的了。
如果你正在优化易用性相对于可靠性,就像在脚本语言中一样,你的结论会有显著的不同。像 Java 和 C# 努力竞争是因为它们就正好在各种场景十字路口中间 —— 有时候被用来做系统开发,有时候被用来做应用开发 —— 但总的上它们的错误模型非常不适合我们的需求。
最后还要提一下,这个故事开始于 2000 年代中期,在 Go、Rust 和 Swift 可供我们参考之前。这三种语言从那之后在错误模型方面做一些很不错的工作。
错误码
错误码可以说是最简单的错误模型。想法是非常基本的,甚至不需要语言或 runtime 的支持。函数只是返回一个值,通常是一个整数,表示成功或者失败。
int foo() {// <try something here>if (failed) {return 1;}return 0;}
这就是典型的模式,返回一个 0 表示成功,非 0 表示失败。调用者必须检查它:
int err = foo();if (err) {// Error! Deal with it.}
大多数系统提供错误码的常量集合,而不是 magic number。可能有也可能没有一个函数你可以用来获得关于最近一个错误的额外信息(像标准 C 里的 errno 和 Win32 的 GetLastError)。一个返回码真的不是语言里什么特别的东西 —— 它只是一个返回值。
C 长期使用错误码,因此,大多数基于 C 的生态系统都这样做。更多低层的系统代码已经写成了使用返回码的规则而不是其他。Linux 是这样,其他的无数的关键任务和实时系统也是这样。所以,可以很公平地说它们有一个令人印象深刻的记录。
在 Windows 上,HRESULT 是一样的。一个 HRESULT 只是一个整数的“handle”,而且在 winerror.h 中有一大串的常量和宏,例如 S_OK,E_Fault,和用来生成和检查值的SUCCEEDED()。Windows 里最重要的代码是用返回码的规则写出来的。在内核中找不到异常。至少也不是故意地使用异常。
在手动管理内存的环境中,在出现错误时释放内存是非常困难的。返回码可以让这点好受点。C++ 使用 RAII 有更多的自动化方法来处理这个,但除非你坚决贯彻 C++ 模型 —— 很多系统程序员都不会这么做 —— 那么没有很好的办法可以在 C 程序中增量使用 RAII。
最近,Go 选择了错误码。虽然 Go 的方法类似 C 的,它通过好得多的语法和库变得更加现代化。
许多函数式语言通过伪装成 monad 的方式使用返回码,称之为 Option<T>、Maybe<T> 或 Error<T>,这些与数据流风格的编程及模式匹配一起使用时,感觉更加自然。这种方法消除了返回码的一些主要缺点,尤其是与 C 相比,我们将在下文继续讨论。Rust 很大程度上采用了这个模型,但对系统程序员来说还有一些令人兴奋的东西。
尽管它们非常简单,返回码的确也有些包袱;总结如下:
- 性能会受到影响
- 编程模型可用性会变差
- 最重要的是:你会意外地忘记检查错误。
让我们讨论每一个,按照顺序来,并基于上述的语言提供一些例子。
性能
错误码在通常情况下“零开销”,只为不通常的情况付出代价的测试中落败。
- 存在调用协定的影响。你现在有了两个值需要返回(对于不是返回
void的函数):实际的返回值和可能的错误。这烧掉了更多的寄存器和/或栈空间,使调用效率更低。对于可以内联的调用子集来说,内联对改善这个有帮助。 - 在被调用者有可能失败的地方在 callsite 中都有分支注入。我称类似这种的开销为“花生酱”,因为那些检查在代码中抹得到处都是,使得很难测量直接的影响。在 Midori 中,我们能够做实验并测量,并可以确认,这种成本是不可忽视的。还有一个次要的影响,因为函数包含了多个分支,有更多的扰乱优化器的风险。
这可能令某些人觉得惊奇,因为无疑每个人都听说过“异常很慢”。事实证明,它们不是一定会这样。并且,如果能做对的话,它们让错误处理代码和数据从热路径(hot path)中移出去,这增加了 I-cache 和 TLB 的性能,对比上述的开销,那显然减慢了它们。
许多高性能系统已经使用返回码来构建,所以你可能会认为我很挑剔。正如我们做的很多事情一样,一个简单的批评是我们做的方法太极端了。但包袱会更差。
忘记检查它们
很容易就忘记检查一个返回码。例如,考虑一个函数:
int foo() { ... }
现在在调用点,要是我们静静地忽略了返回值,就这样继续,会发生什么呢?
foo();// Keep going -- but foo might have failed!
在这里,你已经在程序中掩盖了潜在的关键错误。这是使用错误码很容易出现的最棘手有害的问题。选项类型(option type)能帮助函数式语言解决这个问题。但对于基于 C 的语言,甚至对于使用现代语法的 Go,这是真正的问题。
这问题不只是理论上可能存在。我遇到过无数由于忽略返回码造成的错误,我敢肯定你也遇到过。事实上,正在开发这个错误模型时,我的团队遇到了些让人困惑的错误。例如,当我们将微软的语音服务移植到 Midori 时,我们发现 80% 的繁体中文(zh-tw)请求失败了。不是以一种开发人员立刻能看到的方式失败,而是,客户端会得到一个乱码响应。一开始,我们以为是我们的错,但然后我们发现了原始代码中的一处默默地吞下了 HRESULT。当我们将它挪到 Midori,bug 就被扔到了我们脸上,被找出来并立刻被改好。这段经历当然肯定了我们对于错误码的看法。
令我惊奇的是 Go 将没使用的 import 作为一个错误,却忽视了这个远远更重要的问题。太可惜了!
你的确可以加入一个静态分析检查器,或者也许一个“未使用的返回值”警告,就像大多数商用的 C++ 编译器一样。但一旦你错过将它作为需求加入到语言核心的机会,所有的这些技术没有一个能触及关键的东西,因为对有噪音的分析的抱怨。
无论如何,在我们的语言中,忘记使用返回值是一个编译时错误。你必须要显式忽略它们;一开始我们使用一个 API 来这样做,但最终设计了一个语言语法 —— 跟 >/dev/null 这些一样:
ignore foo();
我们没有使用错误码,然而必须处理返回值的能力对系统的整体可靠性是至关重要的。有多少次你调试系统时会发现,问题的根本原因在于你忘记了使用一个返回值?甚至一些安全漏洞是因为这样造成的。让开发人员显式标记“忽略”返回值也没办法完全避免问题,毕竟他们还是可以做其他错事,但至少它是显式的和可审计的。
编程模型可用性
在用错误码的基于 C 的语言中,你最终不得不在每个调用之后手写很多 if 检查。如果有很多函数可能失败,这就会非常乏味,在 C 程序中,分配失败也是用的返回码,所以可能频繁会失败。返回多个值也是很笨拙的。
警告:这个抱怨是很主观的。在很多方面,返回码的可用性实际上是很优雅的。你重用非常简单的基元 —— 整数、返回和 if 分支 —— 在无数其他情况下也会使用。在我粗鄙的想法中,错误是编程中一个足够重要的概念,语言应当要对你提供帮助。
Go 有一个很好的快捷语法让标准的返回码检查略微更令人愉快点:
if err := foo(); err != nil {// Deal with the error.}
要注意到我们调用了 foo 并检查是否 error 是非 nil 的,在一行代码中。相当整洁。
可用性问题不止于此,然而。
通常,给定的函数中的很多错误会共享一些相同的错误恢复以及修复逻辑。很多 C 程序员使用 label 和 goto 语句来描述这种结构,例如:
int error;// ...error = step1();if (error) {goto Error;}// ...error = step2();if (error) {goto Error;}// ...// Normal function exit.return 0;// ...Error:// Do something about `error`.return error;
不用说,这样的代码只有你妈才会喜欢。
在像 D、C# 和 Java 中,你有 finally 块来更加直接地编码这种“离开范围之前”模式。类似地,微软对 C++ 的自有扩展提供了 __finally,甚至当你还没有全面进入 RAII 和异常就可以使用。而 D 提供了 scope 以及 Go 提供了 defer。所有的这些根除了 goto Error 模式。
下一步,设想我的函数想要返回一个真正的(real)值以及一个错误的可能性?我们已经烧制好了返回槽(return slot)所以有两种显然的可能做法:
- 我们可以用返回槽容纳两者之一(通常是错误码),用另一个槽 —— 比如指针参数 —— 来容纳另一个值(通常是真正的值)。这是 C 语言中的常用做法。
- 我们可以返回一个结构,结构中容纳了两者。正如我们将看到的,这在函数式语言中是很常见的。但在类似 C 的语言,或甚至在 Go 中,这些缺乏参数的多态性的语言中,你会丢失关于返回值的类型信息,所以这就很少见到了。当然,C++ 加入了 template,所以理论上它可以这样干,然而它也加入了异常,所以围绕返回码的生态系统是缺乏的。
为了支持上述的性能要求,想象一下你程序用这两种方法生成的汇编代码结果。
“在旁边”返回值
用 C 写第一种方法的例子如下:
int foo(int* out) {// <try something here>if (failed) {return 1;}*out = 42;return 0;}
真正的值不得不通过“旁边”来返回,让调用显得很笨拙:
int value;int ret = foo(&value);if (ret) {// Error! Deal with it.}else {// Use value...}
不止是变得笨拙,这种模式扰乱了你编译器的定义分配分析,这损害了你获得像使用未初始化的值这种良好 warning 的能力。
Go 也通过更好的语法瞄上了这个问题,感谢多值返回:
func foo() (int, error) {if failed {return 0, errors.New("Bad things happened")}return 42, nil}
因此调用就显得清晰得多了。跟之前提到的对 error 的一行 if 检查组合起来 —— 一个微妙的变化,因为乍一看数值的返回不会在 if 范围内,但实际上会 —— 这做得更好:
if value, err := foo(); err != nil {// Error! Deal with it.} else {// Use value ...}
注意这也会帮助提醒你去检查错误。然而它也不是刀枪不入的,因为函数能返回一个错误而没有另外的其他东西,这样就跟在 C 中一样容易忘记检查它。
正如我上面提到的,有些人会在可用性这一点上反对我。尤其是 Go 的设计师,我怀疑。Go 语言使用错误代码的一个很大的吸引力在于,这是对当今世界过于复杂的语言的一个反叛。我们已经失去了太多让 C 如此优雅的东西 —— 你通常可以看着任一行 C 代码,就能猜出它翻译成的机器码是什么。我不会反对这些观点。事实上,我非常喜欢 Go 对于未检查的异常和 Java 的已检查异常的化身的模型。甚至是在我写这篇文章的时候,已经写了很多 Go 代码,我看着 Go 语言的简洁性,好奇着下文将介绍的我们设计的各种 try 和 require 是否走得太远了呢?我不太确定。Go 的错误模型是这个语言最关键的地方;这可能很大程度上是因为你不能像大多数语言中一样对错误敷衍过去,然而程序员们确实很享受在 Midori 中写代码。最后,很难比较 Go 和 Midori。我确信两者都可以用来写可靠的代码。
在数据结构中的返回值
函数式语言通过将一个值或一个错误打包进一个数据结构解决了很多可用性的挑战。因为如果你想要在调用时用返回值做任何有用的东西,你必须要将错误和值区分开来 —— 你可能会感谢编程的数据流风格 —— 这就很容易避免忘记检查错误的致命问题。
找个现代的例子来说明的话,看看 Scala 的 Option Type。不幸的消息是一些语言,像那些在 ML 家族的,甚至 Scala (由于它的 JVM 血统),将这种优雅的模型和 unchecked exception 世界混合在一起。这污染了单独的数据类型方法的优雅。
Haskell 做了一些更酷的事情,并且给人一种异常处理的幻觉,但实际上还是使用错误码和本地控制流:
在 C++ 程序员中有个长久以来的争论,到底是异常还是错误返回码是正确的方式? Niklas Wirth 认为异常是
goto的化身,所以在他的语言中省略了它们。Haskell 通过一种老到的方式解决了这个问题:函数返回错误码,但错误码的处理不会让代码变得丑陋。
这里的技巧是支持所有熟悉的 throw 和 catch 模式,但使用 monad 而不是控制流。
虽然 Rust 也使用错误码,但它也是函数式的错误类型风格。例如,设想我们正在 Go 里写一个函数名叫 bar:我们会调用 foo,然后如果它失败了,就简单地传递错误给调用者:
func bar() error {if value, err := foo(); err != nil {return err} else {// Use value ...}}
在 Rust 中的写法不会更简洁。它可能会让 C 程序员陷入引入的繁琐的模式匹配语法中(一种真正的关注,而不是搞破坏)。然而,任一个熟悉函数式编程的程序会甚至眼皮都不会眨一下,而且这种方法当然会作为一个提醒,提醒你处理你的错误:
fn bar() -> Result<(), Error> {match foo() {Ok(value) => /* Use value ... */,Err(err) => return Err(err)}}
但它还能做得更好。Rust 有一个 try! 宏,将上面那个例子缩减为一个表达式:
fn bar() -> Result<(), Error> {let value = try!(foo);// Use value ...}
这带给了我们美妙的甜点。它当然会有我之前提过的性能问题,但在所有其他的维度表现得非常好。单独地它是一个不完善的图画 —— 为此,我们需要覆盖 fail-fast(又称:丢弃)—— 但就如我们将见到的一样,它远比现在任何其他广泛使用的的基于异常的模型要好。
异常
