我本人比较喜欢编程,这点要归功于我大一上时的C++老师。当时第一节课上他就说,这门课我不教你一些C++语法方面的细节,我只教你如何将C++作为一个工具完成一些工程实践性的问题。我深以为然,中国大学里这样并非只是所谓的照本宣科的老师真的是“稀有至极”。这不最近兴致又上来了,所以我想重新体验以下编程的快乐。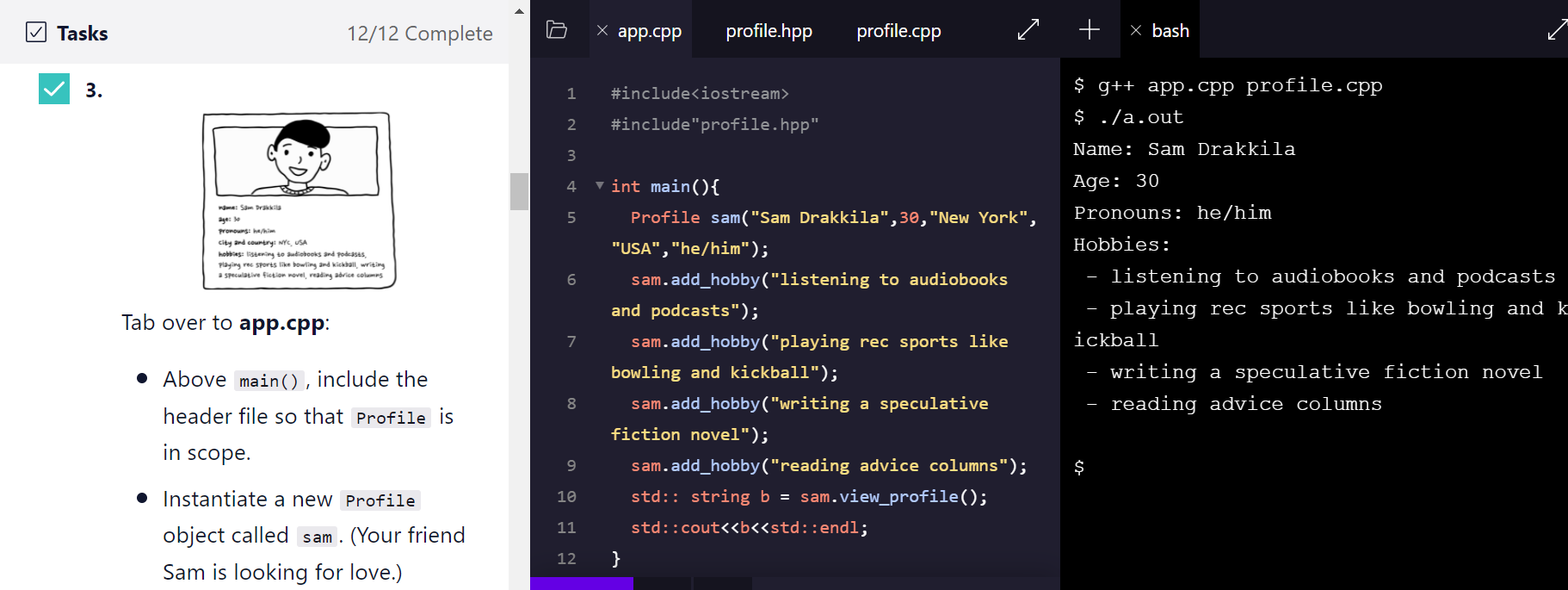
我本人将来研究生期间是有转码的考虑的(宇宙机万岁!),所以从现在开始至少保持编程的手感还是很有好处的。我找了几个相关的途径来练习C++编程。一个是CodeCademy,一个是大一下时的一个课程设计大作业。下面来具体讲讲这两个途径的编程练习。
CodeCademy编程
不得不说,CodeCademy上面的Project是真的简单,我个人觉得比较适合新手小白。CodeCademy上面的一些instruction也是对新手比较友好,但是难度确实很低,所以我就不详细展开说了。
我完成的这个项目是:帮助一个相亲网站写一个类管理相亲网站上的个人信息,主要用文件管理(hpp\cpp等)、vector、string和C++类的相关知识。下面是相关代码:
主文件CPP
#include<iostream>#include"profile.hpp"int main(){Profile sam("Sam Drakkila",30,"New York","USA","he/him");sam.add_hobby("listening to audiobooks and podcasts");sam.add_hobby("playing rec sports like bowling and kickball");sam.add_hobby("writing a speculative fiction novel");sam.add_hobby("reading advice columns");std:: string b = sam.view_profile();std::cout<<b<<std::endl;}
类HPP
#include<vector>class Profile{private:std::string name;int age;std::string city;std::string country;std::string pronouns;std::vector<std::string> hobbies;public:Profile(std::string new_name, int new_age, std::string new_city, std::string new_country, std::string new_pronouns = "they/them");std::string view_profile();void add_hobby(std::string new_hobby);};
类CPP
#include<iostream>#include"profile.hpp"Profile::Profile(std::string new_name, int new_age, std::string new_city, std::string new_country, std::string new_pronouns): name(new_name), age(new_age), city(new_city), country(new_country), pronouns(new_pronouns) {}std::string Profile::view_profile() {std::string bio = "Name: " + name;bio += "\nAge: " + std::to_string(age);bio += "\nPronouns: " + pronouns;std::string hobby_string = "Hobbies:\n";for (std::string hobby : hobbies) {hobby_string += " - " + hobby + "\n";}return bio + "\n" + hobby_string;}void Profile::add_hobby(std::string new_hobby){hobbies.push_back(new_hobby);}
算法基础与数据结构
个人觉得C++用来实现算法与数据结构非常好,这点可以参考我的另外一篇语雀文章:https://www.yuque.com/beifengchuisanzhiyue/lz5gx3/rwg1x1
大一下C++课程设计作业
当时我们总共是有八个题目可以选择,下面这个题目“自动寻找论文的核心句:不是我当时选择的,但是现在大三下回头来再看,感觉这个项目挺有意思的。
课程设计题目
自动寻找论文的核心句
题目:自动寻找论文的核心句
项目要求:对给定的一篇英文科技文章,找出其若干核心句;
说明:这类算法在文本挖掘引擎等的设计中极为有用,是人工智能的一个应用热点领域。该项目可以使学生了解当前人工智能领域的工程项目在做什么,以及怎么实现。
思路:在2007年的一期《Science》杂志上,多伦多大学的Frey教授等人给出了一种极为简单的算法,该算法称为AP(Affinity Propagation),其核心代码只有20行(用类似C语言语法的matlab编写)。该算法的应用例子之一“DETECTING REPRESENTATIVE SENTENCES IN A MANUSCRIPT”即可完成英文文章核心句的自动寻找。事实上,简单的统计方法或聚类方法都能完成核心句的自动寻找。
拓展:英文——中文 / 文字——图片等
图像处理小程序
题目:图像处理小程序
项目要求:
(1) 常用的图像处理算法之一。请在了解图像缩放的原理的基础上,编写一个自定义的图像缩放、翻转、镜像和反色,256色灰度图像,并进行测试,实现类似于“美图秀秀”的功能。
(2) 可以实现简单的图像自动处理:例如随机读取一张8位灰度图像,然后实行二值化分割,对其中的孔洞进行种子填充,并计算孔洞的个数。
拓展:美颜功能,或在(2)的基础上结合更多的现实场景应用。
多项式曲线拟合
题目:多项式曲线拟合
项目要求:根据方程
其中 为添加的噪声(小的随机实数)。在[-4, 4]区间随机产生100个点,然后对这些点用多项式进行拟合。确定多项式方程,并绘制在屏幕上。
为添加的噪声(小的随机实数)。在[-4, 4]区间随机产生100个点,然后对这些点用多项式进行拟合。确定多项式方程,并绘制在屏幕上。
拓展:更多的拟合方式,配合工程应用,比如软测量等。
解决方案及代码
我写了下“自动寻找论文的核心句”的解决方案。
当时看到这个题目的想法就是应该需要用到vector类、string类和其他一些类的知识,然后自己也去网上找了一些关于文本挖掘、核心句检测等方面的算法,有如下几个算法:
- TF-IDF算法
- PageRank算法
- ExpandRank算法
- 其他
具体内容可以参考知乎这一篇文章:https://zhuanlan.zhihu.com/p/377737998
我个人认为寻找核心句的思路如下所示:
- 论文的核心句大概率出现在摘要里,所以我们先对摘要进行提取和分析
- 论文核心句常以We开头,这是一个规律
- 论文核心词不会是介词和一些通用词
- 句子中有build,use,model,method类字眼的更有可能是超级核心句
导入库与创建哈希表类
为什么要导入哈希表类,主要是因为想将单词根据首字母放进哈希表中,然后方便后续的查找和比对,事实上这是哈希表一个非常常见的用法。
导入库与创建哈希表类:
#include<iostream>#include<cstdlib>#include<cstdio>#include<sstream>#include<fstream>#include<string>#include<vector>#include<cctype>#include<cmath>using namespace std;//类的定义部分//类的定义部分//类的定义部分//先定义下链表和哈希表class Node{private:string value;Node* next;public:Node(){value = "";next = NULL;}string Getvalue() { return this->value; }Node* Getnext() { return this->next; }void Setvalue(string num) { value = num; }void Setnext(Node* a) { next = a; }};class Nodearray{private:Node* head;Node* tail;public:Nodearray(){head = NULL;tail = NULL;}Node* Gethead() { return this->head; }void Sethead(Node* a) { this->head = a; }void Settail(Node* a) { this->tail = a; }Node* Gettail() { return this->tail; }void Addnum(string num){if (head == NULL){head = new Node;head->Setvalue(num);head->Setnext(NULL);tail = head;}else{tail->Setnext(new Node);(tail->Getnext())->Setvalue(num);(tail->Getnext())->Setnext(NULL);tail = tail->Getnext();}}void Display(){Node* p = head;if (head == NULL) return;else{while (p != NULL){cout << p->Getvalue() << " ";p = p->Getnext();}}cout << endl;}void Getnum(int pos){int count = 1;Node* p = head;while (p != NULL){if (count == pos){cout << "找到了! ";cout << p->Getvalue() << endl;return;}p = p->Getnext();count++;}cout << "没找到!" << endl;}void Delnum(string num){Node* p1 = head;Node* p2 = head;if (head == NULL){cout << "这是空列表" << endl;return;}else{if (head->Getvalue() == num){head = head->Getnext();return;}else{p2 = p2->Getnext();}while (p2 != NULL){if (p2->Getvalue() == num){p1->Setnext(p2->Getnext());cout << "删除成功" << endl;return;}p1 = p1->Getnext();p2 = p2->Getnext();}}}};//定义哈希表class Hashtable{public:Nodearray a[26];Hashtable(){for (int i = 0; i < 26; i++){a[i].Sethead(NULL);a[i].Settail(NULL);}}void Addnum(string num){//字符首字母决定存储位置int index = (int)(num[0]) - 97;a[index].Addnum(num);}void Display(){for (int i = 0; i < 26; i++)a[i].Display();}};
创建存储信息的字典类
创建字典类,存放文章摘要中的一些关键信息:
//定义字典类,存放论文中的重要数据class Dictionary {public:vector<string> words;vector<float> times;vector<string> core;vector<string> supercore;Hashtable hashtable;Dictionary(){//cout << "A dictionary has been established!" << endl;}//看一个单词是否已经在字典中bool Find_word(string b){auto first = this->words.begin();auto first2 = this->times.begin();auto end = this->words.end();while (first != end){if (*first == b) {(*first2) = (*first2) + 1.0;return true;}++first;++first2;}return false;}void Clear(){this->words.clear();this->times.clear();this->core.clear();this->supercore.clear();}void Copy(Dictionary another){auto first = this->words.begin();auto first2 = this->times.begin();auto first3 = this->core.begin();auto first4 = this->supercore.begin();auto end = this->words.end();auto end2 = this->times.end();auto end3 = this->core.end();auto end4 = this->supercore.end();while (first != end){this->words.push_back((*first));this->times.push_back((*first2));++first;++first2;}while (first3 != end3){this->core.push_back((*first3));++first3;}while (first4 != end4){this->supercore.push_back((*first4));++first4;}}void word2hash(){auto first = this->words.begin();auto end = this->words.end();while (first != end) {hashtable.Addnum((*first));++first;}//cout << "1";}void Display(){auto first = this->words.begin();auto first2 = this->times.begin();auto end = this->words.end();auto end2 = this->times.end();while (first != end){cout << (*first) << " " << (*first2) << endl;++first;++first2;}cout << "core:" << endl;auto first3 = this->core.begin();auto end3 = this->core.end();while (first3 != end3){cout << (*first3) << endl;cout << endl;++first3;}cout << "supercore:" << endl;auto first4 = this->supercore.begin();auto end4 = this->supercore.end();while (first4 != end4){cout << (*first4) << endl;cout << endl;++first4;}this->hashtable.Display();}};//用到的函数的声明Dictionary Findcommoncore( Dictionary input1, Dictionary input2);Dictionary Charu(Dictionary a);
