程序
源程序
☀️ 由计算机执行、处理的指令和数据称为程序
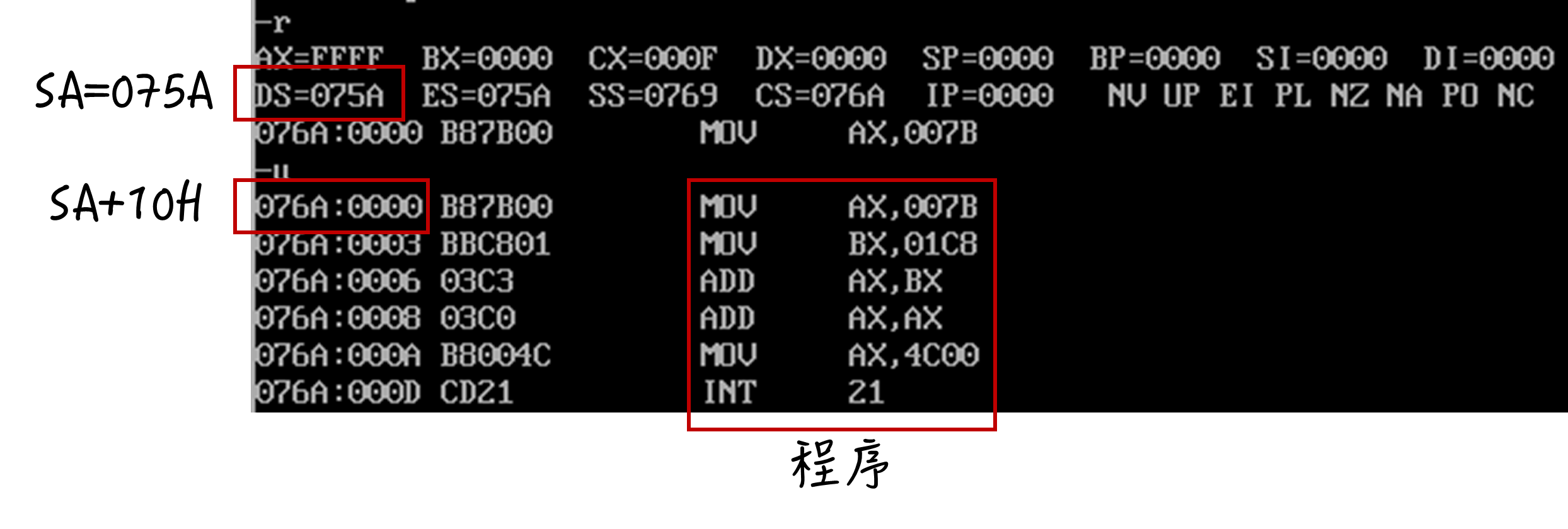
assume cs:codesgcodesg segment;以下是程序mov ax,0123Hmov bx,0456Hadd ax,bxadd ax,axmov ax,4c00Hint 21Hcodesg endsend
数据的后面写 H 表示十六进制数据,写 B 表示二进制,写 D 表示十进制,写 O 表示八进制,不写默认十进制 而
debug方式写的时候不能写后面的代号,只能写十六进制
伪指令
定义一个段
段名 segment段名 ends
程序结束
ends
📢 ends 与 assume 不是配套的,assume 只是声明段
关联段寄存器
assume cs:codesg ; codesg 最终会被编译成“段地址”
伪指令是由编译器执行的,不是由计算机执行的,也就是说计算机不会把 cs 指向 codesg 的段地址
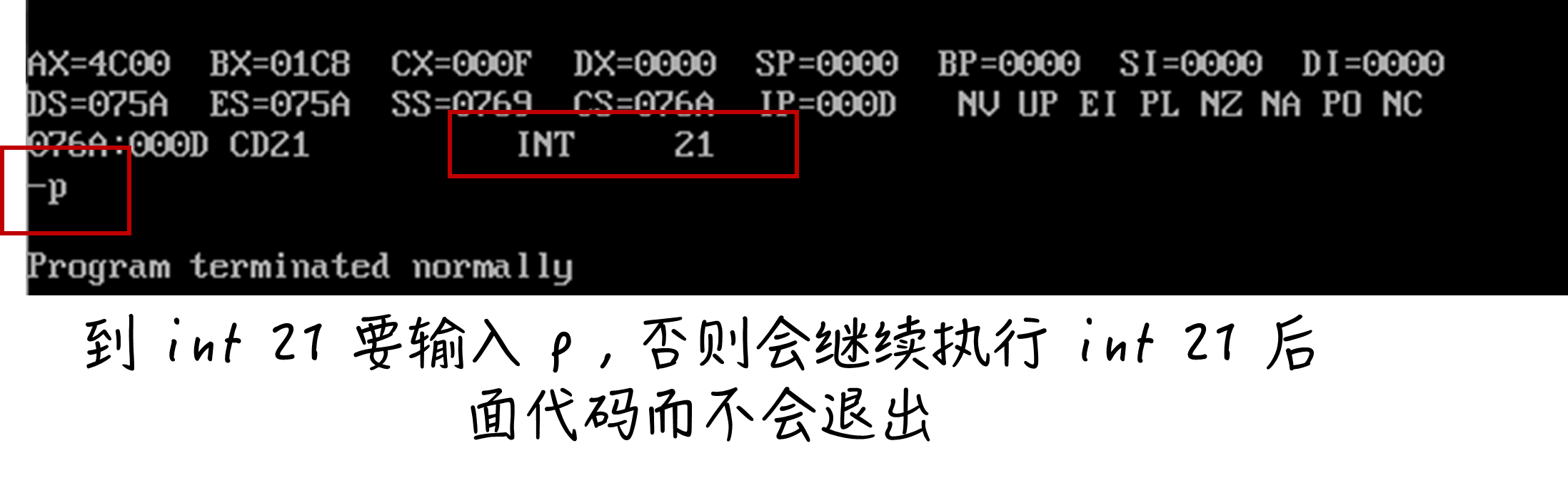
程序返回
单任务操作系统上,正在运行的  程序将
程序将  载入内存,
载入内存, 将控制权交给
将控制权交给  ,
, 才能运行,运行结束后,
才能运行,运行结束后, 又将控制权交给
又将控制权交给  ,称为程序返回
,称为程序返回
mov ax,4c00Hint 21H
在程序的末尾写上上面的两条指令,即可实现程序返回
在 DOS 中, 可以是
可以是 command.com即命令解释器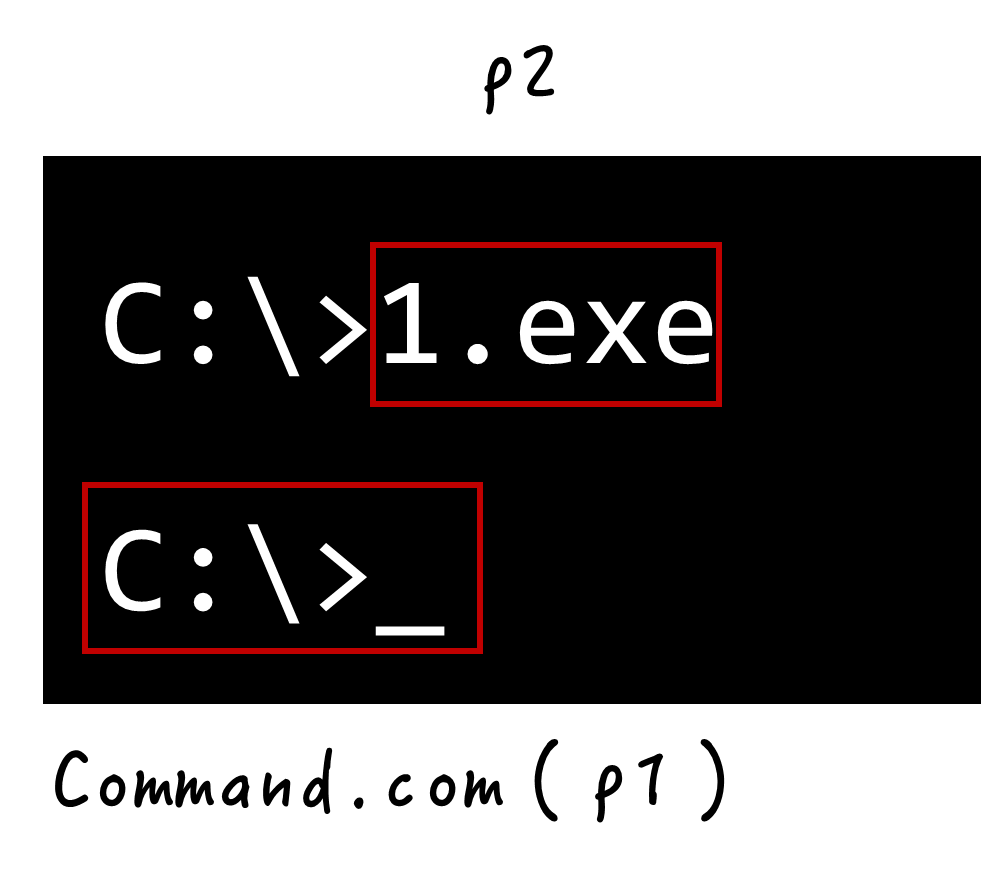
如果不写程序返回,则会变成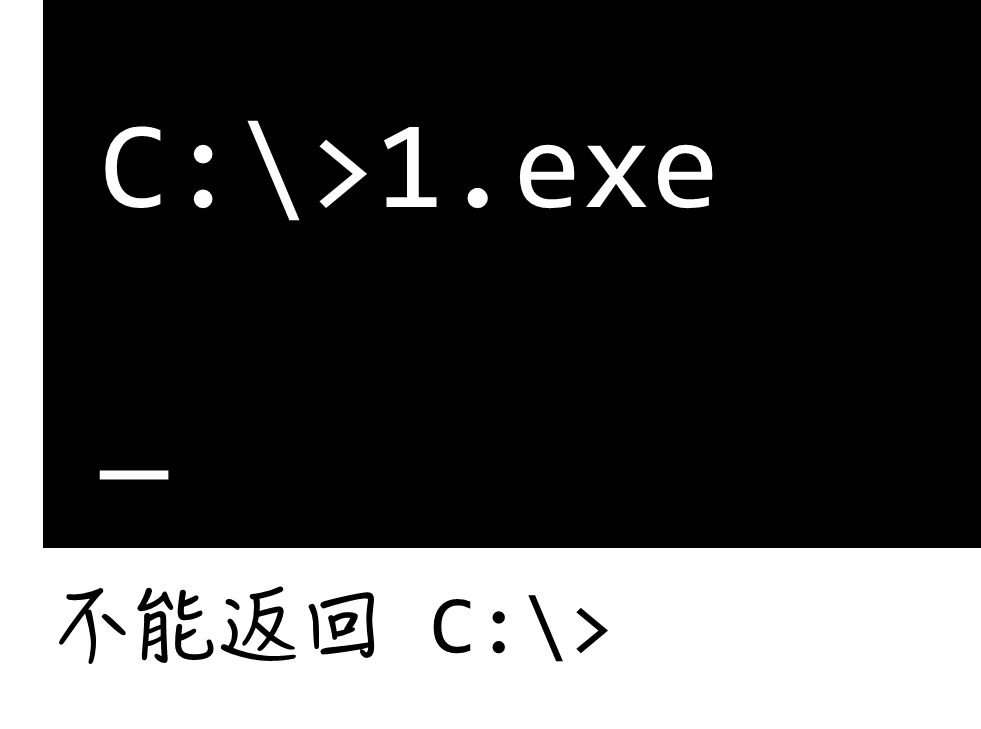
语法错误
sume cs:codesg ; 编译器不知道 sume 是什么codesg segmentmov ax,1000 ; 代码段没有 endsend
逻辑错误
assume cs:codesgcodesg segmentmov ax,1000; 不存在程序返回, 但能通过编译codesg endsend
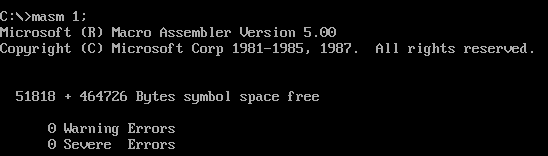
编译

如果文件名不是.asm结尾的需要输入全名,如 1.txt,如果文件和 masm.exe不在同一个目录,还要输入路径
