- 1. 操作系统概述
- 2. 操作系统上的程序
- define call(…) ({ *(++top) = (Frame) { .pc = 0, VA_ARGS }; })
- define ret() ({ top—; })
- define goto(loc) ({ f->pc = (loc) - 1; })
- 3. 多处理器编程
- 4. 理解并发程序执行
- 5. 并发控制:互斥
- 6. 并发控制:同步
- 10. 状态机模型的应用
- 11. 操作系统上的进程
- 12. 进程的地址空间
- 13. 系统调用和 Shell
- GP, #PF 或 #DIV
- 总结
- 14. C 标准库的实现
- 15. Fork 的应用
- 16. 什么是可执行文件
- 17. 动态链接和加载
- 问题
- 参考
operating_systems_three_easy_pieces.pdf
1. 操作系统概述
2. 操作系统上的程序
什么是程序(源代码视角)
程序就是状态机
void hanoi(int n, char from, char to, char via) {if (n == 1) printf("%c -> %c\n", from, to);else {hanoi(n - 1, from, via, to);hanoi(1, from, to, via);hanoi(n - 1, via, to, from);}return;}
#include <stdio.h>#include "hanoi-r.c"int main() {hanoi(3, 'A', 'B', 'C');return 0;}
C 程序的状态机模型 (语义,semantics)
- 状态 = 堆 + 栈
- 初始状态 = main 的第一条语句
- 迁移 = 执行一条简单语句
C 程序的状态机模型 (语义,semantics)
- 状态 = stack frame 的列表 (每个 frame 有 PC) + 全局变量
- 初始状态 = main(argc, argv), 全局变量初始化
- 迁移 = 执行 top stack frame PC 的语句; PC++
- 函数调用 = push frame (frame.PC = 入口)
- 函数返回 = pop frame
应用:将任何递归程序就地转为非递归
- 汉诺塔难不倒你 hanoi-nr.c
- A → B, B → A 的也难不倒你
- 还是一样的 call(),但放入不同的 Frame ```shell typedef struct { int pc, n; char from, to, via; } Frame;
define call(…) ({ *(++top) = (Frame) { .pc = 0, VA_ARGS }; })
define ret() ({ top—; })
define goto(loc) ({ f->pc = (loc) - 1; })
void hanoi(int n, char from, char to, char via) { Frame stk[64], top = stk - 1; call(n, from, to, via); for (Frame f; (f = top) >= stk; f->pc++) { switch (f->pc) { case 0: if (f->n == 1) { printf(“%c -> %c\n”, f->from, f->to); goto(4); } break; case 1: call(f->n - 1, f->from, f->via, f->to); break; case 2: call( 1, f->from, f->to, f->via); break; case 3: call(f->n - 1, f->via, f->to, f->from); break; case 4: ret(); break; default: assert(0); } } }
```shell#include <stdio.h>#include <assert.h>#include "hanoi-nr.c"int main() {hanoi(3, 'A', 'B', 'C');return 0;}
什么是程序 (二进制代码视角)
还是状态机
- 状态 = 内存 M + 寄存器 R
- 初始状态 = (稍后回答)
迁移 = 执行一条指令
所有的指令都只能计算
把 (M,R) 完全交给操作系统,任其修改
- 一个有趣的问题:如果程序不打算完全信任操作系统?
- 实现与操作系统中的其他对象交互
- 读写文件/操作系统状态 (例如把文件内容写入 M)
- 改变进程 (运行中状态机) 的状态,例如创建进程/销毁自己
程序 = 计算 + syscall
3. 多处理器编程
底层原理
详见:http://jyywiki.cn/OS/2022/slides/3.slides#/
4. 理解并发程序执行
详见:http://jyywiki.cn/OS/2022/slides/4.slides#/
5. 并发控制:互斥
详见:http://jyywiki.cn/OS/2022/slides/5.slides#/
共享内存上的互斥
自旋锁(Spin Lock)
使用场景
- 临界区几乎不“拥堵”
- 持有自旋锁时禁止执行流切换
缺点
性能问题 (0)
-
性能问题 (1)
除了进入临界区的线程,其他处理器上的线程都在空转
-
性能问题 (2)
获得自旋锁的线程可能被操作系统切换出去
- 操作系统不 “感知” 线程在做什么
- (但为什么不能呢?)