两个辅助函数
写好两个主函数中会用到的函数:
//找出两篇文章共同的核心词
Dictionary Findcommoncore(Dictionary input1, Dictionary input2)
{
Dictionary dict3;
auto begin = input1.words.begin();
auto ending = input1.words.end();
auto begin_2 = input1.times.begin();
auto ending_2 = input1.times.end();
auto begin2 = input2.words.begin();
auto ending2 = input2.words.end();
auto begin2_2 = input2.times.begin();
auto ending2_2 = input2.times.end();
while (begin != ending)
{
while (begin2 != ending2)
{
//cout << (*begin) << " " << (*begin2) << endl;
if (((*begin) == (*begin2)) && ((*begin) != "we") && ((*begin) != "data") && ((*begin) != "model")) {
dict3.words.push_back((*begin));
dict3.times.push_back((*begin_2) * (*begin2_2));
break;
}
++begin2;
++begin2_2;
}
++begin;
++begin_2;
begin2 = input2.words.begin();
begin2_2 = input2.times.begin();
}
return dict3;
}
//插入排序
Dictionary Charu(Dictionary a)
{
float* series = new float[a.words.size()];
string* series2 = new string[a.times.size()];
auto begin = a.words.begin();
auto ending = a.words.end();
auto begin_2 = a.times.begin();
auto ending_2 = a.times.end();
int c = 0;
while (begin != ending) {
series[c] = (*begin_2);
series2[c] = (*begin);
++c;
++begin;
++begin_2;
}
Dictionary output;
float temp = 0;
string temp2 = "";
int last = 0;
for (int p = 1; p < a.words.size(); p++)
{
temp = series[p];
temp2 = series2[p];
last = p;
for (int i = p; i > 0; i--)
{
if (series[i - 1] < temp)
{
series[i] = series[i - 1];
series2[i] = series2[i - 1];
last = i - 1;
}
}
series[last] = temp;
series2[last] = temp2;
}
for (int j = 0; j < a.words.size(); j++)
{
output.words.push_back(series2[j]);
output.times.push_back(series[j]);
}
return output;
}
读取文本文件
读取事先准备好的txt文本文件:
//读取txt文本
if(i == 0)
infile.open("a.txt", ios::in);
else if(i == 1)
infile.open("c.txt", ios::in);
else if (i == 2)
infile.open("d.txt", ios::in);
else if (i == 3)
infile.open("b.txt", ios::in);
else
infile.open("e.txt", ios::in);
if (!infile.is_open())
{
cout << "读取文件失败" << endl;
return 0;
}
把字典在常用词库中的词去掉,为此我们创建一个常用词的vector:
//创建一个常用词的vector,并把字典在常用词库中的词去掉
vector<string> repository;
repository.push_back("in");
repository.push_back("on");
repository.push_back("of");
repository.push_back("a");
repository.push_back("an");
repository.push_back("the");
repository.push_back("I");
repository.push_back("you");
repository.push_back("we");
repository.push_back("and");
repository.push_back("by");
repository.push_back("to");
repository.push_back("for");
repository.push_back("can");
repository.push_back("as");
repository.push_back("am");
repository.push_back("is");
repository.push_back("are");
repository.push_back("that");
repository.push_back("this");
repository.push_back("or");
统计文章摘要的关键信息
在这里统计关键信息时我做了几个操作:
- 将时态统一为一般现在时
- 根据一些词汇确定核心句和超级核心句
- 将大小写统一为小写
- 处理句子末尾的标点符号
统计文本中的单词,并查看字典中添加的单词:
//统计文本中的单词和核心句
while (getline(infile, buf))
{
s.clear();
temp.clear();
//cout << buf << endl;
istringstream is(buf);
bool flag = false;
bool super = false;
string temp3 = " ";
while (is >> s)
{
//根据“We"来识别核心句
if (s == "We" || flag == true)
{
flag = true;
if (s != "We") {
temp.append(" ");
//如果是过去时就处理成一般现在时
if ((temp3 == "We") && (s.substr(s.length() - 2, s.length()) == "ed")) {
s.erase(s.end() - 1);
cout << "发现一般过去时!" << endl;
temp.append(s);
temp3 = s;
}
else if ((temp3 == "We") && (s == "have" || s == "has"))
cout << "发现现在完成时!" << endl;
else {
temp.append(s);
temp3 = s;
