1. ZK 简介
Zookeeper(动物管理者)简称 ZK,一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 HBase 的重要组件。Zookeeper 使用 Java 编写,但是支持 Java 和 C 两种编程语言。
2. ZK 数据模型
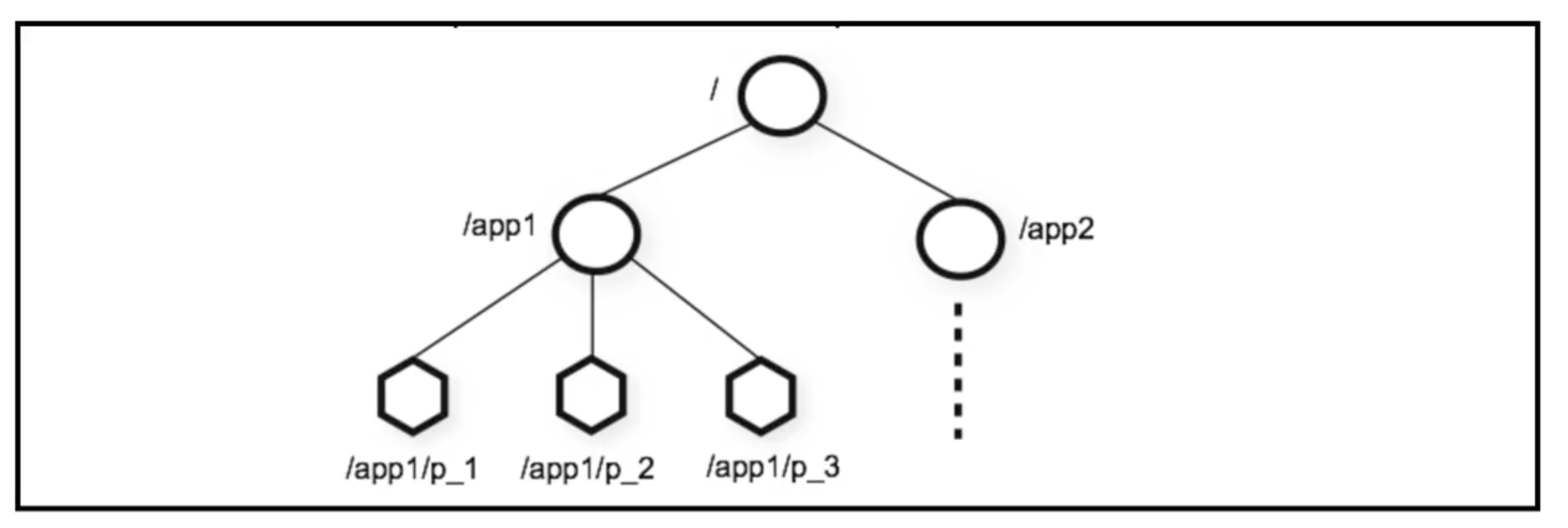
2.1 模型结构
2.2 模型的特点
- 每个子目录如/node1 都被称作一个 znode(节点)。这个 znode 是被它所在的路径的唯一标识。
- znode 可以有子节点目录,并且每个 znode 可以存储数据。
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据。
- znode 可以被监控,包括这个目录节点中存储的数据的修改吗,子节点目录的变化等,一旦变化可以通知设置监控的客户端。
3. 节点的分类
3.1 持久节点(PERSISTENT)
是指在节点创建后,就一直存在,直到有删除操作来主动删除这个节点 — 不会因为创建该节点的客户端会话失效而消失。
3.2 持久顺序节点(PERSISTENT_SEQUENTIAL)
这类节点的基本特性和上面的节点类型是一致的。额外的特性是,在 ZK 中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,要么在创建子节点过程中,ZK 会自动为给定节点名加上一个数字后缀,作为新的节点名。这歌数字后缀的范围是整型的最大值。
3.3 临时节点(EPHEMERAL)
和持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。
3.4 临时顺序节点(EPHEMERAL_SEQUENTIAL)
具有临时节点特点,额外的是,每个父节点会为他的第一级子节点维护一份时序。这点和刚才提到的持久顺序节点类似。
4. 安装
4.1 Linux 安装
- 安装 JDK 并下载 ZK 安装包
下载链接:https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
解压缩 ZK
tar -vxf apache-zookeeper-3.6.3-bin.tar
移动安装目录
sudo mv apache-zookeeper-3.6.3-bin /usr/loacl
配置 zoo.cfg 配置文件,修改 ZK 的 conf 目录下的 zoo_simple.cfg,修改完后,重命名为 zoo.cfg
改名: cp zoo_simple.cfg zoo.cfg
tickTime=2000initLimit=10syncLimit=5dataDir=/usr/local/apache-zookeeper-3.6.3-bin/zkdataclientPort=2181
启动 ZK,进入到 bin 目录
./zkServer.sh start ../conf/zoo.cfg
连接到 ZK 客户端 ```bash ./zkCli.sh -server ip:2181
查看节点 [zookeeper] 只有唯一一个节点
ls /
注意:可以通过 ./zkCli.sh help 查看客户端所有可以执行的命令。<a name="OBiDP"></a>## 4.2 Docker 安装- 获取 ZK 镜像```powershelldocker pull zookeeper:3.6.3
启动 ZK 服务
docker run --name zk -p 2181:2181 -d zookeeper:3.6.3
4.3 配置文件详细说明
tickTime:集群节点之间的心跳间隔(默认时间为 2s)
- initLimit:初始化集群时集群节点同步超时次数为 10,默认的超时时间为 20 s。
- syncLimit:集群在运行过程中同步数据发送请求和认证次数默认为 5次,超时时间为 10 s。
- dataDir:默认数据存储位置。
- clientPort:ZK 启动占用的端口。
- autopurge.purgeInterval:是否开启快照存储。如果为 0,则不不开启快照存储。默认单位为小时,只要一个小时内业务次数超过 3 次,那么就会保存这个快照。
5. 客户端基本命令
查看根目录节点
ls /
查看指定目录下的子节点
ls path
创建一个节点,并给节点绑定数据(默认是持久性节点) ```markdown
创建持久性节点(默认是持久节点) create path data
创建持久性顺序节点 create -s path data
创建临时性节点(注意:临时节点下面不能有子节点) create -e path data
创建临时性持久节点(注意:临时节点下面不能有子节点) create -e -s path data ```
获取节点数据
get path
修改节点数据
set path data
查看节点状态
stat path
查看节点下孩子和当前节点的状态
ls2 path
查看操作历史
history
删除节点(注意:删除节点不能含有子节点)
delete path
递归删除节点(注意:会将当前节点下的所有节点删除)
rmr path
退出当前会话(会话失效)
quit
6. 节点监听机制(watch)
客户端可以监测 znode 节点的变化。
