https://www.selenium.dev/documentation/
1 Selenium简介
Selenium最初是由Shinya Kasatani基于火狐(Firefox)浏览器开发的工具,其主要用于网站的自动化测试。读者可以在火狐浏览器中安装Selenium IDE插件,并使用该插件录制在浏览器中的执行动作(如表单提交、单击和鼠标的移动等)。在本章中,我们将重点介绍Selenium WebDriver的使用。Selenium WebDriver主要应用于程序(Java、Python和C#等)与浏览器的交互,其可以用来实现数据的采集。
Selenium不自带浏览器,需要与第三方浏览器结合使用,如本章与Selenium结合使用的浏览器为火狐浏览器(版本号为56.064位)。相比Jsoup和HttpClient等工具,Selenium有其特有优势,如自动加载页面(执行JavaScript脚本)、模拟真实的浏览器操作(可用于模拟登录)等。
2 JavaSelenium环境搭建
首先,创建一个Java Maven工程,并在该工程下添加两个文件夹drivers和libs,
如图8.1所示。
图8.1 Java Maven工程的项目结构
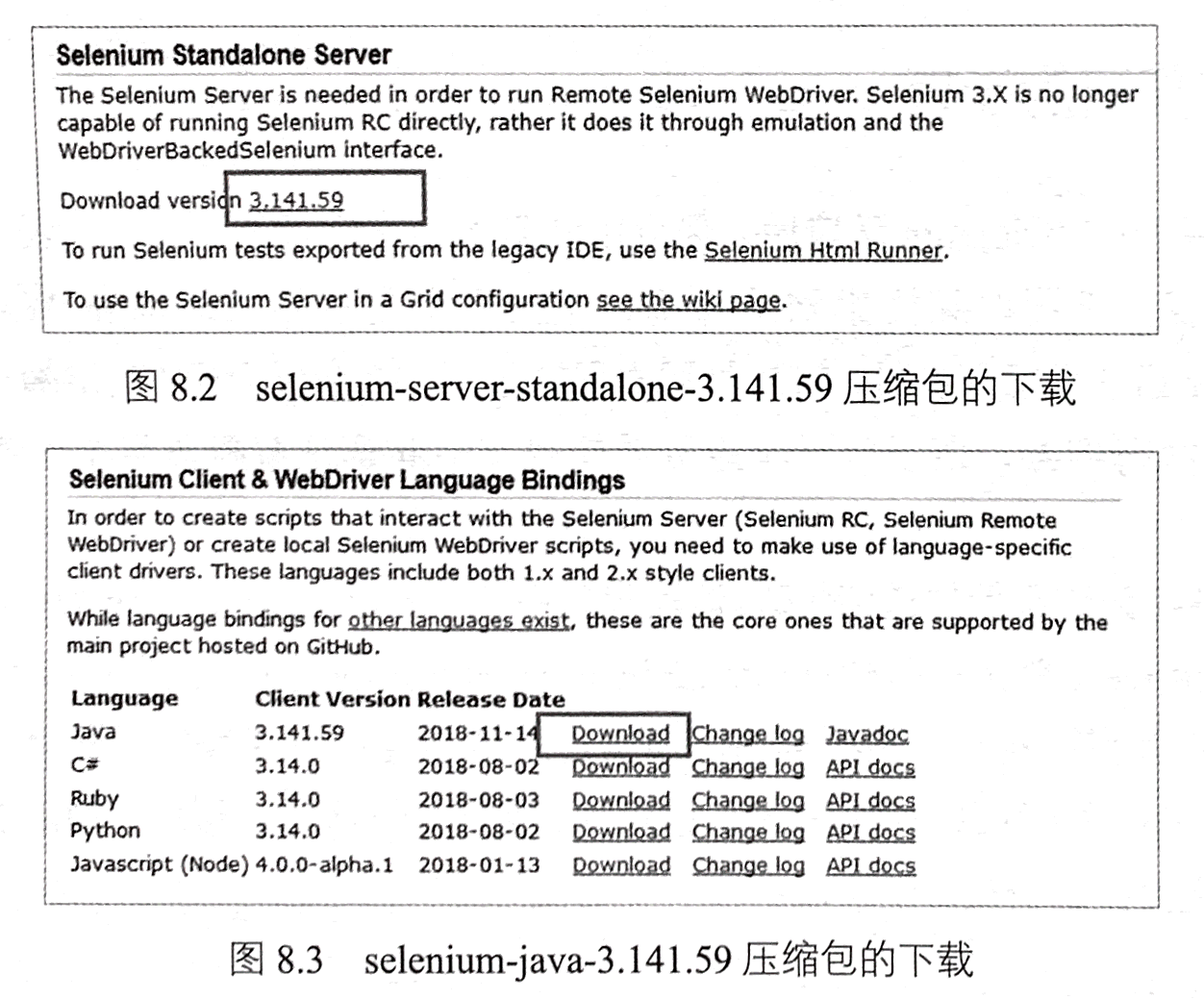
其次,在Java中使用Selenium,需要下载相关jar包,在相关界面(见图8.2)
下载selenium-server-standalone-3.141.59.jar。下载完成后,将该jar包放到工程的libs目
录下,并将该jar包引入项目。另外一种配置相关jar包的方式是单击图8.3中所示的
“Download”按钮,下载selenium-java-3.141.59压缩包,并进行解压,之后将解压后
文件夹中的所有jar包放到libs目录下,并将这些jar包引入项目。再者,也可以直接
使用Maven工程中的pom.xml文件配置所需的jar包。
<dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.141.59</version></dependency>
在相关jar包配置完成之后,需要下载Selenium WebDriver连接火狐浏览器的工
具geckodriver。
此处使用的火狐浏览器的版本号为56,因此这里下载geckodriver-v0.18.0-win64.zip,
如图8.4所示。下载完成后,解压该压缩文件,并将文件夹中的geckodriver.exe放置
到项目的drivers目录下。
3 浏览器的操控
搭建好Java Selenium环境后,便可以利用Java程序操控火狐浏览器,获取网页的响应内容。下面以某搜索网站为例,主要任务是使用Selenium WebDriver和geckodriver启动火狐浏览器,打开某搜索网站首页,并在搜索框中自动输入“Java网络爬虫”,执行搜索,最后针对响应页面使用Xpath语法解析得到搜索结果的标题
和URL。
程序8-1为该案例的详细代码。这段代码中使用setProperty(String key,String value)配置geckodriver,然后实例化FirefoxDriver(声明使用的是火狐浏览器),接着使用火狐浏览器打开页面执行一系列操作。值得注意的是在执行搜索的过程中,需要利用implicitly Wait)方法休息一定的时间,以供网页完全加载数据。最后,使用Xpath语法进行元素定位,解析相应的字段。
程序8-1
package com.qian.test;import java.util.List;import java.util.concurrent.TimeUnit;import org.openqa.selenium.By;import org.openqa.selenium.WebElement;import org.openqa.selenium.firefox.FirefoxDriver;public class Test {public static void main(String[] args) {//geckodriver配置System.setProperty("webdriver.gecko.driver", "drivers\\geckodriver.exe");//声明使用的是火狐浏览器FirefoxDriver driver = new