lambda表达式
Thread t = new Thread(new Runnable() {public void run(){System.out.println("Hello world");}});//用lamba表达式表示Thread t = new Thread(() -> System.out.println("Hello world"));
Lambda表达式允许直接以内联的形式为函数式接口的抽象,方法提供实现,并把整个表达式作为函数式接口的实例
简单来说就是将表达式作为方法的实现,并内联直接实例化
1、行为参数化:需要一个接收BufferedReader并返回String的Lambda
2、函数式接口传递行为
@FunctionalInterfacepublic interface BufferedReaderProcessor {String process(BufferedReader b) throws IOException;}public static String processFile(BufferedReaderProcessor p) throwsIOException {…}
3、执行行为
public static String processFile(BufferedReaderProcessor p) throwsIOException {try (BufferedReader br =new BufferedReader(new FileReader("data.txt"))) {return p.process(br);}}
4、传递lambda
String result = processFile((BufferedReader br) ->br.readLine() + br.readLine());
int a = 10;// Lambda的类型取决于它的上下文Runnable r1 = () -> {int a = 2; // lambda表达式不能屏蔽类变量,编译出错};// 匿名类的类型是在初始化时确定的Runnable r2 = new Runnable(){public void run(){int a = 2; // 编译正常}};
采用函数接口(默认)
重构方式
// 有条件的延迟执行public void log(Level level, Supplier<String> msgSupplier){if(logger.isLoggable(level)){log(level, msgSupplier.get());}}// 环绕执行String oneLine = processFile((BufferedReader b) -> b.readLine());String twoLines = processFile((BufferedReader b) -> b.readLine() + b.readLine());public static String processFile(BufferedReaderProcessor p) throws IOException {try(BufferedReader br = new BufferedReader(new FileReader("java8inaction/chap8/data.txt"))){return p.process(br);}}public interface BufferedReaderProcessor{String process(BufferedReader b) throws IOException;}
函数式接口
1、Predicate返回boolean函数式接口,如filter
// 定义接收String对象的函数式接口@FunctionalInterfacepublic interface Predicate<T>{boolean test(T t);}public static <T> List<T> filter(List<T> list, Predicate<T> p) {List<T> results = new ArrayList<>();for(T s: list){if(p.test(s)){results.add(s);}}return results;}// 创建boolean函数式接口Predicate,过滤list中为空的对象Predicate<String> nonEmptyStringPredicate = (String s) -> !s.isEmpty();List<String> nonEmpty = filter(listOfStrings, nonEmptyStringPredicate);
2、Consumer访问类型T的对象,并执行其操作,如foreach
@FunctionalInterfacepublic interface Consumer<T>{void accept(T t);}public static <T> void forEach(List<T> list, Consumer<T> c){for(T i: list){c.accept(i);}}forEach( Arrays.asList(1,2,3,4,5), (Integer i) -> System.out.println(i) )
3、Function 接受一个泛型T的对象,并返回一个泛型R的对象将输入对象的信息映射到输出,如map
