前情提要
十五章中提到,计算机系统存在两类不同的数据处理工作:操作型处理和分析型处理,也称作联机十五处理(OLTP)和联机分析处理(OLAP)。
xxx
数据仓库技术
概述
数据仓库是为了构建新的分析处理环境而出现的一种数据存储和组织技术。
操作性数据和分析型数据的区别
| 操作型数据 | 分析型数据 |
|---|---|
| 细节的 | 综合的,或者提炼的 |
| 在存取瞬间是准确的 | 代表过去的数据 |
| 可更新 | 不可更新 |
| 操作需求事先可知道 | 操作需求事先不知道 |
| 生命周期符合软件开发生命周期(SDLC) | 完全不同的生命周期 |
| 对性能的要求高 | 对性能的要求宽松 |
| 一个时刻操作一个元组 | 一个时刻操作一个集合 |
| 事务驱动 | 分析驱动 |
| 面向应用 | 面向分析 |
| 一次操作数据量小 | 一次操作数据量大 |
| 支持日常操作 | 支持管理决策需求 |
数据仓库的基本特征
- 主题与面向主题
数据仓库中的数据是面向主题进行组织的。
- 数据仓库是集成的
数据仓库的数据是从原有的分散的数据库数据中取来的,因此数据库在进入数据仓库之前必燃要经过加工与集成,统一与综合。
- 数据仓库是不可更新的
数据仓库主要拱决策分析之用,所涉及的数据操作主要是数据查询,一般情况下并不进行修改操作。
- 数据仓库是随时间变化的
数据仓库中数据不可更新,是指数据仓库的用户进行分析处理时是不进行数据更新操作的,但并不是说在数据仓库的整个生命周期中数据集合是不变的。
数据仓库中的数据组织
数据仓库中的数据分为多个级别:早期细节级、当前细节级、轻度综合级和高度综合级。
物理结构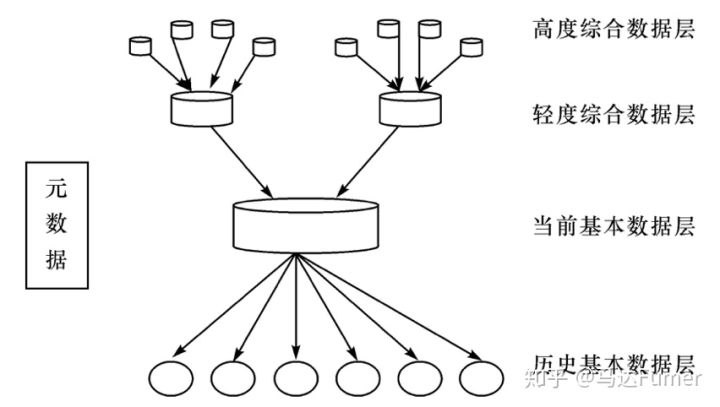
数据仓库系统的体系结构
由数据仓库的后台工具、数据仓库服务器、OLAP(联机分析处理)服务器和前台工具组成。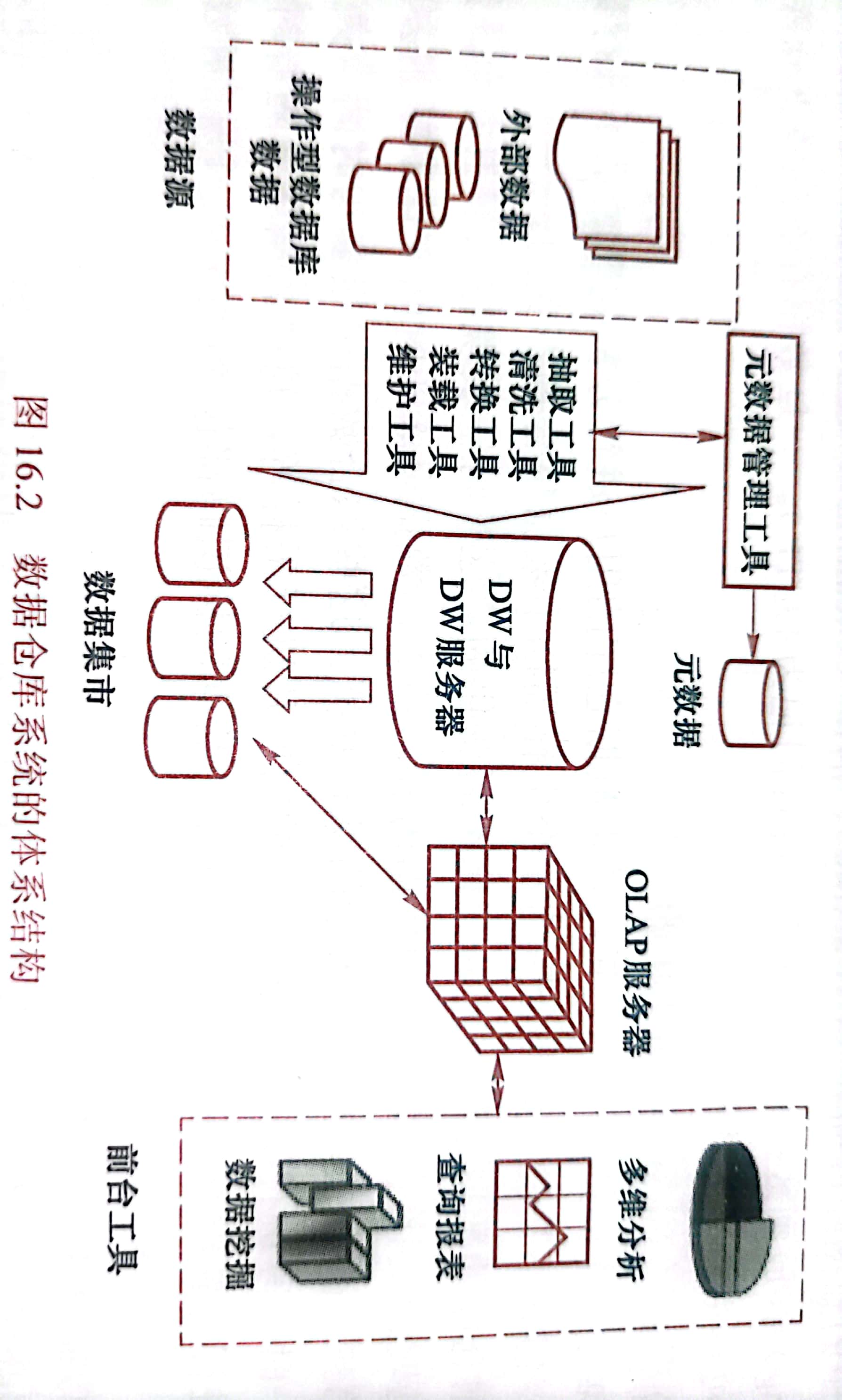