FirefoxDriver();//使用火狐浏览器打开百度driver.get("http://www.baidu.com");//元素定位driver.findElement(By.id("kw")).sendKeys("Java 网络爬虫");driver.findElementById("kw").sendKeys("Java 网络爬虫");driver.findElementById("su").click();//给出一定的响应时间driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);driver.getPageSource();//使用xpath解析数据List<WebElement> titleList =driver.findElements(By.xpath("//*[@class='result c-container ']/h3/a"));//输出新闻标题for(WebElement e : titleList){System.out.println("标题为:" + e.getText() + "\t" + "url为:"+ e.getAttribute("href"));}driver.quit(); // 关闭浏览器}}
执行程序会发现,相关操作都会在浏览器中自动执行。另外,在控制台中也会输出解析的标题和URL,如果8.5所示。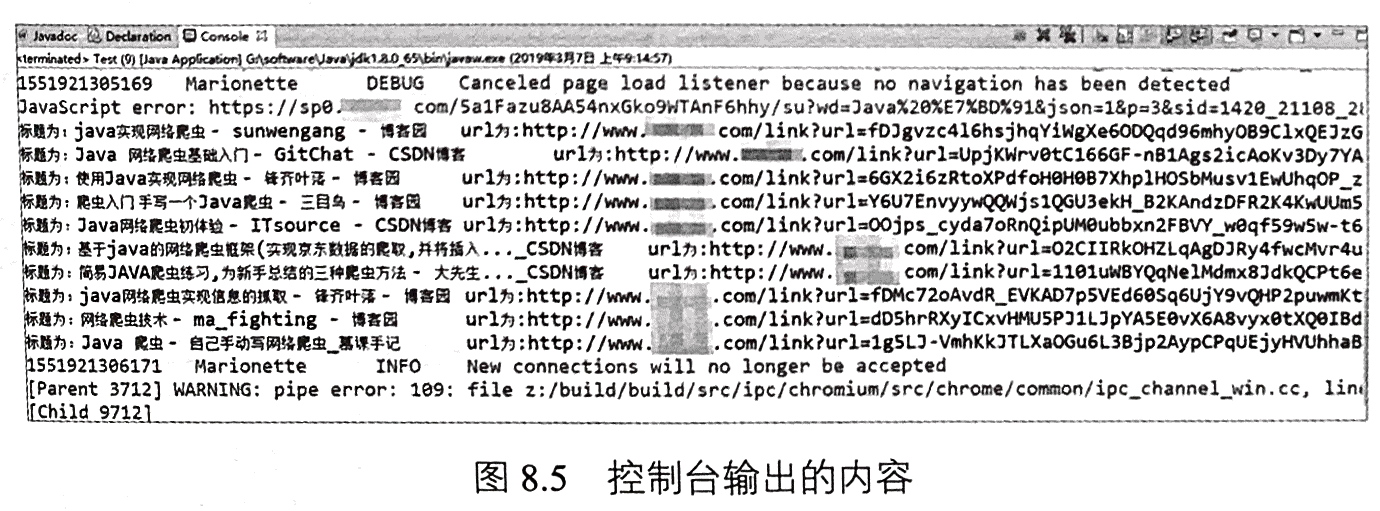
4 元素定位
在使用Selenium时,往往需要先通过定位器找到相应的元素,然后再进行其他操作。例如,在程序8-1中,先使用findElementById(“kw”)定位到搜索框,随后再利用sendKeys(CharSequence.keysToSend)方法输入搜索内容。定位器是一种抽象查询语言,功能是定位元素。Selenium WebDriver提供了多种定位策略,如id定位、name定位、class定位、tag name定位、link text定位、Xpath定位和CSS定位等。下面将分别介
绍这些定位策略。
4.1 id定位
id定位,即通过id在网页中查询元素,使用简单且常用。例如,我们想要通过id定位百度首页的搜索框。首先,在谷歌浏览器中打开该页面,在搜索框的位置右击“检查”,便会看到图8.6所示的内容,进而可以确定搜索框可以通过id=‘kw’进行定位。同理,我们可以通过id=‘su’定位开始搜索按钮,如图8.7所示。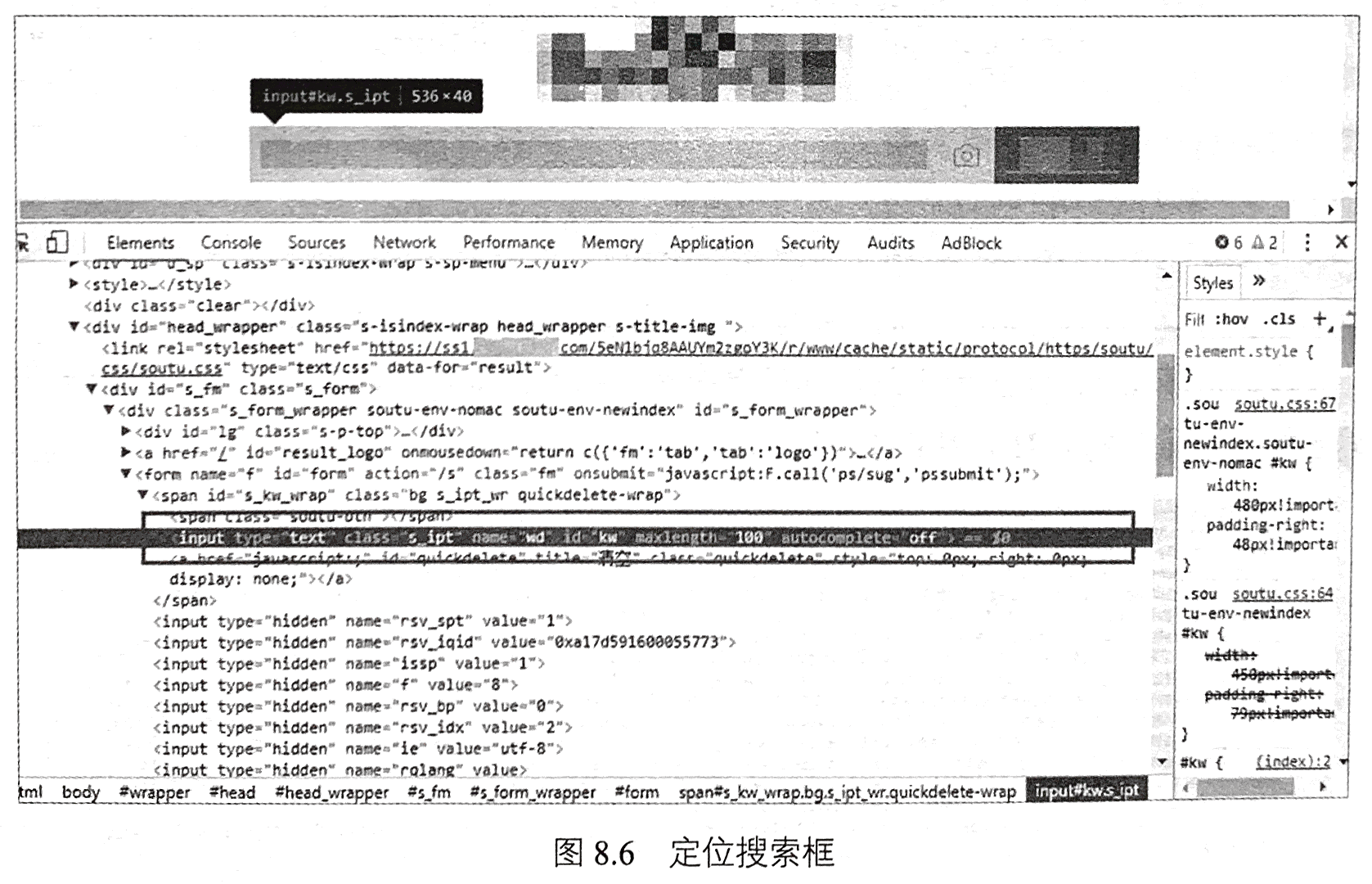

在Java中,有以下四种方式实现id定位策略,如程序8-2所示。
程序8-2
//第一种方式返回WebElement
driver.findElementById(
//第二种方式返回List
driver.findElementsById(
//第三种方式返回WebE1 ement
driver.findElement (By.id(
//第四种方式返回List
driver.findElements (By.id(
4.2 name定位
当元素中包含name属性时,可以使用name进行定位。如图8.6中的搜索框也可以使用name=‘wd’定位。在Java中,有以下四种方式实现name定位策略,如程序8-3所示。
程序8-3
//第一种方式返回WebE1 ement
driver.findElementByName (
//第二种方式返回List
driver.findElementsByName (
//第三种方式返回WebE1 ement
driver.findElement (By.Name (
//第四种方式返回List
driver.findElements (By.Name (
4.3 class定位
当元素中包含class属性时,可以使用class进行定位。如图8.7中的按钮也可以
使用class=‘btn self-btn bg s btn’定位。在Java中,有以下四种方式实现class定位
策略,如程序8-4所示。程序8-4
//第一种方式返回WebE1 ement
driver.findElementByClassName (
//第二种方式返回List
driver.findElementsByClassName (
//第三种方式返回WebElement
driver.findElement (By.ClassName (