}
}
else {
temp.append(s);
temp3 = s;
}
}
if (s.back() == '.' && flag == true)
{
flag = false;
dict[i].core.push_back(temp);
if (super == true)
{
super = false;
dict[i].supercore.push_back(temp);
}
temp.clear();
}
//抹去最后的标点符号
if (s.back() == '.' || s.back() == ',' || s.back() == ':') s.erase(s.end() - 1);
//大小写转换,全部转为小写
//根据特定词汇识别超级核心句
if (isupper(s[0]))
s[0] = tolower(s[0]);
if ((super == false) && flag == true && (s == "build" || s == "use" || s == "model" || s == "method" || s == "approach" || s == "system")) super = true;
temp2 = !dict[i].Find_word(s);
if (temp2 && !(find(repository.begin(), repository.end(), s) != repository.end()))
{
dict[i].words.push_back(s);
dict[i].times.push_back(1);
}
//cout << s << endl;
}
}
这一步结束后结果如下图所示,下面是文章一的核心句和超级核心句,文章二同理:
核心词也类似,下面是部分核心词及其词频:
将每篇文章的关键词整理到字典类的哈希表成员中,效果如下: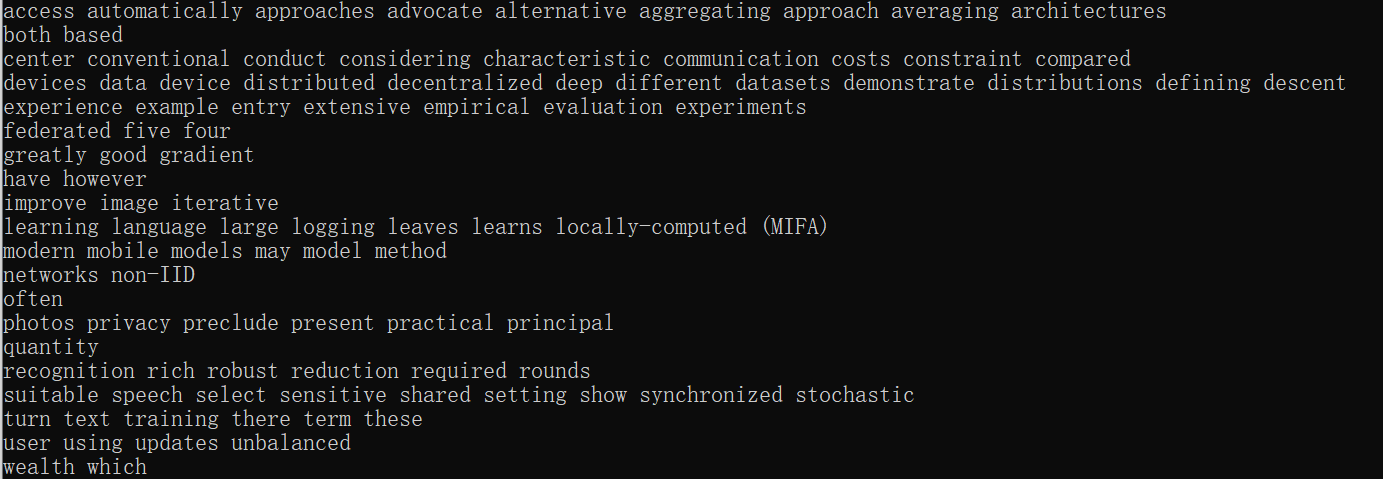
收集两篇文章共同关键词
为了进一步进行文本挖掘,我们还要从多篇文章上找出他们的共同性和相似性。在这里,我们将这种相似性定义为多篇文章共同的关键词。
收集两篇文章共同的关键词:
//先来找找共同的核心词
Dictionary dict3;
auto begin = dict.words.begin();
auto ending = dict.words.end();
auto begin_2 = dict.times.begin();
auto ending_2 = dict.times.end();
auto begin2 = dict2.words.begin();
auto ending2 = dict2.words.end();
auto begin2_2 = dict2.times.begin();
auto ending2_2 = dict2.times.end();
while (begin != ending)
{
while (begin2 != ending2)
{
//cout << (*begin) << " " << (*begin2) << endl;
if (((*begin) == (*begin2)) && ((*begin)!="we") && ((*begin)!="data") && ((*begin)!="model")) {
dict3.words.push_back((*begin));
dict3.times.push_back((*begin_2) * (*begin2_2));
break;
}
++begin2;
++begin2_2;
}
++begin;
++begin_2;
begin2 = dict2.words.begin();
begin2_2 = dict2.times.begin();
}
dict3.Display();
划分共同关键词
将收集到的关键词根据关键程度进一步划分:
//还可以将上面收集到的关键词进一步划分
Dictionary dict4;
Dictionary dict5;
auto begin3 = dict3.words.begin();
auto ending3 = dict3.words.end();
auto begin3_2 = dict3.times.begin();
auto ending3_2 = dict3.times.end();
while (begin3 != ending3)
{
if ((*begin3_2) > 1.0) {
dict4.words.push_back((*begin3));
dict4.times.push_back((*begin3_2));
}
else {
dict5.words.push_back((*begin3));
dict5.times.push_back((*begin3_2));
}
++begin3;
++begin3_2;
}
dict4.Display();
dict5.Display();
如下图所示,两篇文章中共同的重要关键词,如下所示,由关键词可以推测,这篇文章大概率和Federated Learning和 mobile communication有关:
收集五篇文章共同关键词
找出五篇论文共同的关键词并根据关键度进行排序:
Dictionary dict7[4];
//更为重要的是找出五篇论文共同的关键词
//采用循环的方法
int endnum = 0;
for (int i = 0; i < 4; i++) {
if (i == 0) {
dict7[0] = Findcommoncore(dict[0], dict[1]);
endnum++;
}
else {
//共同关键词小于五个时就停止,这五个关键词已经很重要了
//防止这5篇文章没有公共的关键词
if (dict7[i - 1].words.size() <= 5)
break;
else
dict7[i] = Findcommoncore(dict7[i - 1], dict[i + 1]);
endnum++;
}
}
for (int i = 0; i < endnum; i++) {
dict7[i].Display();
}
//将最后得到的核心词根据关键程度进行排序,使用插入排序
Dictionary dict8;
dict8 = Charu(dict7[endnum - 1]);
dict7[endnum - 1] = dict8;
dict7[endnum - 1].Display();
如图所示,五篇论文共同的关键词如下: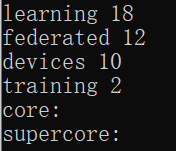
从这里我们基本上已经可以看出这五篇文章共同的主题是Federated Learning了。
HMM+Viterbi词性标注
词性标注是我们进行有监督学习或者进一步进行句法和句意分析的关键。
使用隐马尔可夫链和维特比算法进行词性标注:
//AT BEZ IN NN VB PERIOD
string str[6] = { "AT","BEZ","IN","NN","VB","PERJOD" };
int transistion_sum[6], emission_sum[6];
double tp[6][6], ep[6][16];//tp是归一化后的转移概率矩阵 ep发射概率矩阵
double viterbi[15][6];//待标注句子共有6个单词,语料库共有6种词性 共36个状态节点
int path[15][6];//记录路径
//初始概率
double original_p[6] = { 0.3,0.04,0.1,0.5,0.04,0.02 };
int ind[15] = { 8,6,5,13,9,7,0,12,14,1,2,3,11,10,4 };//待标注句子“The bear is on the move”共6个单词 第i个单词的下标索引值ind[i]
//这是我从网上找到的一个从现有语料库计算得到的转移概率矩阵
int transistion_matrix[6][6] = {
{
1,1,1,48637,1,20},{
