
如今我们的计算机已经进入多CUP或多核时代,而我们使用的操作系统都是支持“多任务”的操作系统,这使得我们可以同时运行多个程序,也可以将一个程序分解为若干个相对独立的子任务,让多个子任务并发的执行,从而缩短程序的执行时间,同时也让用户获得更好的体验
概念
进程就是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,操作系统管理所有进程的执行,为它们合理的分配资源。进程可以通过fork或spawn的方式来创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此必须通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。
一个进程还可以拥有多个并发的执行线索,简单的说就是拥有多个可以获得CPU调度的执行单元,这就是所谓的线程。由于线程在同一个进程下,它们可以共享相同的上下文,因此相对于进程而言,线程间的信息共享和通信更加容易。当然在单核CPU系统中,真正的并发是不可能的,因为在某个时刻能够获得CPU的只有唯一的一个线程,多个线程共享了CPU的执行时间。使用多线程实现并发编程为程序带来的好处是不言而喻的,最主要的体现在提升程序的性能和改善用户体验,今天我们使用的软件几乎都用到了多线程技术,这一点可以利用系统自带的进程监控工具(如macOS中的“活动监视器”、Windows中的“任务管理器”)来证实,如下图所示。
缺点:
其他进程的角度:多线程的程序对其他程序并不友好,因为它占用了更多的CPU执行时间,导致其他程序无法获得足够的CPU执行时间
开发者角度:难度较高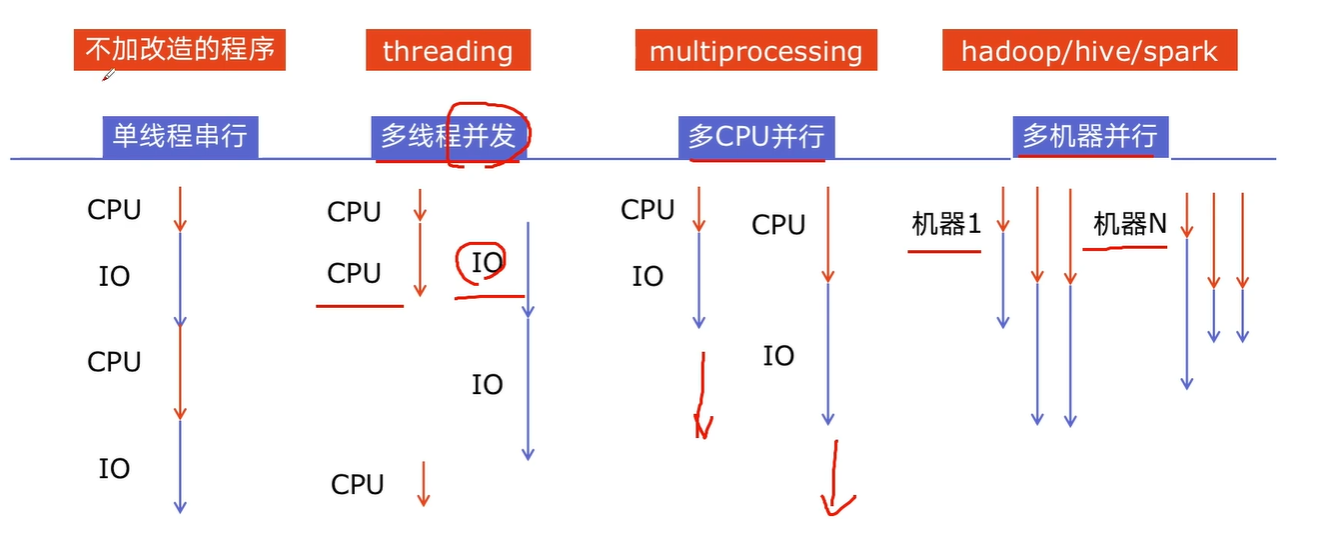

CPU密集型与IO密集型
CPU和IO可以同时进行
- CPU密集型 CPU bound
CPU密集型也叫计算密集型,指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
比如:压缩解压缩、加密解密、正则表达式搜索
- IO密集型 I/O bound
IO密集型指系统运作大部分的状态是CPU在等I/O(磁盘/内存)的读/写操作,CPU占用率比较低
例如:文件处理程序、网络爬虫程序、读写数据库程序
多线程、多进程、多协程的比较

| 分类 | 多进程Process(multiprocessing) | ||
|---|---|---|---|
| 优缺点 | |||
| 适用场景 |
python速度慢的原因
动态语言
GIL(global interpreter lock)
- 什么是GIL
全局解释器锁,无法利用多核CPU并发执行
计算机程序设计语言解释器用于同步线程的一种机制。它使得任何时刻仅有一个线程在执行。即便在多核处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
- 为什么要有GIL
Python设计初期,为了解决多线程之间数据完整性和状态同步的问题,而引入的。
Python中对象管理,是使用引用计数器记性,引用数为0则释放对象。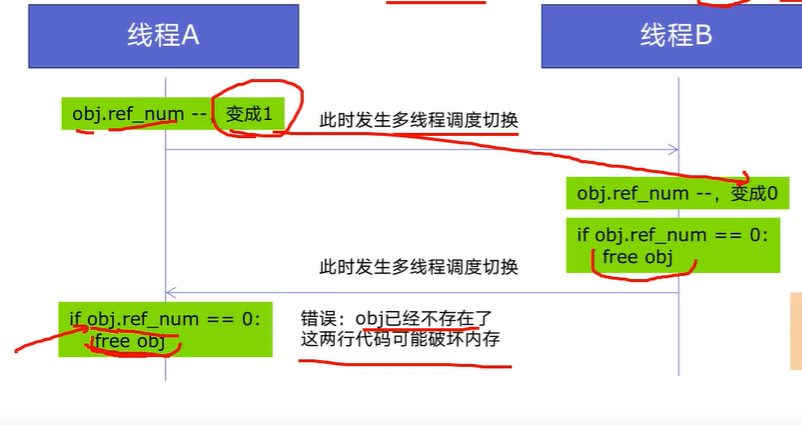
- 如何规避GIL的限制
- 多线程threading机制依然有用,用于IO密集型计算
