public class KafkaConsumerEx {public static void main(String[] args) {Properties props = new Properties();// 必须设置的属性props.put("bootstrap.servers", "localhost:9092");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("group.id", "kirby_group");// 可选设置属性props.put("enable.auto.commit", "true");// 自动提交offset,每1s提交一次props.put("auto.commit.interval.ms", "1000");props.put("auto.offset.reset","earliest");props.put("client.id", "kirby_client_id");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅test1 topicconsumer.subscribe(Collections.singletonList("dove_1"));while(true) {// 从服务器开始拉取数据ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));records.forEach(record -> {System.out.printf("topic = %s ,partition = %d,offset = %d, key = %s, value = %s%n", record.topic(), record.partition(),record.offset(), record.key(), record.value());});}}}
Client
主流程 sendFetches → poll → fetchedRecords
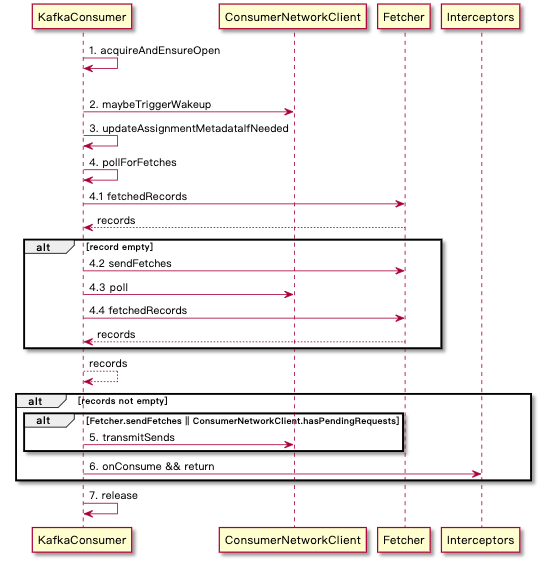
- 组件介绍
- ConsumerNetworkClient: 处理 Consumer 请求响应的网络层
- Fetcher: 管理关联 Brokers 的拉取处理流程。这针对心跳消息的处理是可以交给多个线程,但是对于其他响应处理只能由 consumer 单线程处理。
- 如果一个 ResponseHandler 访问任何 Fetcher 的共享状态(比如 FetchSessionHandler ),所有的访问必须是在 Fetcher 实例上是互斥的