@FunctionalInterfacepublic interface Function<T, R>{R apply(T t);}public static <T, R> List<R> map(List<T> list, Function<T, R> f) {List<R> result = new ArrayList<>();for(T s: list){result.add(f.apply(s));}return result;}// [7, 2, 6]List<Integer> l = map(Arrays.asList("lambdas","in","action"), (String s) -> s.length());
4、针对专门的输入参数类型的函数式接口的名称都要加上对应的原始类型前缀
public interface IntPredicate{boolean test(int t);}IntPredicate evenNumbers = (int i) -> i % 2 == 0;evenNumbers.test(1000); // true 无装箱Predicate<Integer> oddNumbers = (Integer i) -> i % 2 == 1;oddNumbers.test(1000); // false装箱
| Predicate |
T->boolean | IntPredicate,LongPredicate, DoublePredicate |
|---|---|---|
| Consumer |
T->void | IntConsumer,LongConsumer, DoubleConsumer |
| Function |
T->R | IntFunction IntToDoubleFunction, IntToLongFunction, LongFunction LongToDoubleFunction, LongToIntFunction, DoubleFunction ToIntFunction ToDoubleFunction ToLongFunction |
| Supplier |
()->T | BooleanSupplier,IntSupplier, LongSupplier,DoubleSupplier |
| UnaryOperator |
T->T | IntUnaryOperator, LongUnaryOperator, DoubleUnaryOperator |
| BinaryOperator |
(T,T)->T | IntBinaryOperator, LongBinaryOperator, DoubleBinaryOperator |
| BiPredicate |
(L,R)->boolean | |
| BiConsumer |
(T,U)->void | ObjIntConsumer ObjLongConsumer ObjDoubleConsumer |
| BiFunction |
(T,U)->R | ToIntBiFunction ToLongBiFunction ToDoubleBiFunction |

Optional
读取Optional实例中的变量值
get() // 这些方法中最简单但又最不安全的方法。如果变量存在,它直接返回封装的变量值,否则就抛出一个NoSuchElementException异常orElse(T other) //在Optional对象不包含值时提供一个默认值。orElseGet(Supplier<? extends T> other) //Supplier方法只有在Optional对象不含值时才执行调用orElseThrow(Supplier<? extends X> exceptionSupplier) //Optional对象为空时都会抛出一个异常ifPresent(Consumer<? super T>) //在变量值存在时执行一个作为参数传入的方法,否则就不进行任何操作。

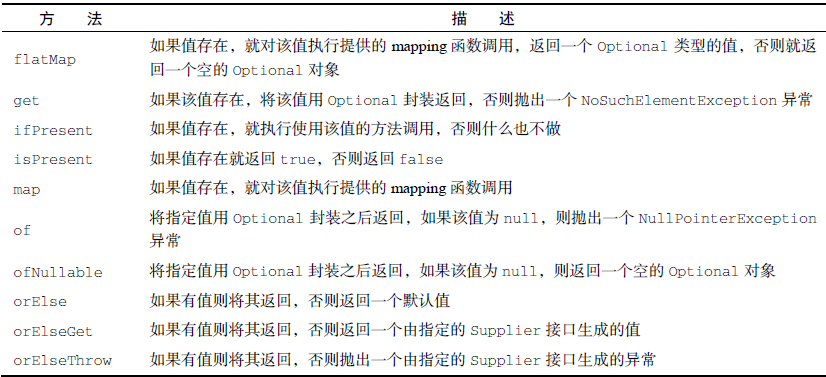
// map.get() 不存在key对应的值// 对潜在为null的对象进行转换,替换为Optional对象Optional<Object>value=Optional.ofNullable(map.get("key"));
基础类型的Optional对象OptionalInt、OptionalLong以及OptionalDouble
不支持map、flatMap、filter方法,也不能作为这些方法的传参
异常
任何函数式接口都不允许抛出受检异常(checked exception)。如果你需要Lambda表达式来抛出异常,有两种办法
// 1、定义一个自己的函数式接口,并声明受检异常@FunctionalInterfacepublic interface BufferedReaderProcessor {String process(BufferedReader b) throws IOException;}// 2、把Lambda包在一个try/catch块中。Function<BufferedReader, String> f = (BufferedReader b) -> {try {return b.readLine();}catch(IOException e) {throw new RuntimeException(e);}};
类型检查
test方法描述了一个函数描述符,它可以接受一个Apple,并返回一个boolean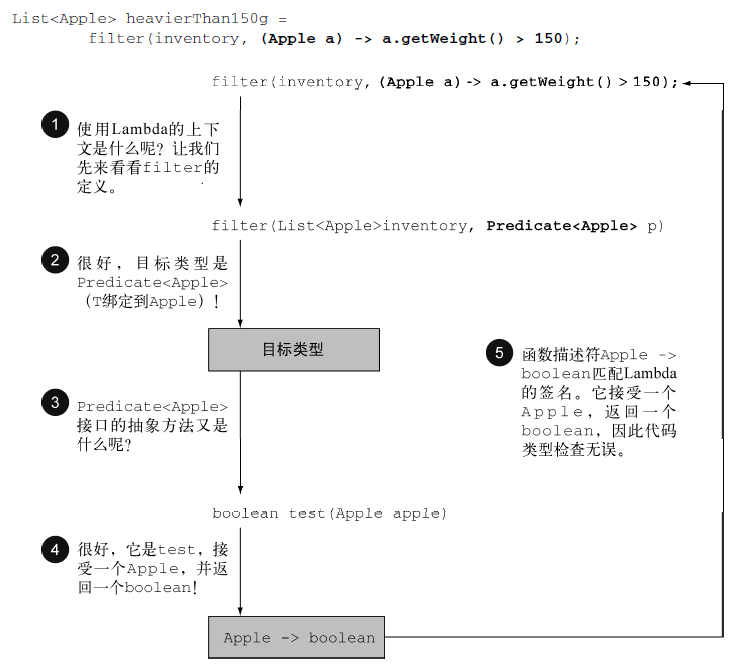
方法引用
构造函数引用
ClassName::new 适合Supplier的签名() -> ClassName
