文档内容基于 B 站视频: https://www.bilibili.com/video/BV1nJ411V7bd 数据结构以及算法的代码实现: https://github.com/BlckKn1fe/Data-Structure-and-Algorithm
第二章的内容都是关于线性表
2.1 定义和特点
线性表是具有相同特性的数据元素的一个有限序列
线性表特征:
- 起始节点:没有直接前驱,只有一个直接后继
- 终端节点:没有直接后继,只有一个直接前驱
- 其他节点:只有一个直接前驱和一个直接后继
2.2 案例引入
(略)
2.3 线性表数据类型定义

数据对象:a 可以表示不同的数据类型,i 为下标
数据关系:前驱和后继关系
基本操作:增删改查,排序,反转等(这些操作也就是所谓的算法)
(基本操作通常有初始条件和操作结果,这里省略)
顺序表在机器内存中的物理状态,就是线性表(逻辑结构)的一种实现(物理结构)
- 地址连续
- 以此存放
- 随机存取

- 类型相同
我们可以使用高级语言已经实现的数据类型,来描述这种储存结构:数组
2.4 线性表的实现(顺序表)
#define MAXSIZE 100typedef struct {ElementType *elem;int len;} SqList;
(基于数组 Array)

绿色部分就是储存元素的数组,蓝色部分来记录储存的元素个数
(对线性表的基本操作实现参考原视频,比如增删改查,初始化,销毁,清空等操作)
操作 ArrayList:
- P17 [11:35] (初始化,摧毁,清空,求长,判断空,取值
- P18(按值查找)
- P19(插入元素)
- P20(删除元素)
时间复杂度:
查找、插入、删除的平均时间复杂度都是 
空间复杂度:
由于不需要辅助空间,所以空间复杂度 
优点:
- 储存密度大(这里的密度指的是,数据元素本身所占的存储量 / 节点结构所占存储量的比值。对比链表来说,链表的节点结构内除了需要储存数据元素本身,还需要存前驱和后继的地址,储存密度就会比顺序表的密度要小)
- 可以随机存取表中任意元素,随机存取法
缺点:
- 插入、删除某一元素时,需移动大量元素
- 浪费储存空间(通常定义的比较大,防溢出)
- 数组大小无法动态修改
2.5 线性表的实现(链表)
链表实现线性表的表现形式:
- 用一组物理位置任意的储存单元来存放数据元素
- 储存单元可连续,也可以不连续
- 元素的逻辑次序和物理次序可以不同
(单)链表中的每个节点由两个部分组成:
- 数据域:存储元素数值
- 指针域:存储直接后继节点的内存地址
(双链表和循环链表略)

其中的头结点可有可无,对于它存在的好处:
特点:
- (综合 表现形式 的 1 和 2)
- 访问时只能通过头指针进入链表,然后一个接着一个依次向后,这种方式也叫顺序存取法
定义这种单链表:
typedef struct Lnode {ElemType data;struct Lnode *next;} Lnode, *LinkedList;
操作 LinkedList:(以下都是单链表)
- P24[0:00] 链表初始化
- P24[6:55] 判断链表是否为空
- P25 销毁链表
- P26 清空链表
- P27 求链表长度
- P28[7:15] 获取链表第 i 个元素
- P29 查找
- P30 插入
- P31 删除第 i 个元素
- P33 头插法建立单链表
- P34 尾插法建立单链表
时间复杂度:
查找,插入,删除的时间复杂度都是
2.6 循环链表
(单向)循环链表就是把单链表的的最后一个元素的指针域(next)指向单链表的第一个元素上,让链表形成一个环的形状
通常,循环链表中的一些操作,是在尾指针开始的,因为:
 的储存位置是 tail -> next ->next (有头节点的情况)
的储存位置是 tail -> next ->next (有头节点的情况) 的储存位置就是 tail 这个位置
的储存位置就是 tail 这个位置
他们的时间复杂度都是 
如果是用头指针的话,找 虽然是
虽然是  ,但是找
,但是找 就是
就是 了
了
2.7 双向链表
双向链表:在单链表的每个节点里,再添加一个指针域 previous,该指针指向其直接前驱
typedef struct Node {Elemtype data;struct Node *prev, *next;} Node, *LinkedList;
双链需要注意的是,插入和删除操作和单链有区别,(不写具体代码的实现了,举一反三),具体操作上看下图:
插入操作: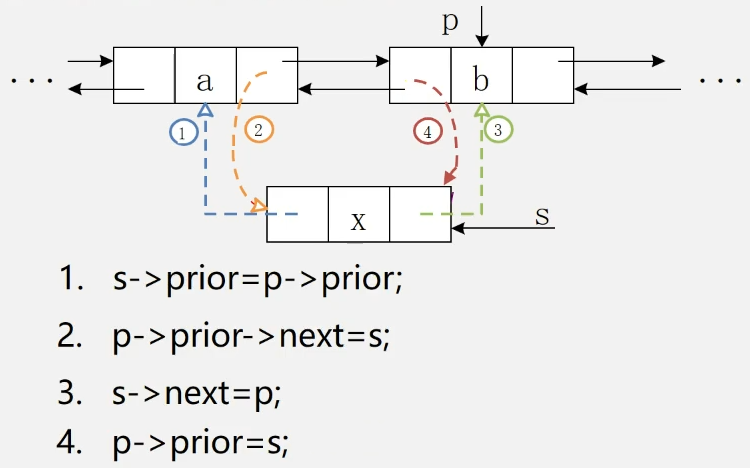
删除操作: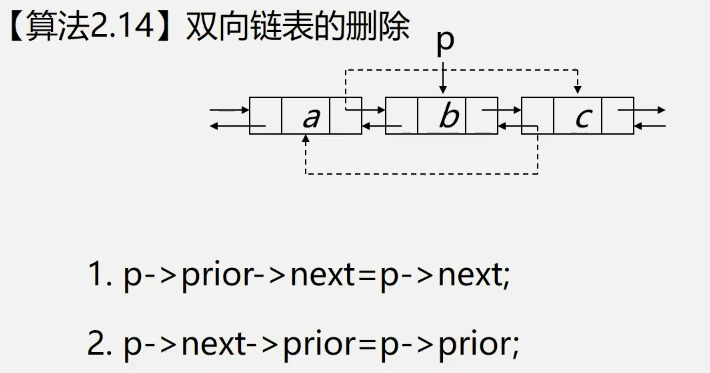
2.8 顺序表和链表比较


若有收获,就点个赞吧
0 人点赞
