第5章 Elasticsearch集群入门 113
5.1 索引管理 113
5.1.1 新建索引 113
创建索引和在MySQL中创建一个数据库是一样的,注意Elasticsearch索引名称中不能出现大写字母。例如新建一个索引,名为blog,命令如下:
PUT blog
Elasticsearch默认给一个索引设置5个分片1个副本,一个索引的分片数一经指定后就不能再修改,副本数可以通过命令随时修改。如果想创建自定义分片数和副本数的索引,可以通过setting参数在索引时设置初始化信息。以创建3个分片0个副本名为blog的索引为例,命令如下:
5.1.2 更新副本 115
5.1.3 读写权限 115
5.1.4 查看索引 116
5.1.5 删除索引 117
5.1.6 索引的打开与关闭 118
5.1.7 复制索引 118
5.1.8 收缩索引 119
5.1.9 索引别名 120
5.2 文档管理 123
5.2.1 新建文档 123
5.2.2 获取文档 125
5.2.3 更新文档 127
5.2.4 查询更新 129
5.2.5 删除文档 129
5.2.6 查询删除 130
5.2.7 批量操作 130
5.2.8 版本控制 133
5.2.9 路由机制 136
5.3 映射详解 137
5.3.1 映射分类 137
5.3.2 动态映射 138
5.3.3 日期检测 140
5.3.4 静态映射 141
5.3.5 字段类型 142
5.3.6 元字段 156
5.3.7 映射参数 162
5.3.8 映射模板 180
5.4 本章小结 181
第6章 Elasticsearch搜索详解 182
6.2 全文查询
高级别的全文搜索通常用于在全文字段(例如:一封邮件的正文)上进行全文搜索,通过全文查询理解被查询字段是如何被索引和分析的,在执行之前将每个字段的分词器(或搜索分词器)应用于查询字符串。
6.2.1 match query
match查询会解析查询语句,举一个经典的例子:假设我们现在的查询语句为“java编程”,查询域为title,使用term query进行查询,查询命令及查询结果如图6-3所示,可以看到搜索结果为空。但是测试文档集合中有一个文档的title为“Java编程思想”,查询“java编程”理应返回该文档的,为什么没有返回?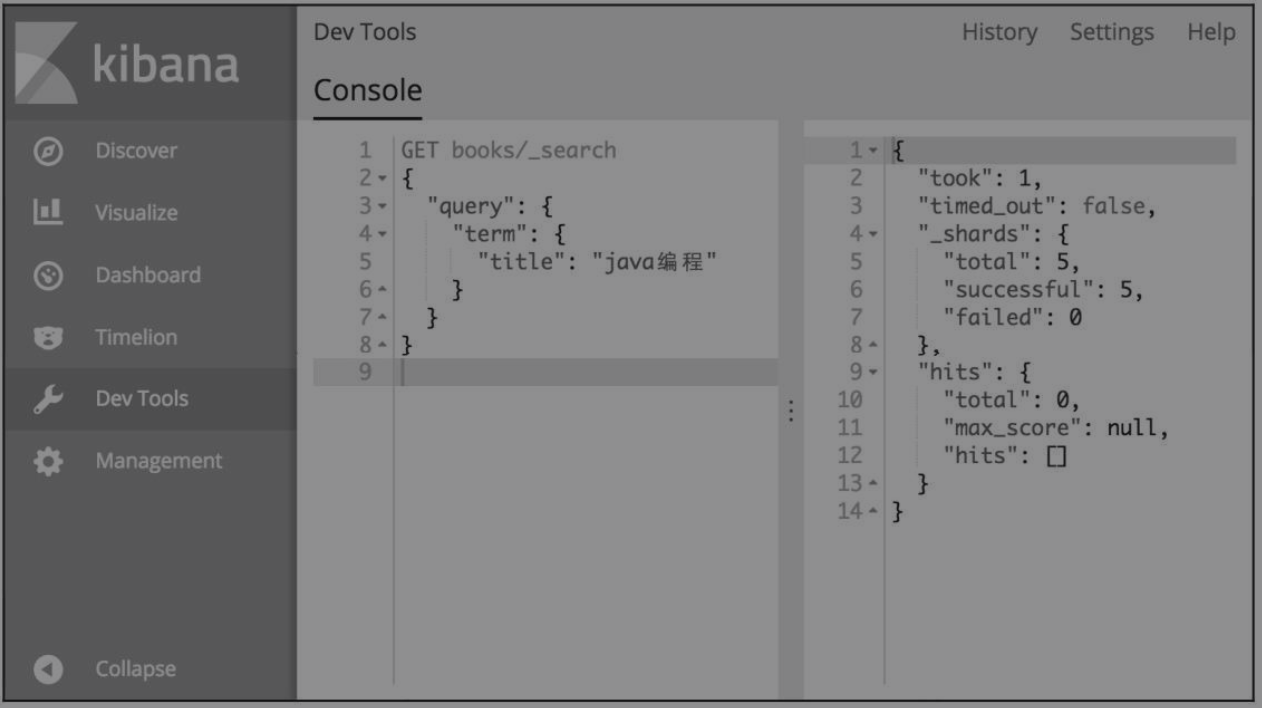
图6-3 term query查询结果
究其原因,term query查的是词项,“Java编程思想”经过分词以后会变成“java”“编程”“思想”等多个词项,不存在词项“java编程”,因此返回结果为空。换成match query,查询结果如图6-4所示。
图6-4 match query查询结果
match query会对查询语句进行分词,分词后查询语句中的任何一个词项被匹配,文档就会被搜索到。如果想查询匹配所有关键词的文档,可以用and操作符连接,命令如下:

6.2.2 match_phrase query
match_phrase query首先会把query内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到:
(1)分词后所有词项都要出现在该字段中。
(2)字段中的词项顺序要一致。
例如,有以下3个文档,使用match_phrase查询“hello world”,只有前两个文档会被匹配:
6.2.3 match_phrase_prefix query