如果默认忽略各种中间文件,且目标文件名不变,可以直接编译输入下面的代码进行编译,;不能省略
masm 1;
连接

link 1;
跟踪
debug 1.exe
注意
exe不能省略
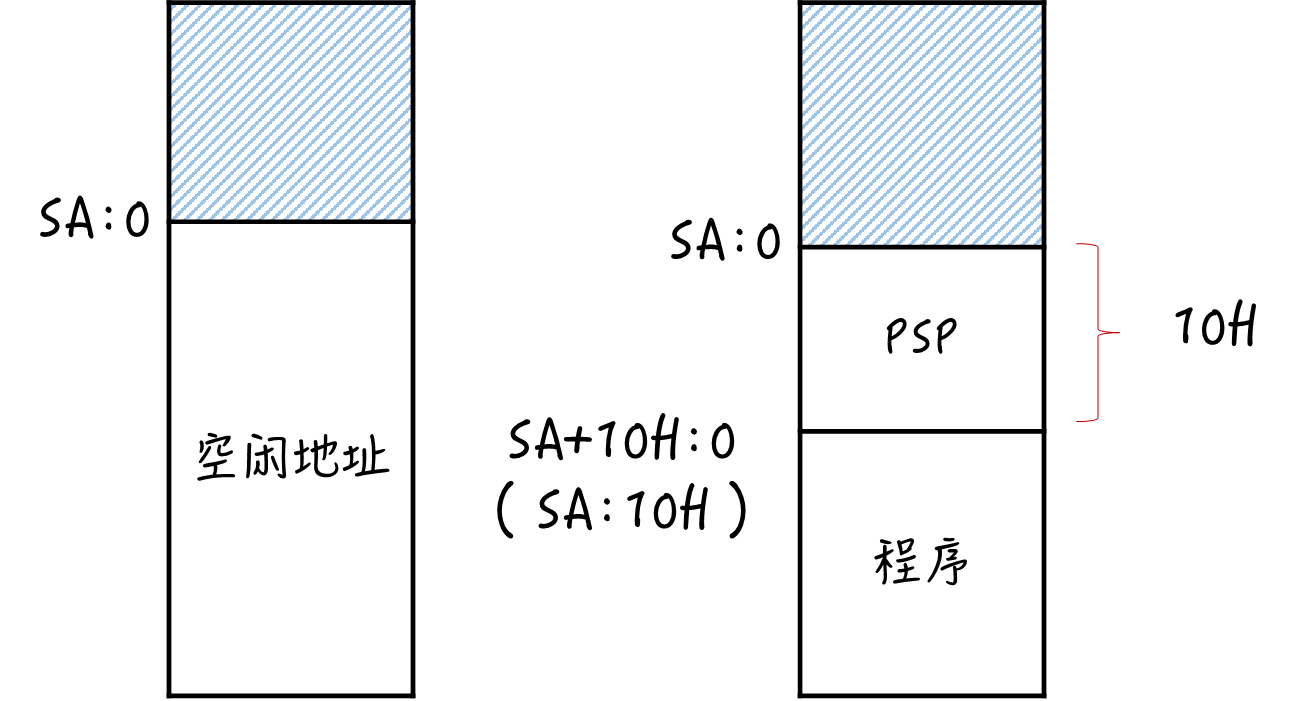
程序载入过程
会自动寻找足够大的空闲空间
[BX] 与 loop
描述符 ()
(寄存器)表示寄存器里的内容,如(ax)=1000H(物理地址)表示物理地址里的内容,如(2000H)=0010H(段寄存器)表示段寄存器的内容,如((ds)×16+(ax))=1000H约定符 idata
idata 表示常量
mov ax,[idata]表示mov ax,[1]``mov ax,[2]等mov ax,idata表示mov ax,1``mov ax,2等[bx]
mov ax,[bx]表示将偏移地址为(bx)的字型数据送入 ax,即(ax)=((ds)×16+(bx))
如果是mov al,[bx]则[bx]代表字节型数据(即 1 个字节)注意,
[...]只能放入bx``si``di``bp寄存器,[ax]``[cx]``[dx]``[ds]是非法的
mov ax,0ffffh ; 汇编不允许字母开头的数据mov ds,axmov bx,6;将字节型(8位)数据 ffff:0 送入 16 位的 ax 中;如果直接 mov ax,[bx] 则会送入字型数据(16位), ah 不一定是 0 了mov al,[bx]mov ah,0
自增 inc
inc bx ; 表示 bx=bx+1
不能操作段寄存器

loop
assume cs:codecode segmentmov ax,2mov cx,11s: add ax,axloop smov ax,4c00hint 21hcode endsend
执行到  会先让
会先让  然后再判断是否
然后再判断是否  ,若成立则退出(
,若成立则退出( 是通用寄存器)
是通用寄存器)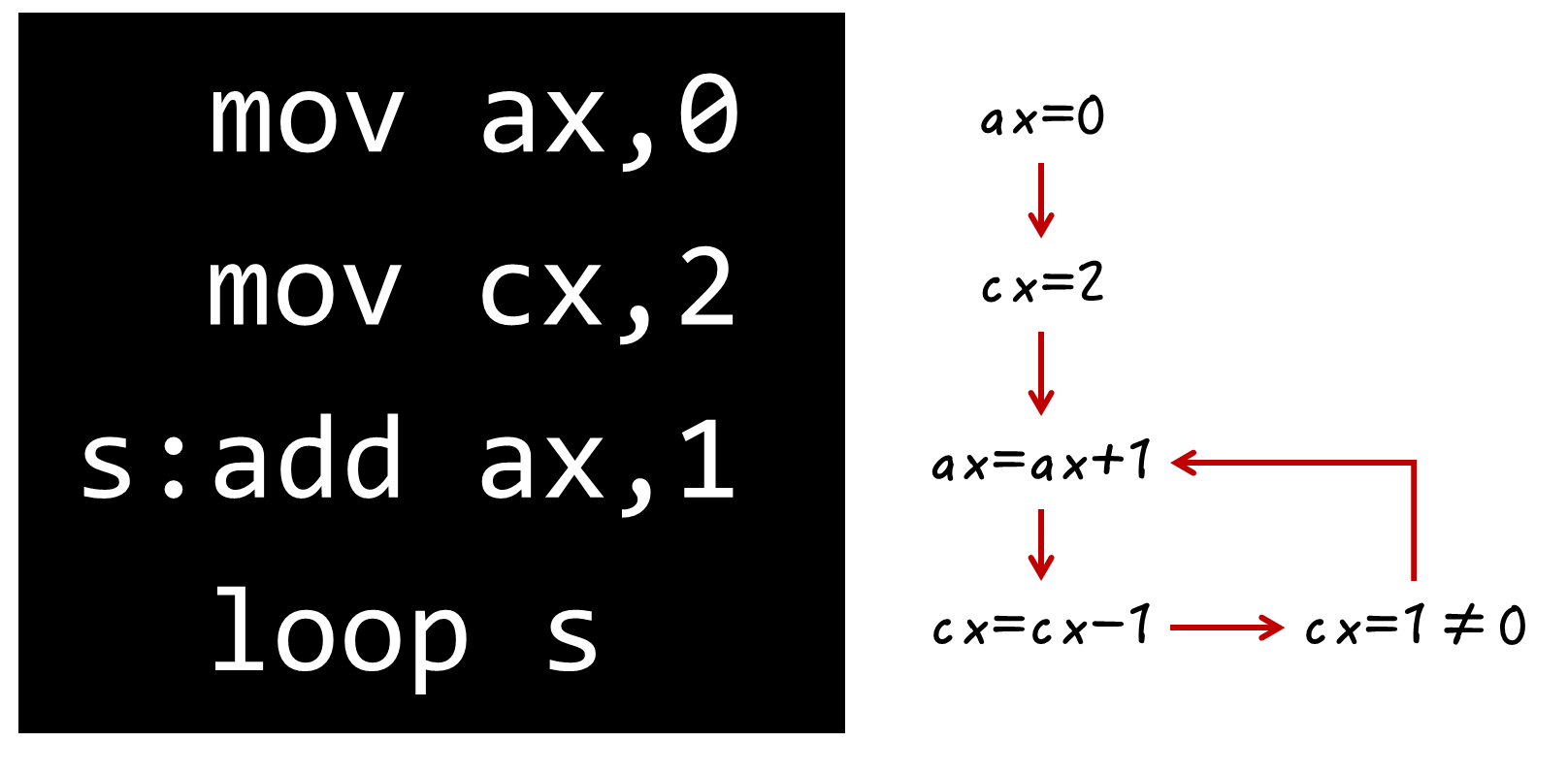
指定跟踪位置
assume cs:codecode segmentmov ax,0ffffhmov ds,axmov bx,6mov al,[bx]mov ah,0mov cx,123s: add dx,ax ;这里需要循环loop smov ax,4c00H ; 这里循环结束int 21Hcode endsend
