
在数据库和大数据领域,通过SQL中的JOIN连接将两个及两个以上的表(或中间表、视图、物化视图)中的数据 按指定的连接条件关联起来,是很常用也很方便的操作。 我们前面学习了JOIN有多种常见连接方式如内连接INNER JOIN、左外连接LEFT JOIN等,今天来学习一下连接操作具体是如何实现的,有哪些常见的连接算法。
首先说明一下容易让人犯迷糊的概念:Join的连接方式通常也叫做连接类型 Join Types,而Join的连接算法则称为连接方法 Join Methods。 为了方便叙述,先假设一个连接场景:有a、b两个表,分别有Ra、Rb 行数据,使用一个等值连接条件做内连接,即 a JOIN b ON a.c1 = b.c2。
嵌套循环连接 NESTED LOOP JOIN
嵌套循环连接 NESTED LOOP JOIN 简称NLJ,顾名思义,他就是一个两层的循环,有简单版本和几个优化的变种。
NESTED LOOP JOIN示意图,图源见水印。
Simple Nested Loop Join
简单嵌套循环连接 Simple Nested Loop Join是最简单的一种连接实现算法,外层循环遍历a表,内层循环则遍历b表,如果满足连接条件,则组合两个表的列输出,最终生成连接后的临时表。 这种连接算法效率比较低下,其复杂度表示为: O(Ra * Rb)。 伪代码如下:
for aRow in afor bRow in bif aRow.c1 equals bRow.c2combine aRow and bRowoutput abRow
Index Nested Loop Join
索引嵌套循环连接 Index Nested Loop Join的优化思路是利用索引减少内层表的循环次数,通过外层表的匹配列的值直接与内层表匹配列的索引进行匹配,再遍历匹配上的记录进行匹配、合并、输出。该算法避免和内层表的每条记录去进行比较,需要内层表的匹配列存在索引,复杂度可表示为: O(Ra * b表索引高度)。 伪代码如下:
for aRow in afind bRows by index b.c2 with value aRow.c1for bRow in bRowsif aRow.c1 equals bRow.c2combine aRow and bRowoutput abRow
Block Nested Loop Join
分块嵌套循环连接 Block Nested Loop Join(简称 BNL)的优化思路是利用缓存减少内层表的循环次数,通过缓存外层表的多条数据到Join Buffer里(通常是个HASH表),然后批量与内层表的数据进行匹配、合并、输出。当内层表的匹配列不存在索引时可以使用Block Nested Loop Join,复杂度可表示为: O(a表的Buffer个数 * Rb),其中Buffer个数为表中全部数据加载到内存需要的内存页数量 / 可用于缓存的内存能容纳的内存页的个数 。 伪代码如下:
var joinBuffersfor aRow in aif joinBuffers not fulladd aRow to joinBufferselsefor bRow in bRowsfind aRow in joinBuffers and if aRow.c1 equals bRow.c2combine aRow and bRowoutput abRowclean joinBuffers
Batched Key Access Join
批量索引访问连接Batched Key Access Join(简称BKA)是结合了分块嵌套循环连接 Block Nested Loop Join 和索引嵌套循环连接 Index Nested Loop Join两种方案的优点,通过先对外层表数据做攒批再批量查询,内层表的索引的方式进一步提高效率,复杂度可表示为: O(a表的Buffer个数 * b表索引高度)。
排序合并连接 SORT MERGE JOIN
排序合并连接SORT MERGE JOIN 也是嵌套循环连接 NESTED LOOP JOIN 的一种变体。 该算法要求连接中的两个数据集有序,如果数据集尚未排序,则需要先对它们进行排序,这就是SORT操作。对于第一个数据集中的每一行,在第二个数据集中找到一个起始行,该起始行为前一次迭代中的到达的位置,然后读取第二个数据集,直到找到一个不匹配的行时停止,再对第一个数据集中的下一行进行相同的操作,这就是MERGE 操作。