异常的历史引人入胜。在探索异常的旅程中,我花费了无数个小时追溯行业的步伐。包括阅读一些源头文章 —— 比如 Goodenough 在 1975 年的经典文章《异常处理:问题和建议》 —— 以及查找几种语言的方法:Ada、Eiffel、Modula-2 和 3、ML、以及,最具启发性的 CLU。许多论文在总结这个漫长而艰辛的旅程方面做得比我要好,所以我在这里不会这么做。相反,我将重点放在对于搭建一个可靠的系统,那些方法有效,哪些不行。
在我们开发错误模型时,可靠性是我们最重要的需求。如果你无法对故障进行适当的反应,你的系统从定义上不会非常可靠。操作系统通常来说需要可靠。可悲的是,最常见的模式 —— unchecked exception —— 是这个维度上你会做到最差的。
由于这些原因,大部分可靠的系统采用的是返回码,而不是异常。这让本地决定如何最好地响应错误条件成为可能。我可能说得太快了,让我们深挖一下。
Unchecked Exception(未检查异常)
快速回顾一下。在 unchecked exception 模型中,你 throw 和 catch 异常,而不将其作为类型系统或者函数签名的一部分。例如:
// Foo throws an unhandled exception:void Foo() {throw new Exception(...);}// Bar calls Foo, and handles that exception:void Bar() {try {Foo();}catch (Exception e) {// Handle the error.}}// Baz also calls Foo, but does not handle that exception:void Baz() {Foo(); // Let the error escape to our callers.}
在这个模型里,任何一个函数调用 —— 有时候任何语句 —— 可能会抛出一个异常,转换控制到某个不在本地的地方。转移到哪里?鬼才知道。没有标记或者类型系统神器来帮你分析。结果就是,在抛出异常时任何人都很难了解程序的状态是怎样,状态会改变,当异常在调用栈用传播 —— 在并发程序中也可能跨线程传播 —— 当它被捕获或未处理时,结果状态会改变。
当然可以试着去做。这么做需要阅读 API 文档,手动审核代码,严重依赖代码审查,以及大量的好运气。语言本身在这一点上没有为你提供任何帮助。因为失败是罕见的,所以这听起来并不完全是灾难性的。我的结论是,这就是为什么业界的很多人都认为 unchecked exception 已经“足够好了”。它们在通常的成功路径脱颖而出,并且由于大多数人不会在非系统程序中编写健壮的错误处理代码,抛出异常通常很快让你避免这种麻烦。捕获异常然后继续通常也是有效的。没有伤害,没有犯规。统计意义上讲,程序是“工作的”。
也许对脚本语言来说,统计正确性是不错的,但对操作系统的最底层,或任一个处理关键任务的应用,这不是一个合适的解决方案。我希望这个不会有什么争议。
.NET 会导致更糟糕的的情况,由于它的异步异常。C++ 也有所谓的“异步异常”:那些由硬件错误触发的失败,像非法访问。然而,它在 .NET 中变得非常讨厌。任一个线程几乎可以在代码中的任一点注入失败。甚至在一个赋值的 RHS 和 LHS 之间!因此,源代码中看起来是原子性的操作,实际上并不是。我在大概 10 年前写个一篇文章讨论这点,而挑战仍然还存在,尽管风险已经降低了,因为 .NET 大体认识到线程中止是有问题的。新的 CoreCLR 甚至缺少了 AppDomain,并且新的 ASP.NET Core 1.0 栈当然不像它过去那样用线程中止。但那些 API 仍然存在。
有一个著名的对 C# 主设计师 Anders Hejlsberg 的采访,谓之 checked exception 的麻烦。从一个系统程序员的视角来看,其中的大部分都让你挠头。没有比这更说明 C# 是面向快速程序开发者的语句了:
Bill Venners:但这样做的话,你不是在破坏他们的代码吗?甚至在一个没有
checked exception的语言中。如果foo的一个新版本打算要抛出一种新的异常,而这需要客户端要考虑处理的。是不是当他们写代码的时候没有考虑到这种异常,代码就被破坏了?Anders Hejlsberg:是的,因为大多数情况下,人们不会在乎的。他们不会去处理任何一个这种异常。在他们的消息循环周围有一个兜底的异常处理器,这个处理器只是弹出一个对话框说什么出了错,然后继续。程序员通过到处都是的
try finally来保护他们的代码,所以如果异常发生了,他们能够正确处理,但他们实际上对异常处理不感兴趣。
这让我想起了 Visual Basic 中的 On Error Resume Next,以及 Windows Form 自动捕获并吞掉应用抛出的异常,然后试图继续。在这里,我不是在指责 Anders 的观点;呃,因为 C# 被广泛欢迎,我确信这是当时环境下正确的做法。但这显然不是写操作系统代码的正确方式。
C++ 至少试着用它的异常抛出规范提供了一些比 unchecked exception 更好的东西。不幸的是,这个特性依赖动态执行,这为它带来了死亡诅咒。
如果我写一个函数 void f() throw (SomeError),它的函数体仍然可以随意调用其他 throw SomeError 之外异常的函数。类似地,如果我通过 void f() throw() 声明 f 不会抛出异常,它仍然可能调用抛出异常的其他东西。因此,为了实现声明的约定,编译器和 runtime 必须确保,如果这种情况发生了,std::unexpected 要被调用来终止进程作为响应。
我不是唯一认识到这种设计是错误的人。实际上,throw 现在被废弃了。一个详细的 WG21 文档,废弃异常规范,描述了 C++ 如何走到这一步,并在它的公开声明中提到这一点:
异常规范在实践中已经被证明几乎没有什么价值,并且还给程序增加了可观的开销。
作者列举了废弃 throw 的三个理由。三个中的两个是动态选择的结果:运行时检查(及其相关的不透明故障模式)和运行时性能开销。第三个则是,缺乏跟泛型代码的良好组合,可以通过使用适当的类型系统来解决(当然代价比较大)。
但最坏的地方在于,依赖另一个动态强制的构造 —— noexcept 规范器 —— 对这个我认为跟问题本身一样差。
“异常安全”是 C++ 社区中常常讨论的实践。这种方法根据如下依据进行了整齐的分类:从一个函数调用者的调度角度来说,函数对于错误、状态变迁和内存管理本意是要如何响应的。一个函数属于以下四类之一:no-throw 代表执行过程保证没有异常会出现;strong safety(强安全)代表状态变迁是原子性的,一个错误不会留下部分提交的状态或破坏的不变量;basic safety(基本安全)代表,尽管一个函数可能部分提交状态变化,不变量不会被破坏而且泄露被阻止了;以及最后 no safety(不安全)代表任何事情都可能发生。这种分类很有用,我鼓励所有人有意识并严格地处理错误行为,通过这样或其他类似方式,即使你在使用错误码。问题是,在系统中使用 unchecked exception 的话,我们无法遵循上述准则,除了一个调用小而易于审计的其他函数的叶子节点数据结构。试想一下:为了保证所有地方都遵循 strong safety,你需要考虑所有函数调用抛出异常的可能性,并相应地保护周围代码。这要么意味着防守式的编程,信任其它函数的文档(未经计算机检查过的),运气很好并且只调用 noexcept 函数,要么只能听天由命。感谢 RAII,basic safety 的无泄漏更容易实现了 —— 在如今通常还要感谢智能指针 —— 但不变量的破坏还是很难预防。异常处理:虚假的安全感一文很好地总结了这一点。
对于 C++ 来说,现实的解决方案很容易预测,而且相当直接:对于需要鲁棒的系统程序,不要使用异常。这是嵌入式 C++ 使用的方法,另外还有大量的实时和关键任务的 C++ 指南,包括 NASA 的喷气推进实验室的。火星上的 C++ 肯定不会在接下来使用异常。
因此如果你可以安全地避免异常并坚持在 C++ 中使用类似 C 的返回码,你还有什么好抱怨的呢?
整个 C++ 生态系统都在使用异常。要遵守上述指南,你必须得舍弃这个语言的重要部分,而且事实上,还包括类库生态系统的重要部分。想要用标准模板库?太可惜了,它使用异常。想要用 Boost?太可惜了,它使用异常。你的分配器可能会抛出 bad_alloc。等等。这甚至导致像人们创建现有类库的消除了异常的 fork 的混乱。作为例子,Windows 内核就有它自己的不使用异常的 STL 的 fork。生态系统的这种分支既不让人愉快,要维护也不实际。
这种混乱是我们陷入了不利之境。特别是因为许多语言使用 unchecked exception。很明显,它们不适合用于编写底层的、可靠的系统代码。(我确信我这么坦白地说出这个会招来一些 C++ 敌人。)在 Midori 写了这几年代码之后,再用回使用 unchecked exception 的语言写代码让我飙泪,即使只是代码审查也是折磨。但是“谢天谢地”我们有从 Java 那里可以学习和借鉴的 checked exception ……对吧?
Checked Exceptions
呃,checked exception。几乎所有 Java 程序员,以及所有近距离关注过 Java 的人都喜欢痛殴的玩意。在我看来这很不公平,尤其是相对于unchecked exception带来的麻烦来说。
在 Java 中,你大体上可以知道一个方法会抛出什么,因为一个方法必须要这样声明:
void foo() throws FooException, BarException {...}
现在调用方就知道了调用 foo 可能会导致抛出 FooException 或 BarException。在调用点,程序员必须做出决定:1)原样传播异常,2)捕获异常并处理它们,或者 3)用某种方式转换抛出异常的类型(可能甚至“忘记”所有的类型)。举个例子:
// 1) Propagate exceptions as-is:void bar() throws FooException, BarException {foo();}// 2) Catch and deal with them:void bar() {try {foo();}catch (FooException e) {// Deal with the FooException error conditions.}catch (BarException e) {// Deal with the BarException error conditions.}}// 3) Transform the exception types being thrown:void bar() throws Exception {foo();}
这离我们能用的东西很接近了。但它也在一些地方有失败之处:
- 异常经常跟不能恢复的 bug 联系在一起,像
null解引用,除 0 等等。 - 因为我们可爱的
RuntimeException朋友,实际上你并不能完全知道可能会被抛出来的所有东西。因为 Java 对所有的错误条件使用异常 —— 甚至对 bug,如上所述 —— 设计者意识到人们会被所有的那些异常规范搞疯。因此他们引入了一种unchecked的异常。也就是说,一个方法会在未声明的时候将它抛出来,并因此调用者会没意识到地调用它。 - 虽然签名声明了异常的类型,但在调用点没有关于什么样的调用会导致抛出异常的指示。
- 人们讨厌它们。
最后一点很有意思,迟点在描述 Midori 采用的方法时我会回头探讨它。总而言之,人们对 Java 中 checked exception 的厌恶主要来源于或者至少被加强了其他三点。结果造成的模型好像是集合两个世界里面最糟糕的。它不会帮你写出刀枪不入的代码,而且它还很难用。最后你会写出很多乱七八糟的代码,而只获得很小的好处。而且对你的接口做版本控制简直蛋疼。正如我们很快会看到的那样,我们能做得更好。
版本控制点(versioning point)是值得思考。如果你坚持单一类型的 throw,那版本控制问题不会比错误码更差。一个函数会失败或者不会。实际上,如果你将你的 API 的版本 1 设计成没有失败模式,却想在版本 2 加入失败模式,你就完蛋了。在我看来,你本来就会完蛋。一个 API 的失败模式是它的设计和调用约定的很关键的部分。正如你不应该静悄悄不让调用者知道地改掉 API 的返回类型一样,你也不应该通过一种有语义意义的方式改变失败模式。后面会讨论这个争论点。
CLU 使用了一种有趣的方式,正如在这个由 Barbara Liskov 于 1979 年写下的 CLU 中的异常处理论文的歪歪扭扭的扫描版所描述的那样。请注意他们把关注点放在“语言学”上;换句话说,他们想要一种人们喜欢的语言。在函数调用点检查和重新传播所有错误的需求感觉很像返回值,但编程模型有一种现在我们称之为异常的更丰富和略微陈述性的感觉。最重要的是,signals(他们为 throw 起的名字)是被检查的。如果一个预料之外的 signal 发生,也有很方便的终止程序的办法。
异常的普遍问题
大多数异常系统都有一些主要的东西干得不对,不管它们是 checked 的还是 unchecked 的。
首先,抛出一个异常通常是非常昂贵的。这几乎总是由于对堆栈跟踪的收集造成的。在托管系统中,收集堆栈跟踪也需要填充元数据,以创建函数符号的字符串名称。然而,如果这个错误被捕获并被处理掉的话,在运行时你甚至不需要那些信息!诊断最好还是通过日志和诊断体系来实现,而不是通过异常系统自己。关注点是正交的。尽管如此,为了达成上面说的诊断需求,需要有些东西能够将堆栈跟踪恢复出来;永远不要低估 printf 调试和堆栈跟踪的重要性。
其次,异常会严重损害代码质量。我在我的上一篇文章谈到过这个问题,在 C++ 的上下文中有对关于这个主题的很好的论文。没有静态类型系统的信息使得很难在编译器中建立控制流,这导致了过于保守的优化器。
另一个大多数异常系统搞糟的事情是鼓励了太粗粒度的错误处理。返回码的拥趸喜欢在特定函数调用时本地处理错误。(我也是!)在异常处理系统中,在一大块代码外面包一个粗粒度的 try/catch 块实在太简单了,而没有仔细地对单个的失败做出反应。这产生了几乎肯定会出错的脆弱代码;如果不是在今天,就是在不可避免的重构之后出错。许多这样的需要有正确的语法来处理。
最后,throw 的控制流通常是不可见的。即使是在使用异常来标记方法签名的 Java 中,对代码体进行审计并精确地找出异常是从哪里出来的也是不可能的。无声的控制流跟 goto 或 setjmp/longjmp 一样糟,并使编写可靠的代码非常困难。
我们到了哪?