g IP
 指需要循环的指令的
指需要循环的指令的  ,即指令
,即指令 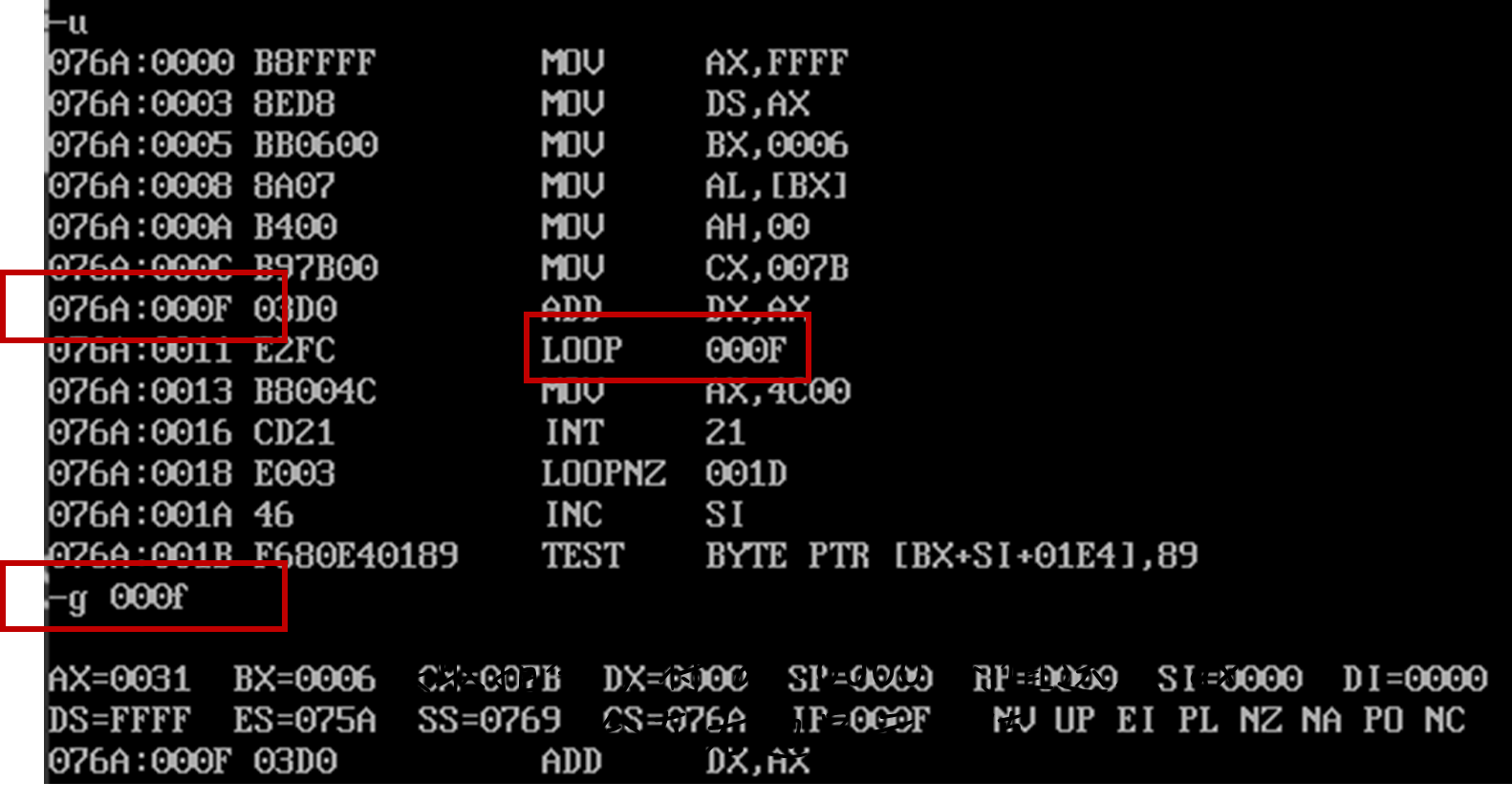
跳过循环
p

g IP
 指循环结束后指令的
指循环结束后指令的  ,即
,即 循环嵌套
有问题的程序
assume cs:code,ds:datadata segmentdb 'ibm 'db 'dec 'db 'dos 'db 'vax 'data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov cx,4 ; 四个单词, 外循环需要循环 4 次s0: mov si,0mov cx,3 ; 三个字母, 内循环需要循环 3 次s1: mov al,[bx+si]and al,11011111Bmov [bx+si],alinc alloop s1add bx,16loop s0code endsend start
当一次内循环结束后遇到loop s0循环次数cx就会变成FFFF这样外循环的循环次数不断被覆盖,无法结束循环
解决方案一
使用寄存器dx临时保存外循环的cx
assume cs:code,ds:datadata segmentdb 'ibm 'db 'dec 'db 'dos 'db 'vax 'data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov cx,4s0: mov dx,cx ; 保存外循环的 cxmov si,0mov cx,3s1: mov al,[bx+si]and al,11011111Bmov [bx+si],alinc siloop s1add bx,16mov cx,dx ; 这里恢复外循环的 cxloop s0mov ax,4c00Hint 21Hcode endsend start
解决方法二
使用栈来保存多个循环的cx