I/O(read,write,send,recv,tec),期间,线程会释放GIL,实现CPU与IO的并行,因此多线程用于IO密集型计算依然可以大幅度提升速度,但是多线程用于CPU密集型计算时,会拖慢速度。
- 使用multiprocessing的多线程机制实现并发计算,利用多核CPU优势
多进程
from multiprocessing import Processfrom os import getpidfrom random import randintfrom time import time, sleepdef download_task(filename):print('启动下载进程,进程号[%d].' % getpid())print('开始下载%s...' % filename)time_to_download = randint(5, 10)sleep(time_to_download)print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))def main():start = time()p1 = Process(target=download_task, args=('Python从入门到住院.pdf', ))p1.start()p2 = Process(target=download_task, args=('Peking Hot.avi', ))p2.start()p1.join()p2.join()end = time()print('总共耗费了%.2f秒.' % (end - start))if __name__ == '__main__':main()
在上面的代码中,我们通过Process类创建了进程对象,通过target参数我们传入一个函数来表示进程启动后要执行的代码,后面的args是一个元组,它代表了传递给函数的参数。Process对象的start方法用来启动进程,而join方法表示等待进程执行结束。运行上面的代码可以明显发现两个下载任务“同时”启动了,而且程序的执行时间将大大缩短,不再是两个任务的时间总和。下面是程序的一次执行结果。
多线程
线程的生命周期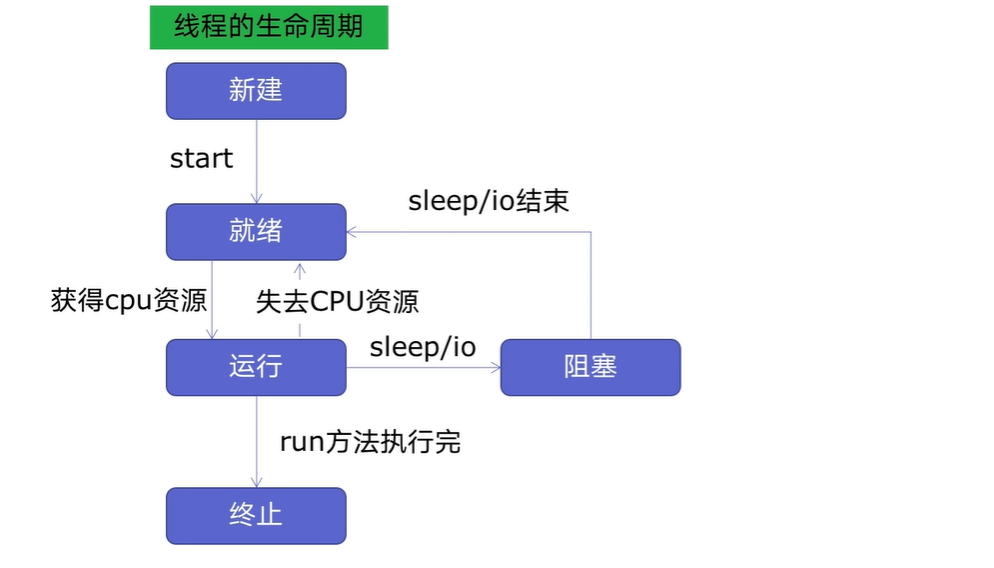
创建多线程
- 导入模块from threading import Thread
- 编写target函数
- 创建线程 t1 = Thread(target=xxx,args=(xx,))
- 启动线程 t1.start()
- 等待线程结束t1.join() ```python import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=’utf-8’) from random import randint from threading import Thread from time import time, sleep
def download(filename): print(‘开始下载%s…’ % filename) time_to_download = randint(5, 10) sleep(time_to_download) print(‘%s下载完成! 耗费了%d秒’ % (filename, time_to_download))