match_phrase_prefix和match_phrase类似,只不过match_phrase_prefix支持最后一个term前缀匹配: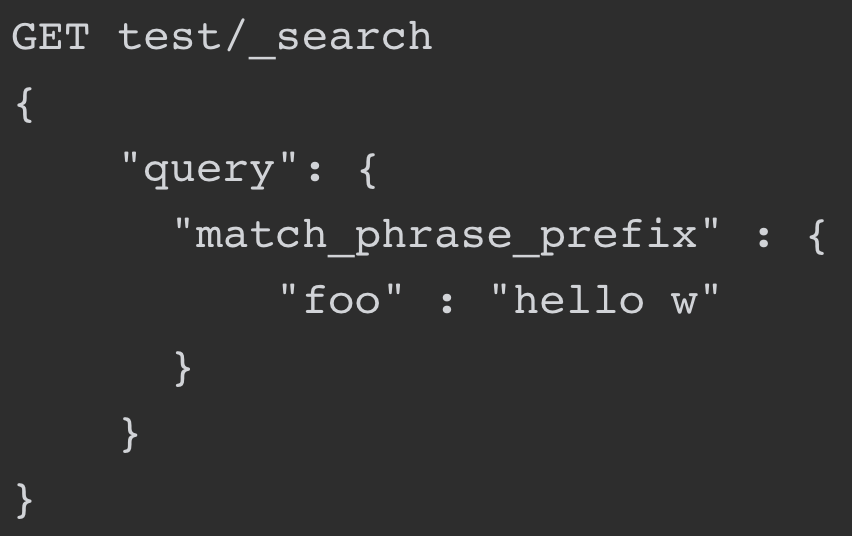
6.2.4 multi_match query
multi_match是match的升级,用于搜索多个字段。查询语句为“java编程”,查询域为title和description,查询语句如下:
multi_match支持对要搜索的字段的名称使用通配符,示例如下:
同时,也可以用指数符指定搜索字段的权重。指定关键词出现在title中的权重是出现在description字段中的3倍,命令如下:

6.2.5 common_terms query
common_terms query是一种在不牺牲性能的情况下替代停用词提高搜索准确率和召回率的方案。
查询中的每个词项都有一定的代价,以搜索“The brown fox”为例,query会被解析成三个词项“the”“brown”和“fox”,每个词项都会到索引中执行一次查询。很显然包含“the”的文档非常多,相比其他词项,“the”的重要性会低很多。传统的解决方案是把“the”当作停用词处理,去除停用词之后可以减少索引大小,同时在搜索时减少对停用词的收缩。
虽然停用词对文档评分影响不大,但是当停用词仍然有重要意义的时候,去除停用词就不是完美的解决方案了。如果去除停用词,就无法区分“happy”和“nothappy”,“The”“To be or not to be”就不会在索引中存在,搜索的准确率和召回率就会降低。
common_terms query提供了一种解决方案,它把query分词后的词项分成重要词项(低频词项)和不重要的词项(高频词,也就是之前的停用词)。在搜索的时候,首先搜索和重要词项匹配的文档,这些文档是词项出现较少并且词项对其评分影响较大的文档。然后执行第二次查询,搜索对评分影响较小的高频词项,但是不计算所有文档的评分,而是只计算第一次查询已经匹配的文档得分。如果一个查询中只包含高频词,那么会通过and连接符执行一个单独的查询,换言之,会搜索所有的词项。
词项是高频词还是低频词是通过cutoff_frequency来设置阀值的,取值可以是绝对频率(频率大于1)或者相对频率(0~1)。common_terms query最有趣之处在于它能自适应特定领域的停用词,例如,在视频托管网站上,诸如“clip”或“video”之类的高频词项将自动表现为停用词,无须保留手动列表。
例如,文档频率高于0.1%的词项将会被当作高频词项,词频之间可以用low_freq_operator、high_freq_operator参数连接。设置低频词操作符为“and”使所有的低频词都是必须搜索的,示例代码如下:

6.2.6 query_string query
query_string query是与Lucene查询语句的语法结合非常紧密的一种查询,允许在一个查询语句中使用多个特殊条件关键字(如:AND|OR|NOT)对多个字段进行查询,建议熟悉Lucene查询语法的用户去使用。6.2.7 simple_query_stringsimple_query_string是一种适合直接暴露给用户,并且具有非常完善的查询语法的查询语句,接受Lucene查询语法,解析过程中发生错误不会抛出异常。例子如下:
6.2.7 simple_query_string