在继续之前,让我们回顾一下我们到了哪里:
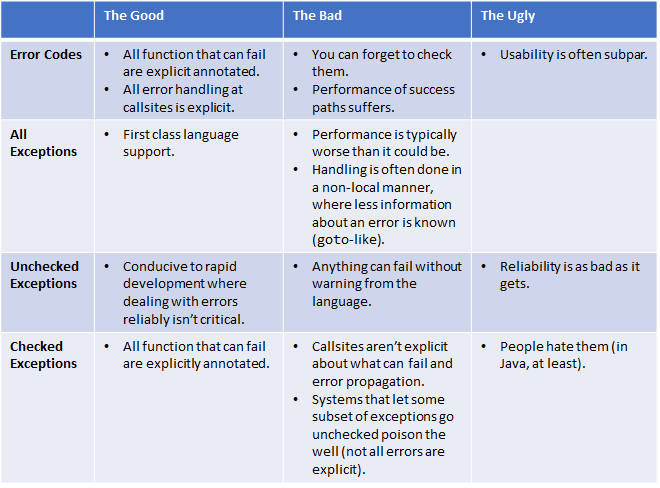
如果我们可以得到所有的优点并扔掉所有的缺点和丑陋的地方不是会非常棒吗?
单独来看这只是会向前迈出一大步。但还不足够。这导致了我们的第一个很棒的“啊哈”时刻,塑造了将会到来的一切。对于一个重大的错误的类型,上面的方法全部都不太适合。
Bug 不是可修复的错误!
我们之前做了一个关键的区分,是关于可修复的错误和 bug 的不同的:
一个可修复的错误通常是程序化数据验证的结果。一些代码已经检查了世界的状态并认为这种情况不能被处理过程接受。也许是一些正在解析的标记文本、网站的用户输入或者一次暂时的网络连接失败。在这种情况下,程序是被期望去修复的。编写这些代码的开发人员必须考虑在发生这些失败事件时要做什么处理,因为不管你代码写的多么完善,这些情况还是会出现。响应可能是将情况传达给最终用户,重试或者完全放弃操作。尽管它被称为“错误”,但它是可以预测的,而且经常是计划中的情形。
一个 bug 是一种程序员没有想到的错误。输入没有被正确地验证、逻辑写错了、或者一系列问题的出现。这些问题往往不能及时被发现;需要一段时间直到“间接的影响”被直接观察到为止,到这个时候程序的状态可能已经遭到了严重的破坏。因为开发人员没有设想过这会发生,所有的措施都是没有的。这些代码涉及到的所有数据结构现在都变成了可疑的。而且由于这些问题并不一定能及时发现,事实上,还有涉及的更多是可疑的。依赖于你使用语言的隔离保证,也许整个进程都受到了污染。
这个区别是至关重要的。令人惊讶的是,绝大多数系统没有做这样的区分,至少不是通过一种原则性的方式!正如我们上面提到的,Java、C# 以及动态语言只使用异常来处理一切,而 C 和 Go 则使用返回码。C++ 能混合使用,取决于用户,但通常是一个项目只捡起一种方式然后在项目里到处使用它。但你通常不会听说语言建议两种不同的错误处理技术。
鉴于 bug 本身无法自动修复,我们不会尝试去 try。所有的在运行时检测到的 bug 会导致称为丢弃的东西,这是 Midori 团队中的术语,其他地方通常称之为“fail-fast(快速失败)”。
每一个上述的系统都提供了类似丢弃的机制。C# 有 Environment.FailFast;C++ 有 std::terminate;Go 有 panic;Rust 有 panic!;等等。每种都会迅雷不及掩耳地终止周围的上下文。这种上下文的范围取决于系统 —— 比如,C# 和 C++ 终止进程,Go 终止当前的 Goroutine,Rust 中止当前的线程,还有一个可选的 panic 处理器尝试去抢救一下进程。
虽然我们的确更为常规并且无处不在使用丢弃,但我们当然不是第一个认识到这种模式的人。这篇 Haskell 文章就很好地表达了这个区别:
我参与了用 C++ 编写的库的开发。其中一个开发人员告诉我,开发人员有的喜欢异常,另外一些喜欢返回码。在我看来,喜欢返回码的朋友赢了。然而,我有个印象是,他们搞错了点:异常和返回码具有同样表现力,然而,不应该用来描述错误。实际上,返回码包含如
ARRAY_INDEX_OUT_OF_RANGE的定义。但是我想知道:如果从子程序获取这个返回码,我的函数需要如何反应?它会向其程序员发送邮件吗?它可以依次将该代码返回给其调用者,但也不知道如何应对它。更糟糕的是,由于我不能对函数的实现做出假设,所以我必须认为每个子例程都可能有一个ARRAY_INDEX_OUT_OF_RANGE。我的结论是ARRAY_INDEX_OUT_OF_RANGE是一个(编程)错误。它在运行时无法处理或修复,而只能由开发人员修复。因此,应该不是使用返回码,而是应该使用断言。
丢弃中的细粒度的可变共享内存范围是可疑的 —— 像协程或线程或其他什么东西 —— 除非你的系统以某种方式对潜在损害的范围作出保证。尽管如此,这些机制在我们这里使用表现得非常棒!这意味着在这些语言中使用一种丢弃规范是有可能的。
然而,这种方法要在规模上取得成功需要必要的架构要素。我确信你会想:“如果每次在 C# 碰到一个解 null 引用我都将整个进程干掉的话,客户会很生气,后果很严重”;以及,同样的:“那样就一点可靠性都没有了!”可靠性,很可能,不是你想的这样子。
可靠性、容错性以及隔离
在我们进一步讨论之前,我们需要达成一个中心信念:故障发生。
打造一个可靠的系统
通常明智的做法是,你通过系统地保证失败永远不会出现来搭建一个可靠的系统。直观地说,这很有道理。只有一个问题:在有限制的情况下,这是不可能做到的。如果你能够单独为这个特性花上数以百万计的美元 —— 像很多关键任务、实时系统那样做 —— 那么你可以做出重大突破。或者使用像 SPARK) 这样的语言(一个 Ada 的基于约定的扩展集合)来形式化证明写下的每一行代码的正确性。然而,经验证明即使是这样做也不是万无一失的。
与其跟生活的这个事实作斗争,我们拥抱了它。显然你会试图在可能的地方尽量消除失败。错误模型必须使它们透明并容易处理。但更重要的是,你架构你的系统,使得即使单独的部分失败了,整个系统仍然保持功能性,然后教你的系统去优雅地恢复那些失败了的部分。这在分布式系统中是众所周知的。那么为什么它是新颖的呢?
在这一切的中心,操作系统只是协作进程的分布式网络,就像分布式的微服务集群或互联网本身一样。主要的不同包括延迟;你可以保证什么级别的信任和多容易做到这点;以及关于位置、身份等等的各种假设。但在高度异步、分布式以及 I/O 密集的系统中,失败是必然会出现的。我的印象是,很大程度由于庞大单一内核的持续成功,世界上还没有跨越到“操作系统作为分布式系统”的洞察力。然而,一旦你这样做了,许多的设计原则立刻变得显而易见。
与大多数分布式系统一样,我们的架构假设进程失败是不可避免的。 我们经常长时间地防范连锁故障,定期做系统日志,并让程序和服务的可重启性可用。
当你开始这样设想,你会按照不同的方式来构建系统。
特别地,隔离是至关重要的。Midori 的进程模型鼓励轻量级细粒度的隔离。结果就是,程序以及原先在现代操作系统中的“线程”的东西,现在是完全独立的实体。对一个这样的连接失败的保护,比在整个地址空间共享可变状态中的容易得多。
隔离还鼓励了简单性。Butler Lampson 经典的计算机系统设计的启示探索了这个主题。我总是喜爱这个来自 Hoare 的引用:
可靠性不可避免的代价是简单性。(C. Hoare)
通过将程序打碎成更小的块,其中的每块都可以自行失败或成功,它们的状态机可以保持更为简单。由此,从失败中恢复变得更加容易。在我们的语言中,可能的失败点是显式的,进一步帮助保持内部的状态机正确,并指出了跟更为混乱的外部世界的联系。在这样的世界中,个体失败的代价并不是那么严峻。我怎么强调这一点也过分。没有这种低成本和始终存在的隔离的架构基础,没有一个我之后会描述的语言特性能有效果。
Erlang 已经非常成功地将这个特性以很基础的方式建立在语言中。像 Midori 一样,它使用通过消息传递连接的轻量级的进程,鼓励容错的架构。一个常见的模式是“监管(supervisor)”,其中的一些进程负责查看并一旦发生了失败事件就重启其他进程。这篇文章做了一个了不起的工作,阐述了这种哲学 —— “让它崩溃” —— 并推荐了在实践中构建可靠的 Erlang 程序的技术。
关键的问题在于它并不是防止失败本身,而是知道如何以及何时处理失败。
一旦建立了这种架构,你尝试打败它来确保它能正确工作。对于我们来说,这意味着以周为单位的压力运行,进程进进出出,有些是由于失败,来确保作为整体的系统保持一个很好的前进进程。这让我想起像 Netflix 的混乱猴子(Chao’s Monkey)这样的系统,它会随机干掉你集群内的整个机器,来确保整体的服务保持健康。
我希望在转移到更多分布式计算的时候,世界上更多的人会采用这种哲学。举个例子,在一个微服务的集群中,单个容器的故障通常由围绕它的集群管理软件(Kubernetes, Amazon EC2 容器服务, Docker Swarm,等等)无缝地处理掉。因此,我在本文描述的很可能对编写更可靠的 Java、Node.js/Javascript、Python、以及甚至 Ruby 服务有所帮助。不幸的消息是,你可能要挑战你的语言来做到这一点。你进程中的很多代码可能会需要很困难的工作,来保证在失败发生时依旧勉强运行。
丢弃
即使进程便宜又隔离,容易重新创建,还有有理由认为在遇到 bug 的时候丢弃整个进程是一种反应过度。让我试着说服你。
当你试图构建一个鲁棒的系统时,遇到 bug 还继续执行是非常危险的。若程序员没有设想到这种出现的情况,谁知道代码会不会正确地处理这些东西。关键的数据结构很可能已经落在了一个不正确的状态。举一个极端点(可能有点蠢)的例子,一个本想将你的金额向下取整用于银行业务的例程可能将它向上取整。
你可能去视图将丢弃的粒度降低到比进程更小的东西。但这很棘手。举个例子,想象你进程中的一个线程遇到了一个 bug,并失败了。这个 bug 可能是被储存在静态变量的一些状态触发的。即使一些其他的线程可能看上去没有被这个导致失败的条件所影响,你还是不能下这个结论。除非你系统的某些属性 —— 语言中的隔离、暴露给独立线程的对象根集合的隔离、或者一些其他东西 —— 最安全的做法是,假设在窗口之外的整个地址空间波及到的其他东西都是危险而且不可靠的。
由于 Midori 中的轻量级性质的进程,丢弃一个进程更像丢弃经典的系统中的单个线程而不是一整个进程。但我们的隔离模型让我们可靠地做到这一点。
我得承认范围界定的话题是一个滑坡。也许世界上的所有数据都被污染了,所以你怎么知道波及进程就已经足够了?!这里有一个重要的区分。进程状态是设计上就是短暂的。在一个良好设计的系统中它可以随心所欲地被扔掉然后再重建。当然,一个 bug 可能破坏持久的状态,但那样的话你就有一个更大的问题要处理了 —— 一个必须使用不同的方式来处理的问题。
作为一些背景,我们可以看看容错系统设计。丢弃(fail-fast)已经是这个领域的常见技术了,我们可以将很多关于这些系统的知识应用到普通的程序和进程。也许最重要的技术是定期记录和检查宝贵的持久状态。Jim Gray 1985 年的论文,为什么计算机会停止以及我们能够做些什么?,很好地描述了这个概念。随着程序继续向云转移,并积极地被分解成更小的独立的服务,短暂状态和持续状态的清晰的分离就更为重要了。由于这些软件的编写方式发生了变化,现代架构中丢弃的可能性远远超过以往。事实上,丢弃可以帮助你避免数据损坏,因为在下一个检查点之前检测到 bug 可以防止错误的状态逃脱出去。
Midori 内核的 bug 是以不同的方式处理的。例如,一个在微内核中的 bug,是跟用户模型进程的 bug 完全不同的野兽。可能造成危害的范围更大,最安全的反应是丢弃整个“域”(地址空间)。幸好,大部分你以为是经典的“内核”的功能 —— 调度器、内存管理器、文件系统、网络栈、以及甚至设备驱动 —— 都是在用户模型以隔离的进程方式运行的,这样失败就可以通过上述的通常的方式处理了。
Bug:丢弃、断言、以及约定
在 Midori 中,一些种类的 bug 会触发丢弃:
- 不正确的类型转换。
- 试图解引用空指针。
- 试图超出范围访问数组。
- 被 0 除。
- 计划外的数学的向上/向下溢出。
- 内存不足。
- 栈溢出。
- 显式丢弃。
- 约定失败。
- 断言失败。
我们的根本信念是每一个上述的条件都是程序没办法从中恢复的。让我们一个个来讨论。
普通的老 bug
这些情况中的一些毫无疑问表示程序出 bug 了。
不正确的转换、null 解引用尝试、越界访问数组、或者被 0 除明显是程序逻辑的问题,因为它视图执行毫无疑问的非法操作。我们待会会看到,会有一些处理的方法(例如,也许你对于被零除想要 NaN 风格的传播)。但我们默认认为它是 bug。
