数组(Array)
是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。

特性:
随机访问:根据数组下标的随机访问,时间复杂度O(1)
低效的插入、删除:为了保证数组内存连续性,会对数组元素进行位置移动
链表(Linked list)
是一种线性的数据结构。它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用
查询时间复杂度O(n),更新、删除时间复杂度O(1)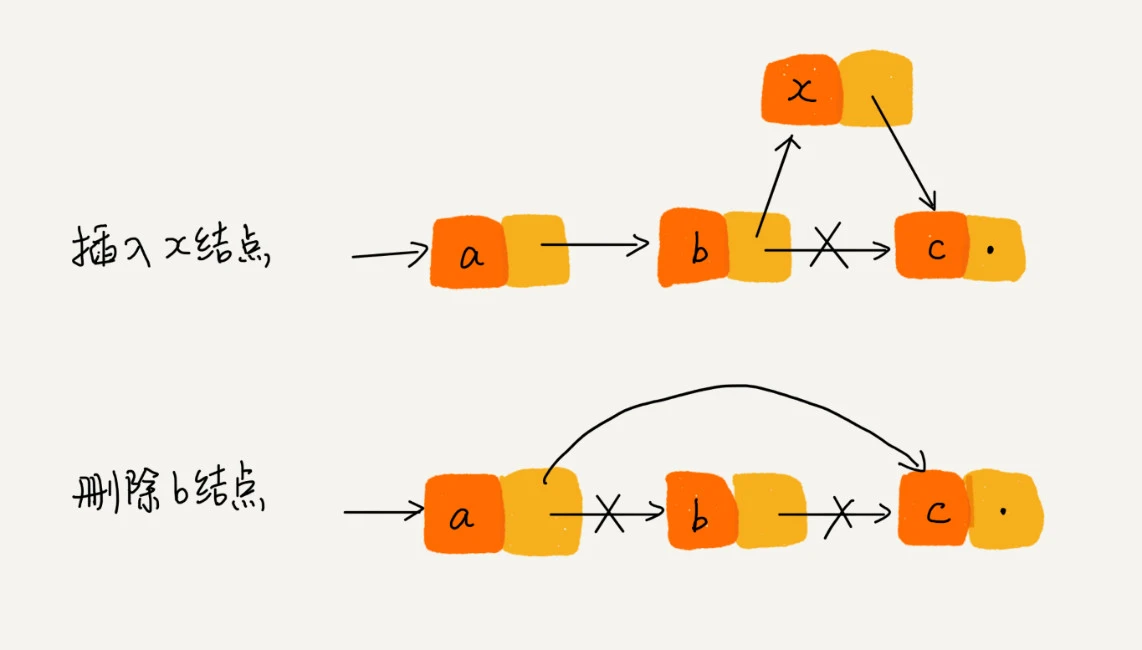
- 单链表

- 循环链表(特殊的单向链表)

- 双向链表


数组 VS 链表

数组扩容需要进行数据复制,效率较低、链表天然支持动态扩容,因为指针节点存在,占用内存较多
链表代码的编写
- 理解指针或引用的含义
- 警惕指针丢失和内存泄漏
- 利用哨兵简化实现难度
- 重点留意边界条件处理
如果链表为空时,代码是否能正常工作?
如果链表只包含一个结点时,代码是否能正常工作?
如果链表只包含两个结点时,代码是否能正常工作?
代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
- 举例画图,辅助思考

- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
栈
栈是一种“操作受限”的线性表,只允许在一端插入和删除数据
栈可以用数组实现,称为顺序栈。也可以用链表实现,称为链式栈

队列
一种操作受限的线性表数据结构
用数组实现的队列叫作顺序队列

存在当不断入队达到数组长度后,即使有空间也无法入队的情况,可以使用数据迁移的方式来解决,最好操作时间点是在队满之后进行迁移,降低时间复杂度为O(1),均摊了
用链表实现的队列叫作链式队列
- 循环队列:使用循环队列可以避免出现数组出现的数据迁移问题