-
互斥锁(Mutex Lock)
Futex = Spin + Mutex
自旋锁 (线程直接共享 locked)
更快的 fast path
- xchg 成功 → 立即进入临界区,开销很小
- 更慢的 slow path
- xchg 失败 → 浪费 CPU 自旋等待
睡眠锁 (通过系统调用访问 locked)
- 更快的 slow path
- 上锁失败线程不再占用 CPU
- 更慢的 fast path
- 即便上锁成功也需要进出内核 (syscall)
Futex: Fast Userspace muTexes
- Fast path: 一条原子指令,上锁成功立即返回
- Slow path: 上锁失败,执行系统调用睡眠
- 性能优化的最常见技巧
- 看 average (frequent) case 而不是 worst case
- 性能优化的最常见技巧
先在用户空间自旋
- 如果获得锁,直接进入
- 未能获得锁,系统调用
解锁以后也需要系统调用
- futex.py
- 更好的设计可以在 fast-path 不进行系统调用
总结
Take-away message
软件不够,硬件来凑 (自旋锁)
- 用户不够,内核来凑 (互斥锁)
- 找到你依赖的假设,并大胆地打破它
-
6. 并发控制:同步
详见:http://jyywiki.cn/OS/2022/slides/6.slides#/
条件变量:Conditional Variables
条件变量 API
wait(cv, mutex)
- 调用时必须保证已经获得 metex
- 释放 mutex,进入睡眠状态
- signal/notify(cv)
- 如果有线程正在等待 cv,则唤醒其中一个线程
broadcast/notifyAll(cv)
-
条件变量:实现并行计算
```c struct job { void (run)(void arg); void *arg; }
while (1) { struct job *job;
mutex_lock(&mutex); while (! (job = get_job()) ) { wait(&cv, &mutex); } mutex_unlock(&mutex);
job->run(job->arg); // 不需要持有锁 // 可以生成新的 job // 注意回收分配的资源 }
<a name="r7KHE"></a>## 信号量:Semaphore<a name="Oa8lX"></a>## 哲学家吃饭问题万能的方法:条件变量<a name="izsUT"></a>## 总结- 实现同步的方法- 条件变量、信号量- Job queue 可以实现几乎任何并行算法- 不要“自作聪明”设计算法,小心求证<a name="PXkow"></a># 7. 真实世界的并发编程详见:[http://jyywiki.cn/OS/2022/slides/7.slides#/](http://jyywiki.cn/OS/2022/slides/7.slides#/)<a name="as2L0"></a>## 高性能计算中的并发编程<a name="OL2sC"></a>### 高性能计算程序:特点“A technology that harnesses the power of supercomputers or computer clusters to solve complex problems requiring massive computation.” (IBM)<br />以计算为中心- 系统模拟:天气预报、能源、分子生物学- 人工智能:神经网络训练- 矿厂:纯粹的 hash 计算- [HPC-China 100](http://www.hpc100.cn/top100/20/)<a name="tYCXW"></a>### 高性能计算:主要挑战计算任务如何分解- **计算图需要容易并行化**- 机器-线程两级任务分解- 生产者-消费者解决一切- [MPI](https://hpc-tutorials.llnl.gov/mpi/) - “a specification for the developers and users of message passing libraries”, [OpenMP](https://www.openmp.org/) - “multi-platform shared-memory parallel programming in C/C++ and Fortran”- [Parallel and Distributed Computation: Numerical Methods](https://web.mit.edu/dimitrib/www/pdc.html)线程间如何通信- 通信不仅发生在节点/线程之间,还发生在任何共享内存访问<a name="aIW1a"></a>## 数据中心里的并发编程<a name="EBhoN"></a>### 数据中心程序:特点:::info“A network of computing and storage resources that enable the delivery of shared applications and data.” (CISCO):::**以数据 (存储) 为中心**- 从互联网搜索 (Google)、社交网络 (Facebook/Twitter) 起家- 支撑各类互联网应用:微信/QQ/支付宝/游戏/网盘/……**算法/系统对 HPC 和数据中心的意义**- 你有 1,000,000 台服务器- 如果一个算法/实现能快 1%,就能省 10,000 台服务器- 参考:对面一套房 ≈ 50 台服务器 (不计运维成本)<a name="liJo6"></a>### 数据中心:主要挑战多副本情况下的高可靠、低延迟数据访问- 在服务海量地理分布请求的前提下- 数据要保持一致 (Consistency)- 服务时刻保持可用 (Availability)- 容忍机器离线 (Partition tolerance)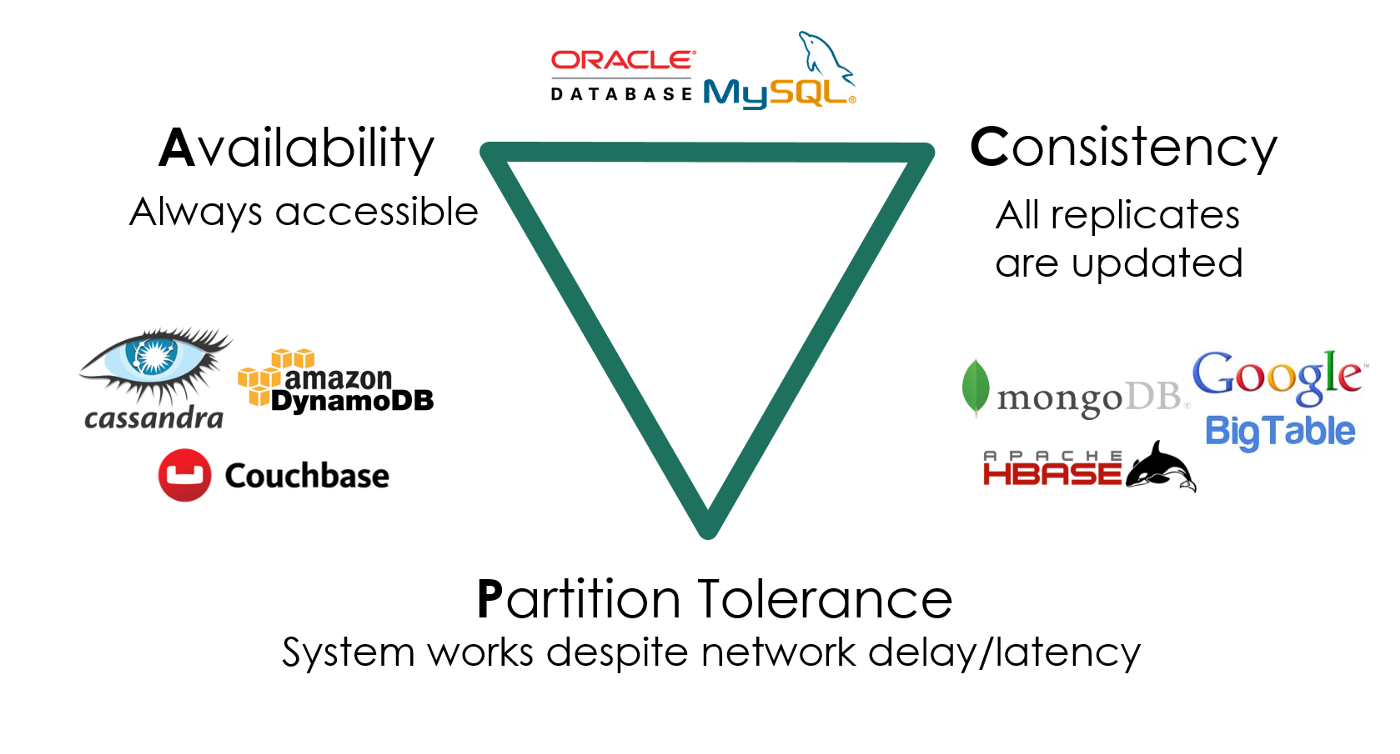<a name="fGHUv"></a>### 如何用好一台计算机如何用一台 (可靠的) 计算机尽可能多地服务并行的请求- 关键指标:QPS, tail latency, ...**我们有的工具**- 线程 (threads)thread(start = true) { println("${Thread.currentThread()} has run.") }- 协程 (coroutines)- 多个可以保存/恢复的执行流 ([M2 - libco](http://jyywiki.cn/OS/2022/labs/M2))- 比线程更轻量 (完全没有系统调用,也就没有操作系统状态)<a name="TGl7p"></a>### 数据中心:协程和线程**数据中心**- 同一时间有数千/数万个请求到达服务器- 计算部分- 需要利用好多处理器- 线程 → 这就是我擅长的 (Mandelbrot Set)- 协程 → 一人出力,他人摸鱼- I/O 部分- 会在系统调用上 block (例如请求另一个服务或读磁盘)- 协程 → 一人干等,他人围观- 线程 → 每个线程都占用可观的操作系统资源- (这个问题比你想象的复杂,例如虚拟机)<a name="hg61o"></a>### Go 和 Goroutine:::infoGo: 小孩子才做选择,多处理器并行和轻量级并发我全都要!:::Goroutine: 概念上是线程,实际是线程和协程的混合体- 每个 CPU 上有一个 Go Worker,自由调度 goroutines- 执行到 blocking API 时 (例如 sleep, read)- Go Worker 偷偷改成 non-blocking 的版本- 成功 → 立即继续执行- 失败 → 立即 yield 到另一个需要 CPU 的 goroutine- 太巧妙了!CPU 和操作系统全部用到 100%例子- [fib.go](http://jyywiki.cn/pages/OS/2022/demos/fib.go); [The Go Programming Language(ch 9.8)](https://books.studygolang.com/gopl-zh/ch9/ch9-08.html)<a name="DCCZV"></a>### 现代编程语言上的系统编程:::infoDo not communicate by sharing memory; instead, share memory by communicating. ——Effective Go:::**共享内存 = 万恶之源**- 在奇怪调度下发生的各种并发 bugs- 条件变量:broadcast 性能低,不 broadcast 容易错- 信号量:在管理多种资源时就没那么好用了既然生产者-消费者能解决绝大部分问题,提供一个 API 不就好了?- [producer-consumer.go](http://jyywiki.cn/pages/OS/2022/demos/producer-consumer.go)- 缓存为 0 的 channel 可以用来同步 (先到者等待)<a name="pAdln"></a>## 总结- 并发编程的真实应用场景- **高性能计算 (**注重任务分解): 生产者-消费者 (MPI/OpenMP)- **数据中心** (注重系统调用): 线程-协程 (Goroutine)- **人机交互** (注重易用性): 事件-流图 (Promise)- 编程工具的发展突飞猛进- 自 Web 2.0 以来,开源社区改变了计算机科学的学习方式- 希望每个同学都有一个 “主力现代编程语言”- Modern C++, Rust, Javascript, ...<a name="ldjPC"></a># 8. 并发 Bug 和应对<a name="bak5q"></a>## 应对 Bug 的方法<a name="Kkswk"></a>### 防御性编程<a name="Nx6AY"></a>## 并发 Bug: 死锁(Deadlock)<a name="ATYPG"></a>### AA-Deadlock假设你的 spinlock 不小心发生了中断- 在不该打开中断的时候开了中断- 在不该切换的时候执行了 yield()```cvoid os_run() {spin_lock(&list_lock);spin_lock(&xxx);spin_unlock(&xxx); // ---------+} // |// |void on_interrupt() { // |spin_lock(&list_lock); // <--+spin_unlock(&list_lock);}