大多数程序员都会接受这一点,没有什么问题。并将它们作为 bug 处理,在开发循环的内部进行丢弃,可以快速找到和修复开发过程中的 bug。丢弃真的能帮助人在写代码的时候更有生产力。一开始这让我惊喜,但它是有道理的。
另一方面,这里的一些情形是主观的。我们必须做出关于默认行为的决定,经常有争议,并且有时候提供程序化的控制。
算术上/下溢出
说一个木易的算术上/下溢出代表一个 bug 当然是一种有争议的姿态。然而,在不安全的系统中,这种情形频繁导致安全漏洞。我鼓励你查看一下国家的漏洞数据库来瞧瞧相关漏洞的数量。
事实上,我们移植到 Midori 的 Windows TrueType 字体解析器(在性能上收获很大),先前一些年就已经遭受了一打这样的问题。(解析器往往是这样的安全漏洞的种植场。)
这就引起了像 SafeInt 之类的软件包的出现,本质上让你远离本机语言的算术运算,而支持已经过检查的库。
大多数这样的漏洞当然也会跟访问不安全的内存成对出现。因此你可以合理地争辩说,在安全语言中溢出是无害的,所以应该被允许。然而,基于安全经验,很明显的,程序在面对五一的上/下溢出时经常做错事情。简单地说,开发人员经常忽视存在这种溢出的可能,而程序则继续做着计划外的事情。这正好精确的符合的丢弃意图起作用的 bug 的定义。钉上棺材上最后一根钉子的是,在哲学上,当有关于正确性的任何问题的时候,我们倾向于认为显示的意图之外的东西是错误。
所以,所有未声明的上/下溢出都会被认为是 bug 并会引致丢弃。这跟使用 /checked 开关编译 C# 类似,除了我们的编译器更加积极优化冗余检查。(由于很少人想过在 C# 中使用这个开关,代码生成器几乎不会做工作来删除插入的检查。)由于这种语言跟编译器的共同开发,结果远远好于大多数 C++ 编译器面对 SafeInt 算术操作所生成的。同样跟 C# 一样,在需要上/下溢出的地方,可以使用 unchecked 作用域结构。
虽然大多数我谈过的大多数 C# 和 C++ 开发人员一开始对这样做的看法是负面的,但我们的经验是,十中有九,这种方法帮助在程序中避免了 bug。剩下的一次通常是出现在我们 72 小时的压力运行的某次,被丢弃出来 —— 在那时我们使用浏览器和多媒体播放器和其他的随便什么我们可以用的东西来折磨系统 —— 那时一些无害的计数器溢出了。我总是觉得有趣的是,我们花了时间来修复这些,而不是以经典的那种方式来经过压力程序,也就是说以死锁和竞争条件的方式。在这个和那个之间,我会选择溢出丢弃!
内存不足和栈溢出
内存不足(OOM)是很复杂的。它一直都是。而我们在这里的立场当然也是有争议的。
在手动管理内存的环境,错误码风格的检查是最常见的方法:
X* x = (X*)malloc(...);if (!x) {// Handle allocation failure.}
这有一个微妙的好处:分配是痛苦的,需要先思考,所以使用这种技术的程序通常以更节俭和慎重的方式来使用内存。但是它有一个巨大的缺点:它很容易出错,导致大量的频繁的未经测试的代码路径。而当代码路径未经测试时,它们通常就不会有效。
开发人员通常做一些可怕的工作让他们的软件正好在资源枯竭的边缘正常工作。根据我对 Windows 和 .NET Framework 的经验,这是惊人的错误的起因。而且它导致了非常复杂的编程模型,如 .NET 的称为约束执行区域的东西。一个程序陷入瘫痪的边缘,无法再分配哪怕一丁点的内存,会迅速变成可靠性的敌人。Chris Brumme 的奇妙的可靠性文章用所有它的血淋淋的光荣描述了这个和相关的挑战。
我们系统的一部分当然某种意义上是“百炼成钢”的,像内核的最底层一样,那里丢弃影响的范围必然比单一的进程更广泛。但我们尽可能保持这一块尽少的代码。
对于其余的部分?是的,你猜到了:丢弃。很简单很好。
让人惊奇的是我们已经从多少个这样的情形中逃脱了。我把这个的大部分归结到隔离模型。事实上,我们会故意让一个进程遭受 OOM,并确保由于资源管理策略而出现的丢弃,并且仍然确信建立在整体架构之上的稳定性和可恢复性。
如果你真的想的话,可选的对单独分配的可恢复失败也是可能的。这并不常用,然而支持机制就在那里。也许最好的动机例子是这样:想象你的程序想分配一个 1MB 大小的缓冲区。这跟你通常的跑了上百万个 1KB 的子对象分配的情形不同。开发人员会仔细考虑并明确处理这样的事实,即 1MB 的连续块可能不可用,并且相应地处理它。例如:
var bb = try new byte[1024*1024] else catch;if (bb.Failed) {// Handle allocation failure.}
栈溢出也是同一种哲学的简单扩展。栈只是一种内存支持的资源。事实上,由于我们的异步链接栈模型,跑爆了栈物理上跟跑爆了堆是完全一样的,所以一致地处理这些堆栈对于开发人员一点都不奇怪。现在,很多系统都是这样处理栈溢出。
断言
断言是一种代码中手动的检查,检查一些条件是否保持为 true,如果不是,就触发丢弃 。跟大多数其他系统一样,我们既有只存在 debug 的断言,也有 release 的断言,然而不想其他大多数系统的是,我们有比 debug 更多的 release 断言。事实上,我们的代码布满了大量的断言。大多数方法有多个断言。
这符合在运行时找到 bug 比碰到 bug 时再处理好的理念。以及当然的,我们的后端编译器也被教授了如何针对断言进行跟其他一切东西一样的积极优化。这个断言密度的级别跟高度可靠系统建议的指南类似。例如,来自 NASA 的论文:开发关键的安全代码的十个准则的力量:
准则:代码的断言密度应该平均为每个函数最少两个断言。断言用于检查实际运行中永远也不应该出现的异常条件。断言必须是无副作用的,并且应该被定义为布尔测试。
原理:工业编码工作的统计数据表明,单元测试通常会在每 10 到 100 行代码中找到至少一个缺陷。拦截缺陷的可能性随着断言密度的增加而增加。通常还建议使用断言作为强大的防御性编码策略的一部分。
表明一个断言,你只需调用 Debug.Assert 或 Release.Assert:
void Foo() {Debug.Assert(something); // Debug-only assert.Release.Assert(something); // Always-checked assert.}
我们也实现了类似 C++ 中的 __FILE__ 和 __LINE__ 宏,再加上用于谓词表达式文本化的 __EXPR__,以使由于断言失败而导致的丢弃携带更有用的信息。
在早期,我们使用了跟现在断言的不同的“级别”。我们有三个级别:Contract.Strong.Assert,Contract.Assert,和 Contract.Weak.Assert。强的级别意味着“总是检查”,中间的意味着“由编译器决定”,弱的意味着“仅在 debug 模式下进行检查”。我做了有争议的决定来从这三个级别换成现在的这个模型。事实上,我很确定地知道团队里 49.99% 的人讨厌我选择的这个术语(Debug.Assert 和 Release.Assert),但我总是喜爱它们,因为它们相当清楚地表明了它们做的东西。旧分类的问题在于,没有人明确地知道断言什么时候会被检查;在这个方面的混乱是根本不能接受的,在我看来,对于一个程序的可靠性,好的断言纪律的重要性是休戚相关的。
当我们将约定(contract)转到语言中时(很快就会提到),我们尝试将 assert 也作为一个语言的关键字。不过我们最终选择回使用 API。主要的原因是断言并不像约定那样是 API 签名的一部分;以及由于断言很容易作为一个库实现,将它们加入到语言中能让我们获得什么还是不明确的。此外,像“在 debug 中检查”对比“在 release 中检查”之类的策略根本就不觉得它们应该属于编程语言中的一部分。我得承认,几年之后的今天,我还是这两种方式的骑墙派。
约定(Contract)
约定是在 Midori 里找到 bug 的主要机制。尽管我们是从 Singularity) 开始的,它使用了 Spec# 的一个变体,但我们很快就转到了甜美的 C# 并不得不重新发明我们想要的东西。在跟这个模型处了几年之后,我们最终得到了很不同的东西。
所有的约定和断言被证明是无副作用的,由于我们语言对不可变性和副作用的理解。这也许是语言创新的最大的一个领域,所以我肯定会很快写一篇关于这个的文章。
与其他领域一样,我们受到了许多其他系统的启发和影响。Spec# 是显然的一个。Eiffel 是非常有影响力的,特别是有许多发表的案例研究能供学习。研究努力,像基于 Ada 的 SPARK),以及实时和嵌入式系统的建议。深入理论的虎穴,Hoare 的公理语义等编程逻辑证明了这一切的基础。不过,对于我来说,最具哲学意义的灵感来自于 CLU 的,以及后来的来自 Argus 的,处理错误的整体方法。
前置条件和后置条件
约定最基本的形式是方法的前置条件。这说明了当方法要分发时,必需要保持什么什么条件。这通常用于验证参数变量。有时候它用于验证目标对象的状态,虽然这通常不是太好的做法,因为形态对于程序员去依赖来说是件困难的事。前置条件实质上是调用者对被调用者的保证。
在我们最终的模型中,前置条件是使用 requires 关键字声明的:
void Register(string name)requires !string.IsEmpty(name) {// Proceed, knowing the string isn't empty.}
一种较不常见的约定形式是方法的后置条件。这说明了当方法被执行之后应该保持什么样的条件。这是被调用者对调用者的保证。
在我们的最终模型中,后置条件使用 ensures 关键字来声明:
void Clear()ensures Count == 0 {// Proceed; the caller can be guaranteed the Count is 0 when we return.}
在后置条件中提及返回值是可能的,通过特别的 return 名称。先前的值 —— 例如需要在后置条件中提及的输入值 —— 可以通过 old(..) 方法来捕获;例如:
int AddOne(int value)ensures return == old(value)+1 {...}
当然,前置和后置条件可以混合使用。例如,来自我们的 Midori 内核的环缓冲(ring buffer):
public bool PublishPosition()requires RemainingSize == 0ensures UnpublishedSize == 0 {...}
这个方法知道 RemainingSize 为 0,可以安全地执行它的方法体,调用者知道返回后 UnpublishedSize 也是 0,可以安全地执行返回后的代码。
如果任一个约定在运行时被发现为 false,丢弃就发生了。
这是我们跟其他努力不同的一个领域。约定现在作为一种用于高级验证技术的程序逻辑表达式变得流行起来。那些工具通常使用全局分析来证明关于约定陈述的真还是假。我们采用了更简单的方法。默认情况下,约定是在运行时检查的。如果编译器能够在编译器证明它的真或者假,那么它可以很痛快地删掉运行时的检查或者抛出一个编译时的错误作为响应。
现代编译器有基于约束的分析,可以对这个做得很好,像我在上一篇文章提到过的范围分析。这些推广了事实并已经使用它们来优化代码。这包括了消除冗余的检查:显式编码在约定中或者在正常的程序逻辑中。并且它们训练有素地在合理的时间内执行这些分析,以免程序员切换到更快的另一个编译器。定理证明技术根本不符合我们的需求:我们的核心系统模块花了一天的时间来使用最好的那个定理证明分析框架来进行分析!