- 如果一个 ResponseHandler 访问任何 coordinator 的共享状态(比如 SubscriptionState) ,那必须假定所有访问必须在 coordinator 实例上是互斥的
- 有部分需要通过多个 broker 收集得到的响应(比如 list offsets)会在 response future 实例上互斥。
- 对于每一个节点(node)在任何时间只能保证最多一个 request 是出于 pending 状态的。出于 pending 的请求将会被追述直到响应被处理之后再去更新其状态。这保证了更新状态将对任何线程都是可见的。
- ConsumerInterceptors: Consumer 拦截器容器,通过 interceptor.classes 配置可注册。实现参考 ConsumerInterceptor
- 关键步骤
- Fetcher.sendFetches → ConsumerNetworkClient.poll → Fetcher.fetchedRecords 共同构成的通过 ConsumerNetworkClient 向 Broker 发送请求然后获取响应的流程
细节
细节
ConsumerNetworkClient.send流程中存在对于wakeup是的后续poll不阻塞FetchRequest关键属性- data
- replicaId
- maxWaitMs
- minBytes
- maxBytes
- isolationLevel
- forgottenTopicsData: 仅在 version > 13 生效
- topics
- partitions
- partition
- currentLeaderEpoch
- lastFetchedEpoch
- fetchOffset
- LogStartOffset
- partitionMaxBytes
- partitions
- apiKey: FETCH
- version: 客户端版本信息
- metadata
- sessionEpoch:
- sessionId:
- data
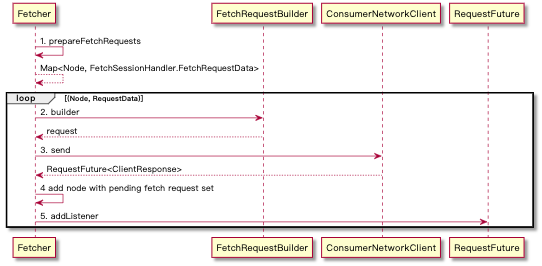
listener 针对响应的每个 partition 分别获取消息并放入到 CompleteFetchesQueue 中,依赖于 ConsumerNetworkClient.poll 响应返回之后触发(这一步直接影响到后续的 Records 组装),流程如下: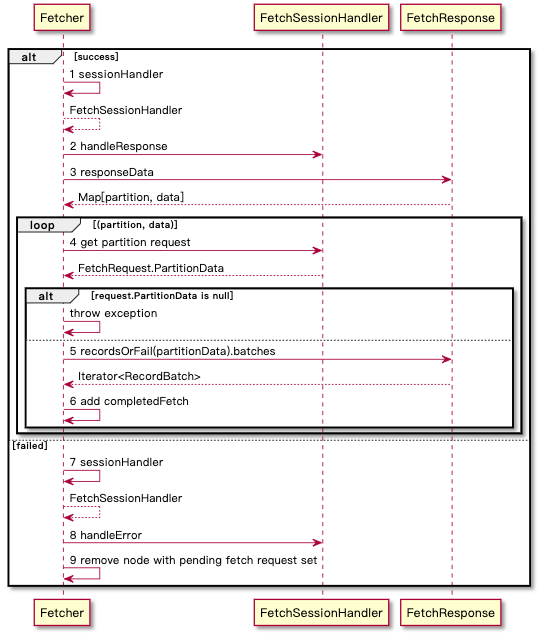