assume cs:code,ds:datadata segmentdb 'ibm 'db 'dec 'db 'dos 'db 'vax 'data endsstack segmentdw 0 ; 这里写一个 0 就可以创建 16 个字节的栈stack endscode segmentstart: mov ax, stackmov ss,axmov sp,16mov ax,datamov ds,axmov bx,0mov cx,4s0: push cx ; cx 入栈mov si,0mov cx,3s1: mov al,[bx+si]and al,11011111Bmov [bx+si],alinc siloop s1add bx,16pop cx ; cx 出栈loop s0mov ax,4c00Hint 21Hcode endsend start
汇编代码的不同处理
debug 里[0]就代表ds:0里的数据,而源程序中代表 0
解决方法
使用 bx 中转
mov bx,0mov ax[bx]
显示声明内存单位,又称为段前缀
mov ax,ds:[0]
8 位二进制数累加
8 位二进制范围 0~255,累加可能会导致进位丢失
- 不能直接把 8 位二进制放到 ax 中,因为位数不匹配
解决方法
s:mov al,[bx]mov ah,0add dx,ax ; 利用 dx 进行“中转”, dx 是 16 位的, 累加用 dx, ax 通过 al,ah 拼成 16 位inc bxloop s
多段程序
代码段中使用数据 dw
使用
dw让系统自动帮我们分配数据的内存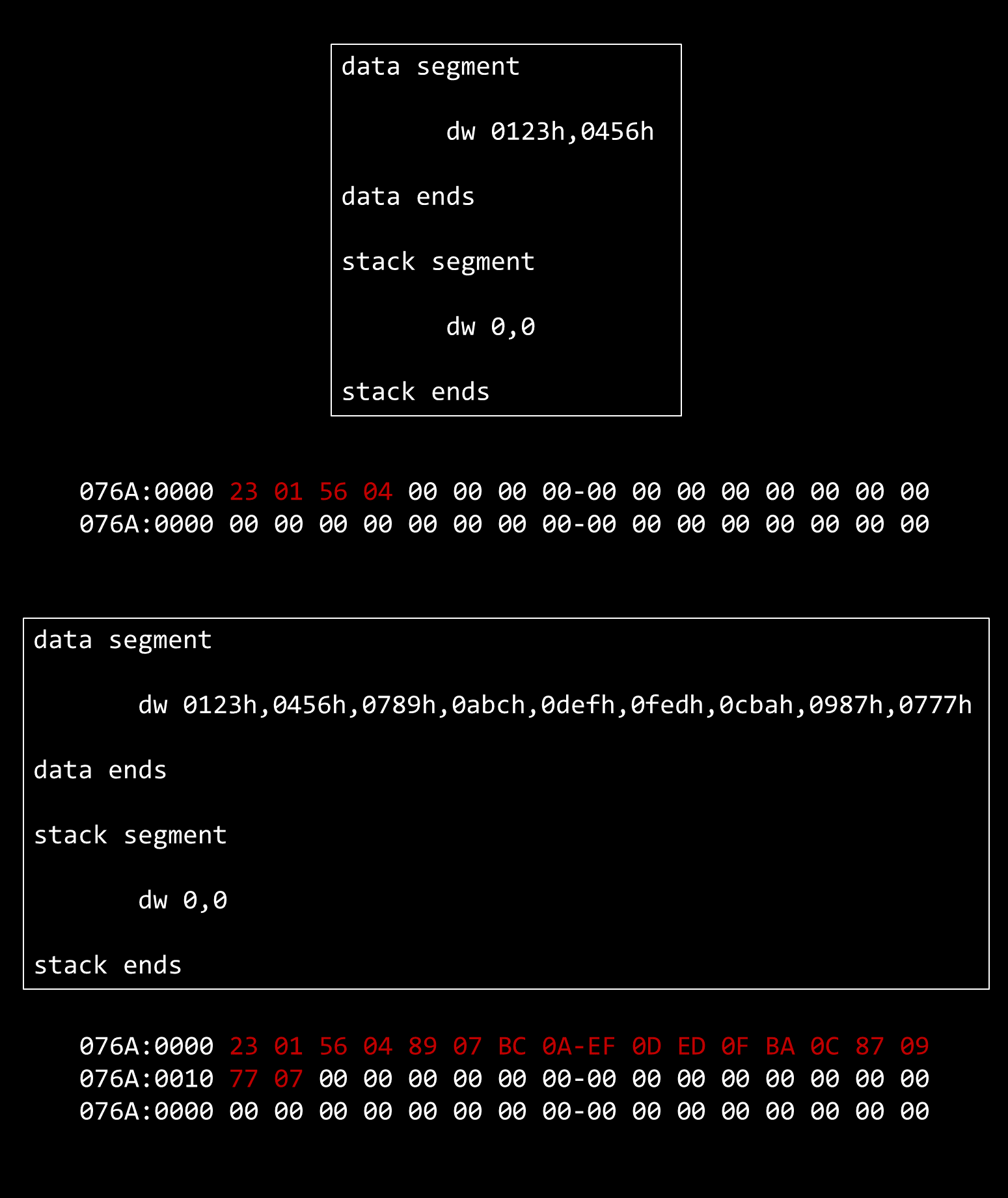 不够 16 个字节的会占满 16 个字节,超了会到下一行,即
不够 16 个字节的会占满 16 个字节,超了会到下一行,即  个字节数据,实际占用
个字节数据,实际占用  字节
这里要用
字节
这里要用cs:[bx]不能直接写[bx],因为数据是存在指令地址空间上的,而[bx]代表ds:[bx]是数据地址空间
assume cs:codecode segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hmov bx,0mov ax,0mov cx,8 ;循环 8 次s: add ax,cs:[bx] ; cs[0]指向 dw 所指代的数据add bx,2loop smov ax,4c00Hint 21Hcode endsend
直接使用 u查看是一堆看不懂的指令,即由 dw定义的数据被编译器看成了指令
需要跳过前面的dw才能看到正确的指令
为了不让编译器误执行前面不对的代码,需要指定代码执行的入口,编译器会根据end start自动设置程序的 