ABBA-Deadlock
void swap(int i, int j) {spin_lock(&lock[i]);spin_lock(&lock[j]);arr[i] = NULL;arr[j] = arr[i];spin_unlock(&lock[j]);spin_unlock(&lock[i]);}
上锁的顺序很重要……
swap 本身看起来没有问题
- swap(1, 2); swap(2, 3), swap(3, 1) → 死锁
- philosopher.c
避免死锁
死锁产生的四个必要条件 (Edward G. Coffman, 1971):
互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程请求资阻塞时,不释放已获得的资源
- 不剥夺:进程已获得的资源不能强行剥夺
循环等待:若干进程之间形成头尾相接的循环等待资源关系 :::info “理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。” ——Bullshit. ::: AA-Deadlock
AA 型的死锁容易检测,及早报告,及早修复
- spinlock-xv6.c 中的各种防御性编程
- if (holding(lk)) panic();
ABBA-Deadlock
- 任意时刻系统中的锁都是有限的
- 严格按照固定的顺序获得所有锁 (lock ordering; 消除 “循环等待”)
- 遇事不决可视化:lock-ordering.py
- 进而证明 T1:A→B→C;T2:B→C 是安全的
- “在任意时刻总是有获得 “最靠后” 锁的可以继续执行”
并发 Bug: 数据竞争(Data Race)
以下代码概括了你们遇到数据竞争的大部分情况// Case #1: 上错了锁void thread1() { spin_lock(&lk1); sum++; spin_unlock(&lk1); }void thread2() { spin_lock(&lk2); sum++; spin_unlock(&lk2); }
// Case #2: 忘记上锁void thread1() { spin_lock(&lk1); sum++; spin_unlock(&lk1); }void thread2() { sum++; }
- “在任意时刻总是有获得 “最靠后” 锁的可以继续执行”
回顾我们实现并发控制的工具
- 互斥锁 (lock/unlock) - 原子性
- 条件变量 (wait/signal) - 同步
忘记上锁——原子性违反 (Atomicity Violation, AV)
忘记同步——顺序违反 (Order Violation, OV)
Empirical study: 在 105 个并发 bug 中 (non-deadlock/deadlock)
- MySQL (14/9), Apache (13/4), Mozilla (41/16), OpenOffice (6/2)
-
应对并发 Bug 的方法
Lockdep: 运行时的死锁检查
ThreadSanitizer: 运行时的数据竞争检查
为所有事件建立 happens-before 关系图
Program-order + release-acquire
对于发生在不同线程且至少有一个是写的 x,y 检查x≺y∨y≺x
Lockdep: lock/unlock
- ThreadSanitizer: 内存访问 + lock/unlock
解析记录检查问题
- Lockdep: x⇝y∧y⇝x
- ThreadSanitizer: x⊀y∧y⊀x
付出的代价和权衡
- 程序执行变慢
-
动态分析工具:Sanitizers
AddressSanitizer (asan); (paper): 非法内存访问
- ThreadSanitizer (tsan): 数据竞争
- Demo: fish.c, sum.c, peterson-barrier.c; ktsan
- MemorySanitizer (msan): 未初始化的读取
UBSanitizer (ubsan): undefined behavior
统计当前的 spin count
- 如果超过某个明显不正常的数值 (1,000,000,000) 就报告
int spin_cnt = 0;while (xchg(&locked, 1)) {if (spin_cnt++ > SPIN_LIMIT) {printf("Too many spin @ %s:%d\n", __FILE__, __LINE__);}}
- 如果超过某个明显不正常的数值 (1,000,000,000) 就报告
-
防御性编程:低配版 Sanitizer (L1)
内存分配要求:已分配内存 S=[ℓ0,r0)∪[ℓ1,r1)∪…
kalloc(s) 返回的 [ℓ,r) 必须满足 [ℓ,r)∩S=∅
- thread-local allocation + 并发的 free 还蛮容易弄错的 ```c // allocation for (int i = 0; (i + 1) sizeof(u32) <= size; i++) { panic_on(((u32 )ptr)[i] == MAGIC, “double-allocation”); arr[i] = MAGIC; }