//第四种方式返回List
driver.findElements (By.ClassName (
4.4 tagname定位
Selenium WebDriver也提供了tag name(标签名称)定位的方法,使用标签名称可以很方便地定位一些元素,如定位所有表格中的
程序8-5
//第一种方式返回WebElement
driver.findElementByTagName (
//第二种方式返回List
driver.findElementsByTagName (
//第三种方式返回WebE1 ement
driver.findElement (By.tagName (
//第四种方式返回List
driver.findElements (By.tagName (
4.5 linktext定位
link text定位,是通过链接文本定位链接的。在Java中,有以下四种方式实现lnk
text定位策略,如程序8-6所示。
程序8-6
//第一种方式返回WebE1 ement
driver.findElementByLinkText(
//第二种方式返回List
driver.findElementsByLinkText (
//第三种方式返回WebElement
driver.findElement (By.linkText (
//第四种方式返回List
driver.findElements (By.linkText (
4.6 Xpath定位
Selenium WebDriver支持使用Xpath表达式定位元素,如程序8-1中使用Xpath表达式定位一些元素。Xpath使用路径表达式来定位HTML或XML文档中的节点或节点集合,在5.1.2节中已详细介绍了Xpath语法,这里不再赘述。在Java中,同样可以使用四种方式实现Xpath定位策略,如程序8-7所示。
程序8-7
//第一种方式返回WebE1 ement
driver.findElementByXPath (
//第二种方式返回List
driver.findElementByXPath (
//第三种方式返回WebE1 ement
driver.findElement (By.xpath (
//第四种方式返回List
driver.findElements(By.xpath(
4.7 CSS选择器定位
在5.1.1节中,介绍了CSS选择器,这里不再赘述。Selenium WebDriver在定位
元素时,也可以使用CSS选择器,其实现方式有四种,如程序8-8所示。
程序8-8
//第一种方式返回WebE1 ement
driver.findElementByCssSelector (
//第二种方式返回List
driver.findElementsByCssSelector (
//第三种方式返回WebElement
driver.findElement (By.cssSelector (
//第四种方式返回List
driver.findElements (By.cssSelector (
5 模拟登录
Selenium可以精准地定位浏览器中的元素(如输入框)模拟真实的浏览器操作(如输入文本、单击等)。针对一些复杂且需要登录才能获取数据的网站,可以利用Selenium的特性,模拟登录该网站,获取登录的Cookie。之后,使用Jsoup或者Httpclient采集该网站中的数据。以下,将以某网站的模拟登录为例,介绍Selenium的使用情况。
首先,使用谷歌或火狐浏览器,打开该网站登录页面。之后,在用户名、密码和登录按钮的位置分别右击“检查”,获取这三个元素的定位信息。由图8.8可知,可以使用name=‘email’定位用户名框。同理,可以通过id=‘password’定位密码框,通过id=‘login’定位登录按钮。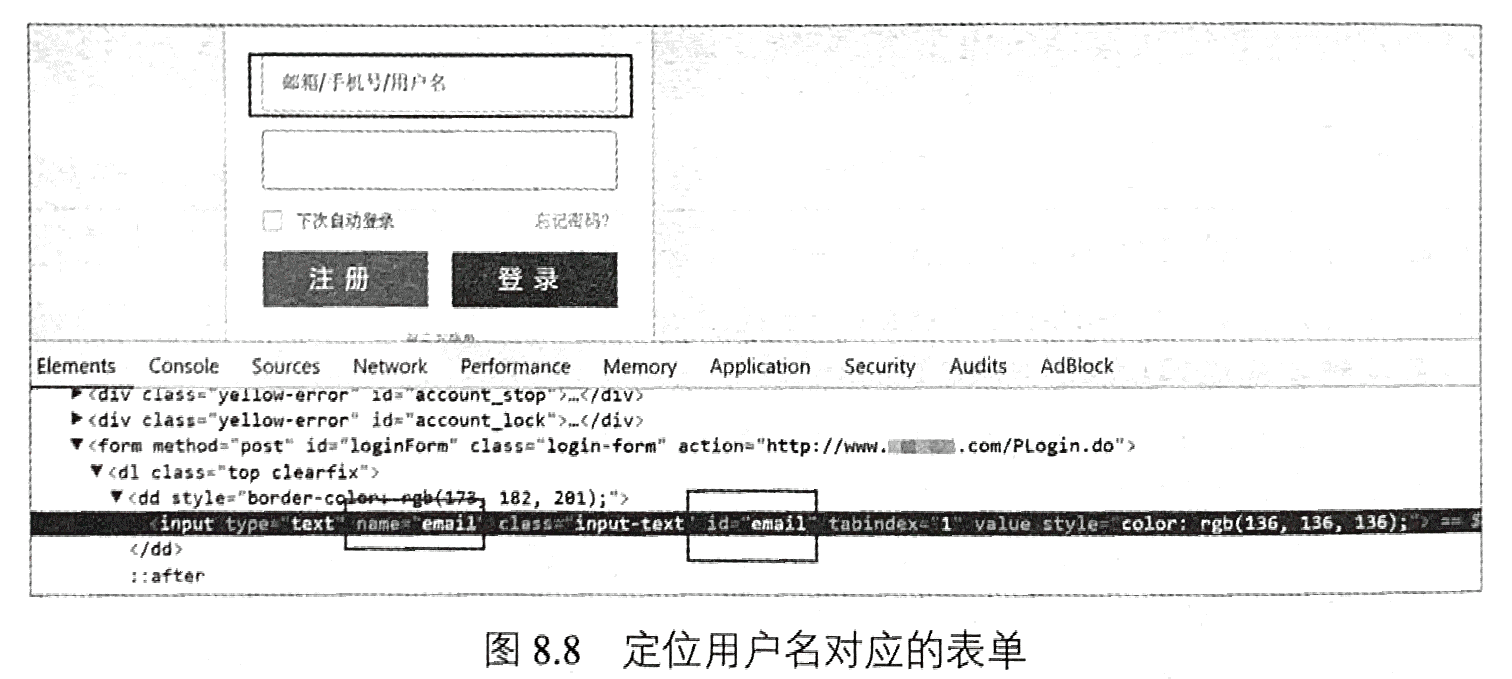
利用Selenium,输入用户名和密码,并单击“登录”按钮执行登录操作。在登录完成后,使用Jsoup请求个人页面的数据,如图8.9所示。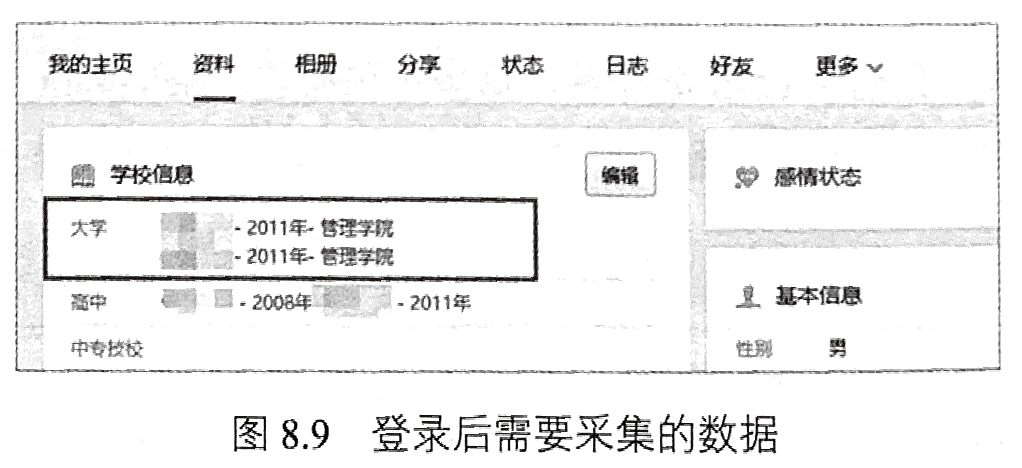
程序8-9给出了为模拟登录的完整代码。需要注意的是在模拟单击登录按钮后,
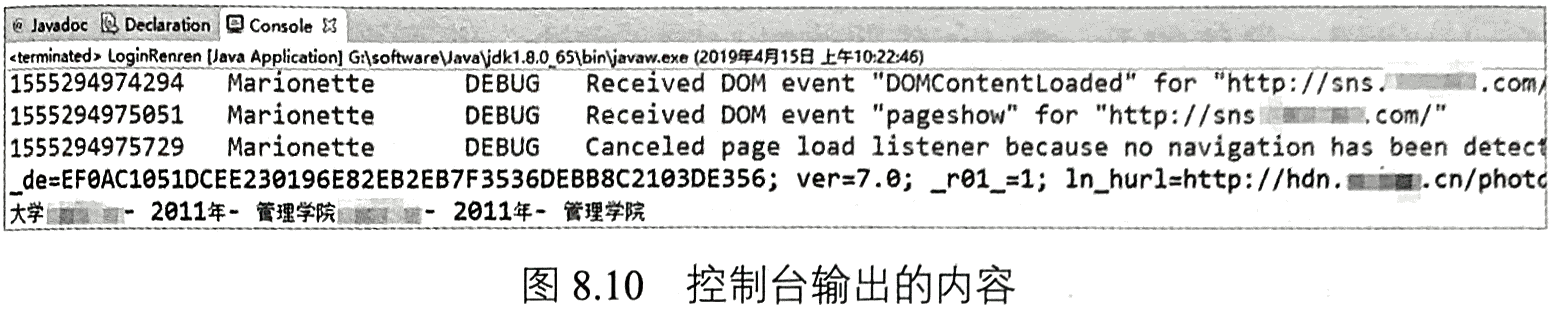