//构造函数引用指向默认的Apple()构造函数Supplier<Apple> c1 = Apple::new;Apple a1 = c1.get();Supplier<Apple> c1 = () -> new Apple();Apple a1 = c1.get();//指向Apple(Integer weight)的构造函数引用Function<Integer, Apple> c2 = Apple::new;Apple a2 = c2.apply(110);//指向Apple(String color,Integer weight)的构造函数引用BiFunction<String, Integer, Apple> c3 = Apple::new;Apple c3 = c3.apply("green", 110);
排序方法
//传递Comparator对象public class AppleComparator implements Comparator<Apple> {public int compare(Apple a1, Apple a2){return a1.getWeight().compareTo(a2.getWeight());}}inventory.sort(new AppleComparator());//使用匿名类inventory.sort(new Comparator<Apple>() {public int compare(Apple a1, Apple a2){return a1.getWeight().compareTo(a2.getWeight());}});// lambda表达式inventory.sort((Apple a1, Apple a2)-> a1.getWeight().compareTo(a2.getWeight()));inventory.sort((a1, a2) -> a1.getWeight().compareTo(a2.getWeight()));//Comparator具有一个叫作comparing的静态辅助方法,//它可以接受一个Function来提取Comparable键值,并生成一个Comparator对象Comparator<Apple> c = Comparator.comparing((Apple a) -> a.getWeight());import static java.util.Comparator.comparing;inventory.sort(comparing((a) -> a.getWeight()));//方法引用inventory.sort(comparing(Apple::getWeight));inventory.sort(comparing(Apple::getWeight).reversed() //反序.thenComparing(Apple::getCountry)); //排序先后Predicate<Apple> redAndHeavyAppleOrGreen = redApple.and(a -> a.getWeight() > 150) // and谓词.or(a -> "green".equals(a.getColor()) // or谓词.negate()); //非
Function接口
提供andThen和compose两个默认方法,返回Function的一个实例
Function<Integer, Integer> f = x -> x + 1;Function<Integer, Integer> g = x -> x * 2;Function<Integer, Integer> h = f.andThen(g); //g(f(x))int result = h.apply(1); // 4Function<Integer, Integer> h = f.compose(g); // f(g(x))int result = h.apply(1); // 3
静态辅助方法
// 方法引用增强可读性Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(groupingBy(Dish::getCaloricLevel));public class Dish{public CaloricLevel getCaloricLevel(){if (this.getCalories() <= 400) return CaloricLevel.DIET;else if (this.getCalories() <= 700) return CaloricLevel.NORMAL;else return CaloricLevel.FAT;}}// 静态辅助方法:inventory.sort(comparing(Apple::getWeight));int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
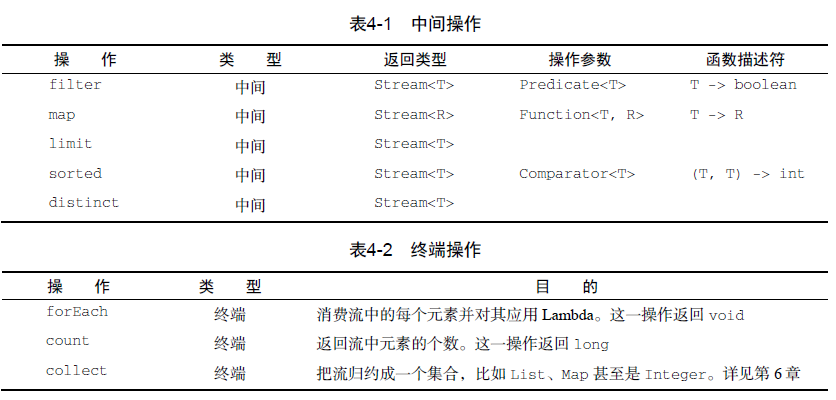
操作方法
分组 Collectors.groupingBy