- 数据仓库的后台工具
包括数据抽取、清洗、转换、装载和维护工具,简记为ECTL工具或者ETL工具。
- 数据仓库服务器
相当于数据库系统中的数据库管理系统,它负责管理数据仓库中数据的存储管理和数据存取,并给OLAP服务器和前台工具提供存取接口(如SQL查询接口)。
x
- OLAP服务器透明地为前台工具和用户提供多维数据视图。用户不必关心它的分析数据(即多维数据)到底存储在什么地方,是怎么存储的。
前台工具包括查询报表工具、多维分析工具、数据挖掘工具和分析结果可视化工具等。
联机分析处理技术
联机分析处理是以海量数据为基础的复杂分析技术。联机分析处理支持各级管理决策人员从不同角度,快速灵活地对数据仓库中的数据进行复杂查询和多维分析处理,辅助各级领导进行正确决策,提高企业竞争力。
多维数据模型
多维数据模型是数据分析时用户的数据视图,是面向分析的数据模型,用于给分析人员提供多种观察的视角和面向分析的操作。
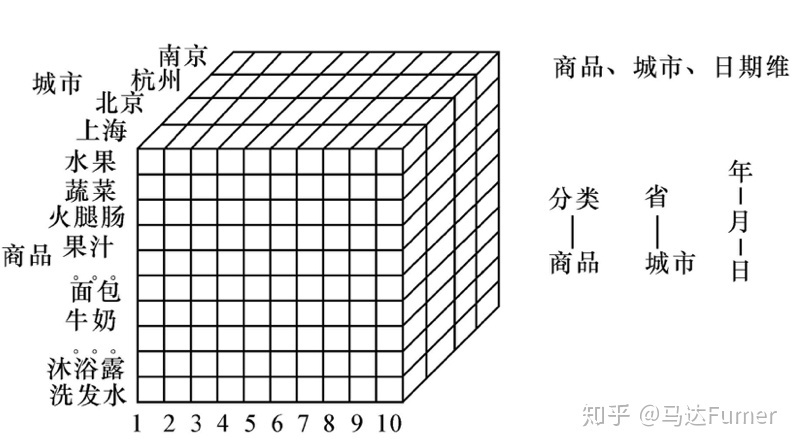
多维分析操作
常用的联机分析处理多为分析操作有切片、切块、旋转、向上综合、向下钻取等。
联机分析处理的实现方式
联机分析处理服务器透明地为分析软件和用户提供多维度数据视图,实现对多维数据的存储、索引、查询和优化等功能。联机分析处理服务器一般按照多维数据模型的不同实现方式,分为MOLAP结构、ROLAP机构、HOLAP结构等多种结构。
MOLAP结构
ROLAP结构
星形模式
雪片模式
HOLAP结构则是MPLAP和ROLAP的混合结构。
联机分析处理软件提供的是多维分析和辅助决策功能,对于深层次的分析和发现数据中隐含的规律和只是,则需要数据挖掘(DM)技术和相应的数据挖掘软件来完成。数据挖掘技术
数据挖掘的概念
数据挖掘是从大量数据中发现并提取隐藏在内的、人们实现不知道的但又可能有用的信息和知识的一种新技术。
数据挖掘的目的是帮助决策者寻找数据间潜在的关联,发现经营者忽略的要素,而这些要素对预测趋势、决策行为也许是十分有用的信息。
