本篇内容主要是2021年9月针对leetcode进行刷题,过程中学习《labuladong的算法小抄》作为刷题主要参考,整理的部分笔记。
数据结构存储方式
只有两种,数组(顺序存储)和链表(链式存储)。 数组方式,连续存储、结构紧密,需要分配一块连续的存储空间,所以每次扩容会面对重新分配连续空间,将原数据整体复制。如果要进行中间插入删除,每次必须搬移中间位置开始后所有数据。
链表方式,元素不连续,指针指向下一元素。不存在扩容问题,但无法随机访问,每个元素包含前后元素指针,消耗更多空间。 其他数据结构是基于该两种数据结构的基础上产生的,只是对外暴露的方法是不同。
基本操作
基本操作无外乎遍历+访问,再进行增删改查。
各种数据结构遍历方式可抽象为两种,线性与非线性。
线性即for、while迭代。 非线性即递归。
class T {/*** 线性迭代*/void traverse(int[] arr) {for (int i = 0; i < arr.length; i++) {// 迭代访问arr[i]}}/*** 链表遍历*/class ListNode {int val;ListNode next;}void traverse(ListNode head) {for (ListNode p = head.next; p != null; p = p.next) {// 迭代访问 p.val}}void traverse(ListNode head) {// 递归访问head.valtraverse(head.next);}/*** 二叉树遍历框架*/class TreeNode {int val;TreeNode left, right;}void traverse(TreeNode root) {traverse(root.left);traverse(root.right);}/*** 拓展:n叉树遍历框架*/class TreeNode {int val;TreeNode[] children;}void traverse(TreeNode root) {for (TreeNode child : root.children) {traverse(child);}}/*** 拓展:在n叉树上,可得到图的遍历方式,图即若干棵n叉树* 注意:图上如果出现环怎么处理,使用boolean[] visited做标记*/}
体会上述代码,各种数据结构的访问方式无外乎从基础访问方式中延伸出来。 掌握基础的数据结构,从中汲取通用方式即可。
二叉树问题集锦
/*** 二叉树*/class BinaryTree {/*** 二叉树最大路径和*/class leetcode124 {int ans = INT_MIN;int oneSideMax(TreeNode root) {if (root == nullptr) {return 0;}int left = max(0, oneSideMax(root.left));int right = max(0, oneSideMax(root.right));ans = max(ans, left + right + root.val);return max(left, right) + root.val;}}/*** 根据前序遍历和中序遍历的结果还原二叉树*/class leetcode105 {TreeNode buildTree(int[] preorder, int preStart, int preEnd, int[] inorder, int inStart, int inEnd, Map<Interger, Interger> inMap) {if (preStart > preEnd || inStart > inEnd) {return null;}TreeNode root = new TreeNode(preorder[preStart]);int inRoot = inMap.get(root.val);int numsLeft = inRoot - inStart;root.left = buildTree(preorder, preStart + 1, preStart + numsLeft, inorder, inStart, inRoot - 1, inMap);root.right = buildTree(preorder, preStart + numsLeft + 1, preEnd, inorder, inRoot + 1, inEnd, inMap);return root;}}/*** 恢复一棵BST* 中序遍历*/class leetcode99 {void traverse(TreeNode node) {if (!node) {return;}traverse(node.left);if (node.val < prev.val) {s = (s == NULL) ? prev : s;t = node;}prev = node;traverse(node.right);}}}
二叉树的问题解决若干->get递归的精髓->递归的问题就是树的问题。 这种分类刷题的方法,可以抽象成,学习一类框架,通过例子加深学习,最终掌握框架、活学活用。
动态规划凑零钱的例子非常形象,本质上也是个递归的问题,但是在思考题目本身的问题时,很容易被各种条件,边界等等影响思路,实际上,先回归到该种类型本身,可以抽象出一个简单模型
class Coin {void coin(List<Integer> coins, int amount) {}int dp(int n) {if (n == 0) {return 0;}if (n < 0) {return -1;}int res = INT_MIN;for (Integer coin : coins) {subproblem = dp(n - coin);if (subproblem == -1) {continue;}res = min(res, 1 + subproblem);}return res != INT_MIN ? res : -1;}/*** 我猜你也看不懂上面的* 换成下面的人话就简单很多*/int dp(int n) {for (Integer coin : coins) {dp(n - coin);}}}
动态规划解题详解
动态规划问题的一般形式在于求解最值,核心问题在于穷举,但因为动态规划问题存在重叠子问题,所以必然具备最优子结构。 求解过程:
- 明确 状态
- 定义dp数组or函数的含义
- 明确 选择
- 明确 base case
下面通过两个例子来辅助理解:
案例
斐波那契数列
该例子主要用于讲解算法设计是一个螺旋上升的优化过程。
- 暴力递归
class Solution {public int fib(int n) {if (n == 1 || n == 2) {return 1;}return fib(n - 1) + (n - 2);}}

