声明: 这个回答只满足一般前端工作者,但不适合语言实现领域的『专家』
谢邀: 我之前也造过一个轮子,GitHub - leeluolee/mcss: writing modular css witch mcss ,如果你抛开对 star 的成见,忽略它貌似已经被 “弃坑” 的现状,你其实会发现语言能力上比 Less 要强一些,而且它确实在公司中数十个产品线中稳定使用了 3 年以上 (不乏考拉、易信等较大的产品线),所以算是一个成熟的可参考对象,绝非玩具。
LESS 或者 Jade 这类 css 和 html 的预处理语言,都可以被归类为为 DSL, 即
DSL(Domain Specific Language) , 字面翻译为领域受限的编程语言. 它与我们日常使用的一般编程语言不同,是被设计用来解决 特定问题域 的 语言工具 ,DSL 一般分为内部 DSL 与外部 DSL。这里我们的关注点是外部 DSL
(关于内部 DSL 和外部 DSL 就不细讲了,不过我在公司内有一次比较全面的沙龙分享,有兴趣的可以问我要 PPT)
我先来介绍下,mcss 这种 compile to css 的 DSL 的实现流水线 (所有的 compile to js, compile to xx 的流水线都大同小异).
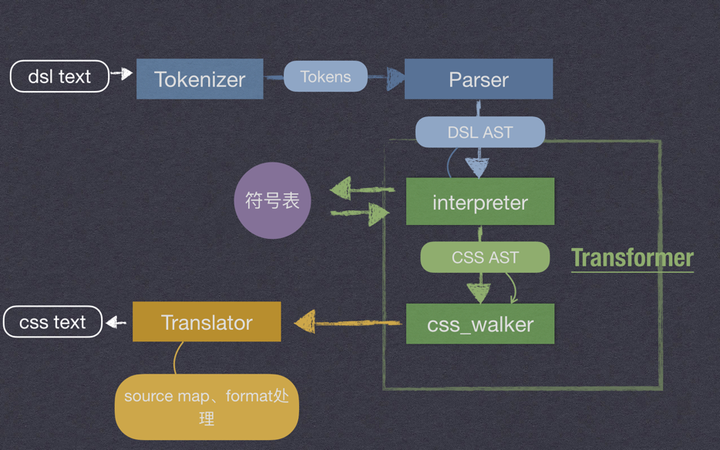
**
- 词法解析 Tokenizer or Lexer**
作用相当于自然语言的分词,比如 total + number ,total 和 number 此时都会输出类似 Identifier 这样词法元素,并且一些无效的元素比如空格回车缩进 (这个取决于语言设计,有些语言是有意义的) 会被剔除。它输出的是扁平化结构, 一般是一个 token 队列结构, 或是一个 token Stream 供 Parser 使用
2. 语法解析 Parser: 即将词语根据 Grammer 组装成语义结构,
通常是输出是一个树形结构,实现上会涉及大量的递归操作。基本常见解决思路有 LL 和 LR 两种,LR 由于与我们思维的模式有些出入,很难人工书写,所以一般都是靠代码生成来实现。这里我们就更一般的 LL 做下简单描述。 常见有 LL(1), LL(2) , LL(n) 等分别,即你向前看多少个『词』(n 即代表要查看不定数量),可以确定他的语法的节点类型,以 SASS 为例,如 function 定义
xx-mixin
当我们碰到 时候已经可以判断这会是个 type 为 function 的 At-rule 的定义, 所以 LL(1) 即向前看一位的 Parser 就能解决这个场景
mcss 有点特殊,是个 LL(n) 的解释器,比如在设计中,函数在 mcss 是 First-class 的,可以被返回或传入函数,并保持作用域信息,所以它是一种特殊的值,定义我设计与一般赋值一样。
$size = ($width, $height) {// ...}
这里当你不读取到{ 是无法判断 = 后面是函数定义 还是 普通 css 中的 compound values . 众所周知参数列表可能无限长,所以必须是 LL(n) 的 Parser 才能够解答。
虽然带来一定的性能影响和实现成本 (比如回溯、中断),但是带来语言语法上的一些灵活性。
3. 一次或多次的 Transformer:
在最终输出前,我们需要对现有的 AST 做适当调整以满足输出要求。