- 阻塞队列:生产者 - 消费者模型
就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回
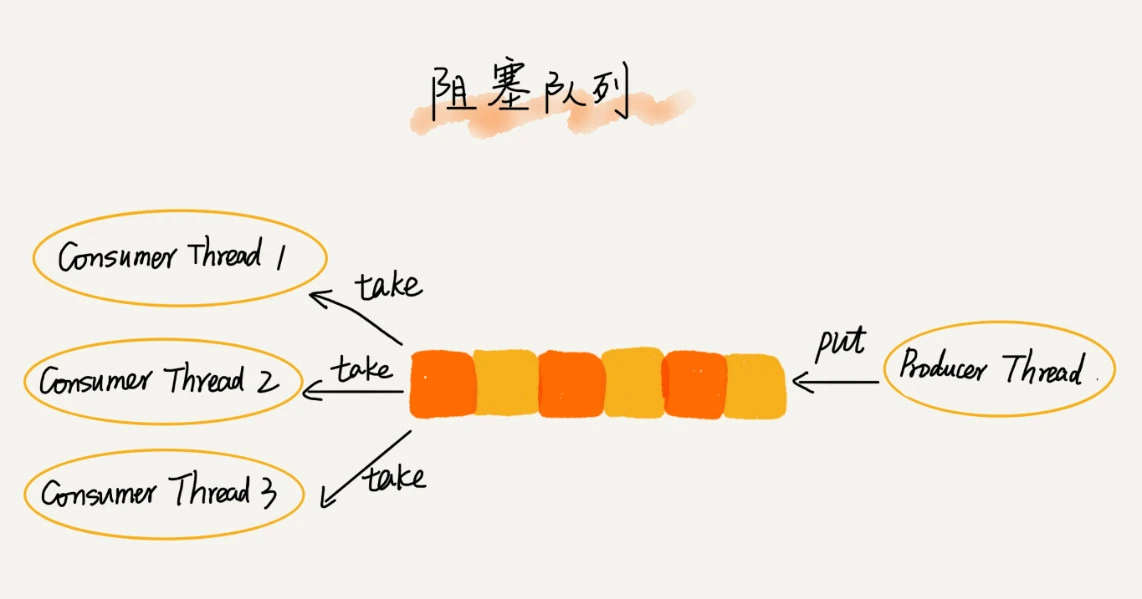
- 并发队列
最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。实际上,基于数组的循环队列,利用 CAS 原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因
跳表
链表加多级索引的结构,动态数据结构,可以支持快速地插入、删除、查找操作,写起来也不复杂,甚至可以替代红黑树(Red-black tree),redis(sorted set)使用该数据结构实现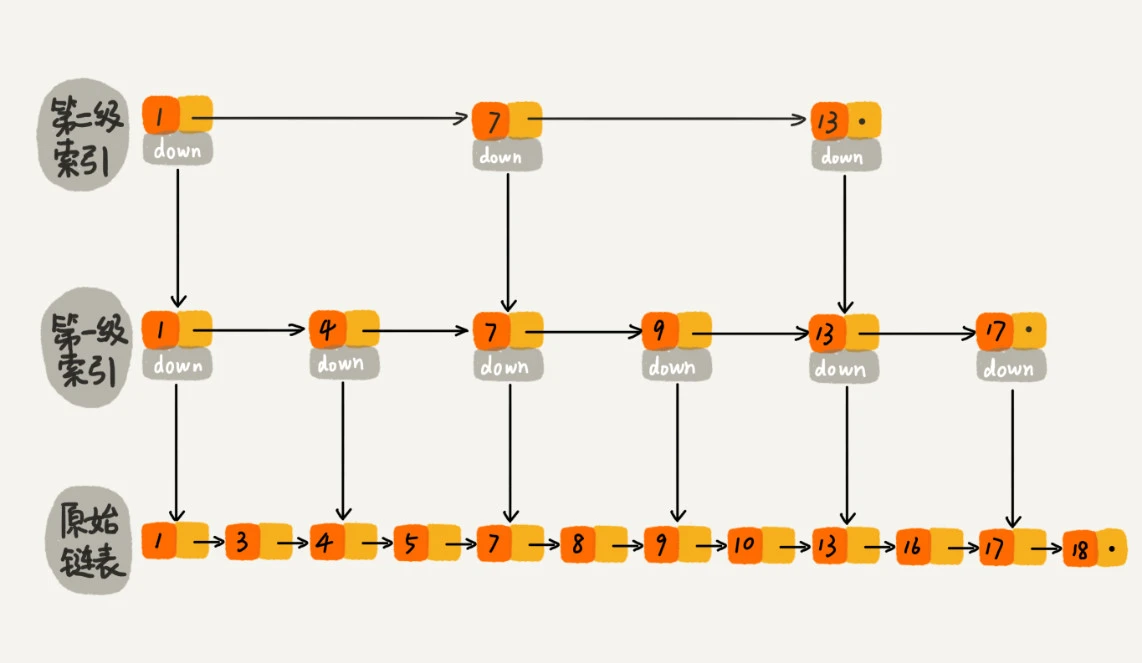