Znode 节点的变化触发相应的事件,然后清除对该节点的监测。当监测一个 znode 节点时,Zookeeper 会发送通知给监测节点。一个 Watch 事件是一个一次性的触发器,当被设置了 Watch 的数据或目录发送了改变的时候,则服务器将这个改变发送给设置了 Watch 的客户端以便通知它们。
监听节点目录的变化
ls /path true
监听节点数据的变化
get /path true
注意⚠️:
在新版本的 zookeeper 中,我们可以使用 ls path 或者 get path 添加参数 -w 的方式进行实现一次性监听。
- 使用 addWatch 命令能持久监听 path 和 data 的变化。
7. Java 操作 ZK
7.1 创建项目引入依赖
<dependency><groupId>com.101tec</groupId><artifactId>zkclient</artifactId><version>0.10</version></dependency>
7.2 ZK 相关 API
创建节点
/*** 用于测试: zk 创建节点*/@Testpublic void testCreateNode() {// 1. 持久节点 返回创建的节点名称String persistentNodeName = zkClient.create("/node1", "xiaoliao", CreateMode.PERSISTENT);System.out.println("persistentNodeName = " + persistentNodeName);zkClient.createPersistent("/node2", "baiyi");// 2. 创建持久顺序节点zkClient.create("/node1/node2", "baiyi", CreateMode.PERSISTENT_SEQUENTIAL);zkClient.createPersistentSequential("/node1/node3", "baiyi");// 3. 创建临时节点zkClient.create("/node1/e1", "test1", CreateMode.EPHEMERAL);zkClient.createEphemeral("/node1/e2", "test");// 4. 创建临时顺序节点zkClient.create("/node1/es1", "es1", CreateMode.EPHEMERAL_SEQUENTIAL);zkClient.createEphemeralSequential("/node1/es2", "es2");}
删除节点
/*** 用于测试: zk 删除节点*/@Testpublic void testDeleteNode() {// 注意:使用该方法进行删除节点时,节点下不能有子节点boolean delete = zkClient.delete("/node1");System.out.println("delete = " + delete);// 注意:使用该方法可以递归进行删除节点boolean delete1 = zkClient.deleteRecursive("/node1");System.out.println("delete1 = " + delete1);}
查看节点的子节点
/*** 用于测试: zk 查询当前节点下的所有子节点*/@Testpublic void testFindNodes() {// 获取指定路径的节点信息 返回值为当前节点的所有子节点List<String> children = zkClient.getChildren("/");children.forEach(System.out::println);}
获取节点的数据
/*** 用于测试: 查看 zk 某节点的数据* 注意:通过 java 客户端操作必须保证节点存储的数据和获取节点时序列化方式必须要一致*/@Testpublic void testFindNodeData() {Object data = zkClient.readData("/node2");System.out.println("data = " + data);}
注意:如果出现 org.I0Itec.zkclient.exception.ZkMarshallingError: java.io.StreamCorruptedException: invalid stream header: 7869616F 这个异常,那就是创建节点时的序列化和获取节点数据的序列化方式不一致导致的。
查看节点状态信息
/*** 用于测试: 查看 zk 节点状态信息*/@Testpublic void testFindNodeDataAndStat() {Stat stat = new Stat();Object data = zkClient.readData("/node2", stat);System.out.println("data = " + data);System.out.println("stat = " + stat);System.out.println("stat.version = " + stat.getVersion());}
修改节点的数据