def main(): start = time() t1 = Thread(target=download, args=(‘Python从入门到住院.pdf’,)) t1.start() t2 = Thread(target=download, args=(‘Peking Hot.avi’,)) t2.start() t1.join() t2.join() end = time() print(‘总共耗费了%.3f秒’ % (end - start))
if name == ‘main‘: main()
<a name="QlfGl"></a>## 创建自定义线程类我们可以直接使用threading模块的`Thread`类来创建线程,但是我们之前讲过一个非常重要的概念叫“继承”,我们可以从已有的类创建新类,因此也可以通过继承`Thread`类的方式来创建自定义的线程类,然后再创建线程对象并启动线程。代码如下所示。```pythonfrom random import randintfrom threading import Threadfrom time import time, sleepclass DownloadTask(Thread):def __init__(self, filename):super().__init__()self._filename = filenamedef run(self):print('开始下载%s...' % self._filename)time_to_download = randint(5, 10)sleep(time_to_download)print('%s下载完成! 耗费了%d秒' % (self._filename, time_to_download))def main():start = time()t1 = DownloadTask('Python从入门到住院.pdf')t1.start()t2 = DownloadTask('Peking Hot.avi')t2.start()t1.join()t2.join()end = time()print('总共耗费了%.2f秒.' % (end - start))if __name__ == '__main__':main()
threading方法
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
-
线程同步(安全)
线程安全指某个函数在多线程环境中被调用时,能够正确地处理多个线程之前的共享变量,使程序功能正确.
相反的,由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全.Lock解决线程安全问题
使用Lock的方式
- try-finally模式 ```python import threading
lock = threading.Lock() lock.acquire() try: do() finally: lock.release()
- with模式```pythonimport threadinglock = threading.Lock()with lock:do
- 代码实例
- 线程不安全性 ```python import threading import time
class Account(): def init(self, balance): self.balance = balance