此外,方法声明的约定是它的签名的一部分。这意味着它们会自动地显示在文档中,在 IDE 的工具提示中,在其他地方。约定跟方法的返回类型和参数类型一样重要。约定实际上是类型系统的扩展,使用语言中任意的逻辑来控制交换类型的形状。因此,所有通常的子类型要求都适用于它们。而且,当然,这适用于模块化的本地分析,可以在几秒内使用标准优化编译器技巧来完成。
在 .NET 和 Java 中有 90% 的典型的使用异常场景变成了使用前置条件。包括所有的 ArgumentNullException、ArgumentOutOfRangeException 以及相关的类型,以及更重要的是,手工的检查并抛出异常已经拜拜了。目前在 C# 中,方法经常跟这些检查搅和在一起;光在 .NET 的 CoreFX 仓库中就有数以千计的这些东西。例如,下面是 System.IO.TextReader 的 Read 方法:
/// <summary>/// .../// </summary>/// <exception cref="ArgumentNullException">Thrown if buffer is null.</exception>/// <exception cref="ArgumentOutOfRangeException">Thrown if index is less than zero.</exception>/// <exception cref="ArgumentOutOfRangeException">Thrown if count is less than zero.</exception>/// <exception cref="ArgumentException">Thrown if index and count are outside of buffer's bounds.</exception>public virtual int Read(char[] buffer, int index, int count) {if (buffer == null) {throw new ArgumentNullException("buffer");}if (index < 0) {throw new ArgumentOutOfRangeException("index");}if (count < 0) {throw new ArgumentOutOfRangeException("count");}if (buffer.Length - index < count) {throw new ArgumentException();}...}
由于一些原因,这样做是很破碎的。当然,这很冗长繁琐,所有这些繁文缛节!但我们不得不用我们的方式来文档化这些异常,开发人员真的不应该 catch 它们。相反,他们应该在开发过程中找到这些 bug 并修复它。所有这些异常废话鼓励了非常差的行为。
另一方面,如果我们使用 Midori 风格的约定,这就能缩减为:
/// <summary>/// .../// </summary>public virtual int Read(char[] buffer, int index, int count)requires buffer != nullrequires index >= 0requires count >= 0requires buffer.Length - index >= count {...}
这就有了一些有吸引力的东西。首先,它更简洁。而且更重要的是,它通过一种文档化自己并且很容易被调用者理解的方式自描述了 API 的约定。而不是要求程序员用英语来表达错误条件,实际的表达式可供调用者阅读,并且有工具来理解和使用。它使用丢弃来跟失败联系起来。
我还应该提到我们有大量的约定帮助类来帮助开发人员编写通用的前置条件。上述的显式的范围检查非常凌乱,容易出错。相反,我们可以这样写:
public virtual int Read(char[] buffer, int index, int count)requires buffer != nullrequires Range.IsValid(index, count, buffer.Length) {...}
并且,除了手头上的那些活,在加上两个高级的特性 —— 数组作为切片(slice)和非空类型 —— 我们可以将代码缩减到下面这样,并保持同样的保证:
public virtual int Read(char[] buffer) {...}
不过我跳过头了……
简陋的起点
虽然我们已经达成了这种明显的很像 Eiffel 和 Spec# 的语法 —— 回到原点 —— 如前所述,我们实际上并不是一开始就想要改变语言的。实际上我们从采用简单的 API 方法开始的:
public bool PublishPosition() {Contract.Requires(RemainingSize == 0);Contract.Ensures(UnpublishedSize == 0);...}
这种方法有一些问题,跟 .NET 代码约定努力发现的困难的部分一样。
首先,以这种方式编写的约定是 API 实现的一部分,而我们希望它们成为签名的一部分。这似乎是一个理论上的关注点,但它远不止是理论上的。我们希望生成的程序包含内置的元数据,因此像 IDE 和调试器这样的工具可以在调用的时候显示约定。而且我们希望工具能够从约定中自动生成文档。而将它们埋藏在实现中是做不到这点的,除非你以某种方式反编译这个方法来将它们提取出来(这是一种 hack)。
这也使得它很难跟后端的编译器集成,而我们发现对于好的性能来说,这很有必要。
其次,你可能已经注意到调用 Contract.Ensures 的问题。因为 Ensures 意味着拿住了方法的所有完成路径,我们又怎可以只单纯地将它实现为 API 呢?答案是,你不能。一种方式是重写生成的 MSIL,在语言编译器产生了它之后,但这会导致见鬼的混乱。这个时候,你开始怀疑,为什么不简单地承认这是一种语言表达和语义问题,并为它添加语法呢?
另一个一直困扰我们的方面是约定是有条件的还是无条件的。在很多经典的系统中,你会在 debug 版本中检查约定,但在完全优化的版本则不会去检查它。在一个很长的时间里,我们有同样的三个级别的约定,跟我们之前提到过的断言一样:
- 弱,通过
Contract.Weak.*来声明,意思是只用于 debug 的。 - 通常的,通过
Contract.*来声明,让什么时候检查它作为一个实现的决定。 - 强,通过
Contract.Strong.*来声明,意思是一直都需要检查。
我得承认,一开始我觉得这是一个优雅的方案。不幸的是,随着时间的推移,我们发现,是否应该在 debug 和 release 版本中或者在上面全部版本中检查“通常的”约定造成了混乱,所以人们也对应地滥用了弱和强约定。不管怎么说,当我们开始集成这个方案到语言和后端编译器工具链中时,我们遇到了相当多的问题,不得不开始反思这一点。
首先,如果你简单地将 Contract.Weak.Requires 翻译成 weak requires 和将 Contract.Strong.Requires 翻译到 strong requires,在我看来,你最终会得到一种相当笨拙和特例化的语法,有更多的策略,而不是让我感觉到更舒服。它立刻就会引出 weak/strong 策略的参数化和可替换性。
然后,这种方法携带了一种条件编译的新模式,对我来说,这就有点尴尬了。换句话说,如果你想要一个只在 debug 模式生效的检查,你已经可以这样做:
#if DEBUGrequires X#endif
最后,对我来说这是板上钉钉的 —— 约定应该是 API 签名的一部分。有一个条件的约定是什么意思呢?工具应该如何去处理它呢?根据 debug 和 release 版本来生成不同的文档?此外,一旦你这么做了,你就是去了关键的保证 —— 代码如果不符合前提条件,就不能运行。
因此,我们干掉了整个条件编译的方案。
最终,我们得到了只有一种的约定:它是 API 签名的部分,并且一直都会被检查。如果编译器在编译期就可以证明约定是满足的 —— 我们在这里花费了大量精力 —— 它可以自如地去掉检查。但代码会被保证如果它的前置条件得不到满足,它就永远不会被执行。对于你想要进行条件检查的情况,你一向可以使用断言系统(上面有写)。
当我们开始部署新的模型时,我感觉就更加好了,因为我发现很多人滥用了“强”和“弱”概念,造成了混乱。迫使开发人员做出决定,能导致更加健康的代码。
将来的方向
我们项目关门大吉的时候,一些开发的领域正处于不同的成熟期。
不变式(Invariants)
我们在不变式上实现了很多。每次当我们跟精通根据约定进行设计的人员说起时,他们总是很震惊我们没有在第一天开始就引入它们。实话说,我们的设计的确在一开始就包含了它们。但我们从来没有完成实现和部署它们。这部分是因为工程的带宽问题,但也是因为有一些困难的问题依然存在。老实说,团队几乎总是对前置和后置条件加上断言的组合感到满意。我怀疑有充分的时间的话,我们会加入不变式来作为完成,但到目前为止我还是有一些问题未解决。我需要在实践中观察它一段时间。
我们设计了的方法是一个 invariant 变成它的围绕类型的一个成员;例如:
public class List<T> {private T[] array;private int count;private invariant index >= 0 && index < array.Length;...}
请注意 invariant 是被标记为 private 的。一个不变式的访问修饰符控制了哪些成员必须保持不变性。举个例子,一个 public invariant 必须保持的只是 public 函数的出口和出口情况;这就允许了 private 函数可以临时违反不变式的常见的模式,只要公共的入口能够保持即可。当然,跟上面例子一样,一个类也可以自由地声明一个 private invariant,来要求保持所有函数入口和出口。
我实际上很喜欢这个设计,我能它能够生效。我们都具有的主要的关注点是静默地在所有的地方引入检查。直到现在,这一点仍然让我觉得紧张不已。例如,在 List<T> 例子中,你必须在这个类型的每一个方法的调用前和调用后都有 index >= 0 && index < array.Length 检查。现在,我们的编译器最终非常擅长于识别和合并多余的约定检查;而且约定的存在实际上使代码质量变得更好的例子很多。不过,在上面给出的极端例子中,我相信会有一个性能损失。这将带给我们压力让我们改变什么时候应该检查不变式的策略,这可能会使整体的约定模型变得复杂化。
我真的希望我们有更多的时间来更加深入地探索不变式。我不认为团队对没有拥有它们有很强烈的反应 —— 当然我没有听到很多关于它们的缺失的抱怨(也许因为团队具有非常强烈的性能意识) —— 但我的确认为不变式会跟约定能够很好地结合。
高级类型系统
我一直喜欢说,约定是是从类型系统之上起作用的。类型系统允许你使用类型编码变量的属性。类型限定了变量可能保有的预期的值范围。约定也类似地检查变量所持有的值的范围。区别在哪?类型在编译时通过严格的可组合的归纳规则,相当低成本地来得到低成本证实,通常但不是全部,由开发人员编写的声明作为辅助。约定尽可能在编译时进行证明,不行的话就转到运行时,因此,远没有语言本身的任意逻辑那么严格的规范。
类型通常是首选的,因为它们能保证在编译时进行检查;并被保证很快地检查。这种给开发人员的把握是很强的,使用它们,整体上开发人员的生产力变得更好。
然而,类型系统的限制也是不能避免的;类型系统需要留有一些余地,否则它会很快增长到非常笨重并且没法用,极端情况下会被区分为不同的 bits 和 bytes。另一方面,我总是对需要使用约定的两种特定的余地感到失望:
- 可空性(
Nullability) - 数字范围(
Numeric ranges)
我们约定的大约 90% 都落到这两块上。因此,我们认真地探索更加高级的类型系统以用类型系统来区分变量的可空性和范围,而不是使用约定。
作为例子,以下是两者代码的不同之处,使用约定:
public virtual int Read(char[] buffer, int index, int count)requires buffer != nullrequires index >= 0requires count >= 0requires buffer.Length - index < count {...}
而这下面的代码就不需要约定,同样能够做到所有的保证,在编译时静态地进行检查:
public virtual int Read(char[] buffer) {...}
将这些属性放置到类型系统显著地减少了错误条件检查的负担。假设 1 个状态的生产者有 10 个消费者。与其 10 个消费者中的每一个都来采取措施来从错误条件中保护自己,我们可以将责任推回到那 1 个生产者,或者需要用于强制类型的单个断言,或者做得更好,让值一开始就保存在正确的类型中。
非空类型(Non-Null Types)
这第一个真的很困难:静态地保证变量不会接受空值。这就是 Tony Hoare 他著名的“十亿美元的错误”的所在。修复这个是任何语言的一个正义的目标,我很高兴看到新的语言设计师开始着手解决这个问题。
语言的很多方面都会在这个问题上每一步都跟你纠缠不休。泛型、0-初始化、构造函数以及更多。将非 null 改装进在现有语言中是相当困难的!