/*** 用于测试: zk 修改数据*/@Testpublic void testUpdateNodeData() {zkClient.writeData("/node2", new User("baiyi", 18, new Date()));User user = zkClient.readData("/node2");System.out.println("user = " + user);}
监听节点数据变化
/*** 用于测试: 检测 zK 节点数据变化*/@Testpublic void testWatchNodeDataOnChange() throws IOException {zkClient.subscribeDataChanges("/node2", new IZkDataListener() {/*** 当数据发生变化时,触发当前方法进行相关业务操作* @param s 节点名称* @param o 修改后的节点数据* @throws Exception*/@Overridepublic void handleDataChange(String s, Object o) throws Exception {System.out.println("update nodeName = " + s);System.out.println("update data = " + o);}/*** 当节点被删除时,触发当前方法进行相关业务操作* @param s 节点名称* @throws Exception*/@Overridepublic void handleDataDeleted(String s) throws Exception {System.out.println("update nodeName = " + s);}});// 让程序进入阻塞状态,让当前方法不会退出System.in.read();}
注意:
- 使用 Java 进行监听,这是永久操作的,不会像 终端操作 一样,只能监听一次。
- 使用 Java 程序进程监听,只能监听到由于 Java 程序进行修改数据的变化,无法监听到 终端修改数据的变化。
- 监听节点的目录变化
/*** 用于测试: 监控 zk 节点发生变化*/@Testpublic void testWatchNodeChildrenOnChange() throws IOException {zkClient.subscribeChildChanges("/node1", (s, list) -> {System.out.println("this parent nodeName = " + s);for (String childrenName : list) {System.out.println("childrenName = " + childrenName);}});System.in.read();}
8. ZK 集群
8.1 集群(Cluster)
集群概念:集合同一种软件服务的多个节点同时提供服务。
集群解决了什么问题?

ZK 集群保证数据一致性是通过 ZK 底层的 ZAB 原子广播协议。每个节点都不对数据进行确认,直至所有节点都成功写完数据之后,才会返回 数据写入完成。如果期间有一个节点出现了问题,那么直接就提示 数据写入失败。节点之间的通信是通过 心跳💗 的方式进行。
8.3 集群搭建
这里为了创建方便,只使用了一台机器进行创建三个 ZK 节点进行搭建 ZK 集群。
创建三个 dataDir 目录
mkdir zkdata1 zkdata2 zkdata3
分别在这三个 dataDir 目录下放置 myid 文件
touch ./zkdata1/myid
myid 的内容是 服务器 表示为 1 2 3 节点,内容为 int 数字。
echo "1" >> zkdata1/myid
在 /conf 目录下创建三个 zk 配置文件,分别是 zoo1.cfg, zoo2.cfg, zoo3.cfg ```markdown
zoo1.cfg
tickTime=2000
initLimit=10 syncLimit=5 dataDir=/usr/zookeeper/zkdata1 clientPort=2181 server.1=192.168.0.220:2888:3888 server.2=192.168.0.221:2888:3888 server.3=192.168.0.222:2888:3888
zoo2.cfg
tickTime=2000
initLimit=10 syncLimit=5 dataDir=/usr/zookeeper/zkdata2 clientPort=2181 server.1=192.168.0.220:2888:3888 server.2=192.168.0.221:2888:3888 server.3=192.168.0.222:2888:3888
zoo3.cfg
tickTime=2000
initLimit=10 syncLimit=5 dataDir=/usr/zookeeper/zkdata3 clientPort=2181 server.1=192.168.0.220:2888:3888 server.2=192.168.0.221:2888:3888 server.3=192.168.0.222:2888:3888 ```
9. Java 操作 ZK 集群
这个操作集群和操作单个节点都是异曲同工的事情。只需要对某一个节点进行操作即可。其他节点会对其数据进行同步。
但是建议还是把所有的 ZK 集群的节点 IP 都写上。

若有收获,就点个赞吧
0 人点赞