需要使用sleep((long millis)方法休息一段时间,使登录信息加载完整。在Jsoup请求指定页面时,使用了登录后的Cookie信息。执行程序8-9,会发现相关登录操作会在浏览器中自动执行。同时,控制台也会输出解析得到的内容,如图8.10所示。
程序8-9
package com.qian.test;import java.io.IOException;import java.util.Set;import java.util.concurrent.TimeUnit;import org.jsoup.Connection.Response;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.openqa.selenium.Cookie;import org.openqa.selenium.firefox.FirefoxDriver;public class LoginRenren {public static void main(String[] args) throws IOException, InterruptedException {//geckodriver配置System.setProperty("webdriver.gecko.driver", "drivers\\geckodriver.exe");//声明使用的是火狐浏览器FirefoxDriver driver = new FirefoxDriver();//使用火狐浏览器打开人人网driver.get("http://sns.******.com/");//元素定位,提交用户名以及密码//清空后输入driver.findElementByName("email").clear();driver.findElementByName("email").sendKeys("*********");driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);//清空后输入driver.findElementById("password").clear();driver.findElementById("password").sendKeys("*******");//元素定位,点击登陆按钮driver.findElementById("login").click();//休息一段时间,使得网页充分加载。注意这里非常有必要Thread.sleep(10 * 1000);Set<Cookie> cookies = driver.manage().getCookies();//获取登陆的cookiesString cookieStr = "";for (Cookie cookie : cookies) {cookieStr += cookie.getName() + "=" + cookie.getValue() + "; ";}System.out.println(cookieStr);//基于Jsoup,使用cookies请求个人信息页面//添加一些header信息Response orderResp = Jsoup.connect("http://www.******.com/427727657/profile?v=info_timeline").header("Host", "www.******.com").header("Connection", "keep-alive").header("Cache-Control", "max-age=0").header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*;q=0.8").header("Origin", "http://www.******.com").header("Referer", "http://www.