1974,1,427,188,1,39},{
43323,1,1326,17315,1,186},{
1068,3721,42471,11774,615,21393},{
6073,43,4759,1477,130,1523},{
8017,76,4657,1330,955,1} };
//这是我从网上找到的一个从现有语料库经过Laplace处理得到的发射概率矩阵
int emission_matrix[6][16] = {
{
1,1,69017,1,1,69017,1,1,1,1,1,1,1,1,1,1},{
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1},{
5485,5485,1,1,1,1,1,1,1,1,1,5485,1,1,1,1},{
1,1,1,383,383,1,1,383,383,383,1,1,1,1,383,1},{
1,1,1,1,1,1,40034,1,1,1,1,1,1,1,1,1},{
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,48810} };
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
transistion_sum[i] += transistion_matrix[i][j];
}
}
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 16; j++) {
emission_sum[i] += emission_matrix[i][j];
}
}
//转移概率及发射概率的计算
for (int i = 0; i < 6; i++) {//转移概率矩阵 每行概率和为1
for (int j = 0; j < 6; j++) {
tp[i][j] = 1.0 * transistion_matrix[i][j] / transistion_sum[i];
}
}
for (int i = 0; i < 6; i++) {//发射概率矩阵 每行概率和为1
for (int j = 0; j < 16; j++) {
ep[i][j] = 1.0 * emission_matrix[i][j] / emission_sum[i];
}
}
//HMM + VERTEBI 算法
for (int i = 0; i < 6; i++) {//计算第一列的节点的值 初始概率*发射概率
viterbi[0][i] = 1.0 * original_p[i] * ep[i][ind[0]];//第一列对应的单词(句子的第0个单词)the的下表索引值是6 ind[0]==6
}
for (int i = 1; i < 15; i++) {//第i列 句子的第i个单词的词性
for (int j = 0; j < 6; j++) {//可标注的词性共6种可选
double mp = 0;//temporary maxmium
int mp_id = -1;
for (int k = 0; k < 6; k++) {//遍历更新最大值
if (viterbi[i - 1][k] * tp[k][j] > mp) {
mp = viterbi[i - 1][k] * tp[k][j];
mp_id = k;
}
}
viterbi[i][j] = mp * ep[j][ind[i]];//记录前向最大概率值
path[i][j] = mp_id;
}
}
double ans = 0;
int ans_id = 0; //最后一个单词的词性
for (int i = 0; i < 6; i++) {
if (viterbi[14][i] > ans) {
ans = viterbi[14][i];
ans_id = i;
}
}
int output[15];
for (int i = 14; i >= 0; i--) {//从最后一天的隐状态回溯到第一天的隐状态 从后往前寻找路径 ,输出时从前往后
output[i] = ans_id;
ans_id = path[i][ans_id];
}
//输出词性标注的结果
for (int i = 0; i < 15; i++) {
cout << str[output[i]] << " ";
}
cout << endl;
例如对这一句话进行词性标注:
标注结果如下,可以说大致正确了:
完整代码示例
完整代码如下:
#include<iostream>
#include<cstdlib>
#include<cstdio>
#include<sstream>
#include<fstream>
#include<string>
#include<vector>
#include<cctype>
#include<cmath>
using namespace std;
//类的定义部分
//类的定义部分
//类的定义部分
//先定义下链表和哈希表
class Node
{
private:
string value;
Node* next;
public:
Node()
{
value = "";
next = NULL;
}
string Getvalue() { return this->value; }
Node* Getnext() { return this->next; }
void Setvalue(string num) { value = num; }
void Setnext(Node* a) { next = a; }
};
class Nodearray
{
private:
Node* head;
Node* tail;
public:
Nodearray()
{
head = NULL;
tail = NULL;
}
Node* Gethead() { return this->head; }
void Sethead(Node* a) { this->head = a; }
void Settail(Node* a) { this->tail = a; }
Node* Gettail() { return this->tail; }
void Addnum(string num)
{
if (head == NULL)
{
head = new Node;
head->Setvalue(num);
head->Setnext(NULL);
tail = head;
}
else
{
tail->Setnext(new Node);
(tail->Getnext())->Setvalue(num);
(tail->Getnext())->Setnext(NULL);
tail = tail->Getnext();
}
}
void Display()
{
Node* p = head;
if (head == NULL) return;
else
{
while (p != NULL)
{
cout << p->Getvalue() << " ";
p = p->Getnext();
}
}
cout << endl;
}
void Getnum(int pos)
{
int count = 1;
Node* p = head;
while (p != NULL)
{
if (count == pos)
{
cout << "找到了! ";
cout << p->Getvalue() << endl;
return;
}
p = p->Getnext();
count++;
}
cout << "没找到!" << endl;
}
void Delnum(string num)
{
Node* p1 = head;
Node* p2 = head;
if (head == NULL)
{
cout << "这是空列表" << endl;
return;
}
else
{
if (head->Getvalue() == num)
{
head = head->Getnext();
return;
}
else
{
p2 = p2->Getnext();