// 分组统计Map<String, List<Student>> collect = stuList.stream().collect(Collectors.groupingBy(Student::getInstitution));// 自定义分组类别public enum CaloricLevel { DIET, NORMAL, FAT }Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(groupingBy(dish -> {if (dish.getCalories() <= 400) return CaloricLevel.DIET;else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;else return CaloricLevel.FAT;} ));//多级分组(多个类别)Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel = menu.stream().collect(groupingBy(Dish::getType, //默认类型条件groupingBy(dish -> { //自定义类型条件(做为外层分组的第二个参数)if (dish.getCalories() <= 400) return CaloricLevel.DIET;else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;else return CaloricLevel.FAT;})));// 子组收集数据//groupingBy工厂方法的第二个传递的参数会对分到同一组中的所有流元素执行进一步归约操作Map<Dish.Type, Long> typesCount = menu.stream().collect(groupingBy(Dish::getType, counting())); // 统计子组的数量,作为第二个参数Map<Dish.Type, Integer> totalCaloriesByType = menu.stream().collect(groupingBy(Dish::getType, summingInt(Dish::getCalories))); //对分组的所有流元素进一步进行归约操作Map<Dish.Type, Dish> mostCaloricByType = menu.stream().collect(groupingBy(Dish::getType, collectingAndThen( //collectingAndThen 对收集器的类型进行转换maxBy(comparingInt(Dish::getCalories)),Optional::get)));// 分组映射 mappingMap<Dish.Type, Set<CaloricLevel>> caloricLevelsByType = menu.stream().collect(groupingBy(Dish::getType, mapping( //第二个分组结果成为分组映射的值dish -> { if (dish.getCalories() <= 400) return CaloricLevel.DIET;else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;else return CaloricLevel.FAT; }, toSet() ))); //第一个参数分组,第二个参数结果对象收集// toSet()可以修改为toCollection(HashSet::new) 保证结果的类型// 多字段分组Function<Student, List<Object>> compositeKey = t -> Arrays.<Object>asList(t.age(), wlb.sex());Map<Object, List<Student>> map = stuList.stream().collect(Collectors.groupingBy(compositeKey, Collectors.toList()));// 分区(分区为true和false两组)Map<Boolean, List<Dish>> partitionedMenu = menu.stream().collect(partitioningBy(Dish::isVegetarian));List<Dish> vegetarianDishes = menu.stream().filter(Dish::isVegetarian).collect(toList());Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType =menu.stream().collect(partitioningBy(Dish::isVegetarian, groupingBy(Dish::getType)));// 分组并取最大Map<Integer,NurseVitalSignsRec>maxMap=list.parallelStream().filter(Objects::nonNull).collect(Collectors.groupingBy(NurseVitalSignsRec::getVisitId,Collectors.collectingAndThen(Collectors.reducing((t1,t2)->t1.getVisitId()>t2.getVisitId()?t1:t2),Optional::get)));
排序sorted