从上方图片可以看到,在暴力递归的过程中,递归树会有许多重复计算问题,相同子树多次运算,这使得算法效率底下。 递归算法时间复杂度为:子问题个数x单个子问题需要运算的时间。二叉树的子树为指数级别,子问题分解为2^n个。
故而该算法时间复杂度为O(2^n)。
- 带备忘录的递归法
该算法为针对上面的重叠子问题的一种优化:将已运算的子问题解缓存,每次求解子问题先从缓存中查找,没有再进行计算,更新缓存。
class Solution {public int fib(int n) {int[] results = new int[n + 1];return help(n, results);}public int help(int n, int[] results) {if (n == 1 || n == 2) {return 1;}if (results[n] != 0) {return results[n];}results[n] = help(n - 1, results) + help(n - 2, results);return results[n];}}
- dp数组迭代法
备忘录方法是自顶向下的,缺少什么就运算什么,反过来,自底向上可以从最小规模求解,逐步推到答案。
class Solution {public int fib(int n) {int[] results = new int[n + 1];results[1] = 1;results[2] = 1;for (int i = 3; i <= n; i++) {results[i] = results[i - 1] + results[i - 2];}return results[n];}}
凑零钱问题
给K种面值的硬币,面值不同,数量无限,再给出总金额,求问最少需要几枚硬币可以凑出总金额,如果不行则返回-1
- 确定状态:状态即原问题和子问题中的变量,唯一状态是目标金额amount;
- 定义dp函数:目标金额为n。至少需要dp(n)个硬币;
- 确定选择:从coins选出硬币,目标金额减少;
- 明确base case:目标金额为0时,所需硬币为0,小于0时无解。
回溯算法解题详解
回溯问题 = 决策树遍历过程 思考:路径、选择列表、结束条件 框架伪代码如下:
result = []def backtrack(路径, 选择列表):if 满足结束条件:result.add(路径)returnfor 选择 in 选择列表:做选择backtrack(路径, 选择列表)撤销选择
回溯算法不存在重叠子问题,纯暴力枚举,复杂度高。
【例】给你⼀个 N×N 的棋盘, 让你放置 N 个 皇后, 使得它们不能互相攻击。 PS: 皇后可以攻击同⼀⾏、 同⼀列、 左上左下右上右下四个⽅向的任意单 位。
class Solution {List<List<Charater>> res = new ArrayList<>();List<List<Charater>> solveNQueens(int n) {List<List<Charater>> board = new ArrayList<>(8);for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {board[i][j] = '.';}}backtrack(board, 0);return res;}void backtrack(int row) {if (row == board.length) {res.put(board);return;}int n = board[row].length;for (int col = 0; col < n; col++) {if (!isValid(board, row, col)) {continue;}board[row][col] = 'Q';backtrack(board, row + 1);board[row][col] = ',';}}boolean isValid(List<List<Charater>> board, int row, int col) {int n = board.length;for (int i = 0; i < n; i++) {if (board[i][col] == 'Q')return false;}for (int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {if (board[i][j] == 'Q') {return false;}}for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {if (board[i][j] == 'Q') {return false;}}return true;}// 解法复杂度过高,优化算法boolean backtrack(List<List<Charater>> board, int row) {if (row == board.size()) {res.put(board);return;}int n = board[row].size();for (int col = 0; col < n; col++) {board[row][col] = 'Q';if (backtrack(board, row + 1)) {return true;}board[row][col] = ',';}}}
BFS广度优先搜索
通常写广搜算法都使用队列实现,BFS与DFS相比,BFS找到的路径最短,空间复杂度却相对大很多 广搜算法求解问题通常本质是在图上找从起点到终点的最近距离。 框架代码如下:
class Solution {int bfs(Node start, Node target) {Queue<Node> q = new LinkedList<>();// 避免走回头路Set<Node> visited;// 将七点加入队列q.offer(start);visited.add(start);// 记录扩散步数int step = 0;while (q.size() > 0) {int size = q.size();for (int i = 0; i < size; i++) {Node current = q.poll();// 判断是否达到终点if (current.equals(target)) {return step;}for (Node x : current.adj()) {// 将相邻节点加入队列if (visited.contains(x)) {q.offer(x);visited.add(x);}}// 更新步数step++;}}}}
BFS算法缺点,队列每次都会存储着二叉树一层的节点,最坏情况下队列中存储树的最底层节点数量,即N/2,空间复杂度为O(n),所以通常在寻找最短路径时使用BFS,其余用DFS.