start只是个单词,写什么都可以,只要end xxx和xxx:对应即可
assume cs:codecode segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hstart: mov bx,0mov ax,0mov cx,8 ;循环 8 次s: add ax,cs:[bx] ; cs[0]指向 dw 所指代的数据add bx,2loop smov ax,4c00Hint 21Hcode endsend start
代码段中使用栈
使用
dw开辟栈空间
assume cs:codecode segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hdw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ; 申请 16 个字空间start: mov ax,csmov ss,axmov sp,30h ; 栈顶从 8×2 + 16×2 = 48 = 30h 开始mov bx,0mov cx,8s: push cs:[bx]add bx,2loop smov bx,0mov cx,8s0: pop cs:[bx]add bx,2loop s0mov ax,4c00Hint 21Hcode endsend start
入栈本来只需要 8 个字即可,但是由于不明确的原因,必须申请 16 个
数据、代码放在不同段
assume cs:code,ds:data,ss:stackdata segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hdata endsstack segmentdw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0stack endscode segmentstart: mov ax,stackmov ss,ax ; 栈段地址指向 stack 的段地址mov sp,20hmov ax,data ; 数据指向 data 段地址mov ds,ax ; data 会被解析成一个数值, 因此 mov ds,data 不合法mov bx,0mov cx,8s: push [bx] ; 由于数据不在指令地址空间了, 因此不需要写 cs:[bx]add bx,2loop smov bx,0mov cx,8s0: pop [bx]add bx,2loop s0mov ax,4c00Hint 21Hcode endsend start
