1、python 参数带独立星号(*)
星号参数的作用:确保参数只能以关键字形式来指定,调用时必须以带参数的名字调用
2、对象和变量
创建变量
- 创建一个对象,并分配一块内存,存储值3
- 将对象和变量,通过指针连接,从变量到对象的连接称为引用(变量引用对象)
- 无需声明变量类型,变量类型在运行过程中根据对象类型自动决定,变量没有类型,类型是属于对象的
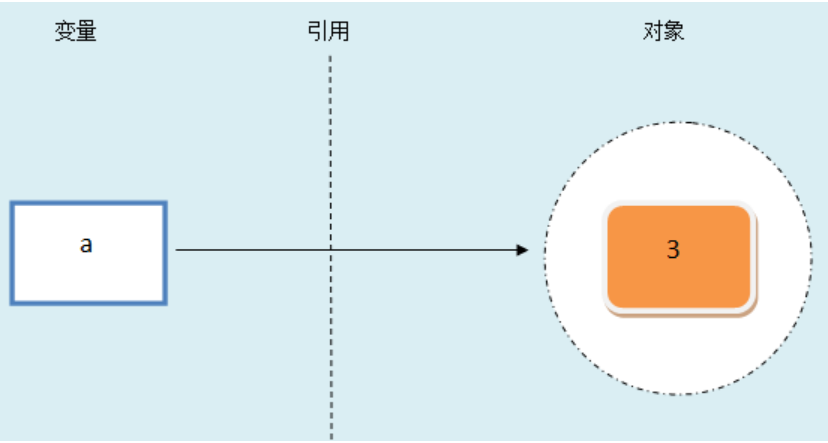
2.1 对象的结构
- 每个对象包含了类型标识符(标记了对象的类型,指向int的对象的指针)、引用计数器

2.2 垃圾回收
a = 1a = "span"#1、当变量a重新赋值字符串span时,它的的上一个引用对象1立马被回收,对象的空间立马放入自由内存空间池,# 等待后来的对象使用# 2、任意使用对象而不考虑释放内存空间# 3、对象内部有一个计数器,计数器记录当前对象引用的数目,一旦计数器为0,该对象的内存空间自动回收,#这种自动回收垃圾的机制称为垃圾回收机制
3、浅拷贝和深拷贝
浅拷贝
- 拷贝父对象,不会拷贝对象的内部的子对象。
- 所谓的浅拷贝就是拷贝指向对象的指针,意思就是说:拷贝出来的目标对象的指针和源对象的指针指向的内存空间是同一块空间.
浅拷贝只是一种简单的拷贝,让几个对象公用一个内存,然而当内存销毁的时候,指向这个内存空间的所有指针需要重新定义,不然会造成野指针错误
a = {1: [1,2,3]}b = a.copy()>>> a, b({1: [1, 2, 3]}, {1: [1, 2, 3]})>>> a[1].append(4)>>> a, b({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。