这里引用leetcode752题,该题目设计精巧,在复杂背景下容易忽略如何选择对应框架,抓住题干中关键信息,最小旋转次数,即可推断使用广搜,改题目深搜相当麻烦,存在无解情况需要判断。
双向BFS优化
传统BFS框架是从七点开始向四周扩散,遇到终点停止,双向BFS则是从七点和终点同时开始扩散,当两边有交集停止。 该问题从树上无法直观感受,结合密码锁问题可以理解多一点点。 双向BFS局限性:必须知道终点在哪里。
算法框架:不再使用队列,而是使用HashSet快速判断两个集合是否有交集,while循环的最后,交换q1和q2的内容,默认扩散q1相当于轮流扩散q1,q2。
再优化:在循环的开始,判断哪个集合元素多,每次都选择扩散集合中元素较少的一个,空间增长速度慢,效率更高。
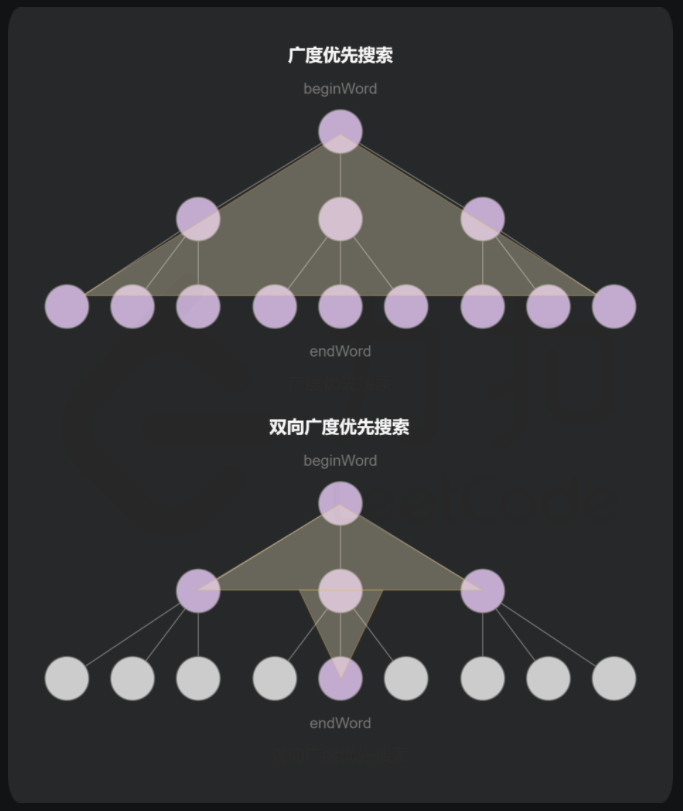
在做leetcode127题时,看到这个图解非常清晰,作为补充理解
class Solution {/*** 该方法比较特别,单个人认为不学也罢,这种方法下居然超时了...* @param deadends* @param target* @return*/int openLock(String[] deadends, String target) {// 使用两个set来记录当前扩散位找交集即结束Set<Integer> q1 = new HashSet<>();Set<Integer> q2 = new HashSet<>();int[] dead = new int[10000];int tar = Integer.parseInt(target);for (String deadend : deadends) {dead[Integer.parseInt(deadend)] = 1;}if (dead[0] == 1 || dead[tar] == 1) {return -1;}int step = 0;q1.add(0);q2.add(tar);while (!q1.isEmpty() && !q2.isEmpty()) {// 再优化技巧点:判断q1,q2长度,每次扩散更小的那个// 原因是空间增加速度慢,效率更高// if (q1.size() > q2.size()) {// temp = q1;// q1 = q2;// q2 = temp;// }Set<Integer> temp = new HashSet<>();for (Integer cur : q1) {if (cur != null) {if (dead[cur] == 1) {continue;}if (q2.contains(cur)) {return step;}for (int j = 0; j < 4; ++j) {int pow = (int) Math.pow(10, j);int next = cur + ((cur / pow % 10 + 1) % 10) * pow - (cur / pow % 10 * pow);if (next >= 10000 || next < 0 || dead[next] == 1) {} else {temp.add(next);}next = cur + ((cur / pow % 10 - 1 + 10) % 10) * pow - (cur / pow % 10 * pow);if (next >= 10000 || next < 0 || dead[next] == 1) {} else {temp.add(next);}}}}q1 = q2;q2 = temp;step++;}return -1;}}
二分查找
难点:思路很简单,细节是魔鬼,mid +1 or -1,while <= or <
框架代码:
class BinarySearch {// 常规搜索方法int binarySearch(int[] nums, int target) {int left = 0, right = nums.length - 1;while (left <= right) {// 防止mid溢出,这样可以避免left + right整型溢出问题int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;} else if (nums[mid] < target) {left = mid + 1;} else if (nums[mid] > target) {right = mid - 1;}}return -1;}// 左侧搜索方法int leftBinarySearch(int[] nums, int target) {int left = 0, right = nums.length;while (left < right) {int mid = (left + right) / 2;if (nums[mid] == target) {right = mid;} else if (nums[mid] < target) {left = mid + 1;} else if (nums[mid] > target) {right = mid;}}if (left == nums.length) {return -1;}return nums[left] == target ? left : -1;}// 【闭区间】左侧搜索方法int leftBoundBinarySearch(int[] nums, int target) {int left = 0, right = nums.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {right = mid - 1;} else if (nums[mid] < target) {left = mid + 1;} else if (nums[mid] > target) {right = mid - 1;}}if (left >= nums.length - 1 || nums[left] != target) {return -1;}return nums[left];}// 右侧搜索方法int rightBinarySearch(int[] nums, int target) {int left = 0, right = nums.length;while (left < right) {int mid = (left + right) / 2;if (nums[mid] == target) {left = mid;} else if (nums[mid] < target) {right = mid;} else if (nums[mid] > target) {left = mid + 1;}}if (left >= nums.length) {return -1;}return nums[left] == target ? left : -1;}// 【闭区间】右侧搜索方法int rightBoundBinarySearch(int[] nums, int target) {int left = 0, right = nums.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {left = mid + 1;} else if (nums[mid] < target) {right = mid - 1;} else if (nums[mid] > target) {left = mid + 1;}}if (right < 0) {return -1;}return nums[right] == target ? right : -1;}}
滑动窗口
【例:76 Minimum Window Substring】
算法思路:
- 在字符串S中使用双指针中左右指针技巧,初始化left = right = 0, 把索引左闭右开区间称作一个窗口[left, right)
- 不断增加right指针扩大窗口,直到窗口中字符串符合要求
- 停止增加right,转而增加left指针缩小窗口,直到不再符合要求
- 重复2、3,直到right到达S尽头。
简言之,第2步找到可行解,第3步优化可行解,最终找到最优解。