如果不指定end start,则会从第一个段开始执行,即 data 段

因此如果不想写end start则把 code 段写在第一个即可
更灵活寻址方法
and 按位与
mov al,01100011Band al,00111011B; 结果 al=00100011B
or 按位或
mov al,01100011Bor al,00111011B; 结果 al=01111011B
ASCII码
伪指令 db
db不会像dw一样默认占 16 个字节,db定义字节型数据
assume cs:code,ds:datadata segmentdb 'ubIX'db 'foRK'data endscode segmentstart: mov al,'a'mov bl,'b'mov ax,4c00hint 21hcode endsend start
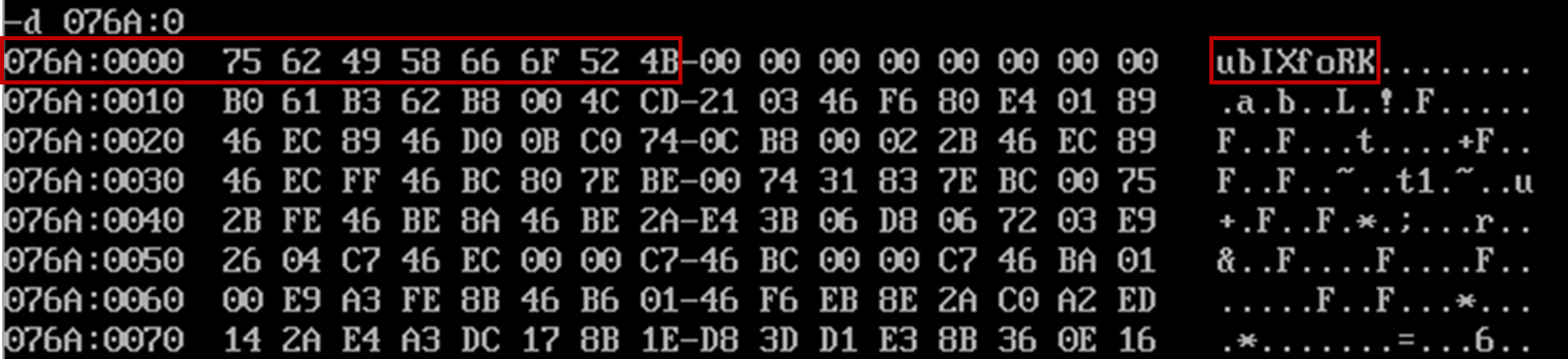
转成大写
assume cs:code,ds:datadata segmentdb 'ubIX'data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov cx,4 ; 单词数 4 就循环 4 次s:mov al,[bx]and al,11011111B ; 小写字母的 ASCII 第 5 个数变成 0, 则变成大写mov [bx],alinc bxloop smov ax,4c00hint 21hcode endsend start

转成小写
assume cs:code,ds:datadata segmentdb 'ubIX'data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov cx,4 ; 单词数 4 就循环 4 次s:mov al,[bx]or al,00100000B ; 大写字母的 ASCII 第 5 个数变成 1, 则变成小写mov [bx],alinc bxloop smov ax,4c00hint 21hcode endsend start