类型系统
简单地说,非空性归结为一些简单的类型系统规则:
- 默认情况下,所有未修饰的类型都是
non-null的。 - 所有的类型能够通过
a?修饰符,就像T?那样,来标记它为可空。 - 对于
non-null类型来说,null是一个非法值。 T可以隐式转换为T?。某种意义上,T是T?的一个子类型(虽然也不是全对)。存在转换
T?到T的操作符,通过运行时检查如果是null会触发丢弃(abandoned)。这里面大多数都可能是“显而易见的”,因为没有太多的选择。这种做法的意义是确保类型系统知道
null的所有路径。特别是,没有null可以“偷偷地”变成non-null类型T的值;这意味着解决 0 初始化(zero-initialization)也许是这里面最难的问题。语法
从语法层面,我们提供了一些方法来达成 #5,将
T?转换为T。当然,我们并不鼓励这样做,而是宁愿你尽可能地待在“非空”的世界中。但有时候这是不可能的。多步骤的初始化经常发生 —— 特别是跟集合数据结构一起 —— 所以必须得到支持。设想有一刻我们有一个
map:Map<int, Customer> customers = ...;
这告诉我们关于构造的三件事:
Map自身是非空的。- 它里面作为
key的int也不能是空。 - 它里面的
Customer值也不能为空。
现在假设所引起会返回 null 来表示缺少对应的 key:
public TValue? this[TKey key] {get { ... }}
现在,在调用方我们需要一些方法来检查查找是否成功。我们讨论了许多语法。
我们最容易实现的是保护性检查:
Customer? customer = customers[id];if (customer != null) {// In here, `customer` is of non-null type `Customer`.}
我承认,我对这种“魔术般的”类型强制保持观望态度。当它失败了总是很难指出什么东西错了,总让我烦恼。例如,如果你将 c 跟持有 null 值的变量比较,它就不生效,必须是字面上的 null。不过这种语法很容易记住,通常也是正确的。
这些检查会动态地分支到不同的逻辑块,如果值的确为 null 的话。通常你会想要简单地断言这个值是 non-null 的,否则就进行丢弃。有一个显式的类型断言操作符可以这样做:
Customer? maybeCustomer = customers[id];Customer customer = notnull(maybeCustomer);
notnull 操作符将任何的 T? 表达式转为 T 的表达式。
泛型
泛型很困难,因为有多个层次的可空性需要考虑。考虑一下:
class C {public T M<T>();public T? N<T>();}var a = C.M<object>();var b = C.M<object?>();var c = C.N<object>();var d = C.N<object?>();
基本的问题是:a、b、c 和 d 的类型都是什么?
我觉得我们一开始将它搞得比我们需要的更难了,很大程度是因为 C# 现有的可空(nullable)是一个相当古怪的东西,我们试图分心去模拟它太多了。好消息是我们最终找到了我们自己的道路,但这也花了好一段时间。
为了说清楚我的意思,让我们回到先前的这个例子。有两个阵营:
- .NET 阵营:
a是object;b、c以及d都是object?。 - 函数式语言阵营:
a是object;b和c是object?;d是object??。
换句话说,.NET 阵营认为你应该将任意一个或多个 ? 串折叠到单一个 ?。函数式阵营 —— 能理解数学组合的优雅 —— 避免了魔法操作,而是让世界跟它本身一样。最终我们认识到 .NET 的路线非常复杂,并且需要运行时的支持。
函数式语言的路线一开始会让你的脑袋有点大。例如,砍回先前的 map 例子:
Map<int, Customer?> customers = ...;Customer?? customer = customers[id];if (customer != null) {// Notice, `customer` is still `Customer?` in here, and could still be `null`!}
在这个模型中,你需要每次剥离一层 ?。但坦率地说,你停下来想想,这是有道理的。这更加透明而且精确反映了底下发生的事情。最好不要跟它作对。
也存在实现上的问题。最容易的实现方式是将T? 展开到某些“包装类型”,像 Maybe<T>,然后注入适当的包装和拆包装操作。事实上,对于这个实现如何能够工作是有合理的心理模型的。然而,有两个理由让这个简单的模型无法使用。
首先,对于引用类型 T,T? 必须不能浪费额外的一个 bit;一个指针的运行时的表示已经可以将 null 作为一个值,对于系统语言,我们想要利用这个事实,而将 T? 跟 T 一样有效地存储。这个可以通过专门的一般实例化就可以很简单地完成。但这的确因为这,non-null 不再能简单化为一个前端技巧。它需要后端编译器的支持。
(注意这种技巧不能简单地扩展到 T??!)
第二,Midori 支持安全协变数组,多亏了我们的可变性声明。如果 T 和 T? 存在不同的物理表示,那么将 T[] 转换为 T?[] 就是一个非转换操作。这是一个小瑕疵,特别是当你插入它们已经有的安全漏洞之后,协变数组已经变得不那么有用了。
不管如何,我们最终烧掉了 .NET 中 Nullable<T> 的做法,而使用了更加可组合的多个 ? 的设计。
0-初始化
0-初始化是真正的无法描述的痛。驯服它意味着要做到:
- 一个类中的所有的
non-null字段都必须在构造时初始化。 - 所有的
non-null元素的数组必须完全在构造时初始化。
但这在 .NET 中就更糟了,值类型是隐式初始化为 0 的。初始化的规则于是变成:
struct的所有字段必须是可空的。
但那样就入了鲍鱼之肆。它立刻用可空类型感染了整个系统。我的假设是可空性只有在可空类型不常见(比如 20%)的时候才真的有用。但这一下子就摧毁了这一点。
因此,我们走了消除自动 0-初始化语义的路。这是很大的一个变化。(C# 6 允许 struct 提供它们自己的无参构造方法,不过最终不得不放弃了,因为这对生态系统产生了巨大的影响。)这本来应该是有效的,但偏航太远了,并且引发了一些让我们可能要心烦意乱对付的问题。如果我可以重来一遍,我就会消除在 C# 中值类型和引用类型的区别。在即将写下的一个关于与垃圾回收作战的帖子中,我会更清晰地阐述这一点。
Non-null 类型的命运
我们有一个坚实的设计和几个原型,但从来没有在整个操作系统中部署下这个。原因是被绑在我们期待的跟 C# 兼容级别上。公平地说,我在这一点上说的比较含糊,我想着最终是我的决定。在 Midori 的早期,我们想要“熟悉的认知”。在项目的后期,我们实际上会考虑是否所有的这些特性会被作为对 C# “添加的”的扩展。正式这种后面的心态阻碍了我们认真去做 non-null 类型。我现在的想法是,只是加入注解(annotation)是行不通的;Spec# 使用 ! 来尝试了这样做却总是觉得搞反了。Non-null 需要是默认的以实现我们期望能造成的影响。
我最遗憾的是,我们在 non-null 类型上白等了那么久。仅在约定(contract)成为了一个已知的量,并且我们注意到数以千计的 requires x != null 充斥着各处,我们才认真探索了它(non-null 类型)。这将是复杂和昂贵的,然而如果我们同时去掉值类型的不同,这将是一个杀手级的结合。活到老学到老!
如果我们将我们的语言作为一个独立的不同于 C# 的东西发布,我确信这会胜出。
范围类型(Range Type)
我们曾有一个给 C# 添加范围类型的设计,但它总是超出我复杂度限制一步。
基本的设想是任一个数字类型都可以给出一个上下限的类型参数。例如,假设你有一个整数,只能容纳 0 到 1,000,000 的数字。它可以表示为 int<0..1000000>。当然,这也指出你可能应该使用 uint 而且编译器会警告你。实际上,完整的数字集合可以概念上通过范围这种方式表示:
typedef byte number<0..256>;typedef sbyte number<-128..128>;typedef short number<-32768..32768>;typedef ushort number<0..65536>;typedef int number<-2147483648..2147483648>;typedef uint number<0..4294967295>;// And so on ...
这真的很“酷” —— 但复杂得可怕 —— 的部分是然后就可以使用依赖类型来允许符号范围参数。例如,假设我有一个数组,并希望传递给它一个索引,这索引的范围是保证在边界内的。通常我会这样写:
T Get(T[] array, int index)requires index >= 0 && index < array.Length {return array[index];}
或者我可能使用 uint 来避免头一半的检查:
T Get(T[] array, uint index)index < array.Length {return array[index];}
有范围类型的话,我就可以将数字的上界跟数组的长度直接关联起来:
T Get(T[] array, number<0, array.Length> index) {return array[index];}
当然,如果你不知所谓搞砸了别名分析的话,就不会有对编译器会消除边界检查的保证。但我们希望,用这种类型不会比使用通常的约定检查干得更差了。而且不可否认,这种方法在类型系统中对信息的编码更加直接。
无论如何,我仍然把这一点归结为一个很酷的想法,不过它还是在“有是很好,但没有也没啥”的领域里。
由于类型系统中的 slice 成为了一等公民,“没有也没啥”就显得特别正确了。我会说,在使用范围检查的 66% 或更多的情况里,使用 slice 会干得更好。我认为大部分人仍然习惯使用范围检查,所以他们会写出标准的 C# 代码,而不是就使用 slice。我会在即将发布的文章中介绍 slice,但它删除了在大多数代码中写入范围检查的需要。
可恢复的错误:类型导向的异常(Type-Directed Exception)
当然,丢弃(Abandonment)不是唯一的一种。还有大量合理的情形,程序员可以合理地从发生的错误中恢复。例子包括:
- 文件 I/O
- 网络 I/O
- 解析数据(例如,一个编译器解析器)
验证用户数据(例如,一个 Web 表单提交)
在每一种这样的情况中,你通常不会像在遇到问题时触发丢弃。相反,程序会预料到它会一次次发生,并且需要做一些合理的事情来处理它。经常是通过跟某些人进行沟通:正在往一个网页中输入的用户、系统的管理员、使用某个工具的开发人员等等。当然,丢弃是一种很多情况下会考虑的适当的方法,但对于这些情形来说,它通常过于激烈了。而且,特别是对于 IO,这会让系统存在非常脆弱的风险。设想一下如果你正在使用的程序每当你的网络连接丢了一个包就毅然退出!
进入异常
我们对可以从中恢复的错误使用异常。不是那种
unchecked的异常,也不是就 Java 的那种checked的。首先的首先:虽然 Midori 使用异常,但一个没有进行
throws声明的方法永远都不会抛出一个异常,永远也不会。没有像 Java 中鬼鬼祟祟的RuntimeException。我们无论如何也不需要它们,因为对于 Java 中使用运行时异常的情况,Midori 中会使用丢弃。这造成了生成系统的一个神奇的属性。我们系统的 90-多% 的函数不会抛出异常!默认的,实际上,它们不会抛出异常。这跟像 C++ 这样的系统形成了鲜明的对比,在那你需要自行避免异常并使用
noexception来声明这点。当然,API 还是可能会因为丢弃而失败,不过只会在调用者没满足定义的约定是发生,跟传递了一个错误类型的参数类似。我们对异常的选择在一开始就有争议。我们在团队中有一个命令式的、过程式的、面向对象的以及函数式的语言角度的混合。C 程序员希望使用错误码并担心我们会重新造出一个 Java 的,或者更糟的,C# 的设计。函数式的角度是对所有的错误使用 dataflow,但异常是非常面向控制流的。最后,我认为我们选择的是我们在所有可用的可恢复性错误模型之间的一个很好的折衷。我们迟点就能看到,我们的确提供一种将错误作为头等值的机制,应对那些少有情形下,一种更为数据流的编程风格是开发人员想要的。
然而最重要的是,我们在这个模型下写了很多代码,并且它为我们工作的相当好。甚至函数式语言的家伙最终都皈依了。跟 C 程序员一样,感谢我们从返回码中获得的一些因素。
语言和类型系统
在某种程度上,我做了一个有争议的观察和决定。正如你不会在改动一个函数的返回值之后期待它没有带来兼容性影响一样,你也不应该在改变一个函数的异常类型时怀有这样的期望。用另一句话说,异常,跟用错误代码一样,只是另一种形式的返回值!
