1、索引基础
1.1 索引是什么
索引( Index)是帮助mysql高效获取数 据的数据结构。
1.2 优势&劣势
优势:类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本; 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势:实际上素引也是一张表,该表保存了主键与素引字段,并指向实 体表的记录,所以索引列也是要占用空间的,虽然索引大大提高了査询速度,同时却会降低更新表的速度, 如对表进行 INSERT、 UPDATE和 DELETE。 因为更新表时, MYSQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变 化后的素引信息。
优点:
提高查询效率
提高聚合函数查询效率
提高排序查询效率
使用覆盖索引避免回表
1.3 B树索引和B+树索引
参考:https://blog.csdn.net/weibozhouchao/article/details/103190992
https://www.cnblogs.com/xueqiuqiu/articles/8779029.html
B树: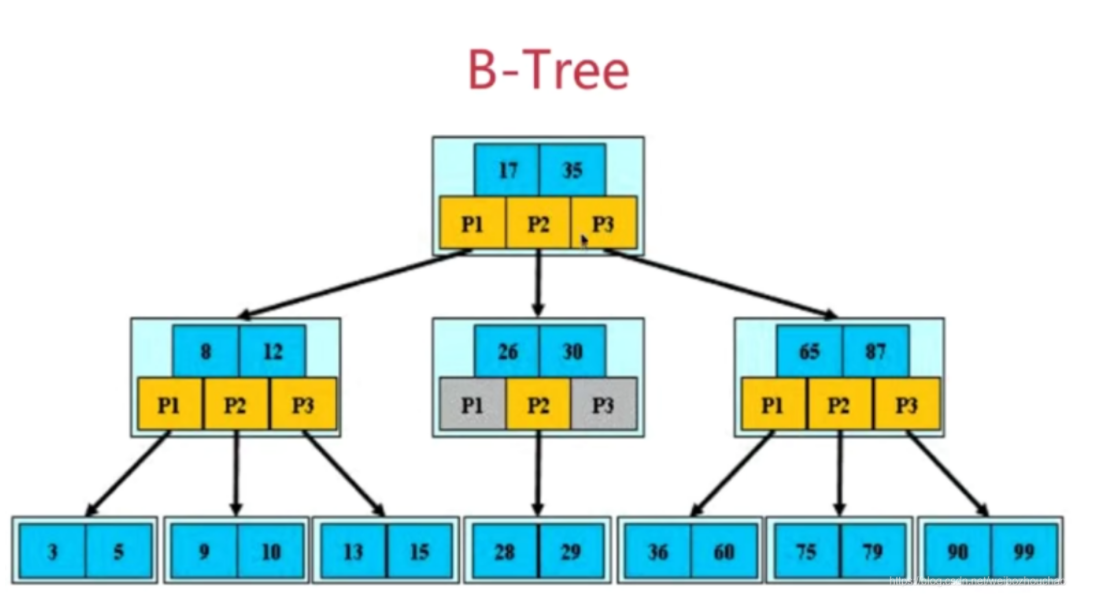
特点:
- 定义任意非叶子结点最多只有M个儿子,且M>2;
- 所有叶子节点都位于同一层
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 每进行一次磁盘IO,将节点加载到内存,然后将内存中的数据进行比较(比较时间可忽略,因为内存速度较快),最后找下一个节点,IO次数就是树的高度,树的宽度取决于磁盘页的大小;
B+树:
特点:
- 有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
- 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
- 通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
- 同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
█ b+树相比于b树的查询优势:
- b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
- b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
- 对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历
1.4 索引的分类
从物理结构区分为聚集索引和非聚集索引,参考:https://www.cnblogs.com/aspnethot/articles/1504082.html
聚集索引(也称聚类索引、簇集索引)确定表中数据的物理顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样,正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
1)聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。
2)如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。
3)当索引值唯一时,使用聚集索引查找特定的行也很有效率。
聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
从应用上分 ,分为 主键索引、唯一索引、全文索引和组合索引。
Mysql中索引主要分为以下几类:
1)主键索引(PRIMARY KEY):主键索引一般都是在创建表的时候进行指定,「一个表只有一个主键索引」,特点是「唯一、非空」。MYSQL常用就是 自增主键;
2)唯一索引(UNIQUE):唯一索引具有的特点就是唯一性,即指定列不能出现重复数据;
3)前缀索引(prefix INDEX):前缀索引建立的基础就指定列数据有很多的共同前缀;
4)联合索引:联合索引又称符合索引,是在表中两个或者两个列以上的基础上创建索引;(a,b,c) a,ab,abc
5)覆盖索引:当一个索引包含(或者说是覆盖)需要查询的所有字段的值时,我们称之为覆盖索引;
1.5 索引下推
MySQL的大概结构包含 连接层 -> 服务层 -> 引擎层 -> 文件系统层
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
没有ICP :存储引擎读取索引记录,根据索引中的主键值,回表定位并读取完整的行记录,存储引擎把记录交给Server层去检测该记录是否满足WHERE条件。
有ICP: 存储引擎读取索引记录,判断条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录,条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表),存储引擎把记录交给层,层检测该记录是否满足条件的其余部分。
作用:索引下推的目的是为了减少回表次数,也就是要减少IO操作。
参考:https://baijiahao.baidu.com/s?id=1716515482593299829&wfr=spider&for=pc
2、性能分析
2.1 MySQL 常见性能瓶颈
- CPU
- SQL中对大量数据进行比较、关联、排序、分组,最大的压力在于 比较
- IO
- 实际内存满足不了缓存数据或排序等需要,导致产生大量物理IO,查询执行效率低,扫描过多数据行。
锁
EXPLAIN关键字可以模拟优化器执行SQL查询语句
- 作用a
- 表的读取顺序 ID
- 哪些索引可以使用
- 数据读取操作的操作类型
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
- 执行计划包含的信息