数据挖掘技术涉及数据库、人工智能、机器学习、统计分析等多种技术,它使决策支持系统跨入了一个新阶段。数据挖掘和传统分析方法的区别
数据挖掘是在没有明确的假设的前提下挖掘信息,发现知识。
- 数据挖掘所得到的信息应该具备先前未知,有效和可实用三特征。
没有假设前提,挖掘出的数据越是出乎意料的,越可能有价值。
例如一家连锁店通过数据挖掘发现小孩尿布和啤酒之间的销售模式有着惊人的联系。
我们去沃尔玛超市会发现一个很有趣的现象:货架上啤酒与尿布竟然放在一起售卖,这看似两者毫不相关的东西,为什么会放在一起售卖呢? 原来,在美国,妇女们经常会嘱咐她们的丈夫下班以后给孩子买一点尿布回来,而丈夫在买完尿布后,大都会顺手买回一瓶自己爱喝的啤酒(由此看出美国人爱喝酒)。商家通过对一年多的原始交易记录进行详细的分析,发现了这对神奇的组合。于是就毫不犹豫地将尿布与啤酒摆放在一起售卖,通过它们的关联性,互相促进销售。“啤酒与尿布”的故事一度是营销界的神话。

上例中利用数据挖掘中的关联规则(从大量数据中找出两个对象的关联性)进行信息挖掘,事先并没有任何假设和前提,只是从一年多的原始交易记录中分析得出这对神奇的组合(出乎意料的组合)。
数据挖掘的数据源
两种来源:
- 数据仓库
- 数据库
在实际的应用数据往往是不完全、有噪声的、模糊的、随机的、因此要根据不同的需求在挖掘之前完成预处理。
而数据仓库中的数据已经经过了预处理,从数据仓库中获取数据会方便许多。许多数据不一致的问题得到了较好解决,减少了数据挖掘中清洗数据的工作量。
为了数据挖掘也不必非得建立一个数据仓库。建立一个巨大的数据仓库是一个巨大的工程,消耗大量的时间。如果只是为了数据挖掘,可以把一个或者几个联机分机处理数据库导入到一个只读的数据库中,然后在上面进行数据挖掘。
所有的数据还要再次进行选择,具体的选择方式与任务有关。挖掘的结果需要评价是否有用。按照评价,数据还需要反馈到不同阶段,重新分析。
数据挖掘的功能


若有收获,就点个赞吧
0 人点赞