******.com/SysHome.do").userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0").header("Content-Type", "application/x-www-form-urlencoded").header("Accept-Encoding", "gzip, deflate, br").header("Upgrade-Insecure-Requests", "1").cookie("Cookie", cookieStr).execute();//解析数据Document doc = orderResp.parse();//System.out.println(doc);org.jsoup.select.Elements elements = doc.select("div[class=info-section-info]").select("dl[class=info]");for (Element element : elements) {if (element.select("dt").text().contains("大学")) {System.out.println(element.text());}}// 关闭浏览器driver.quit();}}
6 动态加载JavaScript数据(操作滚动条)
在使用Jsoup和Httpclient直接请求URL时,有时会发现响应得到的HTML中包含的信息不全,未展示出的信息必须通过执行页面中的JavaScript代码才能展示。相比于Jsoup和Httpclient,Selenium可以利用JavascriptExecutor接口执行任意JavaScript代码。下面将以国外某网站中的新闻数据采集为例,讲解如何使用Selenium动态加载JavaScript数据。
在进入新闻的某一网页时,下拉滚动条,会发现底部展示了一系列的相关新闻(网站推荐的内容),如图8.11所示,继续下拉滚动条,新的新闻内容会不断地加载出来。
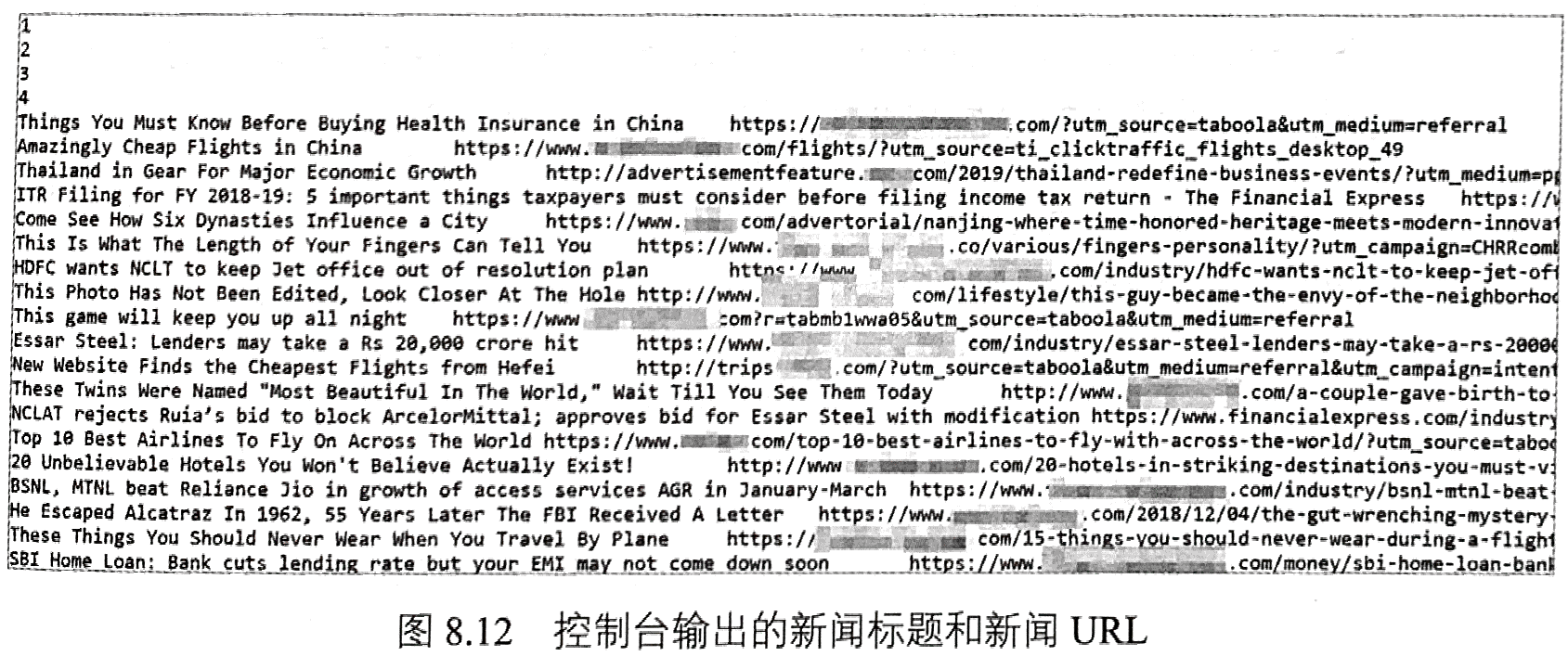
为了采集每条新闻对应的一系列相关新闻,则需要不断地向下加载数据,即下拉浏览器滚动条。程序8-10给出了动态加载JavaScript数据的代码。在程序8-10中,使用JavascriptExecutor接口的executeScript(String script,Object..args)方法执行JavaScript代码,具体的JavaScrript代码为scrollTo方法,即页面滚动方法。在执行第一次滚动时,都需要休息一定的时间,以使得网页充分加载数据。在滚动完成之后,获取该网页的HTML内容并使用Jsoup工具解析相关新闻数据。执行程序8-10,会在控制台输出新闻的标题和URL,如图8.12所示。
package com.qian.test;import java.io.IOException;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.openqa.selenium.JavascriptExecutor;import org.openqa.selenium.firefox.FirefoxDriver;public class FinancialNewsRolling {public static void main(String[] args) throws IOException, InterruptedException {//geckodriver配置System.setProperty("webdriver.gecko.driver", "drivers\\geckodriver.exe");//声明使用的是火狐浏览器FirefoxDriver driver = new FirefoxDriver();//使用火狐浏览器打开任意某一新闻页driver.get("https://www.financialexpress.com/industry" + "/nclat-rejects-hdfc-plea-for-insolvency-" + "proceedings-against-rhc-holding/1640159/");// 执行JS操作JavascriptExecutor JS = (JavascriptExecutor) driver;Thread.sleep(3000);try {JS.executeScript("scrollTo(0, 5000)");System.out.println("1");//调整休眠时间可以获取更多的内容Thread.sleep(5000);JS.executeScript("scrollTo(5000, 10000)");System.out.println("2");Thread.sleep(5000);// 