散列表
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据
该如何构造散列函数呢?
我总结了三点散列函数设计的基本要求:
散列函数计算得到的散列值是一个非负整数;
如果 key1 = key2,那 hash(key1) == hash(key2);
如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
但是在真实的情况下,要想找到一个不同的 key 对应的散列值都不一样的散列函数,几乎是不可能的。即便像业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。而且,因为数组的存储空间有限,也会加大散列冲突的概率。
散列冲突解决方法有两类,
开放寻址法(open addressing): 线性探测
当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的ThreadLocalMap使用开放寻址法解决散列冲突的原因
链表法(chaining)
基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表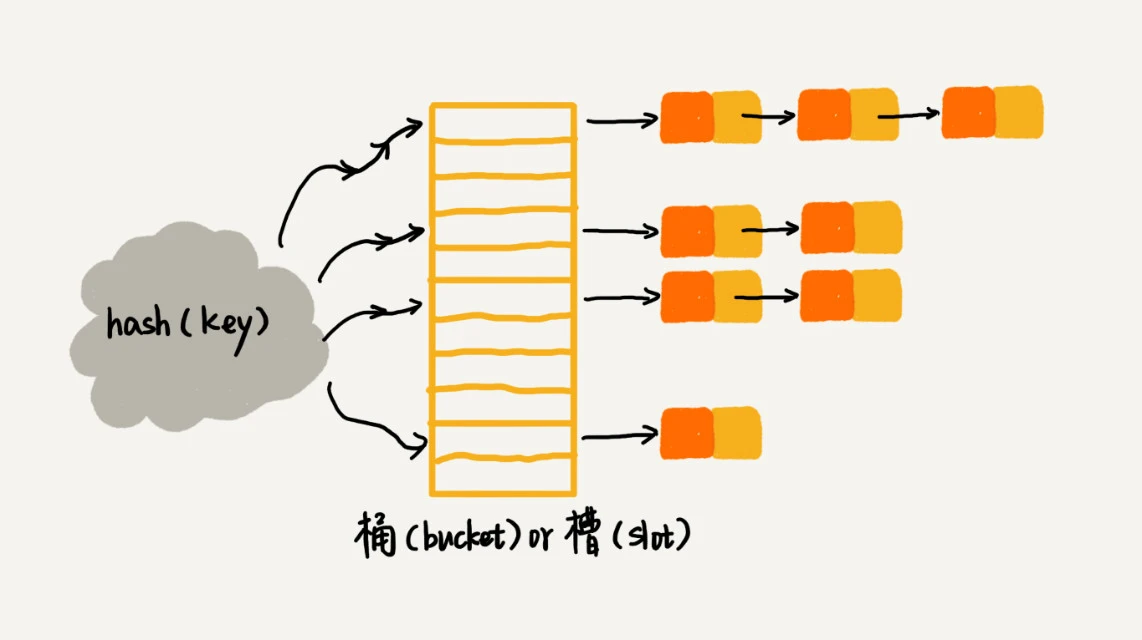
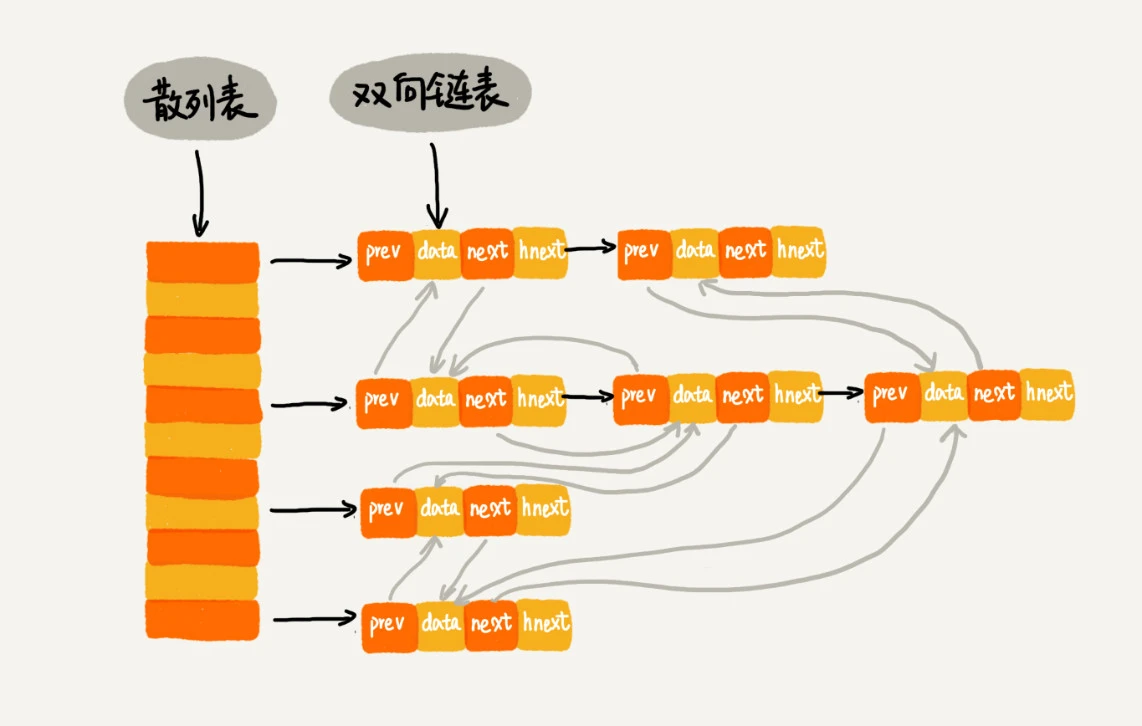
一个链是刚刚我们提到的双向链表,另一个链是散列表中的拉链。前驱和后继指针是为了将结点串在双向链表中,hnext 指针是为了将结点串在散列表的拉链中。
为什么散列表和链表经常一块使用?
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那我们需要将散列表中的数据拷贝到数组中,然后排序,再遍历。因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当我们希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
树(Tree)