// free for (int i = 0; (i + 1) sizeof(u32) <= alloc_size(ptr); i++) { panic_on(((u32 )ptr)[i] == 0, “double-free”); arr[i] = 0; }
<a name="BPt8A"></a>## 总结- 常见的并发 bug- 死锁、数据竞争、原子性/顺序违反- 不要盲目相信自己:检查、检查、检查- 防御性编程:检查- 动态分析:打印 + 检查<a name="cS762"></a># 9. 操作系统的状态机模型详见:[http://jyywiki.cn/OS/2022/slides/9.slides#/](http://jyywiki.cn/OS/2022/slides/9.slides#/)<a name="STqRZ"></a>## 硬件和软件的桥梁<a name="FMZYM"></a>### C 程序我们已经知道如何写一个 “最小” 的 C 程序了:- [minimal.S](http://jyywiki.cn/pages/OS/2022/demos/minimal.S)- 不需要链接任何库,就能在操作系统上运行“程序 = 状态机” 没问题- 带来更多的疑问- 但谁创建的这个状态机???- 当然是操作系统了……呃……- 这个程序可以在没有操作系统的硬件上运行吗?- “启动” 状态机是由 “加载器” 完成的- 加载器也是一段程序 (状态机)- 这个程序由是由谁加载的?<a name="cDDzC"></a>### Bare-metal 与程序员的约定为了让计算机能运行任何我们的程序,一定存在软件/硬件的约定- CPU reset 后,处理器处于某个确定的状态- PC 指针一般指向一段 memory-mapped ROM- ROM 存储了厂商提供的 firmware (固件)- 处理器的大部分特性处于关闭状态- 缓存、虚拟存储、……- Firmware (固件,厂商提供的代码)- 将用户数据加载到内存- 例如存储介质上的第二级 loader (加载器)- 或者直接加载操作系统 (嵌入式系统)<a name="F64U1"></a>### CPU Reset 之后:发生了什么?《计算机系统基础》:不仅是程序,整个计算机系统也是一个状态机- 从 PC (CS:IP) 指针处取指令、译码、执行……- 从 firmware 开始执行- ffff0 通常是一条向 firmware 跳转的 jmp 指令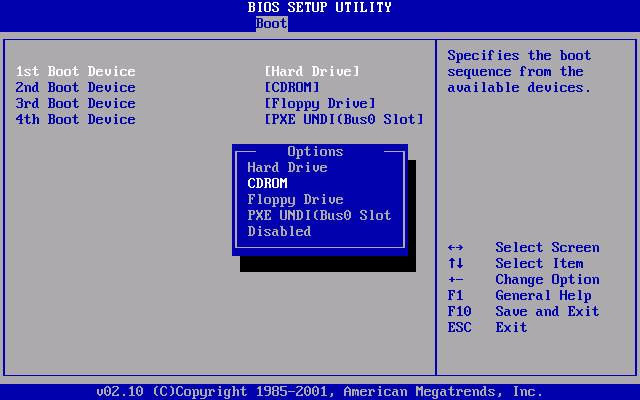<br />Firmware: [BIOS vs. UEFI](https://www.zhihu.com/question/21672895)- 都是主板/主板上外插设备的软件抽象- 支持系统管理程序运行- Legacy BIOS (Basic I/O System)- UEFI (Unified Extensible Firmware Interface)<a name="QltB0"></a>### Legacy BIOS: 约定Firmware 必须提供机制,将用户数据载入内存- Legacy BIOS 把第一个可引导设备的第一个扇区加载到物理内存的 7c00 位置- 此时处理器处于 16-bit 模式- 规定 CS:IP = 0x7c00, (R[CS] << 4) | R[IP] == 0x7c00- 可能性1:CS = 0x07c0, IP = 0- 可能性2:CS = 0, IP = 0x7c00- 其他没有任何约束计算机系统公理:你想到的就一定有人做到。- 模拟方案:QEMU- 传奇黑客、天才程序员 [Fabrice Bellard](https://www.zhihu.com/question/28388113) 的杰作- [QEMU, A fast and portable dynamic translator](https://www.usenix.org/legacy/publications/library/proceedings/usenix05/tech/freenix/full_papers/bellard/bellard.pdf) (USENIX ATC'05)- Android Virtual Device, VirtualBox, ... 背后都是 QEMU- 真机方案:JTAG (Joint Test Action Group) debugger- 一系列 (物理) 调试寄存器,可以实现 gdb 接口 (!!!)