在hashMap的分析上面,很多大佬出过文章,我自己感觉不去阅读一遍源码。单纯的看分析,背特性。容易与编程的灵活性背道而驰,真正成为了八股文知识。其实在hashMap的设计上面有很多的知识点。
散列函数
在这里先引入一个简单的需求,假设我有一个字符串集合{“Abc”,”Def”,”Ghi”},现在需要将这些字符串保存到内存中,而且要求能够快速查找。
由于使用地址下标查找的时间复杂度为O(1),所以我们可以提取单个字符串保存在内存中时的地址。如下图所示,现在我们得到了一个天然的映射关系:即存储地址与存储内容,使用json字符串可以这样表示:
{"0x01":"Abc","0x02":"Def","0x03":"Ghi"}
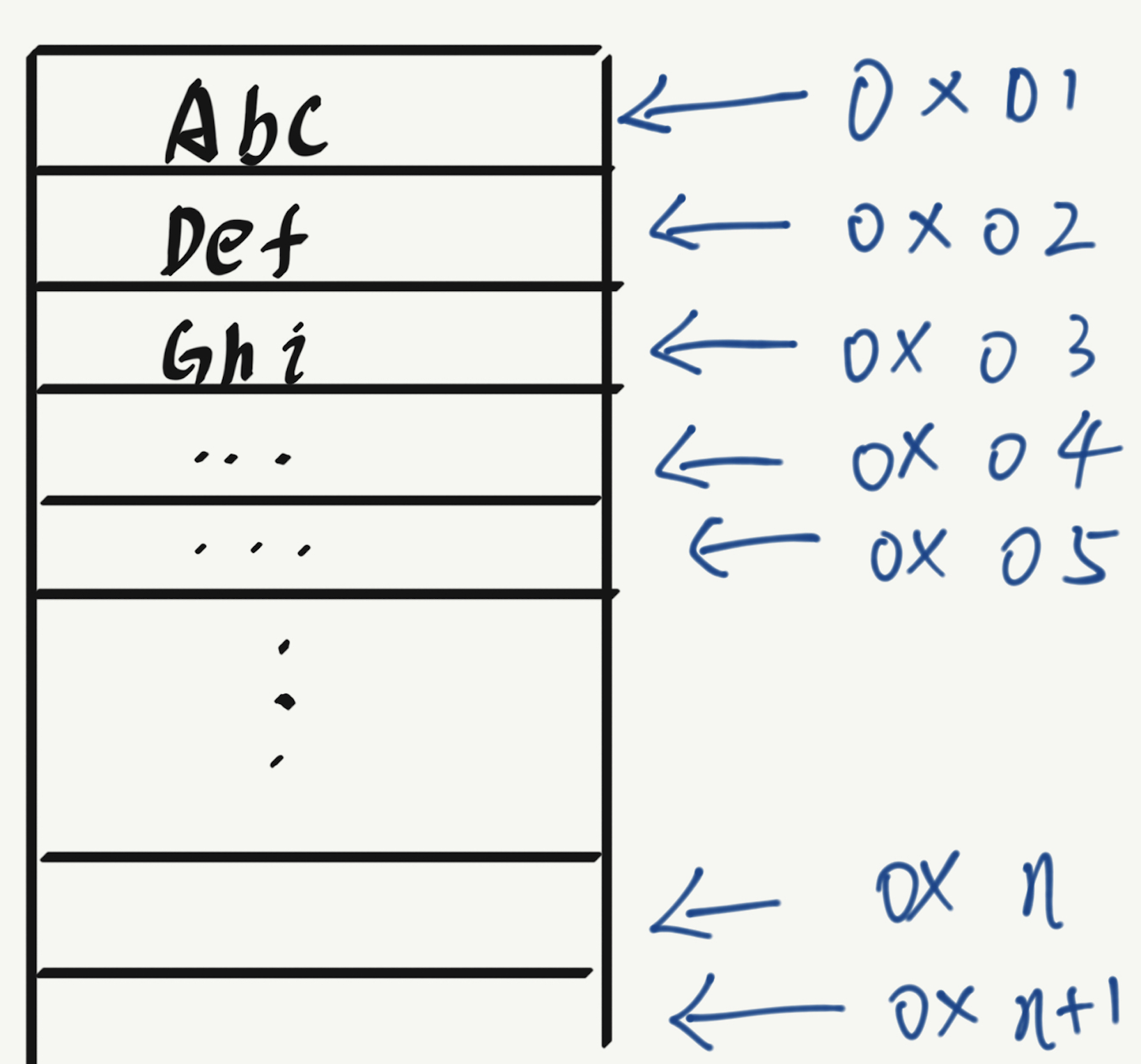
这里要注意,计算机是可以根据地址直接取到值的,所以我们根据存储地址与存储内容的映射关系可以快速的查找想要的值。这样我们就构建了一个索引结构—键值数据(key-value Data)。键值数据是非常常见的,对于hashMap较为复杂的结构来说,这是一个基础的构建模块。
现在使用java中的HashMap
由于java中字符串是以对象的形式体现的,而对象都拥有自身的hashCode,可以根据字符串这个对象的hashCode经过一些特殊处理存到一个数组,再使用这个数组与值建立起映射关系。这样我们就可以根据字符串—>hashCode-(特殊处理)->数组地址—>值的映射关系来快速查找。
如果你熟悉了这个流程,那么在这里引入散列函数与散列表的概念:
已知一个有限的连续的地址集(区间),对于关键字K,必定存储在f(K)的位置上。由此,不必比较便可以得到所查记录,称这个对应关系为散列函数,按照这个函数建立起的表称为散列表。
由于地址集是有限的,对于不同的关键字可能会得到相同的结果。即:key1 != key2,但是f(key1) = f(key2),这种现象称为碰撞。
扰动函数
若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为扰动函数,这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。扰动函数即上面提到的对hashCode值的特殊处理。
java中hashMap的扰动函数:
拉链法
当多个键值对经过扰动函数计算,在hashMap同一个数组节点产生碰撞时,需要对数据进行处理。java中处理的方式是:将此数组节点的地址指向一个链表,产生碰撞后将第二个到来的数据挂在链表后面。jdk8之后此链表长度大于8会向红黑树进行转化。以降低查找复杂度。(从O(n)降低至O(logn))
所以对于一个hashMap
String值—>hashCode经过扰动函数的值—>数组节点地址—>指向的链表—>链表中对应的节点位置

若有收获,就点个赞吧
0 人点赞