深拷贝
- copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
所谓的深拷贝指拷贝对象的具体内容,其内容地址是自助分配的,拷贝结束之后,内存中的值是完全相同的,但是内存地址是不一样的,两个对象之间相互不影响,也互不干涉.
>>>import copy>>> c = copy.deepcopy(a)>>> a, c({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})>>> a[1].append(5)>>> a, c({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
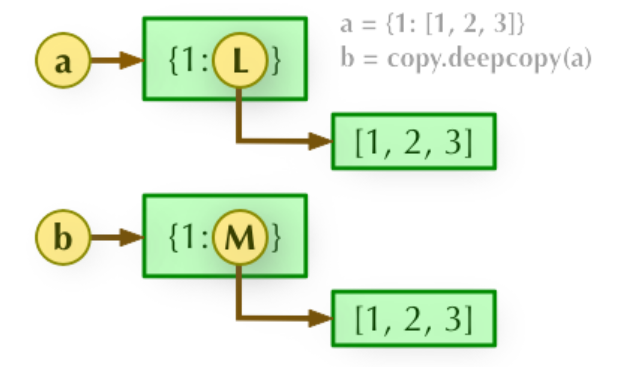
对象赋值
返回值
1> Python 函数使用 return 语句返回 “返回值”
2> 所有函数都有返回值,如果没有 return 语句,隐式调用 return None
3> return 语句并不一定是函数的语句块的最后一条语句
4> 一个函数可以存在多个 return 语句,但是只有一条可以被执行。如果没有一条 return 语句被执行到,隐式调用 return None
5> 如果有必要,可以显示调用return None,可以简写为return
6> 如果函数执行了 return 语句,函数就会返回,当前被执行的 return 语句之后的其它语句就不会被执行了
7> 返回值的作用:结束函数调用、返回 “返回值”
8>函数不能一次返回多个值,return 1, 3, 5 看似返回多个值,隐式的被 python 封装成了一个元组作用域
- 每一个函数都会开辟一个作用域
- 作用域分类
- 全局作用域:
在整个程序运行环境中都可见
全局作用域中的变量称为全局变量 - 局部作用域:
在函数、类等内部可见
局部作用域中的变量称为局部变量,其使用范围不超过其所在局部作用域 - 外层变量在内部作用域可见
- 内层作用域中,如果定义了和外层相同的变量,相当于在当前函数作用域中重新定义了一个新的变量,这个内层变量并不能覆盖掉外部作用域中的变量。
- 外层作用域中,定义变量x,函数内部可以使用变量x,但不能重新定义变量x,只要有=,=左边的变量都是局部变量
- 解决使用global,全局变量一般情况不推荐修改
- 因为函数的目的就是为了封装,尽量与外界隔离
- nonlocal 语句:将变量标记为不在本地作用域定义,而是在上级的某一级局部作用域中定义,但不能是全局作用域中。
- 全局作用域:
- 闭包
```python
python 2 实现闭包
def counter(): c = [0] def inc(): c[0] += 1 # 是赋值即定义嘛?不是!是修改值 return c[0] return inc # 返回标识符,即函数对象

m = counter() m() # 调用函数 inc(),但是 c 消亡了嘛?没有,内层函数没有消亡,c 不消亡(闭包) m() m() print(m())
#
def counter(): c = 0 def inc(): nonlocal c # 非当前函数的本地变量,当前函数之外的任意层函数的变量,绝非 global c += 1 # 是闭包吗?是! return c return inc
m = counter() m() m() m() print(m())
<a name="A5dLH"></a>#### 4.1 函数默认值的作用域```pythondef foo(x=1): # 不可变对象x += 1print(x)foo() # 2foo() # 2def bar(x=[]): # x = [],引用类型x.append(1) # [1]print(x)bar() # [1]bar() # [1, 1]################################################为什么上列 bar 函数第二次调用打印的是 [1, 1]?因为函数也是对象,每个函数定义被执行后,就生成了一个函数对象和函数名这个标识符关联。python 把函数的默认值放在了函数对象的属性中,这个属性就伴随着这个函数对象的整个生命周期。def add(a=[]):a += [5]print(add.__defaults__)# ([],)add()print(add.__defaults__)# ([5],)add()add()print(add.__defaults__) # ([5, 5, 5],)def y(a=[]):a += [5]print(y.__defaults__)# ([],)y()print(y.__defaults__)# ([5],)######################################################### 奇怪def foo(x, m=123, *, n='abc', t=[1,2]):m=456 # 不可变对象n='def'# 不可变对象t.append(12) # 可变对象#t[:].append(12) # t[:],全新复制一个列表,避免引用计数print(x, m, n, t) # ang 456 def [1, 2, 12]print(foo.__defaults__, foo.__kwdefaults__) #(123,) {'n': 'abc', 't': [1, 2]}foo('yang')print(foo.__defaults__, foo.__kwdefaults__) #(123,) {'n': 'abc', 't': [1, 2, 12]}######################################################### 奇怪def foo(x, m=123, n='abc'):m=456n='def'print(x)print(foo.__defaults__) # (123, 'abc')foo('yang')print(foo.__defaults__) # (123, 'abc')########################################################## 奇怪# 查看 foo.__defaults__ 属性,它是个元组def bar(x=[]):x.append(1)print(x)print(bar.__defaults__)bar() # [1]print(bar.__defaults__)bar() # [1, 1]print(bar.__defaults__)# 执行结果:([],)[1]([1],)[1, 1]([1, 1],) # 元组不变,记录的是地址,引用类型变化
4.2 函数的销毁
- 可以使用del语句删除函数,使其引用计数减 1。
- 可以使用同名标识符覆盖原有定义,本质上也是使其引用计数减 1。
- Python程序结束时,所有对象销毁。
- 函数也是对象,也不例外,是否销毁,还是看引用计数是否减为 0。
4.3 列表 +=、+
```python列表的 + 和 += 的区别:
+ 表示两个列表合并并返回一个全新的列表。
+= 表示,就地修改前一个列表,在其后追加后一个列表,就是 extend 方法。
l1 = [1, 2] l2 = [3, 4] l3 = l1 + l2 print(id(l1), id(l2), id(l3)) l3 += l2 # 就地修改 print(id(l3))
执行结果: 2279905055304 2279905055816 2279906334216 2279906334216 ```

若有收获,就点个赞吧
0 人点赞