class Solution {String minWindow(String s, String t) {if (t == null || "".equals(t)) {return t;}Map<Character, Integer> need = new HashMap<>(), window = new HashMap<>();char[] tc = t.toCharArray();char[] sc = s.toCharArray();for (char c : tc) {need.put(c, need.getOrDefault(c, 0) + 1);}int left = 0, right = 0, valid = 0;// 记录最小覆盖字串起始int start = 0, len = Integer.MAX_VALUE;while (right < sc.length) {// 移入窗口的字符串char c = sc[right];// 窗口右移right++;// 进行窗口内数据的一系列更新if (need.containsKey(c)) {window.put(c, window.getOrDefault(c, 0) + 1);if (window.get(c).equals(need.get(c))) {valid++;}}// 判断左侧窗口是否收缩while (valid == need.size()) {// 更新最小覆盖子串if (right - left < len) {start = left;len = right - left;}// d是将被一处窗口的字符char d = sc[left];// 窗口左移left++;// 进行窗口内数据的一系列更新if (need.containsKey(d)) {if (window.get(d).equals(need.get(d))) {valid--;}window.put(d, window.getOrDefault(d, 0) - 1);}}}// 返回最小覆盖字串return len == Integer.MAX_VALUE ? "" : s.substring(start, len);}}
股票买卖问题-状态机
这一节中介绍了很多leetcode上股票买卖相关的问题,抽象来看,都是状态机的问题,找出总共有哪些状态,然后列举出每种状态的选择,就可以 抽象代码为:
for 状态1 in 状态1的所有取值:for 状态2 in 状态2的所有取值:for ...dp[状态1][状态2][...] = 择优(选择1, 选择2...)
以股票问题为例,每天面对三种选择:买入buy、卖出sell、无操作rest,注意,并不是每天都可以进行上述三种操作,sell必须再buy后,buy必须再sell后,rest也分为buy后rest和sell后rest。
同时,还有交易次数限制k次,即买入必须在k>0的情况下操作。 换入对应的问题,列举该问题的状态:天数i、交易次数k、当前持有状态,则选择三维数组存放状态。
dp[i][k][0 or 1]// n为总天数,K为最大允许交易次数0 <= i <= n - 1, 1 <= k <= K此问题总共有n X K X 2中状态,则穷举即可。for 0 <= i < n:for 1 <= k <= K:for s in {0, 1}:dp[i][k][s] = max(buy, sell, rest)
可见,最终求解答案为dp[n - 1][K][0],即最后一天允许K次操作,最终卖出股票获得利润。 列举完了所有状态,来考虑状态转移框架。
如果我当前卖出,则下次操作无法卖出,买入后则状态变为买入,资金减去今天买入金额,无操作则保持为卖出状态。 如果我当前买入,则下次操作无法买入,卖出后则状态变为卖出,资金加上今天卖出金额,无操作则保持为买入状态。
dp[i][k][0] = max(dp[i - 1][k][1] + price[i], dp[i - 1][k][0])= max(买入, 休息)dp[i][k][1] = max(dp[i - 1][k + 1][0] - price[i], dp[i - 1][k][0])= max(卖出, 休息)
注意,上面的K次操作包含了买入+卖出为一次,故只需要在一种操作时增加次数即可。 在得到上面的状态转移方程后,只需要再定义出base case就可以,即最简单的问题。