}
while (p2 != NULL)
{
if (p2->Getvalue() == num)
{
p1->Setnext(p2->Getnext());
cout << "删除成功" << endl;
return;
}
p1 = p1->Getnext();
p2 = p2->Getnext();
}
}
}
};
//定义哈希表
class Hashtable
{
public:
Nodearray a[26];
Hashtable()
{
for (int i = 0; i < 26; i++)
{
a[i].Sethead(NULL);
a[i].Settail(NULL);
}
}
void Addnum(string num)
{
//字符首字母决定存储位置
int index = (int)(num[0]) - 97;
a[index].Addnum(num);
}
void Display()
{
for (int i = 0; i < 26; i++)
a[i].Display();
}
};
//定义字典类,存放论文中的重要数据
class Dictionary {
public:
vector<string> words;
vector<float> times;
vector<string> core;
vector<string> supercore;
Hashtable hashtable;
Dictionary()
{
//cout << "A dictionary has been established!" << endl;
}
//看一个单词是否已经在字典中
bool Find_word(string b)
{
auto first = this->words.begin();
auto first2 = this->times.begin();
auto end = this->words.end();
while (first != end)
{
if (*first == b) {
(*first2) = (*first2) + 1.0;
return true;
}
++first;
++first2;
}
return false;
}
void Clear()
{
this->words.clear();
this->times.clear();
this->core.clear();
this->supercore.clear();
}
void Copy(Dictionary another)
{
auto first = this->words.begin();
auto first2 = this->times.begin();
auto first3 = this->core.begin();
auto first4 = this->supercore.begin();
auto end = this->words.end();
auto end2 = this->times.end();
auto end3 = this->core.end();
auto end4 = this->supercore.end();
while (first != end)
{
this->words.push_back((*first));
this->times.push_back((*first2));
++first;
++first2;
}
while (first3 != end3)
{
this->core.push_back((*first3));
++first3;
}
while (first4 != end4)
{
this->supercore.push_back((*first4));
++first4;
}
}
void word2hash()
{
auto first = this->words.begin();
auto end = this->words.end();
while (first != end) {
hashtable.Addnum((*first));
++first;
}
//cout << "1";
}
void Display()
{
auto first = this->words.begin();
auto first2 = this->times.begin();
auto end = this->words.end();
auto end2 = this->times.end();
while (first != end)
{
cout << (*first) << " " << (*first2) << endl;
++first;
++first2;
}
cout << "core:" << endl;
auto first3 = this->core.begin();
auto end3 = this->core.end();
while (first3 != end3)
{
cout << (*first3) << endl;
cout << endl;
++first3;
}
cout << "supercore:" << endl;
auto first4 = this->supercore.begin();
auto end4 = this->supercore.end();
while (first4 != end4)
{
cout << (*first4) << endl;
cout << endl;
++first4;
}
this->hashtable.Display();
}
};
//用到的函数的声明
Dictionary Findcommoncore( Dictionary input1, Dictionary input2);
Dictionary Charu(Dictionary a);
//主函数部分
//主函数部分
//主函数部分
int main(){
//寻找核心句
//1.论文的核心句大概率出现在摘要里,所以我们先对摘要进行分析
//2.论文核心句常以We开头,这是一个规律
//3.论文核心词不会是介词
//4.句子中有build,use,model,method,approach类字眼的更有可能是超级核心句
ifstream infile;
Dictionary dict[5];
string buf;
string s;
string temp;
bool temp2;
//创建一个常用词的vector,并把字典在常用词库中的词去掉
vector<string> repository;
repository.push_back("in");
repository.push_back("on");
repository.push_back("of");
repository.push_back("a");
repository.push_back("an");
repository.push_back("the");
repository.push_back("I");
repository.push_back("you");
repository.push_back("we");
repository.push_back("and");
repository.push_back("by");
repository.push_back("to");
repository.push_back("for");
repository.push_back("can");
repository.push_back("as");
repository.push_back("am");
repository.push_back("is");
repository.push_back("are");
repository.push_back("that");
repository.push_back("this");
repository.push_back("or");
//读取文本后对文本的处理比较麻烦
//需要考虑大小写 时态 句子分割
//时态统一成一般现在时,尤其是核心句
//有没有办法做到语义分割?