<a name="gZllV"></a>### 鸡和蛋的问题解决有个原始的鸡:Firmware- 代码直接存在于硬件里- CPU Reset 后 Firmware 会执行- 加载 512 字节到内存 (Legacy Boot)- 然后功成身退Firmware 的另一用处- 放置一些 “绝对安全的代码”- [BIOS 中断](http://jyywiki.cn/pages/OS/manuals/BIOS-interrupts.pdf) (Hello World 是如何被打印的)- ARM Trusted Firmware- Boot-Level 1, 2, 3.1, 3.2, 3.3- [U-Boot](https://www.denx.de/wiki/U-Boot): the universal boot loader<a name="hGNMY"></a>### 今天的 Firmware: UEFIIBM PC 所有设备/BIOS 中断是有 specification 的 (成就了 “兼容机”)- 今天的 boot loader 面临麻烦得多的硬件:- 指纹锁、不知名厂商生产网卡上的网络启动、USB 上的蓝牙转接器连接的蓝牙键盘、……<a name="ydgGx"></a>### UEFI 上的操作系统加载标准化的加载流程- 盘必须按 GPT (GUID Partition Table) 方式格式化- 预留一个 FAT32 分区 (lsblk/fdisk 可以看到)- Firmware 加载任意大小的 PE 可执行文件 .efi- 没有 legacy boot 512 字节限制- EFI 应用可以返回 firmware更好的程序支持- 设备驱动框架- 更多的功能,例如 Secure Boot,只能启动 “信任” 的操作系统<a name="RFRYp"></a>## 操作系统的状态机模型<a name="ruZot"></a>### “操作系统” 的状态机已经启动Firmware 和 boot loader 共同完成 “操作系统的加载”- 初始化全局变量和栈;分配堆区 (heap)- 为 main 函数传递参数- 谁给操作系统传递了参数?- 如何实现参数传递?进入 C 代码之后- 完全遵循 C 语言的形式语义- 但有一些行为 “补充” —— AbstractMachine API<a name="j3y5A"></a>### 操作系统:是个 C 程序一个迷你 “操作系统” [thread-os.c](http://jyywiki.cn/pages/OS/2022/demos/thread-os.c)- make 会得到一个 “磁盘镜像”,好像魔法一样- 就跟你们第一次用 IDE 的时候按一个键就可以编译运行一样```cint main() {cte_init(on_interrupt);for (int i = 0; i < LENGTH(tasks); i++) {Task *task = &tasks[i];Area stack = (Area) { &task->context + 1, task + 1 };task->context = kcontext(stack, task->entry, (void *)task->name);task->next = &tasks[(i + 1) % LENGTH(tasks)];}mpe_init(mp_entry);}
总结
- 一切皆可调试 (包括 firmware)
- 理解操作系统是如何被启动的
- 学会使用 gdb (必备生存技能)
操作系统也是程序
- AbstractMachine 扩展了程序的语义,仅此而已
10. 状态机模型的应用
详见:http://jyywiki.cn/OS/2022/slides/10.slides#/查看状态机的执行
Trace 和调试器
程序执行 = 状态机执行
- AbstractMachine 扩展了程序的语义,仅此而已
我们能不能 “hack” 进这个状态机
record full - 开始记录
- record stop - 结束记录
- reverse-step/reverse-stepi - “时间旅行调试”
例子:调试 rdrand.c
Reverse execution 不是万能的
中断就可以做到
- 将状态 s→s′ “记账”
- 执行的语句
- 函数调用栈
- 服务的请求
- 得到统计意义的性能摘要
例子:Linux Kernel perf (支持硬件 PMU) - ilp-demo.c
perf list, perf stat (-e), perf record, perf report
实际中的性能优化
你们遇到的大部分情况
二八定律:80% 的时间消耗在非常集中的几处代码
- L1 (pmm): 小内存分配时的 lock contention
- profiler 直接帮你解决问题
工业界遇到的大部分情况
木桶效应:每个部分都已经 tune 到局部最优了
- 剩下的部分要么 profiler 信息不完整,要么就不好解决
- (工程师整天都对着 profiler 看得头都大了)
- The flame graph (CACM’16)
Model Checker/Verifier
一些真正的 model checkers
TLA+ by Leslie Lamport;
KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs (OSDI’08, Best Paper 🏅)
-
11. 操作系统上的进程
详见:http://jyywiki.cn/OS/2022/slides/11.slides#/
操作系统启动后到底做了什么
从系统启动到第一个进程
回顾 thread-os.c 的加载过程
CPU Reset → Firmware → Boot loader → Kernel _start()
操作系统会加载 “第一个程序”
- RTFSC (latest Linux Kernel)