这是针对已检查异常的重复论证之一。我的回答听起来很老套, 但很简单: 太糟糕了。你使用的是静态类型的编程语言, 而异常的动态特性正是它们糟糕的原因。我们试图解决正是这些问题, 所以我们接受它, 美化强大的类型, 并且从不回头。仅此一项就有助于弥合错误代码和异常之间的鸿沟。
函数会抛出的异常成为其签名的一部分, 就像参数和返回值一样。请记住, 由于与丢弃相比,异常具有比较少出现的性质, 因此这并不像你想象的那么痛苦。许多直观的属性自然地从这个决定中流出。
第一件事是 Liskov 替代原则。为了避免 C++ 中发现的混乱,所有的“检查”必须在编译时静态地进行。因此,所有的那些在 WG21 论文提到的性能问题对我们来说都不是问题。然而,这个类型系统必须是刀枪不入的,没有后门可以摧毁它。因为在我们优化的编译器中,我们需要依赖 throws 声明来解决那些性能挑战,类型安全紧紧地铰接在这个属性上。
我们尝试了很多种不同的语法。在我们致力于改变语言之前,我们用 C# 的 attribute 和静态分析做了一切。用户体验不是非常好,而且很难那样达成一个真正的类型系统。此外,这也显得太费劲了。我们也实验了 Redhawk 项目的做法 —— 最终这项目变成了 .NET Native 和 CoreRT —— 然而,这种方法也没有利用语言,而是依赖静态分析,虽然它跟我们最终的解决方案共享了很多相似的原则。
最终语法的基本要点是简单将一个方法标记为 throws:
void Foo() throws {...}
(有许多年,我们实际上将 throws 放在方法的开头,但这样看起来不对劲。)
这样,替代问题就很简单了。一个 throws 的函数不能取代一个非 throws 函数的位置(非法的强化)。一个非 throws 的函数,在另一方面,可以取代一个 throws 方法的位置(合法的弱化)。这显然影响了虚拟重写(virtual override)、接口实现以及 lambda。
当然,我们做了同样预期的逆变替代。例如,如果 Foo 是 virtual 的,而你 override 了它但不会抛出异常,你就不需要声明 throws 协定。当然,任何通过虚拟调用这样方法的人不会用到这一点,但直接调用可以。
例如,这是合法的:
class Base {public virtual void Foo() throws {...}}class Derived : Base {// My particular implementation doesn't need to throw:public override void Foo() {...}}
而像下面这样实现的话,Derived 的调用者会使用缺乏 throws 的方式;而这是完全非法的:
class Base {public virtual void Foo () {...}}class Derived : Base {public override void Foo() throws {...}}
鼓励一种单一的失败模式是相当解放的。从 Java 的 checked 异常中带来的大量复杂性立刻就消失了。如果你查看大多数失败的 API,它们都有一个单一的失败模式(一种所有的 bug 都是通过丢弃完成的失败模式):IO 失败、解析失败等等。而且开发人员往往会编写的许多恢复操作实际上并不依赖于导致失败的精确的细节,譬如,进行一个 IO 操作。(有些的确会关注细节,对此 keeper 模式往往是更好的答案;很快我们会就这个主题讨论更多。)大部分现代异常中的信息实际上不是用于编程,而是用于诊断。
我们卡在用这种“单一的失败模式”上 2-3 年。最终我做了有争议的决定,支持多失败模式。这并不常见,但要求常常从团员那里合理地弹出来,而这些场景似乎是合理并有用的。它的确带来了类型系统复杂性的代价,但只在所有的平常的子类型化的方式中。而更复杂的场景 —— 例如中止(abort)(后面会谈更多)—— 要求我们这样做。
语法如下:
int Foo() throws FooException, BarException {...}
某种意义上,单个的 throws 是 throws Exception 的快捷方式。
如果你不关心的话,很容易就“忘记”了额外的细节。例如,你可能希望将 lambda 绑定到上面的 Foo API 中,但不希望调用方关心 FooException 或 BarException。当然,该 lambda 还是必须被标记为 throws,但不需要更多的细节了。这是一个非常常见的模式:内部系统会使用像这样类型化的异常来进行内部控制流和错误处理,但会在无需额外细节的公开 API 的边界上讲所有的这些异常转换为简单的 throws。
所有这些额外的键入给可恢复的错误增加了巨大的能力。但如果说约定超过了异常为 10:1,那么简单的 throws 异常方法超过了多个失败模式的方法为另一个 10:1。
这时,你可能会想,这跟 java 中的 checked 异常有什么区别呢?
- 最大份额的错误用丢弃来表达的事实意味着绝大部分的 API 不会
throw。 - 我们鼓励单一模式的失败的事实绝大地简化了整个系统。此外,我们让从多模式的世界更容易转化为单一模型,并转回去。
围绕弱化(weakening)和强化(strengthening)的丰富的类型系统支持也有帮助,我们所做的其他事情也帮主米和了返回代码和异常之间的鸿沟,改进了代码的可维护性,以及更多……
容易审计的调用点
故事行进到这里,我们仍然还没有完成关于错误代码的完全显式语法。函数的声明表示了它们是否会失败(好),但那些函数的调用方仍然还承接这静默的控制流(坏)。
这带来了关于我们异常模型我一直喜爱一些东西。一个调用点需要表达出 try:
int value = try Foo();
这调用了 Foo 函数,如果有错误发生就传播它,否则就将返回值赋予 value。
这有一个非常棒的性质:程序中所有的控制流都保持为显式的。你可以将 try 设想为一种有条件的 return(或者你愿意的话,有条件的 throw)。我真他妈喜欢它让审查代码的错误逻辑变得多么容易!举个例子,设想一个很长的有少数几个 try 在里面的函数;有显式的声明让失败的点,以及因此的控制流,跟 return 语句一样容易地辨认出来:
void doSomething() throws {blah();var x = blah_blah(blah());var y = try blah(); // <-- ah, hah! something that can fail!blahdiblahdiblahdiblahdi();blahblahblahblah(try blahblah()); // <-- another one!and_so_on(...);}
若你在编辑器中有语法高亮,那些 try 是粗大的蓝色显示,那就更好了。
这提供了很多返回代码中的好处,但完全没有包袱。
(Rust 和 Swift 现在支持一种类似的语法。我不得不承认我很伤心我们几年前没有吧这个公开到大众面前。它们的实现是很不同的,然而仍然可以认为这带来了巨大的信心,值得为它们语法进行投票。)
当然,如果你正在 try 一个上面这样的 throws 方法,有两种可能:
- 异常会逃逸到调用中的函数。
- 有一个围绕着的
try/catch块来处理错误。
第一种情况中,你需要也将你的函数声明为 throws。当然,是要传播被调用方声明的强类型的异常信息,还是只是简单地使用单个的 throws,这完全取决于你。
第二种情况中,我们当然理解所有的类型信息。因此,如果你视图捕获一些没有被声明为抛出的东西,我们会给你一个关于死代码的错误。这仍是跟经典的异常系统有争议的偏离。catch (FooException) 本质上是隐藏着一个动态类型测试,这总是困扰着我。你会默默地允许某个家伙调用只返回 object 的 API 然后自动的将返回值赋给一个带类型的变量吗?见鬼,不能!所以我们也不会让你在异常中这么搞。
这里 CLU 也影响了我们。Liskov 在 CLU 的历史中谈到这点:
CLU 的机制在对待未经处理的异常方面是不寻常的。大多数机制采用这种做法: 如果调用方不处理被调用过程引发的异常, 则会将异常传播到其调用方, 等等。我们拒绝了这种方法, 因为它不符合我们关于模块化程序构建的想法。我们希望能够调用一个程序, 只需知道它的规范, 而不是它的实现。但是, 如果异常是自动传播的, 则例程可能会引发其规范中未说明的异常。
即使这样我们也不鼓励大的 try 块,这在概念上是传播错误代码的捷径。要想知道我想说什么,请考虑你在用错误代码的系统中做的事,在 Go 中,你可能会像下面这样写:
if err := doSomething(); err != nil {return err}
在我们的系统,你这样写:
try doSomething();
但我们使用了异常!你可能会说,完全不同!当然,runtime 系统是不同的。但从语言的“语义学”角度来看,它们是同构的。我们鼓励人们从错误代码的角度来思考,而不是他们知道和喜爱的异常角度。这可能看起来很滑稽:为啥不干脆就用返回码呢?你会想。在接下来的部分,我会描述方案中的真同构部分,试图说服你我们的选择。
语法糖
我们还提供了一些用于处理错误的语法糖。try/catch 范围构造有点冗长了,特别是在你正遵循我们尽可能在本地处理错误的最佳实践时。对某些人来说它也还仍然存在某些 goto 感觉,特别是你正在从返回代码的角度考虑时。最终给出了一个我们称为 Result<T> 类型的方法,这类型要不是一个 T,要不是一个异常。
这实际上从控制流的世界过渡到了数据流的世界,应对某些后者更加自然的情形。虽然大多数开发人员选择熟悉的控制流语法,但两者肯定都有自己的位置。
为了说明常见的用法,假设你想记录所有发生的异常的日志,然后再传播异常。虽然这是一种常见的模式,使用 try/catch 块感觉有点过于控制流的沉重,就我的口味来说:
int v;try {v = try Foo();// 也许更多的东西。。。}catch (Exception e) {Log(e);rethrow;}// Use the value `v`...
那“也许更多的东西”引诱你将超出你应该做的东西挤压到 try 块里。将这跟使用 Result<T> 比较,有更多的“返回码感”并且更加方便进行本地处理:
Result<int> value = try Foo() else catch;if (value.IsFailure) {Log(value.Exception);throw value.Exception;}// Use the value `value.Value`...
这里的 try...catch 构造也允许你使用自己的值来做替代,或者甚至触发丢弃来作为失败的相应:
int value1 = try Foo() else 42;int value2 = try Foo() else Release.Fail();
通过将 T 成员的访问从 Result<T> 提升出来,我们也支持数据流错误的 NaN 风格。例如,假设我们有两个 Result<T>,想将他们加在一起。我可以这样做:
Result<int> x = ...;Result<int> y = ...;Result<int> z = x + y;
请注意第三行,那里我们将两个 Result<int> 加起来,生成一个 —— 是的 —— 第三个 Result<T>。这就是 NaN 风格的数据流传播,跟 C# 中新的 ?. 特性类似。
这种方法将异常、返回码、以及数据流传播优雅地混合了起来。
实现
我刚描述的模型不是必须使用异常来实现。它足够的抽象性可以合理地使用异常或者返回代码来实现。这不只是理论上可行,我们实际上试过了。而我们最终使用异常而不是返回码实现是因为性能原因。
为了说明返回码实现的工作方式,设想一些简单的转换:
int foo() throws {if (...p...) {throw new Exception();}return 42;}
变成:
Result<int> foo() {if (...p...) {return new Result<int>(new Exception());}return new Result<int>(42);}
以及这样的代码:
int x = try foo();
变成了一些更像这样的东西:
int x;Result<int> tmp = foo();if (tmp.Failed) {throw tmp.Exception;}x = tmp.Value;
优化的编译器可以更有效地表示这一点,消除过多地复制。特别是使用内联。
若你试图将 try/catch/finally 同样地建模,可能需要使用 goto,你立刻就能明白为什么编译器在优化 unchecked 异常时会那么困难。它们隐藏了控制流的边缘情况!
无论哪种方式,这个练习都非常生动地展示了返回代码的缺点。所有的那些粑粑 —— 原本很少会需要的(想一下,当然,失败是很少见的) —— 在热路径上,搞砸了你黄金路径的性能。这违反了我们最重要的原则之一。
我在我的上一篇文章中描述了我们两个模型的实验结果。概括来说,使用异常地方式在我们地关键基准中小 7% 并且快 4%。由于这些:
- 没有调用约定的影响。
- 没有将包装返回值和调用分支搅和在一起。
- 所有的会抛出的函数在类型系统中是已知的,允许更有灵活性的代码移动。
- 所有的会抛出的函数在类型系统中是已知的,给我们带来了新的 EH 优化,像将
try/finally块变为线性代码块,当try不会抛出异常的情况下。
还有异常的其他方面可以帮助提高性能。我之前提过我们没有像大多数异常系统那样深入调用点收集元数据。我们将诊断留给我们的诊断子系统。而且,另一种常用模式也带来了帮助,就是将异常作为冻结的对象缓存下来,以便每次 throw 无需进行内存分配:
const Exception retryLayout = new Exception();...throw retryLayout;
对于具有高 throw 和 catch 率的系统 —— 像我们的分析器、FRP UI 框架、以及另外的一些领域 —— 高性能是至关紧要的。这里的示例说明了为什么我们不能简单地学舌说“异常是很慢地”。
模式
我们在我们的语言和库中装饰了一些有用的模式。
并发
早在 2007 年,我就写了这篇关于并发和异常的帖子。我主要从并行、共享内存计算的角度来写它,然而在所有的并发调度模式中都存在类似的挑战。基本的问题在于异常实现的方式假设单一的、顺序的堆栈,并具有单一的错误模式。在并发系统中,你又很多的栈和很多的失败模式,其中 0、1 或者很多个可能会“同时”发生。
Midori 所做的一个简单的改进是确保所有地异常相关基础结构使用多个内部 error 处理相关情况。最少这不会让程序员被强迫决定扔掉第 1/N 个失败信息,而现在的异常系统往往如此。更进一步,我们的调度和栈收集基础结构根本上就知道仙人掌式的栈以及如何处理它们,归功于我们的异步模型。
一开始,我们没有支持跨越了异步边界的异常。然而最终,我们扩展了声明 throws 的能力以及可选的类型化异常的子句,使它们跨越异步进程边界。这给异步的 actor 编程模型带来了一个丰富的类型化的编程模型并感觉就像一个自然的扩展。这从 CLU 的继任者 Argus) 那里借鉴了不少。
我们的诊断基础结构美化了这点,给开发人员在他们的堆栈视图中全面查看跨进程的因果关系的调试体验。不是仅仅是高并发系统中的栈仙人掌,而且经常模糊在跨越进程消息传递的边界。可以这样调试系统可以节省大量的时间。
中止(Abort)
有时候一个子系统需要“立刻摆脱这个鬼地方”。丢弃是一个选项,但只会对 bug 做出反应。而且当然在进程中无法将它从轨道里停止。在知道栈中没有东西可以停止我们的情况下,如果我们想将调用点回退到某个地方,然后再在同一个进程中恢复并让它继续跑下去,我们需要做些什么呢?