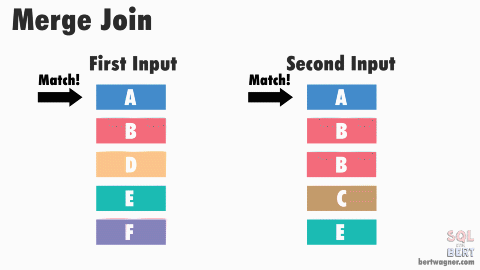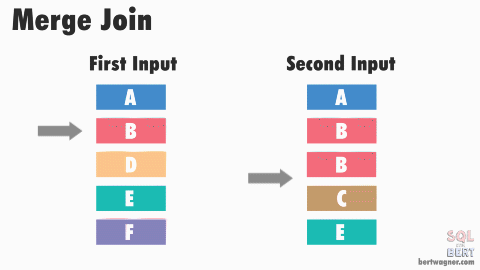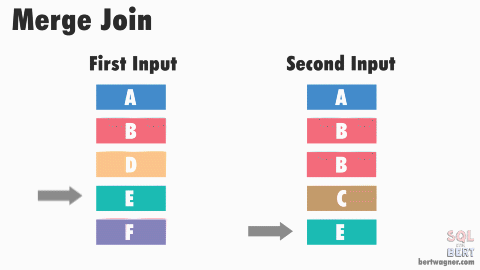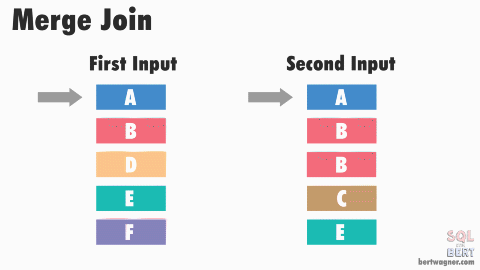
SORT MERGE JOIN示意图,图中的两个数据集都是排序后的,图源见水印。
哈希连接 HASH JOIN
哈希连接 HASH JOIN 使用两个表(数据集)中较小的一个连接键上构建内存中的哈希表,然后遍历更大的表(数据集),探测哈希表以找到满足连接条件的行。其中构建内存哈希表的数据集成为构建表(Build Table),而用来探测的表称为探测表(Probe Table)。
HASH JOIN示意图,图源见水印。
简单哈希连接
当构建表中数据量较小,小到足以放入内存哈希表中时,HASH JOIN效率最高,相当于只分别读取了一次连接的两个表,复杂度可表示为: O(Ra + Rb)。当构建表不足以全量放入内存哈希表时,需要用到接下来介绍的几种优化方案。
分批哈希连接
将构建表中的数据分批,构建多批哈希表,每一批再遍历探测表;该方案和前面的Block Nested Loop Join类似,复杂度也一样。
哈希桶溢出磁盘连接
首先,对构建表进行完整扫描,对连接列做哈希后首先尝试放入内存哈希表,如果内存表满了则将内存哈希表中当前最大的桶的数据放入磁盘上的临时空间,新的行如果属于该最大的桶则直接写入临时空间中的对应桶,否则写入内存表中对应的桶;最中可能会有多个桶存储在磁盘上,剩下的桶存储在内存中。
然后,遍历读取探测表,用相同的哈希函数计算连接列的哈希,探测内存哈希表中是否存在该哈希对应的桶,如果存在则和内存中的数据做连接并返回即可,否则对应桶是在磁盘中,用上面相同方式将该数据存放在磁盘上的单独探测表的桶中。
最后,逐一读取磁盘上临时空间中探测表的数据桶,并和磁盘临时空间中构建表对应的数据桶中的数据进行连接后返回,复杂度可以表示为: O(Ra + Rb + 溢出到磁盘的a表行数 + 溢出到磁盘的b表行数)。如果可以并发执行各个桶的连接操作将会有更快的效率。
分布式哈希连接
对于支持多节点并发计算的系统,可以将构建表和探测表的数据都按连接条件做哈希进行分区,然后发送到多个计算节点上分别对每个分区的数据进行连接操作,最后再合并各节点的连接结果。
分布式哈希优化可以利用多个节点的内存,而不需要或者只有很少量数据需要将构建表的数据溢出到磁盘上,同时可以充分利用多节点的CPU资源进行并发计算,因此可用实现大数据量表的连接计算。特别是在分布式数据仓库系统中,数据本身就可以按连接条件均匀分布在多个节点上存储,无需在节点间重新分布数据并做数据传输,连接的效率最高,复杂度可以达到: O((Ra + Rb)/节点数 )。
参考资料
- https://docs.oracle.com/en/database/oracle/oracle-database/21/tgsql/joins.html#GUID-54F957FB-3568-499A-BCD2-B242BFFF913D
- https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html
- https://dev.mysql.com/doc/refman/8.0/en/bnl-bka-optimization.html
- https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html
- https://bertwagner.com/tag/join-operators.html
- [https://polardbx.com/sql-tunning/topics/join-optimizing.html
](https://polardbx.com/sql-tunning/topics/join-optimizing.html)

若有收获,就点个赞吧
0 人点赞