// 对map的排序Map<Date,List<NurseVitalSignsRec>> finalMap = newLinkedHashMap<>();vitalSigns.entrySet().stream().sorted(Map.Entry.comparingByKey()).limit(10).forEachOrdered(x->finalMap.put(x.getKey(),x.getValue()));vitalSigns.entrySet().stream().sorted(Map.Entry.<Date,List<NurseVitalSignsRec>>comparingByKey().reversed()).limit(10).forEachOrdered(x->finalMap.put(x.getKey(),x.getValue()));//reversed() 正序// limit(2) 取出前两条数据// 先倒序后正序List<Student> collect = list.stream().sorted(Comparator.comparing(Student::getNum).reversed()).limit(2)).collect(Collectors.toList());// 按属性降序排序list.stream().sorted(Comparator.comparing(Student::getNum, Comparator.reverseOrder()));// 按属性num降序,再按name属性降序list.stream().sorted(Comparator.comparing(Student::getNum).thenComparing(Student::getName));
取值/计算
// 最大/最小值Person maxAgePerson = personList.stream().max(Comparator.comparing(Person::getAge)).get();personList.stream().max((o1, o2) -> o1.compareTo(o2));double max = list.stream().mapToDouble(User::getHeight).max().getAsDouble();Optional<Integer> min = numbers.stream().reduce(Integer::min);//求和double sum = list.stream().mapToDouble(User::getHeight).sum(); //DoubleStream 推荐使用,避免拆箱int sum = numbers.stream().reduce(0, (a, b) -> a + b);int product = numbers.stream().reduce(1, (a, b) -> a * b);int sum = numbers.stream(). // 集合求和reduce(0, Integer::sum);Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b)); //无初始值,考虑到没有元素相加结果,返回Optional对象//平均数double average = list.stream().mapToDouble(User::getHeight).average().getAsDouble();//计数long howManyDishes = menu.stream().collect(Collectors.counting());long howManyDishes = menu.stream().count();int count = menu.stream().map(d -> 1).reduce(0, (a, b) -> a + b); //流中的每个元素都映射为1//归约/汇总收集transactions.stream().collect(Collectors.maxBy(Comparator.comparingInt(Transaction::getValue)));transactions.stream() // 遍历流时,把每一个对象映射为累加字段,并累加到累加器.collect(Collectors.summingInt(Transaction::getValue));menu.stream() // 平均值.collect(averagingInt(Dish::getCalories));IntSummaryStatistics menuStatistics = menu.stream().collect(summarizingInt(Dish::getCalories)); // 一次获取总和、平均值、最大值和最小值int totalCalories = menu.stream().collect(reducing(0, Dish::getCalories, (i, j) -> i + j));String shortMenu = menu.stream().map(Dish::getName).collect(reducing( (s1, s2) -> s1 + s2 )).get();Optional<Dish> mostCalorieDish = menu.stream() // 相加没有初始值,返回Optional对象.collect(reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2));int totalCalories = menu.stream() // 对象求和.collect(reducing(0, Dish::getCalories, Integer::sum)); // Optional<Integer>
过滤