i = -1 即还没有开始,最初始的状态,此时利润为0,没有持有股票,故不可能卖出。 dp[-1][k][0] = 0 dp[-1][k][1] = -infinity k = 0
即还没有开始操作,此时利润为0,没有持有股票,故不可能卖出。 dp[i][0][0] = 0 dp[i][0][1] = -infinity
优化思路:
dp[i][1][0] = max(dp[i-1][1][0], dp[i-1][1][1] + prices[i])dp[i][1][1] = max(dp[i-1][1][1], dp[i-1][0][0] - prices[i])= max(dp[i-1][1][1], -prices[i])解释: k = 0 的 base case, 所以 dp[i-1][0][0] = 0。可以看到,这里的k仅存在一种状态,都是 1, 不会改变, 即 k 对状态转移已经没有影响了。可以进⾏进⼀步化简去掉所有 k:dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i])dp[i][1] = max(dp[i-1][1], -prices[i])
题解如下:
class Solutions {/*** 第一题, K = 1* @return*/int getMoney1() {int[][] dp = new int[n][2];int[] price = new int[n];for (int i = 0; i < n; ++i) {if (i - 1 == -1) {dp[i][0] = 0;dp[i][1] = -price[i];continue;}dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + price[i]);dp[i][1] = Math.max(-price[i], dp[i - 1][1]);}return dp[n - 1][0];}int getMoney1youhua() {// int[][] dp = new int[n][2];// 因为该题目中状态仅仅与前一次状态有关,而不需要完整过程,故而可以降低空间复杂度到O(1)int dp_i_0 = 0, dp_i_1 = -price[0];int[] price = new int[n];for (int i = 0; i < n; ++i) {// if (i - 1 == -1) {// dp[i][0] = 0;// dp[i][1] = -price[i];// continue;// }dp_i_0 = Math.max(dp_i_0, dp_i_1 + price[i]);dp_i_1 = Math.max(-price[i], dp_i_1);// dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + price[i]);// dp[i][1] = Math.max(-price[i], dp[i - 1][1]);}return dp_i_0;}}
打家劫舍问题-经典动态规划问题
leetcode上有三道打家劫舍问题,层层递进,属于非常经典的动态规划问题。
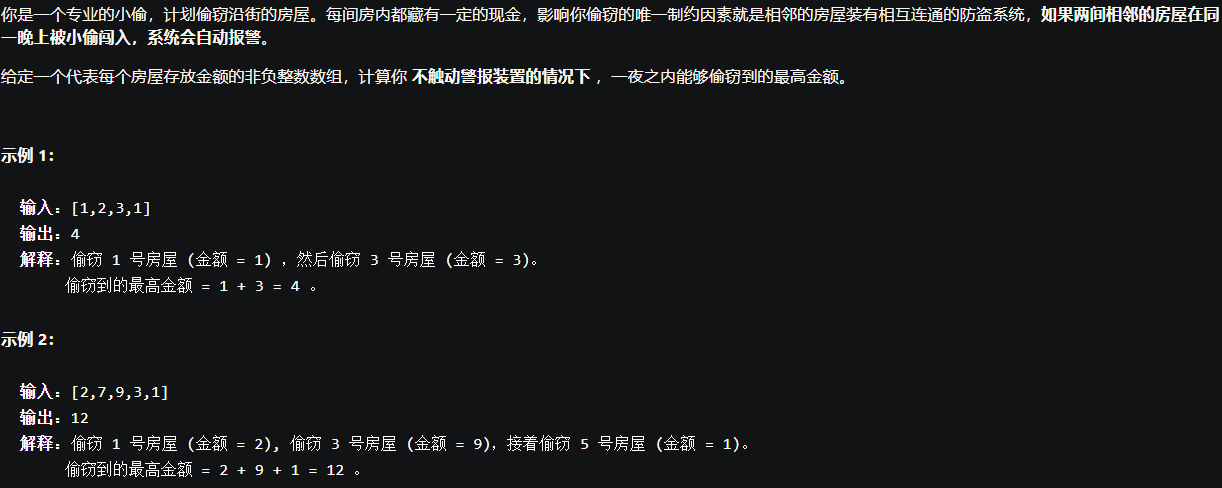

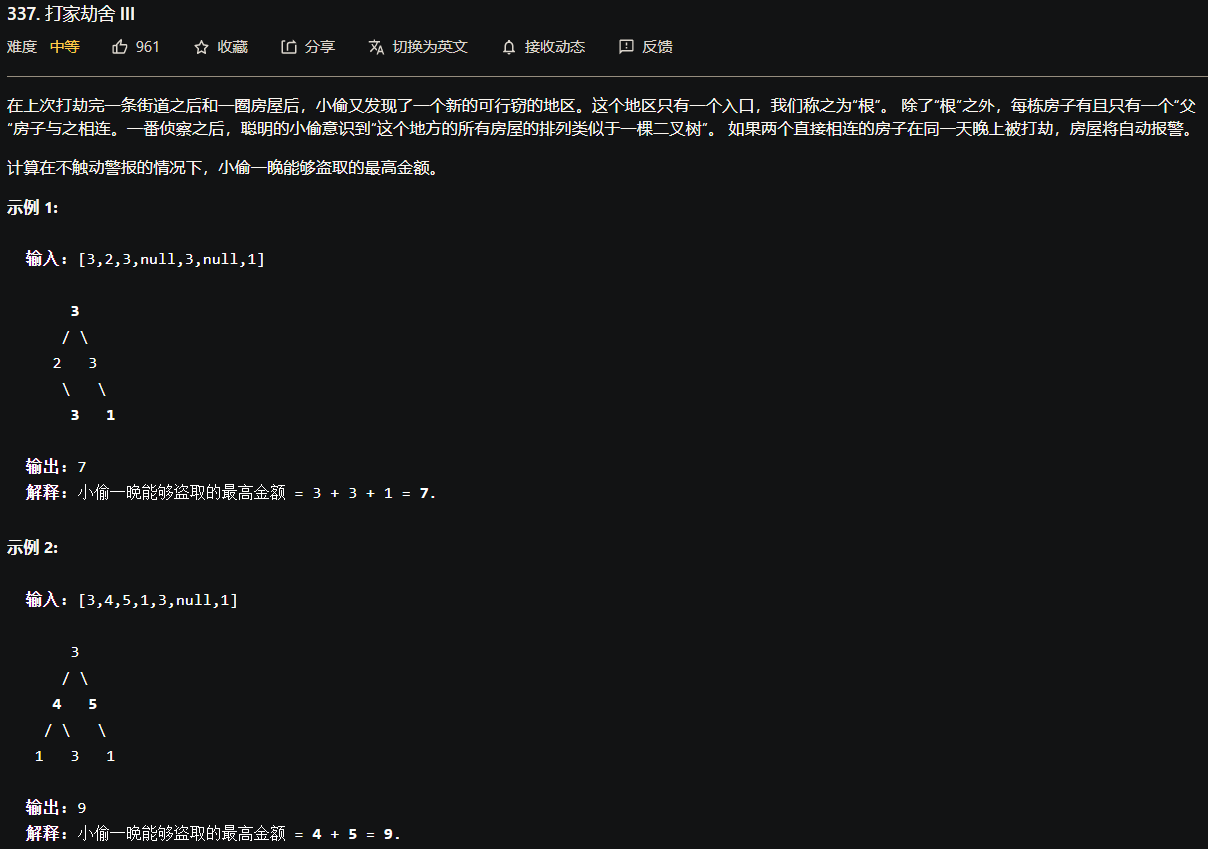
前文有讲过,动态规划的过程就是找[状态]和[选择],从第一题入手分析,盗贼从左向右走过房屋,每间房子都可以选择抢or不抢,如果抢了该间则不能抢下一间,不抢该间则可以抢下一间,走过最后一间则没有抢了。
那么第i间房屋就是状态,抢与不抢就是选择。 下面是代码实现与优化:
class Solution {/*** 第一种解法,最简单的形式,直接dp求解* @return*/public int rob(int[] nums) {return dp(nums, 0);}public int dp(int[] nums, int start) {if (start >= nums.length) {return 0;}return Math.max(nums[start] + dp(nums, start + 2), dp(nums, start + 1));}/*** 第二种解法,带备忘录的动态规划递归解法,效率明显提升* @param nums* @return*/public int rob(int[] nums) {int[] memo = new int[nums.length];return dp(memo, nums, 0);}public int dp(int[] memo, int[] nums, int start) {if (start >= nums.length) {return 0;}if (memo[start] != 0) {return memo[start];}memo[start] = Math.max(dp(memo, nums, start + 2) + nums[start], dp(memo, nums, start + 1));return memo[start];}/*** 第三种解法,非递归,自底向上的解法* @param nums* @return*/public int rob(int[] nums) {int[] result = new int[nums.length + 2];for (int i = nums.length - 1; i >= 0; i--) {result[i] = Math.max(result[i + 1], result[i + 2] + nums[i]);}return result[0];}/*** 第四种解法,非递归,自底向上的解法* 较上一种解法在空间上更优,最后只需要result[0],只与前两个状态相关,而与其他无关* @param nums* @return*/public int rob(int[] nums) {int result_i_1 = 0, result_i_2 = 0;for (int i = nums.length - 1; i >= 0; i--) {int temp_result = Math.max(result_i_1, result_i_2 + nums[i]);result_i_2 = result_i_1;result_i_1 = temp_result;}return result_i_1;}/*** 题目二的求解,实质上就是题目一的分治,通过情况划分,找到两个局部最优再得到最终最优解* 这个题目的解法让我想起来之前做30题的时候,我苦于不知道如何对aa这种词做拆分,实际上,如果也能理解成这种局部最优,就可以理解按照词长取余即可* @param nums* @return*/public int robII(int[] nums) {if (nums.length == 1) {return nums[0];}return Math.max(rob3(Arrays.copyOfRange(nums, 0, nums.length - 1)), rob3(Arrays.copyOfRange(nums, 1, nums.length)));}/*** 题目三的求解,这道题在我本身递归二叉树的解法上增加了数组保存两种结果,不需要重复计算相同递归结果,也没有引入数据结构复杂的备忘录,称得上是一道好解法,需要留意噢* 本质上可能还是接近通过仅保留最近的两种状态即可,无需记录完整历史* @param root* @return*/public int robIII2(TreeNode root) {int[] res = dp1(root);return Math.max(res[0], res[1]);}public int[] dp1(TreeNode root) {if (root == null) {// {不抢, 抢}return new int[]{0, 0};}int[] left = dp1(root.left);int[] right = dp1(root.right);// 注意这里是这家不抢,下家可以抢也可以不抢,取决于价值大小int res0 = Math.max(left[1], left[0]) + Math.max(right[0], right[1]);int res1 = root.val + left[0] + right[0];return new int[]{res0, res1};}}