二叉树
支持动态数据集合的快速插入、删除、查找操作
顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。
满二叉树:叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树。
完全二叉树:叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树
二叉树存储方式:一种是基于指针或者引用的二叉链式存储法,一种是基于数组的顺序存储法。
链式存储法
顺序存储法
二叉树遍历:前序遍历、中序遍历和后序遍历
- 前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
- 中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
- 后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身

二叉查找树(Binary Search Tree)
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值
二叉查找树在比较平衡的情况下,插入、删除、查找操作时间复杂度才是 O(logn),相对散列表,好像并没有什么优势,那我们为什么还要用二叉查找树呢?
第一,散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
第二,散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
第四,散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
最后,为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的散列表,不然会浪费一定的存储空间。
平衡二叉树
二叉树中任意一个节点的左右子树的高度相差不能大于 1。从这个定义来看,上一节我们讲的完全二叉树、满二叉树其实都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树。
通俗理解:平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些
红黑树:特殊的平衡二叉树
顾名思义,红黑树中的节点,一类被标记为黑色,一类被标记为红色。除此之外,一棵红黑树还需要满足这样几个要求:根节点是黑色的;每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
红黑树是一种平衡二叉查找树。它是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。红黑树的高度近似 log2n,所以它是近似平衡,插入、删除、查找操作的时间复杂度都是 O(logn)。因为红黑树是一种性能非常稳定的二叉查找树,所以,在工程中,但凡是用到动态插入、删除、查找数据的场景,都可以用到它。

若有收获,就点个赞吧
0 人点赞