- id
- id相同,执行顺序由上至下
- id值越大,优先级越高,越先执行
- select_type

- table
- 显示这一行的数据是关于哪张表的
- type
- 显示的是访问类型,是较为重要的一个指标
- 结果值从最好到最 坏依次是:
- system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range(尽量保证) > index > ALL
- system
- 表只有一行记录(等于系统表),这是cont类型的特列,平时不会出现
- const
- primary key或者 unique素引
- 索引一次就找到,MYSQL就能将该查询转换为一个常量
- eq_ref
- 唯一性素引扫描,对于每个索引键,表中只有一条记录与之匹配。
- 常见于主键或唯一索引扫描
- ref
- 非唯一性素引扫描,返回匹配某个单独值的所有行,可能会找到多个符合条件的行
- range
- 只检索给定范围的行,使用一个索引来选择行。
- key列显示使用了哪个素引
- 一般就是在你的 where语句中出现了 between、<、>、in等的查询
- 只需要开始于索引的某一点,而结束语另一点,不用扫描全部素引
- index
- 只遍历索引树,通常比ALL快
- 索引文件週常比数据文件小
- 读取位置不一样
- 虽然all和 Index都是读全表,但 index是从索引中读取的, 而all是从硬盘中读的
- 只遍历索引树,通常比ALL快
- all
- 遍历全表以找到匹配的行
- possible_keys
- 显示可能应用在这张表中的素引,一个或多个
- key
- 实际使用的素引。如果为NULL,则没有使用索引
- 查询中若使用了覆盖索引,则该索引和查询的 select字段重叠
- key_len
- 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
- ref
- 显示索引的哪一列被使用了,如果可能的话,是一个常数。
- 哪些列或常量被用于查找索引列上的值
- rows
- 显示MySQL认为它执行查询时必须检查的行数,越少越好
- Extra


- 尽可能减少Join语句的NextedLoop的循环总次数:永远用小结果集驱动大结果集
- 优先优化NestedLoop的内层循环
- 保证Join语句中被驱动表上Join条件的字段已经被索引
- 当无法保证被驱动表的Join条件字段被索引且内存充足的前提下,不要太吝啬JoinBuffer的设置
order by
- ORDER BY子句,尽量使用 Index方式排序,避免使用 File Sort,方式排序
- ORDER BY语句使用索引最左前列
- where子句中如果出现引的范围查询(即explain中出现 range) 会导致 order by索引失效


group by
- 先排序后进行分组,遵照索引建的最佳左前缀
- 当无法使用索引列
- 增大 max_length_for_sort_data参数的设置
- 增 大 sort_buffer_size参数的设置
- where高于having,能写在 where限定的条件就不要去 having限定了。
- 尽量不要使用 distinct,关键字去重:优化
- select distinct kcdz form t_mall_sku where id in( 3,4,5,6,8 ) 使用 distinct 关键字去重消耗性能
- select kcdz form t_mall_sku where id in( 3,4,5,6,8 ) group by kcdz 能够利用到索引
2.3.1 创建索引的策略

2.4 案例分析

mysql 会开启查询优化器,自动调整sql优化,尽量用到顺序和索引顺序一致
范围
c3 的作用在于排序而不是查找
索引顺序和排序顺序不一致,中间梯子断了




group by 分组之前必排序
3、查询分析
3.1 慢查询日志
- MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记 录在MySQL中响应时间超过阀值的语句,具体指运行时间超 过long_query_time值的SQL,则会被记录到慢查询日志中
- long_query_time的默认值为10
- 默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。
- SHOW VARIABLES LIKE ‘%slow_query_log%’;
- MySQL重启后则会失效
- set global slow_query_log=1
- 永久生效
- 修改my.cnf文件,然后重启MySQL服务器。 ```bash slow_query_log =1 slow_query_log_file=/var/lib/mysql/cqm-slow.log //如果没有指定参数slow_query_log_file,系统默认会给一个缺省的文件host_name-slow.log
査看当前多少秒算慢
SHOW VARIABLES LIKE ‘long_query_time%’;
设置慢的阙值时间
set global long_query_time=1
修改为阙值到1秒钟的就是慢sql
修改后发现long_query_time并没有改变,需要重新连接或新开一个会话才能看到修改值。
依据cqm-slow.log跟踪日志信息
查询当前系统中有多少条慢查询记录
show global status like ‘%Slow_queries%’;
- 当然,如果不是调优需要的话,一般不建议启动该参数,因为开 启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持 将日志记录写入文件。- 日志分析工具```bash工作常用参考得到返回记录集最多的10个SQLmysqldumpslow -s r -t 10 /var/lib/mysql/cqm-slow.log得到访问次数最多的10个SQLmysqldumpslow -s c -t 10 /var/lib/mysql/cqm-slow.log得到按照时间排序的前10条里面含有左连接的查询语句mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/cqm-slow.log另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况mysqldumpslow -s r -t 10 /var/lib/mysql/cqm-slow.log | more

3.2 show profile
- 是什么:是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量;
- 官网:http://dev.mysql.com/doc/refman/5.5/en/show-profile.html
- 默认情况下,参数处于关闭状态,并保存最近15次的运行结果
- 分析步骤
- 看看当前的mysql版本是否支持
- Show variables like ‘profiling’; # 默认是关闭,使用前需要开启
- set profiling=1; # 开启
- 运行SQL
- 看看当前的mysql版本是否支持






若有收获,就点个赞吧
0 人点赞