在 mcss 有 Interpreter, 因为内部需要将所有 css 之外的语法元素,比如 Function, Expression 之类的全部解释一遍,输出纯粹的 CSS AST. 一般的 compile to xx 都不需要 interpreter 这一步,因为像 JS 这种目标语言本身就具有完整的语言能力,但 CSS 是个特例,我们创建 css 预处理语言就是要增加它的语言能力。在经过这次 Interpreter 之后,就变成了纯粹的代表 CSS 语法元素的 AST 结构,这步之后,我们会在 Interpreter 上升阶段将其传给一个 css_walker 的流程提供给插件使用,这样用户只需要关注 css 相关的语法元素即可实现插件扩展。 和现在 postcss 暴露给开发者的 pugin API 类似。使用这种 walker 可以帮你实现很多有用的功能,比如 80 行实现一个 csscss 冗余检测工具 (80line implement more powerful csscss (https://github.com/zmoazeni/csscss) version · Issue #3 · leeluolee/mcss · GitHub) . 图片 link 替换 base64 等等功能。
- Translator 翻译器:
输出最终的 CSS 文本,这里输入的 AST, 除了原来的语言中除了语法节点原有的信息,其实还包含有 position 这种位置信息, 在输出时,你同时处理输入和输出的两个位置信息, 就可以实现了source-map的功能,不想处理 map 编码可以直接使用 mozilla/source-map ,你只需要传入输入的行列和输出行列即可。
流程介绍完毕,那么题主,我假设题主是一个没有任何语言实现基础的前端开发者,那么我觉得优先级应该是:
- 设计一门外部 DSL,你首先需要是目标语言的 “大师” ,这样你设计的 DSL 才可能是合理的,是符合问题域的。
就我个人而言,我目前至少通读过 CSS Syntax 和 html5 Syntax 以及 ES5 的完整规范,这用来支持我完成那些开源或非开源的 DSL 工具。 还有一点就是,对于 JS, 你应该把 SpiderMonkey 的 Parser API - Mozilla 通读几次是基本的,特别是 AST 节点的 Interface 定义,这是市面上几乎所有 JS parser 和 code generator 的基石 。
- 合格『够用的』编译原理前端知识:
诚如 所言,一般我们前端领域所碰到的问题,只需要语言实现领域知识的皮毛,并且大部分集中在前端部分 (此前端非彼前端)。但即使如此,对于非科班的同学也有一定的学习代价。在这里我不推荐任何龙书之类。我只推荐《编程语言实现模式》,我觉得这本书虽然评价一般,但是是我看到的唯一一本脱离学院派味道的实战书籍。不过在你使用 JS 实现你的 DSL 时,由于 JS 语言非常灵活,抛开性能因素,你可以实现的比 JAVA 这类语言更加的优雅,其中精通正则表达式,可以让你在实现中少走很多弯路。然后推荐 Flex 和 Bison 这本来了解别人是如何设计语言的, javascript 对应的版本 是 jison, 比如 handlebar 等模板引擎都是基于 jison 实现。
理论结合实际的能力,为什么现在科班出身的前端不再少数,但鲜有人在前端 DSL 领域有过深耕?我觉得一方面是我们教育体制的填鸭教育问题,另一方面公司普遍业务导向,缺乏对人的培养,所有分享等激励措施都流于表面等实际现状脱不了干系。
实际使用的客户群体,论证设计和实现的合理性。这个,相比之下已是老干部的人 (比如我) 相比入职的新人可能更加有优势些。
Parser 这个基本领域是个已经被解决的问题,解决方案已经被固化为各种理论支持的 Parser Generator 方案。 但是在应用层面,如何在特定领域如日新月异的前端开发领域,如何结合特定宿主语言,仍然大有可为。
其实,每一个写 DSL 足够多的人,都会非常想去实现一个 Parser Generator.
https://www.zhihu.com/question/20140718/answer/114360444

若有收获,就点个赞吧
0 人点赞