int i = 0;
while (i < 5)
{
//读取txt文本
if(i == 0)
infile.open("a.txt", ios::in);
else if(i == 1)
infile.open("c.txt", ios::in);
else if (i == 2)
infile.open("d.txt", ios::in);
else if (i == 3)
infile.open("b.txt", ios::in);
else
infile.open("e.txt", ios::in);
if (!infile.is_open())
{
cout << "读取文件失败" << endl;
return 0;
}
//统计文本中的单词和核心句
while (getline(infile, buf))
{
s.clear();
temp.clear();
//cout << buf << endl;
istringstream is(buf);
bool flag = false;
bool super = false;
string temp3 = " ";
while (is >> s)
{
//根据“We"来识别核心句
if (s == "We" || flag == true)
{
flag = true;
if (s != "We") {
//如果是过去时就处理成一般现在时
if ((temp3 == "We") && (s.substr(s.length() - 2, s.length()) == "ed")) {
s.erase(s.end() - 1);
temp.append(" ");
cout << "发现一般过去时!" << endl;
temp.append(s);
temp3 = s;
}
else if ((temp3 == "We") && (s == "have" || s == "has"))
cout << "发现现在完成时!" << endl;
else {
temp.append(" ");
temp.append(s);
temp3 = s;
}
}
else {
temp.append(s);
temp3 = s;
}
}
if (s.back() == '.' && flag == true)
{
flag = false;
dict[i].core.push_back(temp);
if (super == true)
{
super = false;
dict[i].supercore.push_back(temp);
}
temp.clear();
}
//抹去最后的标点符号
if (s.back() == '.' || s.back() == ',' || s.back() == ':') s.erase(s.end() - 1);
//大小写转换,全部转为小写
//根据特定词汇识别超级核心句
if (isupper(s[0]))
s[0] = tolower(s[0]);
if ((super == false) && flag == true && (s == "build" || s == "use" || s == "model" || s == "method" || s == "approach" || s == "system")) super = true;
temp2 = !dict[i].Find_word(s);
if (temp2 && !(find(repository.begin(), repository.end(), s) != repository.end()))
{
dict[i].words.push_back(s);
dict[i].times.push_back(1);
}
//cout << s << endl;
}
}
infile.close();
//将关键词转化为hashtable存储,方便后续查找等工作
dict[i].word2hash();
i++;
//查看字典中添加的单词
//dict2.Display();
}
for (int i = 0; i < 5; i++) {
dict[i].Display();
}
//dict[0].Display();
//上面我们已经实现了对五篇论文的摘要段的读取
//以及核心句和核心词的提取
//为什么读取两篇以上的论文?主要是做相关性分析
//对于核心句和核心词的相关性分析,可以得到两篇文章的相关度
//如果两篇文章内容接近,则能得到两篇论文共同指向的一个主题
//先来找找1和2的共同的核心词
Dictionary dict3 = Findcommoncore(dict[0], dict[1]);
//dict3.Display();
//还可以将上面收集到的关键词进一步划分
Dictionary dict4;
Dictionary dict5;
auto begin3 = dict3.words.begin();
auto ending3 = dict3.words.end();
auto begin3_2 = dict3.times.begin();
auto ending3_2 = dict3.times.end();
while (begin3 != ending3)
{
if ((*begin3_2) > 1.0) {
dict4.words.push_back((*begin3));
dict4.times.push_back((*begin3_2));
}
else {
dict5.words.push_back((*begin3));
dict5.times.push_back((*begin3_2));
}
++begin3;
++begin3_2;
}
//dict4.Display();
//dict5.Display();
//再来找找3和4的共同的核心词
Dictionary dict6 = Findcommoncore(dict[2], dict[3]);
//dict6.Display();
Dictionary dict7[4];
//更为重要的是找出五篇论文共同的关键词
//采用循环的方法
int endnum = 0;
for (int i = 0; i < 4; i++) {
if (i == 0) {
dict7[0] = Findcommoncore(dict[0], dict[1]);
endnum++;
}
else {
//共同关键词小于五个时就停止,这五个关键词已经很重要了
//防止这5篇文章没有公共的关键词
if (dict7[i - 1].words.size() <= 5)
break;
else
dict7[i] = Findcommoncore(dict7[i - 1], dict[i + 1]);
endnum++;
}
}
//for (int i = 0; i < endnum; i++) {
// dict7[i].Display();
//}
//将最后得到的核心词根据关键程度进行排序,使用插入排序
Dictionary dict8;
dict8 = Charu(dict7[endnum - 1]);
dict7[endnum - 1] = dict8;
dict7[endnum - 1].Display();
//以上的分析只是停留在词的层面
//下面可以考虑继续深究的方向有几个
//1.前期文本的清理、处理与进一步划分(包括词性、时态、语态和单复数等等)
//2.词级别处理手段和方法的升级(关键词的分布?语义解析?),C++究竟能做模式识别吗?
//3.进一步升级到词组级、句子级甚至段落级的处理
//4.进一步引进更多的数据和文章(还是那个问题,C++究竟能做模式识别吗?)
//5.现在只考虑了摘要部分,是否可以读入全文进行分析(利用之前构建的hashtable)?
//接下来我们进行词性标注
//采用隐马尔科夫+维特比算法进行词性标注
//实际上我们没有必要对所有句子进行词性标注
//所以我们这里只对每篇文章的核心句进行词性标注
//
//AT BEZ IN NN VB PERIOD
string str[6] = { "AT","BEZ","IN","NN","VB","PERJOD" };
int transistion_sum[6], emission_sum[6];
double tp[6][6], ep[6][16];//tp是归一化后的转移概率矩阵 ep发射概率矩阵
double viterbi[15][6];//待标注句子共有6个单词,语料库共有6种词性 共36个状态节点
int path[15][6];//记录路径
//初始概率
double original_p[6] = { 0.3,0.04,0.1,0.5,0.04,0.02 };
int ind[15] = { 8,6,5,13,9,7,0,12,14,1,2,3,11,10,4 };//待标注句子“The bear is on the move”共6个单词 第i个单词的下标索引值ind[i]
//这是我从网上找到的一个从现有语料库计算得到的转移概率矩阵
int transistion_matrix[6][6] = {
{
1,1,1,48637,1,20},{
1974,1,427,188,1,39},{
43323,1,1326,17315,1,186},{
1068,3721,42471,11774,615,21393},{
6073,43,4759,1477,130,1523},{
8017,76,4657,1330,955,1} };
//这是我从网上找到的一个从现有语料库经过Laplace处理得到的发射概率矩阵
int emission_matrix[6][16] = {
{
1,1,69017,1,1,69017,1,1,1,1,1,1,1,1,1,1},{
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1},{