[bx+idata]
偏移地址可以使用加法
mov ax,[200+bx]
mov ax,[bx+200]
mov ax,200[bx]
mov ax,[bx].200
以上代码都表示(ax)=((ds)×16+(bx)+200)
C语言对比版
; 汇编语言assume cs:code,ds:datadata segmentdb 'BaSic'db 'MinIX'data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov cx,5s:mov al,0[bx]and al,11011111B ; 转大写mov 0[bx],almov al,5[bx]or al,00100000B ; 转小写mov 5[bx],alinc bxloop smov ax,4c00hint 21hcode endsend start
// c 语言char a[5]="BaSic";char b[5]="MinIx";int main(){int i=0;do{a[i]=a[i]&0xDF;b[i]=b[i]|0x20;i++;} while(i<5);}
[SI] 和 [DI]
与
寄存器功能类似,不过不能分成两个 8 位寄存器来使用
[si+di]是非法的
复制字符串
assume cs:code,ds:datadata segmentdb 'welcome to masm!'db '..........'data endscode segmentstart: mov ax,datamov ds,axmov si,0mov di,16mov cx,8s:mov ax,[si]mov [di],axadd si,2add di,2loop smov ax,4c00hint 21hcode endsend start
[bx+si] 和 [bx+di]
与
[bx+idata]功能类似,不过是将idata换成寄存器
mov ax,[bx+si]
mov ax,[bx][si]
以上代码都表示(ax)=((ds)×16+(bx)+(si))
[bx+si/di+idata]
mov ax,[bx+si+200]
mov ax,[bx][si].200
mov ax,200[bx][si]
mov ax,[bx].200[si]
[BP]