继续下拉JS.executeScript("scrollTo(10000, 30000)");System.out.println("3");Thread.sleep(5000);//继续下拉JS.executeScript("scrollTo(10000, 50000)");System.out.println("4");} catch (Exception e) {System.out.println("Error at loading the page ...");driver.quit();}String html = driver.getPageSource();//System.out.println(html);//解析数据Document doc = Jsoup.parse(html);Elements elements = doc.select("[id=taboola-below-article]").select("div[id~=taboola-below-article-p?]");for (Element ele : elements) {String newsTitle = ele.select("a[class= item-label-href]").attr("title");String newsUrl = ele.select("a[class= item-label-href]").attr("href");System.out.println(newsTitle + "\t" + newsUrl);}// 关闭浏览器driver.quit();}}
7 隐藏浏览器
由以上内容可知使用Selenium采集网磁数据时,需要不断地调用浏览器。实际上,通过对Selenium的设置,可以达到隐藏浏览器的效果。仍以8.5节中的新联页面为例,程序8-11中给出了采集该新闻页面标题的代码。在程序8-11中,对火狐浏览器设置了headless,其作用是实现无界面状态。同时,这里使用while循环的方式,以防止加载浏览器请求页面失败。最后,程序执行JavaScript代码,获取新闻的标题,执行程序8-11,会在控制台输出新闻的标题信息。
程序8-11
package com.qian.test;import java.io.IOException;import java.util.concurrent.TimeUnit;import org.openqa.selenium.JavascriptExecutor;import org.openqa.selenium.firefox.FirefoxBinary;import org.openqa.selenium.firefox.FirefoxDriver;import org.openqa.selenium.firefox.FirefoxOptions;public class JavaScriptTest {public static void main(String[] args) throws IOException, InterruptedException {FirefoxBinary firefoxBinary = new FirefoxBinary();firefoxBinary.addCommandLineOptions("--headless");//设置路径System.setProperty("webdriver.gecko.driver", "drivers\\geckodriver.exe");FirefoxOptions firefoxOptions = new FirefoxOptions();firefoxOptions.setBinary(firefoxBinary);FirefoxDriver driver = new FirefoxDriver(firefoxOptions);//直到加载该网页为止while (true) {try {driver.get("https://www.financialexpress.com" + "/industry/nclat-rejects-hdfc-plea" + "-for-insolvency-proceedings-against" + "-rhc-holding/1640159/");} catch (Exception e) {driver.quit();driver = new