5485,5485,1,1,1,1,1,1,1,1,1,5485,1,1,1,1},{
1,1,1,383,383,1,1,383,383,383,1,1,1,1,383,1},{
1,1,1,1,1,1,40034,1,1,1,1,1,1,1,1,1},{
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,48810} };
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
transistion_sum[i] += transistion_matrix[i][j];
}
}
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 16; j++) {
emission_sum[i] += emission_matrix[i][j];
}
}
//转移概率及发射概率的计算
for (int i = 0; i < 6; i++) {//转移概率矩阵 每行概率和为1
for (int j = 0; j < 6; j++) {
tp[i][j] = 1.0 * transistion_matrix[i][j] / transistion_sum[i];
}
}
for (int i = 0; i < 6; i++) {//发射概率矩阵 每行概率和为1
for (int j = 0; j < 16; j++) {
ep[i][j] = 1.0 * emission_matrix[i][j] / emission_sum[i];
}
}
//HMM + VERTEBI 算法
for (int i = 0; i < 6; i++) {//计算第一列的节点的值 初始概率*发射概率
viterbi[0][i] = 1.0 * original_p[i] * ep[i][ind[0]];//第一列对应的单词(句子的第0个单词)the的下表索引值是6 ind[0]==6
}
for (int i = 1; i < 15; i++) {//第i列 句子的第i个单词的词性
for (int j = 0; j < 6; j++) {//可标注的词性共6种可选
double mp = 0;//temporary maxmium
int mp_id = -1;
for (int k = 0; k < 6; k++) {//遍历更新最大值
if (viterbi[i - 1][k] * tp[k][j] > mp) {
mp = viterbi[i - 1][k] * tp[k][j];
mp_id = k;
}
}
viterbi[i][j] = mp * ep[j][ind[i]];//记录前向最大概率值
path[i][j] = mp_id;
}
}
double ans = 0;
int ans_id = 0; //最后一个单词的词性
for (int i = 0; i < 6; i++) {
if (viterbi[14][i] > ans) {
ans = viterbi[14][i];
ans_id = i;
}
}
int output[15];
for (int i = 14; i >= 0; i--) {//从最后一天的隐状态回溯到第一天的隐状态 从后往前寻找路径 ,输出时从前往后
output[i] = ans_id;
ans_id = path[i][ans_id];
}
//输出词性标注的结果
for (int i = 0; i < 15; i++) {
cout << str[output[i]] << " ";
}
cout << endl;
//上面的词性标注还只是个实例
//真正的词性标注需要大量的语料库的数据进行训练
//这次的C++程序设计训练因为能力有限 就暂告一段落了
//虽然说因为C++和数据的限制没有办法进一步探究NLP的世界
//但是这一次还是学习到了很多东西,包括词性标注、关键词识别等
//下面可以考虑继续深究的方向有几个
//1.前期文本的清理、处理与进一步划分(包括词性、时态、语态和单复数等等)
//2.词级别处理手段和方法的升级(关键词的分布?语义解析?),C++究竟能做模式识别吗?
//3.进一步升级到词组级、句子级甚至段落级的处理
//4.进一步引进更多的数据和文章(还是那个问题,C++究竟能做模式识别吗?)
//5.现在只考虑了摘要部分,是否可以读入全文进行分析(利用之前构建的hashtable)?
return 0;
}
//找出两篇文章共同的核心词
Dictionary Findcommoncore(Dictionary input1, Dictionary input2)
{
Dictionary dict3;
auto begin = input1.words.begin();
auto ending = input1.words.end();
auto begin_2 = input1.times.begin();
auto ending_2 = input1.times.end();
auto begin2 = input2.words.begin();
auto ending2 = input2.words.end();
auto begin2_2 = input2.times.begin();
auto ending2_2 = input2.times.end();
while (begin != ending)
{
while (begin2 != ending2)
{
//cout << (*begin) << " " << (*begin2) << endl;
if (((*begin) == (*begin2)) && ((*begin) != "we") && ((*begin) != "data") && ((*begin) != "model")) {
dict3.words.push_back((*begin));
dict3.times.push_back((*begin_2) * (*begin2_2));
break;
}
++begin2;
++begin2_2;
}
++begin;
++begin_2;
begin2 = input2.words.begin();
begin2_2 = input2.times.begin();
}
return dict3;
}
//插入排序
Dictionary Charu(Dictionary a)
{
float* series = new float[a.words.size()];
string* series2 = new string[a.times.size()];
auto begin = a.words.begin();
auto ending = a.words.end();
auto begin_2 = a.times.begin();
auto ending_2 = a.times.end();
int c = 0;
while (begin != ending) {
series[c] = (*begin_2);
series2[c] = (*begin);
++c;
++begin;
++begin_2;
}
Dictionary output;
float temp = 0;
string temp2 = "";
int last = 0;
for (int p = 1; p < a.words.size(); p++)
{
temp = series[p];
temp2 = series2[p];
last = p;
for (int i = p; i > 0; i--)
{
if (series[i - 1] < temp)
{
series[i] = series[i - 1];
series2[i] = series2[i - 1];
last = i - 1;
}
}
series[last] = temp;
series2[last] = temp2;
}
for (int j = 0; j < a.words.size(); j++)
{
output.words.push_back(series2[j]);
output.times.push_back(series[j]);
}
return output;
}
进一步的思考
上面只是一些基础性的工作,实际上因为我们本地的计算资源有限,实际上不可能存储那么多的论文和那么多的常用词来实现一些常用的算法如PageRank算法等(我导师说深度学习就是比算力和算法,现在我信了~下面是一些我对于这个项目进一步的思考:
- 常用词是有无数个的,而常用词库不可能无限大。有没有办法借助一些现有的常用词库、封装好的东西或其他方法来解决这个问题?
- 如果只是使用统计类的方法例如像TF-IDF的统计词频的方法的话,忽略了一个很关键的东西:就是出现的词之间有可能有些词有强相关的关系,例如AI和Machine Learning等,有没有什么监督学习或者无监督学习的方法,又或者是计算一些相关性来解决这个问题?
- 核心句的分布问题,核心句常出现在开头部分或者最后的总结部分。
- 核心句的结构问题,核心句常常有相似的句子结构。
- 至于进一步的研究方向,我分为以下几个方向:
- 前期文本的清理、处理与进一步划分(包括词性、时态、语态和单复数等等)
- 词级别处理手段和方法的升级(关键词的分布?语义解析?)
- 进一步升级到词组级、句子级甚至段落级的处理
- 进一步引进更多的数据和文章(还是那个问题,C++究竟能做模式识别吗?)
- 现在只考虑了摘要部分,是否可以读入全文进行分析(利用hashtable)?
总结
C++编程之美只有你去切身感受才能体会到,所以我也推荐大家,在学习CS时要怀有“纸上得来终觉浅,绝知此事要躬行”的态度,多去实践,多去探索。
欢迎对ECE/CS/AI感兴趣的小伙伴关注我,如果你对我的内容有什么建议或想法的话,也欢迎在评论区留下你的声音。

若有收获,就点个赞吧
0 人点赞