- 如果没有指定启动选项 init=,按照 “默认列表” 尝试一遍
- 从此以后,Linux Kernel 就进入后台,成为 “中断/异常处理程序”
程序:状态机
- C 代码视角:语句
- 汇编/机器代码视角:指令
-
定制最小的 Linux
有存储设备,只有包含两个文件的 “initramfs”
-
$ tree ..├── bin│ └── busybox (可以在我们的Linux里直接执行)└── init
加上 vmlinuz (内核镜像) 就可以在 QEMU 里启动了
可以直接在文件系统中添加静态链接的二进制文件 -
应用程序视角的操作系统
Linux 操作系统启动流程
CPU Reset → Firmware → Loader → Kernel _start() → 第一个程序 /bin/init → 程序 (状态机) 执行 + 系统调用
操作系统为 (所有) 程序提供 API
- 进程 (状态机) 管理
- fork, execve, exit - 状态机的创建/改变/删除 ← 今天的主题
- 存储 (地址空间) 管理
- mmap - 虚拟地址空间管理
文件 (数据对象) 管理
初始状态:main(argc, argv)
- 程序可以直接在处理器上执行
虚拟化:操作系统在物理内存中保存多个状态机
int fork();
int execve(const char filename, char const argv, char * const envp);
- 执行名为 filename 的程序
允许对新状态机设置参数 argv (v) 和环境变量 envp (e)
- 刚好对应了 main() 的参数!
- execve-demo.c
_exit()
状态机管理:终止状态机
UNIX 的答案: _exit
立即摧毁状态机
void _exit(int status)
- 销毁当前状态机,并允许有一个返回值
-
结束程序执行的三种方法
exit 的几种写法 (它们是不同)
exit(0) - stdlib.h 中声明的 libc 函数
- 会调用 atexit
- _exit(0) - glibc 的 syscall wrapper
- 执行 “exit_group” 系统调用终止整个进程 (所有线程)
- 不会调用 atexit
- syscall(SYS_exit, 0)
- 执行 “exit” 系统调用终止当前线程
- 不会调用 atexit
结束当前进程执行的四种方式
- return, exit, _exit, syscall
对 “操作系统” 的完整理解
- CPU Reset → Firmware → Loader → Kernel _start() → 执行第一个程序 /bin/init → 中断/异常处理程序
- 一个最小的 Linux 系统的例子
- 进程管理 API
- fork, execve, exit: 状态机的复制、重置、销毁
- 理论上就可以实现 “各种功能” 了!
12. 进程的地址空间
详见:http://jyywiki.cn/OS/2022/slides/12.slides#/
进程的地址空间
查看进程的地址空间
地址空间的隔离
修改内存
我们可以改内存,也可以改代码!
The Light Side
- “软件热补丁” dsu.c (mprotect)
Ksplice: Automatic rebootless Kernel updates (EuroSys’09)
总结
问题:进程的地址空间是如何创建的,如何更改的
进程的地址空间
- 能文件关联的、带有访问权限的连续内存段
进程地址空间的管理API
- mmap
13. 系统调用和 Shell
详见:http://jyywiki.cn/OS/2022/slides/13.slides#/Shell
为用户封装操作系统 API
这就是 Shell (内核 Kernel 提供系统调用;Shell 提供用户接口)
- mmap
“与人类直接交互的第一个程序”
-
The UNIX Shell
“终端” 时代的伟大设计
“Command-line interface” (CLI) 的巅峰
Shell 是一门 “把用户指令翻译成系统调用” 的编程语言
终端和 Job Control
终端是 UNIX 操作系统中一类非常特别的设备!
-
Session, Process Group 和信号
SIGSEGV 和 SIGFPE
大家熟悉的 Segmentation Fault/Floating point exception (core dumped)
GP, #PF 或 #DIV
- UNIX 系统会给进程发送一个信号
- 此时可以生成一个 “core” 文件 (ELF 格式),能用 gdb 调试
UNIX (System V) 信号其实是有一些 dark corners 的
如果 SIGSEGV 里再次 SIGSEGV?
- POSIX.1 solved the portability mess by specifying sigaction(2), which provides explicit control of the semantics when a signal handler is invoked; use that interface instead of signal().