[bp]的默认段地址是ss,即 ss:[bp]
[bx]的默认段地址是ds,即ds:[bx][bx+bp]是非法的,但是bp可以和si``di合用mov [bp],bx可行,但mov [sp],bx不可行,因此要修改栈元素需要使用bp中转
数据处理
除法 div
用法 div 除数
- 如果除数是 8 位的,则被除数在
ax里,为 16 位,商保存在al里,余数保存在ah里 如果除数是 16 位的,则被除数高位在
dx里,低位在ax里,为 32 位,商保存在ax里,余数保存在dx里div byte ptr [bx+si+8]
上面的代码表示
(al)=(ax)/((ds)×16+(bx)+(si)+8))的商``(ah)=(ax)/((ds)×16+(bx)+(si)+8))的余数计算 100001/100
被除数 100001 不能放到 16 位里,因此只能放在 32 位里
- 除数 100 可以是 8 位的,但是由于被除数只能是 32 位,因此除数也只能是 16 位的
- 100001 的 16 进制为 186A1 ``` assume cs:code
code segment mov dx,1 mov ax,86A1H mov bx,100 div bx
mov ax,4c00Hint 21H
code ends
end
<a name="ukRIg"></a>## 乘法 mul用法`mul 内存单元``mul 寄存器`> 两个乘数位数必须相同- 都是 8 位,一个数放在`al`中,另一个放在内存单元或寄存器中,结果保存在`ax`中- 都是 16 位,一个数放在`ax`中,另一个放在内存单元或寄存器中,结果高位放在`dx`中,低位放在`ax`中
mul byte ptr ds:[0] ; 8 位
```mul word ptr ds:[0] ; 16 位

计算 100×10
100 和 10 都小于 8 位
mov al,10mov bl,100mul bl
注意如果写成mul bx则会被当作 16 位,进而计算ax·bx所以不会报错
伪指令 dd
与
dw和db类似,dd定义双字型数据,也默认占满 16 个字节
dd 1
数据重复 dup
dup重复数不能为 0
dw 3 dup (1,2,3) ; 重复 3 次
上面的代码等价于 dw 1,2,3,1,2,3,1,2,3

若有收获,就点个赞吧
0 人点赞