异常跟我们这里想要的东西很接近了。但不幸的是,栈中的代码可以捕获触发中的异常,从而有效地忽略了中止。我们需要某种不会被忽略的东西。
进入中止。我们引入中止主要是为了支持我们使用函数式反应式编程(FRP)的 UI 框架,虽然这种模式有一些瑕疵。当一个 FRP 重新计算发生的时候,有可能有新的事件进入系统,或者做出了新的发现,使当前的计算无效。如果这种情况发生了 —— 通常发生在交错着用户代码和系统代码的计算的深度栈中 —— FRP 引擎需要快速地回到它的栈顶,在那它可以安全地开始重新计算。由于所有栈上的用户代码是纯函数的,在中途中止它是很容易做到的。不会留下错误的副作用。所有遍历的引擎代码都经过了仔细的审核和强化,归功于类型化的异常,以确保不变量的保持。
中止的设计从权能手册中借用了一页。首先,我们引入了一个叫 AbortException 的基类。它可以直接使用或者通过子类型使用。其中一个是特别的:没有谁可以捕获并且忽略它。这个异常会在任何尝试捕获它的 catch 块之后重新触发。我们称这样的异常为无可否定的。
但对于有人需要达成的中止。整个想法是从一个上下文中退出,而不是以丢弃的方式摧毁整个进程。而这就是能力进入画面的地方。下面是 AbortException 的基本构造:
public immutable class AbortException : Exception {public AbortException(immutable object token);public void Reset(immutable object token);// Other uninteresting members omitted...}
请注意,在构造时,就提供了一个不可变的 token;为了废除这次 throw,需要调用 Reset,而且必须提供一个相匹配的 token。如果 token 不匹配,就会发生丢弃。这个想法是,中止的抛出和意欲捕获部分通常是同一个,或者至少是互相串通的,这样互相安全地分享 token 是很容易做到的。这是实际中对象作为不可否定的能力的一个很好的例子。
是的,栈上的任意代码都可以触发一个丢弃,但那样的代码已经可以通过简单的对 null 解引用来这样做了。这个技术阻止在还没有准备好的中止上下文执行。
其他的框架也有类似的模式。.NET Framework 有 ThreadAbortException,它也是不可否定,除非你调用 Thread.ResetAbort;可悲的是,因为它不是基于权能的,所以需要一个笨拙的安全声明和宿主 API 来阻止意外的中止。经常这是未经检查的。
由于异常是不可变的,以及上面的 token 也是不可变的,一个常用的模式是将这些东西缓存到静态变量中,使用 singleton。例如:
class MyComponent {const object abortToken = new object();const AbortException abortException = new AbortException(abortToken);void Abort() throws AbortException {throw abortException;}void TopOfTheStack() {while (true) {// Do something that calls deep into some callstacks;// deep down it might Abort, which we catch and reset:let result = try ... else catch<AbortException>;if (result.IsFailed) {result.Exception.Reset(abortToken);}}}}
这种模式让中止非常高效。平均每次 FRP 重新计算会被中止多次。记住,FRP 是系统中 UI 的骨干,所以由于异常导致的缓慢是不可接受的。即使分配一个异常对象也是不幸的,因为随口会发生的 GC 压力。
可选使用的 “Try” API
我提到过一些失败后会导致丢弃的操作。包括分配内存、执行溢出或者除 0 的算术运算等。在一些这种例子中,一小部分适用于动态错误传播和恢复,而不是丢弃。即使在普遍情况下丢弃更好。
这形成了一个模式。不太常用,但它出现了。结果,我们有了一系列的运算 API,使用数据流风格的传播溢出、NaN、或者任何发生的事情。
先前我也已经提到了一个具体的例子,那是 try 一个新的内存分配的能力,当 OOM 发生,作为一个可修复的错误而不是丢弃。这非常罕见,但如果你想就可能会出现。比如说,为一些多媒体操作分配一个大的缓冲区。
守护者(Keeper)
我覆盖的最后一个模式被称为守护者模式。
在许多情况下,处理可恢复异常的方式是“由里而外”的。一堆代码被调用,将参数传递下调用栈中,直到最终达到一些认为当前状态不可接受的代码为止。在异常模型中,控制流然后被传播回调用栈,解开,直到找到一些代码来处理这个错误。在那时如果需要对操作进行重试,这一串的调用必须重新发起,等等。
另一种模式是使用守护者。守护者是一个了解如何“就地”从错误中恢复的对象,这样调用栈就不必被摊平开。相反,本来会抛出异常的代码会询问守护者,后者会指示代码如何继续。守护者的一个很好的方面是,当作为配置的能力完成时,周围的代码甚至不需要知道它们的存在 —— 不像在我们的系统中必须声明为类型系统的一部分的异常。守护者的另一个方面是简单而且低成本。
Midori 中的守护者可以被用于立即操作,但更经常用于跨越异步边界的操作。
守护者的典型示例是一个守护文件系统操作。访问文件和目录通常有以下失败模式:
- 非法路径。
- 未找到文件。
- 未找到目录。
- 文件使用中。
- 权限不足。
- 磁盘已满。
- 磁盘写保护。
一种方式是为每个文件系统 API 声明一个 throws 子句。或者像 Java 那样,对每一种情况创建一个 IOException 子类层次。另一种方式是使用守护者。这可确保整个应用程序不需要知道或者关心 IO 错误,从而使恢复逻辑集中起来。这样的一个守护者接口可能像下面一样:
async interface IFileSystemKeeper {async string InvalidPathSpecification(string path) throws;async string FileNotFound(string path) throws;async string DirectoryNotFound(string path) throws;async string FileInUse(string path) throws;async Credentials InsufficientPrivileges(Credentials creds, string path) throws;async string MediaFull(string path) throws;async string MediaWriteProtected(string path) throws;}
这里想法是,在每种情况下,当错误发生时,相关的输入被提供给守护者。然后守护者执行一个可能是异步的操作,来进行恢复。在很多情况下,守护者能够可选地返回更新后地参数用于操作。例如,InsufficientPrivileges 可以返回要使用地另外的 Credentials。(也许程序提示用户然后用户切换到一个有写访问权限的账号。)在上面的每一种情况中,如果守护者不想处理该错误,它可以抛出异常,虽然这部分的模式是可选的。
最后,我需要指出的是,Windows 的结构化异常处理(SEH)系统支持“可继续”的异常,这种异常在概念上试图实现同样的事情。他们让一些代码决定如何重启断裂的计算。不幸的是,它们是使用调用栈上的环境处理器实现的,而不是语言中的头等对象,所以相对于守护者而言,远没有那么优雅,而且易于出错。
未来方向:影响类型化(Effect Typing)
大多数人问我们,存在作为类型系统属性的 async 和 throws 是否分裂了类库的整个统一性。答案是“不,不见得。”但在高度多态的类库代码中的确是痛苦的。
最不顺的例子是像 map、filter、sort 等等的组合。在这些情况下,你通常有任意的函数并希望那些函数的 async 和 throws 属性透明地“流过”。
我们用于处理这个的设计是让你将影响参数化。作为例子,这里有一个统一的映射方法 Map,它传递函数参数中 async 或 throws 影响:
U[] Map<T, U, effect E>(T[] ts, Func<T, U, E> func) E {U[] us = new U[ts.Length];for (int i = 0; i < ts.Length; i++) {us[i] = effect(E) func(ts[i]);}return us;}
请注意我们有一个普通的通用类型 E,除了它是通过关键字 effect 前缀声明。然后我们使用 E 来象征性地代替 Map 签名地效果列表,除了调用 func 函数时在“传播位置”通过 effect(E) 来使用它。这是一个相当繁琐的替换练习,用 throws 代替 E 和用 try 代替 effect(E),来了解逻辑转换。
一个合法的调用像这样:
int[] xs = ...;string[] ys = try Map<int, string, throws>(xs, x => ...);
请注意,throws 流经了函数,因此我们得以传递一个 throws 异常的回调。
作为一个整体,我们讨论要将这个更进一步,并允许程序员声明任意的影响。我以前就假设过这样的系统。然而我们担心的是,这种高阶编程可能需要不必要的聪明并且难以理解,不管多么强大。上面的简单模型可能是甜区,如果给我们更多几个月的话,我们可能已经将它完成了。
回顾及总结
我们已经走到了这个特别旅程的终点。正如我在一开始所说的,一个相对可预测和温和的结果。但我希望所有的这些背景能够帮助你了解我们在分类整理错误画卷上的进化。
简要地说,最终模型有如下特性:
- 一个承担细粒度隔离以及从失败中的恢复性的架构。
- 区别出 bug 和可恢复的错误。
- 使用
contract、assertion以及通常对于所有的 bug 使用abandonment。 - 对于可恢复错误,使用精简版的
checked异常模型,具有丰富的类型系统和语法。 - 采用一些有限制的返回码的优点 —— 例如就地检查 —— 提高可靠性。
而且,虽然这是一个多年的旅程,还是有直到我们项目早夭时我们还一直积极改进的领域。我将它们分在不同的类别是因为我们没有足够的使用它们的经验来声称它们已经成功了。我本来希望如果更干得更久一点,我们就已经将它们的大部分整理好并发布了。特别地,我希望将这个放到最终的模型目录中:
- 默认使用
non-null类型以消除一大批的可空性声明。
丢弃(Abandonment)以及我们使用它的程度,在我看来是我们在这错误模型中最大和最成功的赌注。我们经常在很早期就发现 bug,在它们最容易被诊断和修复的时候。基于丢弃的错误的数量超过可恢复的错误的比率接近 10:1,使 checked 异常很罕见让开发人员可以容忍。
虽然我们从来没机会发布这个,我们已经把这些经验教训带到了其他地方。
例如,在从 IE 重写微软 Edge 浏览器的过程中,我们在几个领域里采用了丢弃。关键的一个,由一个 Midori 工程师提供的,是 OOM。像我之前描述的那样,旧的代码会尝试蹒跚而行而几乎总是将事情搞砸。我的理解是丢弃已经找出了很多潜在的错误,跟我们经常干的将现有代码移植过来到 Midori 中的经历一样。最重要的是,丢弃更多是一种架构上的规则,可以在编程语言中用于修正现有的代码库。
细粒度隔离的架构基础是至关重要的,然而很多系统都有关于这种架构体系的非正式的概念。OOM 丢弃在浏览器中运行得不错的一个原因是,大多数浏览器已经将分离的进程应用到各个 tab 页上了。浏览器在很多方面模仿了操作系统,在这里我们也看到了这种行为。
最近,我们一直在探索一些提议,将这一规则的一部分 —— 包括约定 —— 带到 C++ 中。也有将其中的一些特性也带到 C# 中的具体提议。我们正在积极地对一个将一些 non-null 检查带到 C# 的提议进行迭代。我不得不承认,我希望所有的这些提议都是最好的,然而没有什么能够跟整个栈都用同样的错误规则实现那样刀枪不入。而且得记住,整个隔离和并发模型对于大规模的丢弃是必不可少的。
我希望继续分享知识能让这些想法更广泛地被采用。
而且当然,我已经提到过,Go、Rust 和 Swift 此时已经给这个世界带来了一些非常好的适合系统的错误模型。我可能或多或少显得有点傻气了,但现实情况是它们已经是超过我们开始 Midori 旅程时的那个世界了,拥有了我们当时在业界未曾有的东西。现在是一个系统程序员的好时代!
下次我会更多谈论关于语言的事情。特别地,我们会看到 Midori 如何使用架构、语言支持以及类库的灵丹妙药来驯服垃圾回收器。我希望很快就再见到你!

若有收获,就点个赞吧
0 人点赞