// 去重list.stream().filter(i -> i % 2 == 0).distinct().forEach(System.out::println);//截断(limit)list.stream().filter(d -> d.getCalories() > 300).limit(3).collect(toList());//跳过元素menu.stream().filter(d -> d.getCalories() > 300).skip(2).collect(toList());// 数值范围:使用IntStream和LongStream的静态方法,range和rangeClosedIntStream evenNumbers = IntStream.rangeClosed(1, 100); // 1-100IntStream evenNumbers = IntStream.range(1, 100); // 1-99// 三元素是否符合条件// 1-100 三元数(a*a, b*b, a*a+b*b)是否符合勾股数Stream<double[]> pythagoreanTriples2 = IntStream.rangeClosed(1,100).boxed().flatMap(a -> IntStream.rangeClosed(a, 100).mapToObj(b -> new double[]{a, b, Math.sqrt(a*a + b*b)}).filter(t -> t[2] % 1 == 0));
映射集合
// 映射List<String> words = Arrays.asList("Java 8", "Lambdas", "In", "Action");// getName()返回的是String,map输出流的类型为Stream<String>,并且每个String元素可以使用String的方法/可以对元素操作List<Integer> wordLengths = words.stream().map(String::length).collect(toList());String[] arrayOfWords = {"Goodbye", "World"};Stream<String> streamOfwords = Arrays.stream(arrayOfWords); // 接收数组并转为字符流words.stream().map(word -> word.split("")) // Stream<String[]>.map(Arrays::stream) // 返回多个Stream<String>.distinct().collect(toList());words.stream().map(w -> w.split("")).flatMap(Arrays::stream) //将多个Stream<String>合并为一个Stream<String>.distinct().collect(Collectors.toList());// 连接字符串String shortMenu = menu.stream() //内部使用了StringBuilder来把生成的字符串逐个追加起来.map(Dish::getName).collect(joining());String shortMenu = menu.stream().collect(joining()); // 不对原流进行映射,通过toString()返回得到结果
查找
// 至少匹配一个元素(终端操作)menu.stream().anyMatch(Dish::isVegetarian) // 返回boolean//是否配置所有元素menu.stream().allMatch(d -> d.getCalories() < 1000);//没有任何元素匹配menu.stream().noneMatch(d -> d.getCalories() >= 1000);//返回流中任意元素,Optional<T>类(java.util.Optional)是一个容器类,代表一个值存在或不存在,若没有元素会出现nullPoint异常Optional<Dish> dish = menu.stream().filter(Dish::isVegetarian).findAny();//查找第一个元素: findFirst()
创建流
// 创建流// 值 Stream.ofStream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action");stream.map(String::toUpperCase).forEach(System.out::println);// 数组 Arrays.streamint[] numbers = {2, 3, 5, 7, 11, 13};int sum = Arrays.stream(numbers).sum(); //IntStream// 文件 NIO API Files.lines,它会返回一个由指定文件中的各行构成的字符串流longuniqueWords=0;try(Stream<String> lines = Files.lines(Paths.get("copy.txt"), Charset.defaultCharset())){uniqueWords=lines.flatMap(line->Arrays.stream(line.split(""))) // 每个流都是文件的一行,并拆分为单词,将每个流拆分的单词都合并为一个流.distinct().count();}catch(Exceptione){e.getStackTrace();}// 函数 创建无限流(没有固定大小的流) Stream.iterate和Stream.generateStream.iterate(0, n -> n + 2) //接受一个UnaryOperator<t>作为参数.limit(10).forEach(System.out::println);Stream.generate(Math::random).limit(5).forEach(System.out::println);IntStream ones = IntStream.generate(() -> 1); // 值都为1的无限流IntStream twos = IntStream.generate(new IntSupplier(){public int getAsInt(){ //显示传递对象return 2;}});