def draw(account, amount): if account.balance >= amount: time.sleep(0.1) #休眠0.1秒,让线程堵塞,使异常必现 print(threading.current_thread().name, “取钱成功”) account.balance -=amount print(threading.current_thread().name, “余额”, account.balance) else: print(threading.current_thread().name, “取钱失败,余额不足”)
if name == “main“: account = Account(1000) t1 = threading.Thread(target=draw, args=(account, 600)) t2 = threading.Thread(target=draw, args=(account, 600)) t1.start() t2.start()
- **增加lock锁**```pythonimport threadingimport timelock = threading.Lock()class Account():def __init__(self, balance):self.balance = balancedef draw(account, amount):with lock:if account.balance >= amount:time.sleep(0.1)print(threading.current_thread().name, "取钱成功")account.balance -=amountprint(threading.current_thread().name, "余额", account.balance)else:print(threading.current_thread().name, "取钱失败,余额不足")if __name__ == "__main__":account = Account(1000)t1 = threading.Thread(target=draw, args=(account, 600))t2 = threading.Thread(target=draw, args=(account, 600))t1.start()t2.start()
lock坏处及死锁
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行
坏处
- 性能:首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
- 死锁:由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
- 生活的场景:A,B一起化妆,都需要经历涂口红、涂眼影的动作。当A在涂眼影,B在涂口红,A,B都需要获取对方的道具时,就会互相僵持,引发死锁。
线程通信(队列)
生产者是一条线程,消费者是一条线程,中间有一个产品,有产品的话就去通知,没有的话等待,两条线程就互相等,你等我,我等你,产生了一些协作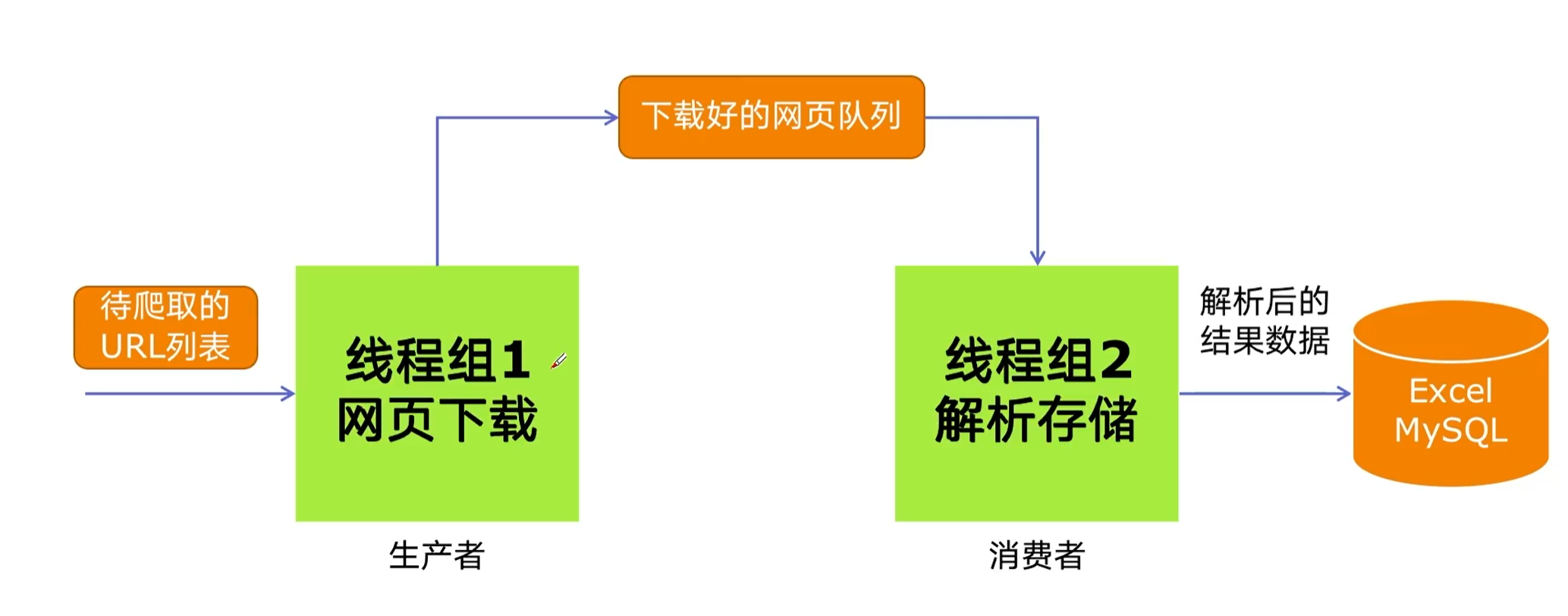