simple_query_string是一种适合直接暴露给用户,并且具有非常完善的查询语法的查询语句,接受Lucene查询语法,解析过程中发生错误不会抛出异常。例子如下:
6.3 词项查询 193
6.3.1term query 193
6.3.2terms query 193
6.3.3range query 194
6.3.4ests query 194
6.3.5prefix query 195
6.3.6wildcard query 195
6.3.7regexp query 196
6.3.8fuzzy query 196
6.3.9type query 196
6.3.10ids query 197
6.4 复合查询 197
6.4.1constant_score query 197
6.4.2 bool query 198
6.4.3dis_max query 198
6.4.4function_score query 199
6.4.5boosting query 200
6.4.6indices query 201
6.5 嵌套查询 202
6.5.1nested query 202
6.5.2has_child query 202
6.5.3has_parent query 204
6.6 位置查询 205
6.6.1geo_distance query 206
6.6.2geo_bounding_box query 206
6.6.3geo_polygon query 208
6.6.4geo_shape query 209
6.7 特殊查询 210
6.7.1more_like_this query 210
6.7.2script query 211
6.7.3percolate query 211
6.8 搜索高亮 213
6.8.1自定义高亮片段 213
6.8.2多字段高亮 213
6.8.3高亮性能分析 214
6.9 搜索排序 215
6.9.1默认排序 215
6.9.2多字段排序 215
6.9.3分片影响评分 216
6.10本章小结 218
第7章 聚合分析 219
7.1 指标聚合 219
7.1.1Max Aggregation 219
7.1.2Min Aggregation 220
7.1.3Avg Aggregation 220
7.1.4Sum Aggregation 221
7.1.5Cardinality Aggregation 221
7.1.6Stats Aggregation 222
7.1.7Extended Stats Aggregation 222
7.1.8Percentiles Aggregation 223
7.1.9Value Count Aggregation 224
7.2 桶聚合 224
7.2.1Terms Aggregation 225
7.2.2Filter Aggregation 227
7.2.3Filters Aggregation 227
7.2.4Range Aggregation 228
7.2.5Date Range Aggregation 231
7.2.6Date Histogram Aggregation 232
7.2.7Missing Aggregation 233
7.2.8Children Aggregation 233
7.2.9Geo Distance Aggregation 234
7.2.10IP Range Aggregation 235
7.3 本章小结 236

若有收获,就点个赞吧
0 人点赞