FirefoxDriver(firefoxOptions);driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);continue;}break;}//滚动条操作JavascriptExecutor JS = (JavascriptExecutor) driver;// 执行JS操作,返回新闻的标题String title = (String) JS.executeScript("return document.title");System.out.println(title);// 关闭浏览器driver.quit();}}
8 截取验证码
在网络爬虫中,很多网站会采用验证码的方式来反爬虫,例如在登录时设置验证码、频繁访问时自动弹出验证码等。针对模拟登录时的验证码输入问题,一种简单的解决方案是将验证码保存到本地,之后在程序中手动输入即可。但对于采集每页都需要验证码的网站来说,则需要使用验证码识别算法或调用一些OCR API来自动识别验证码,以保证其效率。
使用Jsoup或者Httpclient,可以直接将验证码下载到本地。而对Selenium来说,可以使用截图的方式截取验证码,并保存到本地。下面,以某搜索网站为例介绍Selenium如何实现截取验证码,在程序中手动输入验证码内容,实现数据的采集。图8.13展示了需要输入的关键词及关键词对应的部分文章数据。
在浏览器中打开网页时,会出现图8.14所示的情况,即访问异常,需要输入验证码。为此,我们使用Selenium截取验证码。首先,利用浏览器检查元素,使用id=‘seccodelmage’定位到验证码,接着使用getScreenshotAs以及getSubimage方法截取该验证码。程序8-12给出了完整的数据采集代码。在手动输入验证码之后,单击“提
交”按钮,便能看到所需内容。
执行程序8-12,会在“E:/钱洋个人/IdentifyingCode/”目录下出现test.png图片文件,如图8.15所示。在控制台输入验证码内容“8628bs”,便可以成功获取关键词对应的文章数据,如图8.16所示。
程序8-12
package com.qian.test;import java.awt.image.BufferedImage;import java.io.BufferedReader;import java.io.File;import java.io.IOException;import java.io.InputStreamReader;import java.util.concurrent.TimeUnit;import javax.imageio.ImageIO;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.openqa.selenium.By;import org.openqa.selenium.OutputType;import org.openqa.selenium.Point;import org.openqa.selenium.TakesScreenshot;import org.openqa.selenium.WebElement;import org.openqa.selenium.firefox.FirefoxBinary;import org.openqa.selenium.firefox.FirefoxDriver;import org.openqa.selenium.firefox.FirefoxOptions;public class ScreenshotTest {public static void main(String[] args) throws IOException, InterruptedException {FirefoxBinary firefoxBinary = new FirefoxBinary();firefoxBinary.addCommandLineOptions("--headless");//设置路径System.setProperty("webdriver.gecko.driver", "drivers\\geckodriver.exe");FirefoxOptions firefoxOptions = new FirefoxOptions();firefoxOptions.setBinary(firefoxBinary);FirefoxDriver driver = new FirefoxDriver(firefoxOptions);//直到加载该网页为止while (true) {try {driver.get("http://weixin.