Queue模块中的常用方法
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
Queue实现线程通信
```python import queue import time import random import threading import requests from bs4 import BeautifulSoup
class BlogSpider: def init(self): self.urls = [ f”https://www.cnblogs.com/sitehome/p/{page}“ for page in range(1, 50 + 1) ]
def craw(self, url):# print("craw url: ", url)r = requests.get(url)return r.textdef parse(self, html):# class="post-item-title"soup = BeautifulSoup(html, "html.parser")links = soup.find_all("a", class_="post-item-title")return [(link["href"], link.get_text()) for link in links]
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue): while True: url = url_queue.get() html = blog_spider.craw(url) html_queue.put(html) print(threading.current_thread().name, f”craw {url}”, “url_queue.size=”, url_queue.qsize()) time.sleep(random.randint(1, 2))
def do_parse(html_queue: queue.Queue, fout): while True: html = html_queue.get() results = blog_spider.parse(html) for result in results: fout.write(str(result) + “\n”) print(threading.current_thread().name, f”results.size”, len(results), “html_queue.size=”, html_queue.qsize()) time.sleep(random.randint(1, 2))
if name == “main“: blog_spider = BlogSpider() url_queue = queue.Queue() html_queue = queue.Queue() for url in blog_spider.urls: url_queue.put(url)
for idx in range(3):t = threading.Thread(target=do_craw, args=(url_queue, html_queue),name=f"craw{idx}")t.start()fout = open("02.data.txt", "w")for idx in range(2):t = threading.Thread(target=do_parse, args=(html_queue, fout),name=f"parse{idx}")t.start()