N数之和
N数之和的题目,通常是给定一个数组,要求使用其中n个数组,凑出和是给定target的组合。
当题目给定的N是2时,通常第一想法是先对数组排序,通过双指针拿到符合两数之和为target的组合。
再次基础上,可以将题目泛化成nums中有多对元素之和等于target,请返回所有不重复的元素对。
class Solutions {
public List<int[]> twoSumTarget(int[] nums, int target) {
Arrays.sort(nums);
List<int[]> result = new ArrayList<>();
int lo = 0, hi = nums.length - 1;
while (lo < hi) {
int sum = nums[lo] + nums[hi];
// 记录索引 lo 和 hi 最初对应的值
int left = nums[lo], right = nums[hi];
if (sum < target) {
while (lo < hi && nums[lo] == left) {
lo++;
}
} else if (sum > target) {
while (lo < hi && nums[hi] == right) {
hi--;
}
} else {
result.add(new int[]{left, right});
// 跳过所有重复的元素
while (lo < hi && nums[lo] == left) {
lo++;
}
while (lo < hi && nums[hi] == right) {
hi--;
}
}
}
return result;
}
/**
* 通刷nSum
* @param nums
* @param target
* @param n
* @param index
* @param res
*/
public void nSumTarget(int[] nums, int target, int n, int index, List<Integer> res) {
if (n <= 2) {
int lo = index + 1, hi = nums.length - 1;
while (lo < hi) {
// 记录索引 lo 和 hi 最初对应的值
int left = nums[lo], right = nums[hi];
int sum = target - (left + right);
if (sum > 0) {
while (lo < hi && nums[lo] == left) {
lo++;
}
} else if (sum < 0) {
while (lo < hi && nums[hi] == right) {
hi--;
}
} else {
res.add(nums[lo]);
res.add(nums[hi]);
nSumResults.add(new ArrayList<>(res));
// 跳过所有重复的元素
while (lo < hi && nums[lo] == left) {
lo++;
}
while (lo < hi && nums[hi] == right) {
hi--;
}
res.remove(res.size() - 1);
res.remove(res.size() - 1);
}
}
} else {
for (int i = index + 1; i < nums.length;) {
int current = nums[i];
res.add(current);
nSumTarget(nums, target - current, n - 1, i, res);
while (i < nums.length && nums[i] == current) {
i++;
}
res.remove(res.size() - 1);
}
}
}
}

若有收获,就点个赞吧
0 人点赞