The PGID (process-group ID) is preserved across an execve(2) and inherited in fork(2)…
- Each process group is a member of a session
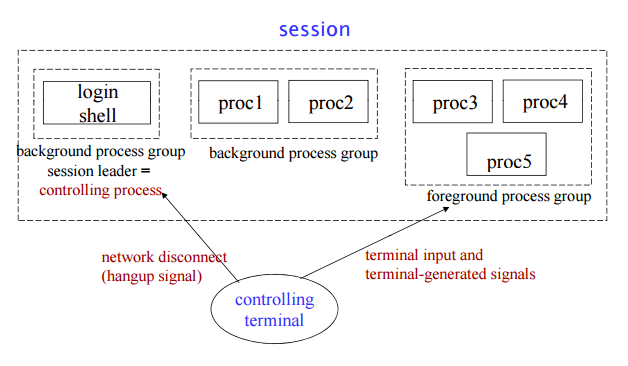
A session can have a controlling terminal.
- At any time, one (and only one) of the process groups in the session can be the foreground process group for the terminal; the remaining process groups are in the background.
- ./a.out & 创建新的进程组 (使用 setpgid)
- If a signal is generated from the terminal (e.g., typing the interrupt key to generate SIGINT), that signal is sent to the foreground process group.
- Ctrl-C 是终端 (设备) 发的信号,发给 foreground 进程组
- 所有 fork 出的进程 (默认同一个 PGID) 都会收到信号
- 可以修改 signal-handler.c 观察到这个行为
- At any time, one (and only one) of the process groups in the session can be the foreground process group for the terminal; the remaining process groups are in the background.
Only the foreground process group may read(2) from the terminal; if a background process group tries to read(2) from the terminal, then the group is sent a SIGTTIN signal, which suspends it.
- 这解释了 cat & 时你看到的 “suspended (tty input)”
- 同一个进程组的进程 read tty 会竞争
- signal-handler.c 同样可以观察到这个行为
The setpgid() and getpgrp() calls are used by programs such as bash(1) to create process groups in order to implement shell job control.
一个功能完整的 Shell 使用的操作系统对象和 API
- session, process group, controlling terminal
- 文件描述符:open, close, pipe, dup, read, write
- 状态机管理:fork, execve, exit, wait, signal, kill, setpgid, getpgid, …
14. C 标准库的实现
详见:http://jyywiki.cn/OS/2022/slides/14.slides#/libc
任何程序都用得上的定义
Freestanding 环境下也可以使用的定义
stddef.h - size_t
- stdint.h - int32_t, uint64_t
- stdbool.h - bool, true, false
- float.h
- limits.h
- stdarg.h
- syscall 就用到了 (但 syscall0, syscall1, … 更高效)
string.h: 字符串/数组操作
-
封装 (2): 文件描述符
stdio.h
FILE * 背后其实是一个文件描述符
-
封装 (3): 更多的进程/操作系统功能
err, error, perror
-
封装 (4): 地址空间
malloc 和 free
RTFM: The GNU C Library, RTFSC: Newlib
总结
- libc
- RTFM; RTFSC: 充满了宝藏
- 性能优化中的 fast/slow path
-
15. Fork 的应用
详见:https://jyywiki.cn/OS/2022/slides/15.slides#/
fork 补充
-
状态机、fork() 和魔法
帮助我们
理解物理世界 (Cellular Automata)
- 理解处理器、操作系统
- 调试 (record-replay)、profiler
- Model checker 和 program verifier
fork() 可以复制状态机?
- 感觉是一个非常 “强大” 的操作
-
搜索并行化
跳过初始化
备份和容错
状态机复制
Afork()in the road (HotOS’19)
fork: UNIX 时代的遗产
fork + execve
如果只有内存和文件描述符,这是十分优雅的方案
- 但贪婪的人类怎么可能满足?
在操作系统的演化过程中,为进程增加了更多的东西
- 信号 (信号处理程序,操作系统负责维护)
- 线程 (Linux 为线程提供了 clone 系统调用)
- 进程间通信对象
- ptrace (追踪/调试)
-
创建进程:POSIX Spawn
int posix_spawn(pid_t *pid, char *path,posix_spawn_file_actions_t *file_actions,posix_spawnattr_t *attrp,char * argv[], char * envp[]);
参数
pid: 返回的进程号
- path: 程序 (重置的状态机)
- file_actions: open, close, dup
- attrp: 信号、进程组等信息
argv, envp: 同 execve
Fork is no longer simple
- Fork doesn’t compose - fork-printf.c
- Fork isn’t thread-safe
- Fork is insecure - 打破了 Address Space Layout Randomization
- Fork is slow - 的确……
- Fork doesn’t scale - 也是……
- Fork encourages memory overcommit - 呃……
但 fork() 是魔法啊:这引起了更多的思考
17. 动态链接和加载
问题
- go 是 C/C++ 实现的吗?最早是,后又实现了自举。
- rust 是 C/C++ 实现的吗?
参考

若有收获,就点个赞吧
0 人点赞