<a name="BIwqd"></a># 线程池新建线程系统需要分配资源,终止线程需要回收资源,如果可以重用线程,则可以减去新建/终止的开销<a name="xrjWt"></a>## 线程池的原理及优势- 原理线程池预创建了N个线程,新任务插入任务队列中,已创建的线程会从队列中挨个取出任务进行执行,没有任务后,又回到线程池,不进行销毁<br />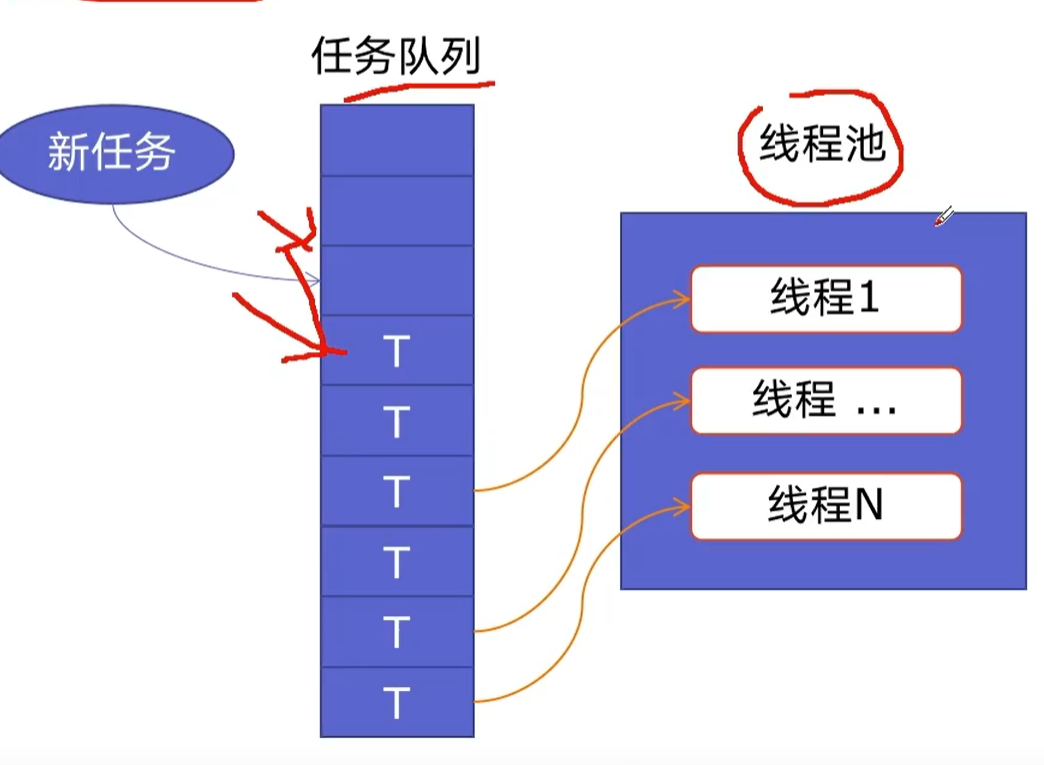- 优势- 提升性能:减去了大量的新建、终止线程的开销,重用了线程资源;- 使用场景:使用处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短- 防御功能:能有效避免系统因为创建线程过多,导致系统负荷过大响应变慢等问题- 代码优势:使用线程池的语法比自己新建线程执行线程更加简介<a name="W0YJ9"></a>## 线程池代码实现```pythonimport concurrent.futuresimport blog_spider# crawwith concurrent.futures.ThreadPoolExecutor() as pool:htmls = pool.map(blog_spider.craw, blog_spider.urls)htmls = list(zip(blog_spider.urls, htmls))for url, html in htmls:print(url, len(html))print("craw over")# parsewith concurrent.futures.ThreadPoolExecutor() as pool:futures = {}for url, html in htmls:future = pool.submit(blog_spider.parse, html)futures[future] = url#for future, url in futures.items():# print(url, future.result())for future in concurrent.futures.as_completed(futures):url = futures[future]print(url, future.result())
异步IO
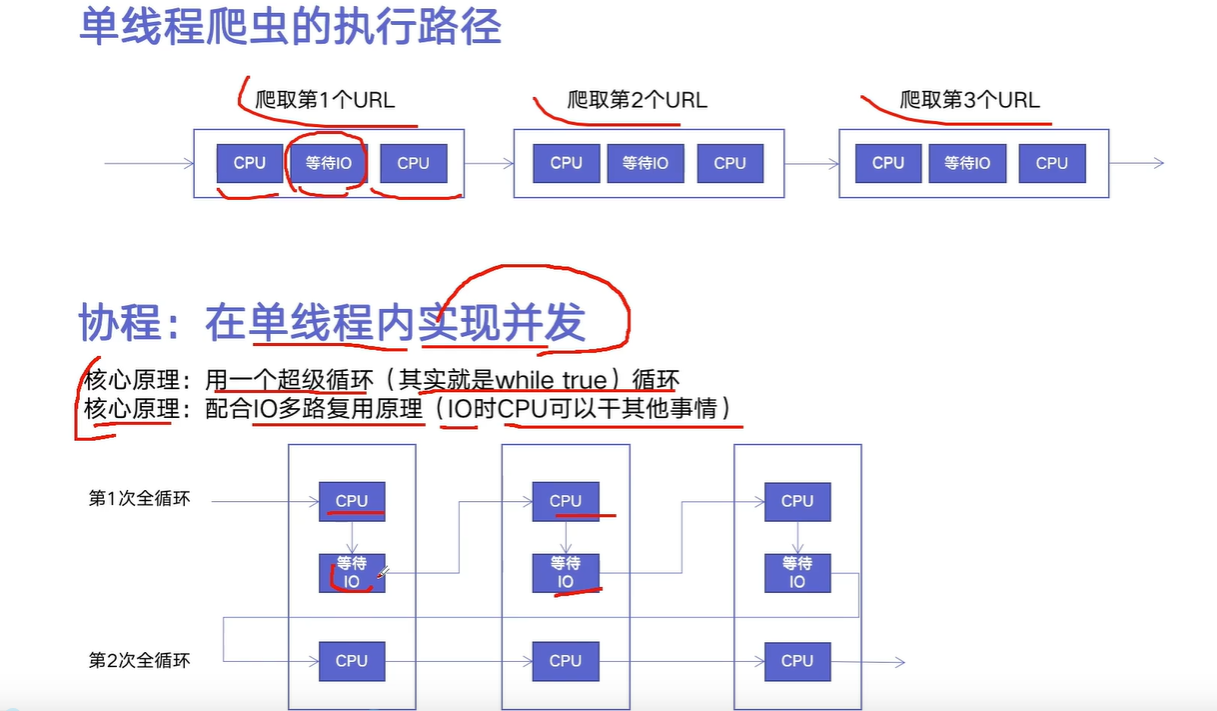
asyncio
- 调用步骤 ```python import asyncio
1.获取事件循环
loop = asyncio.get_event_loop()
2.定义协程
async def myfunc(test): await print_test(test)
3.创建任务列表
tasks = [loop.create_task(myfunc(i)) for i in range(10)]
4.执行任务列表
loop.run_until_complete(asyncio.wait(tasks)) ```

若有收获,就点个赞吧
0 人点赞