ConsumerNetworkClient.poll: 通过网络发送 ClientRequest 在通过 poll(0) 来得到结果
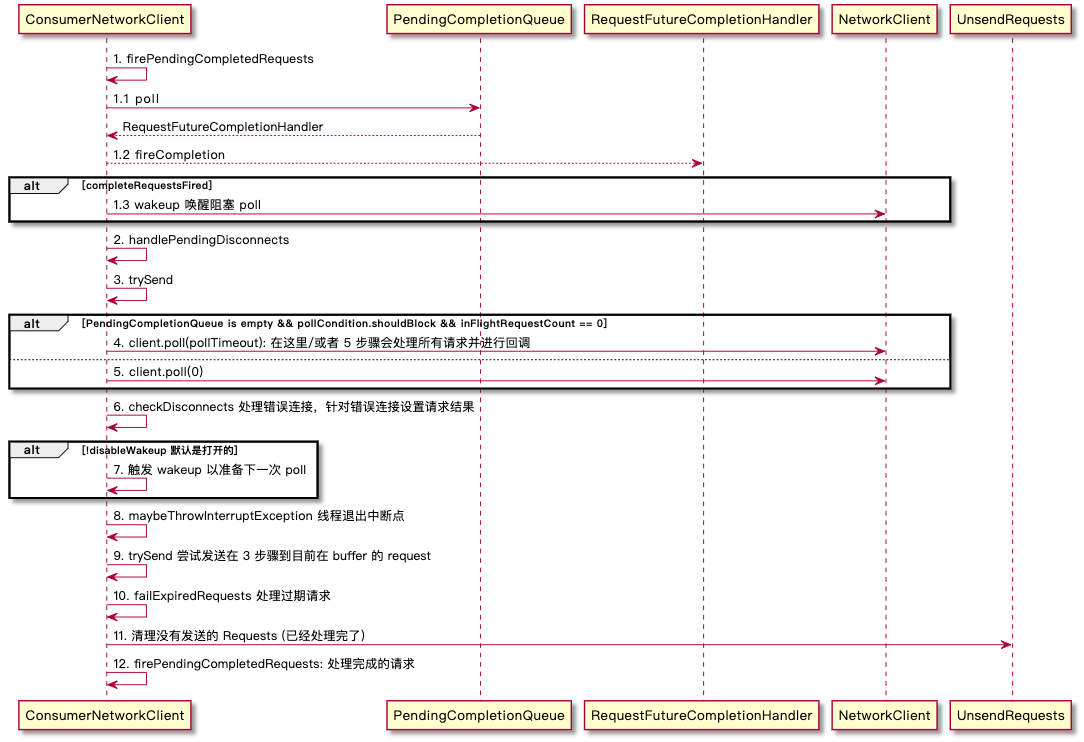
需要说明的是 4/5 不存在的差别实际只为了区分阻塞和非阻塞场景,如果现在没有已经完成的请求在等待被处理也没有未完成的请求发送中,就进行阻塞操作。
poll(0)之所以是非阻塞的是调用了 JDK 中的Selector.selectorNow()来实现的- poll 方法与之前分析
Porducer一样会最终回调ClientResponse中的 callback,在这个场景下 callback =RequestFutureCompletionHandler - 在每次
ConsumerNetworkClient.poll方法头尾都会调用RequestFutureCompletionHandler的 fire 方法将ClientResponse设置到预置的 Future 返回上层方法(ConsumerNetworkClient.send)Fetcher.fetchedRecords: 组装消息并更新消费位点。
从 CompleteFetchesQueue 队列中取出 records(bytes) 并组装成 Map
completedFetches是怎么进入的?在网络响应返回后通过上述流程触发到达Fetcher#sendFeture中设置的 Listener,如果成功了就会将 Response 进行解析放入completedFetches中(上文也有过描述)- 从 Server 得到的 Record 包含多个 partition 的数据,而 Kafka 会以一个 HashMap 来返回给到调用方。如果在内部有序的话可能可以通过有序字段加上
ConsumerInterceptors来实现。Server
与之前介绍 Producer 一样,入口直接看 KafkaApis 的 handler 方法中对应的 handleFetchRequesthandleRequest 核心方法是 ReplicaManager#readFromLocalLog
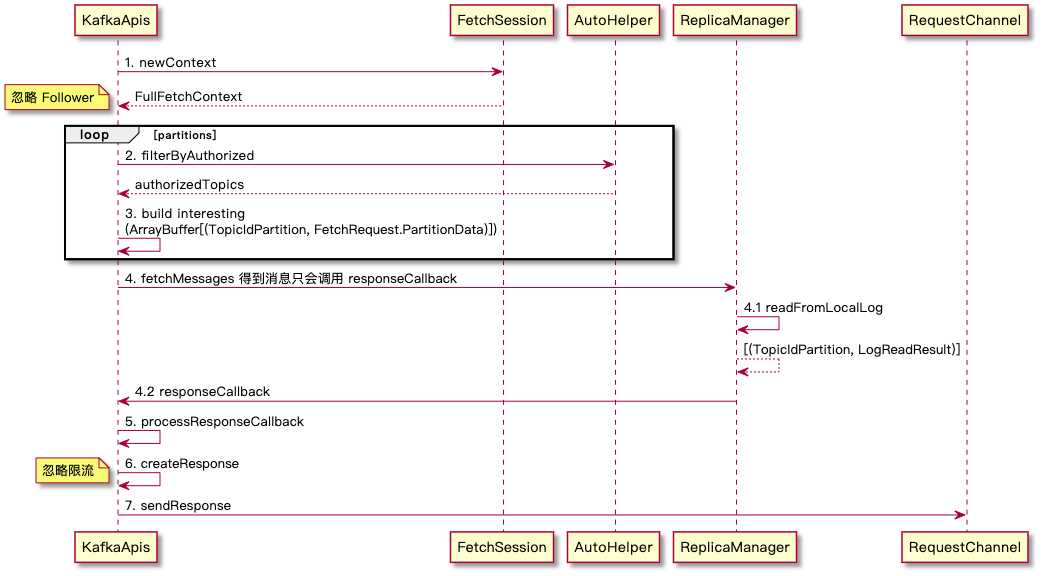
readFromLocalLog → Partition#readRecords → LocalLog#read → LogSegment#read

若有收获,就点个赞吧
0 人点赞