******.com/antispider/?"+ "from=%2fweixin%3Ftype%3d2%26query"+ "%3dcomputer+%26ie%3dutf8%26s_from%"+ "3dinput%26_sug_%3dy%26_sug_type_%3d");} catch (Exception e) {driver.quit();driver = new FirefoxDriver(firefoxOptions);driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);continue;}break;}WebElement webEle = driver.findElement(By.id("seccodeImage"));// Get entire page screenshotjava.io.File screenshot = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);BufferedImage fullImg = ImageIO.read(screenshot);Point point = webEle.getLocation();int eleWidth = webEle.getSize().getWidth();int eleHeight = webEle.getSize().getHeight();BufferedImage eleScreenshot = fullImg.getSubimage(point.getX(), point.getY(),eleWidth, eleHeight);ImageIO.write(eleScreenshot, "png", new File("E:/钱洋个人/IdentifyingCode/test.png"));System.out.println("请输入验证码:");BufferedReader buff = new BufferedReader(new InputStreamReader(System.in));String captcha_solution = "";try {captcha_solution = buff.readLine();} catch (IOException e) {e.printStackTrace();}driver.findElement(By.name("c")).sendKeys(captcha_solution);driver.findElementById("submit").click();//休息一段时间,使得网页充分加载。注意这里非常有必要Thread.sleep(10 * 1000);String html = driver.getPageSource();Document doc = Jsoup.parse(html);Elements elements = doc.select("div[class=txt-box]");for (Element ele : elements) {String newsTitle = ele.select("h3").select("a").text();String newsUrl = ele.select("h3").select("a").attr("href");System.out.println(newsTitle + "\t" + newsUrl);}// 关闭浏览器driver.quit();}}

9 本章小结
本章主要介绍了Selenium WebDriver在网络爬虫中的应用。相比Jsoup、Httpclient
和URLConnection,Selenium的主要优势是可以与浏览器进行交互(如输入文字、单
击按钮等)及执行加载JavaScript代码。但Selenium也存在缺点,如每执行一个URL
都相当于在浏览器中打开一个网页,并且需要加载网页中的JavaScript代码,因此,
Selenium的效率较低,仅适用于小规模数据采集。

若有收获,就点个赞吧
0 人点赞