转换
// map转listmap.entrySet().stream().map(e -> new Person(e.getKey(),e.getValue())).collect(Collectors.toList());// list转mapMap<Integer, String> result = list.stream().collect(Collectors.toMap(Hosting::getId, Hosting::getName));Map<String, FormDict> map = list.stream().collect(Collectors.toMap(Dict::getCode, Dict->Dict));
流
Guava、Apache和lambdaj库提供了声明性操作集合的工具
数据处理的形式:
1、元素的操作
2、元素转换形式或提取信息
3、终端操作(返回结果)
// 流只能遍历一次Stream<String> s = title.stream();s.forEach(System.out::println);s.forEach(System.out::println); //异常,流已被操作或关闭
Optional提供可以显式地检查值是否存在或处理值不存在的情形的方法
- isPresent()将在Optional包含值的时候返回true, 否则返回false。
- ifPresent(Consumer
block)会在值存在的时候执行给定的代码块。 - T get()会在值存在时返回值,否则抛出一个NoSuchElement异常。
- T orElse(T other)会在值存在时返回值,否则返回一个默认值。
无状态:不存储任何状态
有状态:需要存储状态才能进行下一步操作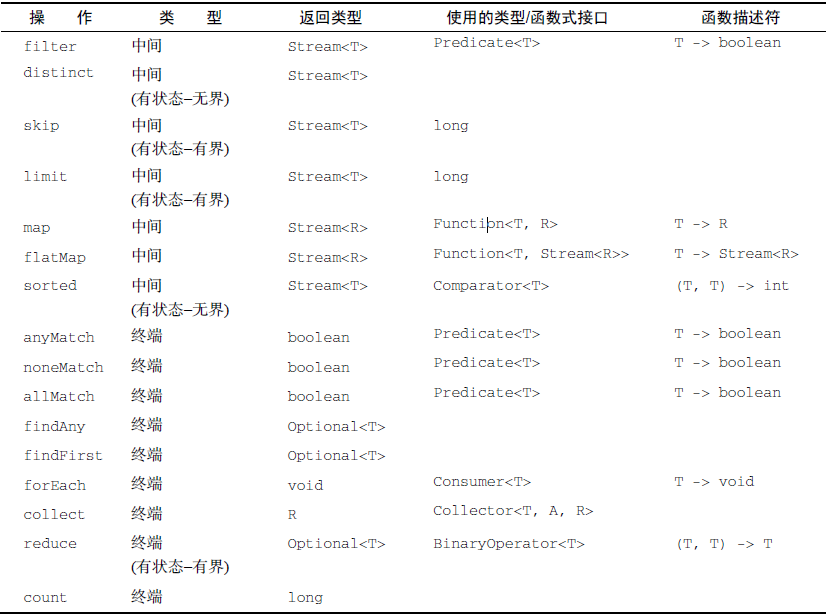
//数值流//流转换 mapToInt、mapToDouble和mapToLong 将Stream<Integer> 转换返回IntStream//流为空,默认返回为0Stream<Integer> stream = intStream.boxed(); // 可以流转换为非特化流//Optional原始类型特化OptionalInt、OptionalDouble和OptionalLong //会判断没有最大值(流为空)或最大值为0时,定义一个默认值
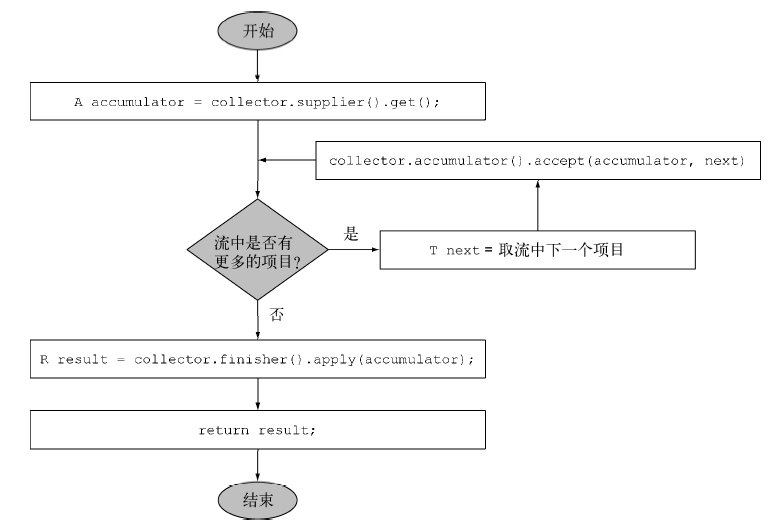
自定义收集器的实现
T是流中要收集的项目的泛型。
A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
R是收集操作得到的对象(通常但并不一定是集合)的类型。
public interface Collector<T, A, R> {Supplier<A> supplier();BiConsumer<A, T> accumulator();Function<A, R> finisher();BinaryOperator<A> combiner();Set<Characteristics> characteristics();}// 1. 建立新的结果容器:supplier方法,将累加器本身作为结果返回public Supplier<List<T>> supplier() {return () -> new ArrayList<T>();}public Supplier<List<T>> supplier() {return ArrayList::new;}// 2. 将元素添加到结果容器:accumulator方法,返回执行归约操作的函数public BiConsumer<List<T>, T> accumulator() {return List::add;}// 3. 对结果容器应用最终转换:finisher方法,返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果public Function<List<T>, List<T>> finisher() {return Function.identity();}// 4. 合并两个结果容器:combiner方法,各个子部分归约所得的累加器要如何合并public BinaryOperator<List<T>> combiner() {return (list1, list2) -> {list1.addAll(list2);return list1;}}//5. characteristics方法,定义了收集器的行为——尤其是关于流是否可以并行归约UNORDEREDCONCURRENTIDENTITY_FINISHpublic Set<Characteristics> characteristics() {return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, CONCURRENT));}
