为了更好地满足各种不同的业务场景,StarRocks支持多种数据模型,StarRocks中存储的数据需要按照特定的模型进行组织(参考表设计章节)。数据导入功能是将原始数据按照相应的模型进行清洗转换并加载到StarRocks中,方便查询使用。
StarRocks提供了多种导入方式,用户可以根据数据量大小、导入频率等要求选择最适合自己业务需求的导入方式。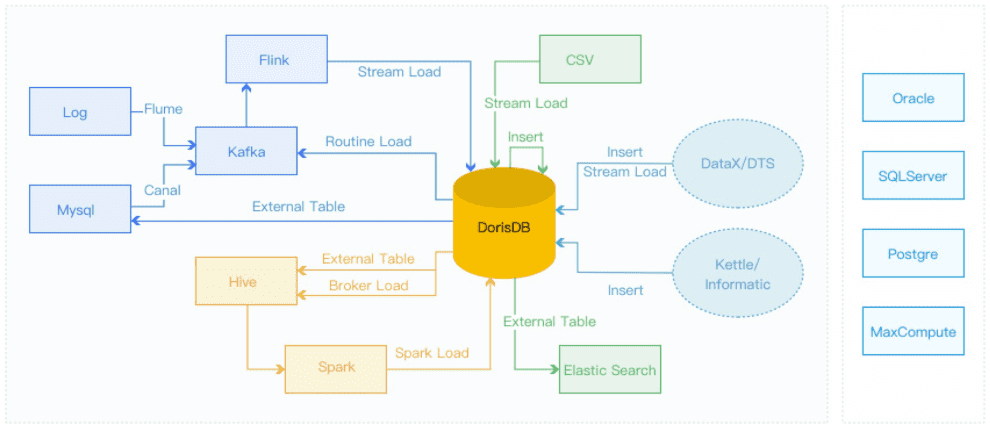
离线数据导入,如果数据源是Hive/HDFS,推荐采用Broker Load导入, 如果数据表很多导入比较麻烦可以考虑使用Hive外表直连查询,性能会比Broker load导入效果差,但是可以避免数据搬迁,如果单表的数据量特别大,或者需要做全局数据字典来精确去重可以考虑Spark Load导入。
实时数据导入,日志数据和业务数据库的binlog同步到Kafka以后,优先推荐通过Routine load 导入StarRocks,如果导入过程中有复杂的多表关联和ETL预处理可以使用Flink处理以后用stream load写入StarRocks,我们有标准的Flink-connector可以方便Flink任务使用.
程序写入StarRocks,推荐使用Stream Load,可以参考例子中有java python shell的demo。
文本文件导入推荐使用 Stream load
Mysql数据导入,推荐使用Mysql外表,insert into new_table select * from external_table 的方式导入
其他数据源导入,推荐使用DataX导入,我们提供了DataX-starrocks-writer
StarRocks内部导入,可以在StarRocks内部使用insert into tablename select的方式导入,可以跟外部调度器配合实现简单的ETL处理
基本原理
导入执行流程: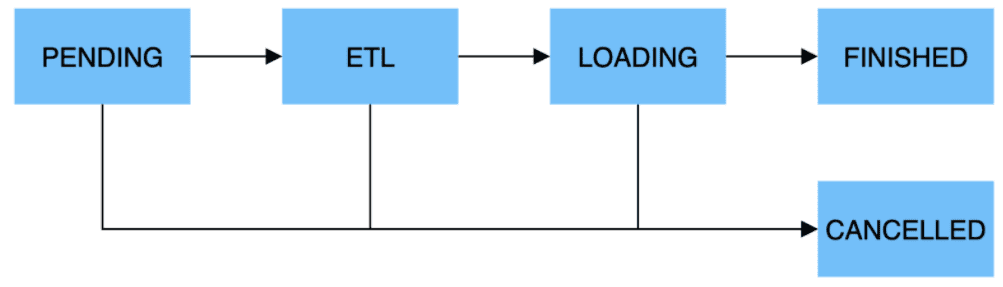
一个导入作业主要分为5个阶段:
1.PENDING
非必须。该阶段是指用户提交导入作业后,等待FE调度执行。
Broker Load和Spark Load包括该步骤。
2.ETL
非必须。该阶段执行数据的预处理,包括清洗、分区、排序、聚合等。
Spark Load包括该步骤,它使用外部计算资源Spark完成ETL。
3.LOADING
该阶段先对数据进行清洗和转换,然后将数据发送给BE处理。当数据全部导入后,进入等待生效过程,此时导入作业状态依旧是LOADING。
4.FINISHED
在导入作业涉及的所有数据均生效后,作业的状态变成 FINISHED,FINISHED后导入的数据均可查询。FINISHED是导入作业的最终状态。
5.CANCELLED
在导入作业状态变为FINISHED之前,作业随时可能被取消并进入CANCELLED状态,如用户手动取消或导入出现错误等。CANCELLED也是导入作业的一种最终状态。
数据导入格式:
- 整型类(TINYINT,SMALLINT,INT,BIGINT,LARGEINT):1, 1000, 1234
- 浮点类(FLOAT,DOUBLE,DECIMAL):1.1, 0.23, .356
- 日期类(DATE,DATETIME):2017-10-03, 2017-06-13 12:34:03
- 字符串类(CHAR,VARCHAR):I am a student, a
- NULL值:\N
导入方式
导入方式介绍
1.Broker Load
Broker Load 通过 Broker 进程访问并读取外部数据源,然后采用 MySQL 协议向 StarRocks 创建导入作业。提交的作业将异步执行,用户可通过 SHOW LOAD 命令查看导入结果。
Broker Load适用于源数据在Broker进程可访问的存储系统(如HDFS)中,数据量为几十GB到上百GB。
2.Spark Load
Spark Load 通过外部的 Spark 资源实现对导入数据的预处理,提高 StarRocks 大数据量的导入性能并且节省 StarRocks 集群的计算资源。Spark load 是一种异步导入方式,需要通过 MySQL 协议创建导入作业,并通过 SHOW LOAD 查看导入结果。
Spark Load适用于初次迁移大数据量(可到TB级别)到StarRocks的场景,且源数据在Spark可访问的存储系统(如HDFS)中。
3.Stream Load
Stream Load是一种同步执行的导入方式。用户通过 HTTP 协议发送请求将本地文件或数据流导入到 StarRocks中,并等待系统返回导入的结果状态,从而判断导入是否成功。
Stream Load适用于导入本地文件,或通过程序导入数据流中的数据。
4.Routine Load
Routine Load(例行导入)提供了一种自动从指定数据源进行数据导入的功能。用户通过 MySQL 协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如 Kafka)中读取数据并导入到 StarRocks 中。
5.Insert Into
类似 MySQL 中的 Insert 语句,StarRocks 提供 INSERT INTO tbl SELECT …; 的方式从 StarRocks 的表中读取数据并导入到另一张表。或者通过 INSERT INTO tbl VALUES(…); 插入单条数据。
| 导入方式 | 同步/异步 | 数据量 | 协议 | 数据类型 | 其它 |
|---|---|---|---|---|---|
| Broker Load | 异步执行 | 几十GB到上百GB | MySQL 协议 | CSV,Parquet 和 ORC | SHOW LOAD 命令查看导入结果 |
| Spark Load | 异步导入 | 可到TB级别 | MySQL 协议 | CSV | SHOW LOAD 命令查看导入结果 |
| Stream Load | 同步执行 | HTTP 协议 | CSV | ||
| Routine Load | MySQL 协议 | CSV | |||
| Insert Into | CSV |

若有收获,就点个赞吧
0 人点赞