同步/异步
同步API:阻塞式调用
调用方需要等待被调用方继续运行,当前任务和调用任务是同一线程
异步API:非阻塞调用
调用方的计算任务和调用任务是异步操作,计算任务的线程会将结果返回给调用方(回调函数、再次调用等待计算任务完成的方法)
public double getPrice(String product) {return calculatePrice(product);}private double calculatePrice(String product) {delay();return random.nextDouble() * product.charAt(0) + product.charAt(1);}public Future<Double> getPriceAsync(String product) {CompletableFuture<Double> futurePrice = new CompletableFuture<>();new Thread( () -> { // 另一个线程异步方式执行try {double price = calculatePrice(product);//长时间计算的任务并得出结果futurePrice.complete(price);// 设置返回值} catch (Exception ex) {futurePrice.completeExceptionally(ex); // 抛出异常}}).start();return futurePrice;}Future<Double> futurePrice = shop.getPriceAsync("my favorite product");double price = futurePrice.get(); // 需要依赖到价格的计算时,调用Future的get方法,要么直接获取返回值,要么等待异步任务完成。// 使用工厂方法supplyAsync创建CompletableFuture对象public Future<Double> getPriceAsync(String product) {return CompletableFuture.supplyAsync(() -> calculatePrice(product));}
CompletableFuture实现
public List<String> findPrices(String product) {List<CompletableFuture<String>> priceFutures = shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " + shop.getPrice(product))).collect(Collectors.toList());return priceFutures.stream().map(CompletableFuture::join) // 等待所有异步操作结束.collect(toList());}
高阶函数
接受函数作为参数的方法或者返回一个函数的方法
调试:使用peek() 输出流中每一步的操作结果
默认方法:
1、在接口内声明静态方法
2、默认方法:让类可以自动地继承接口的一个默认实现。
接口和工具辅助类的同时定义:
Collections就是处理Collection对象的辅助类
可以将工具类中与接口实例协作的静态方法定义在接口内
抽象接口和抽象类的区别:
1、一个类只能继承一个抽象类,但是一个类可以实现多个接口。
2、一个抽象类可以通过实例变量(字段)保存一个通用状态,而接口是不能有实例变量的。
默认方法解决的问题
可选方法:不需要实现无用的方法,直接使用默认实现
行为的多继承:可以实现多个有默认方法的接口
自定义默认方法,实现java中的多继承
如在Collction添加removeIf,ArrayList、TreeSet、LinkedList以及其他集合类型都会使用removeIf方法的默认实现
default boolean removeIf(Predicate<? super E> filter) {boolean removed = false;Iterator<E> each = iterator();while(each.hasNext()) {if(filter.test(each.next())) {each.remove();removed = true;}}return removed;}
API不同类型的兼容性:
- 二进制级的兼容:表示现有的二进制执行文件能无缝持续链接(包括验证、准备和解析)和运行
向接口添加一个方法,新的方法不会调用,已经实现的方法可以调用,不会报错
- 源代码级的兼容:表示引入变化之后,现有的程序依然能成功编译通过
向接口添加默认方法
- 函数行为的兼容:表示变更发生之后,程序接受同样的输入能得到同样的结果
源码
// 默认方法,使用default关键子表示defaultvoidsort(Comparator<? super E> c) {Collections.sort(this, c);}Optional<T> NullPointer // 异常处理
(结构)模式匹配
行为参数化:让方法接受多种行为(或战略)作为参数,并在内部使用,来完成不同的行为。
根据传递参数的类型,可以是类对象、方法、代码块参数化
还可以是匿名类
调试

若有收获,就点个赞吧
0 人点赞
