Trident 拥有一流的 abstractions (抽象)用于 reading from (读取)和 writing to (写入) stateful sources (状态源). state (状态)可以是 internal to the topology (拓扑内部), 例如保存在内存中并由 HDFS 支持 - 或者 externally stored (外部存储)在像 Memcached 或者 Cassandra 这样的数据库中. Trident API 在任何一种情况下都没有区别.
Trident 以 fault-tolerant (容错方式)来管理 state (状态), 以便在 retries (重试)和 failures (失败)时 state updates (状态更新)是 idempotent (幂等)的. 这可以让您理解 Trident topologies (Trident 拓扑结构), 就好像每个消息都被 exactly-once (精确处理一次).
在进行 state updates (状态更新)时可能会有各种级别的 fault-tolerance (容错能力). 在得到这些之前, 我们来看一个例子来说明实现 exactly-once semantics (完全一次性语义)所必需的技巧. 假设您正在对 stream (流)进行 count aggregation (计数聚合), 并希望将 running count (运行的计数)存储在数据库中. 现在假设您在数据库中存储一个 single value representing the count (表示计数的值), 并且每次处理 new tuple (新的元组)时, 都会增加 count (计数).
发生故障时, 将 replayed tuples (元组). 这会导致在执行 state updates (状态更新)时出现问题(或任何带有副作用的东西) - 您不知道如果您曾经成功根据此 tuple (元组)更新了 state (状态). 也许你从来没有处理过 tuple (元组), 在这种情况下你应该增加 count (计数). 也许你已经处理了 tuple , 并成功地增加了 count (计数), 但是 tuple (元组)在另一个步骤中处理失败. 在这种情况下, 您不应该增加 count (计数). 或者也许你看到了 tuple , 但更新数据库时出错. 在这种情况下, 您 应该 update the database (更新数据库).
通过将 count 存储在数据库中, 您不知道这个 tuple 是否被处理过. 所以你需要更多的信息才能做出正确的决定. Trident 提供以下 semantics (语义), 足以实现 exactly-once (完全一次性)处理语义:
- Tuples (元组)被 small batches (小批)处理(参见 the tutorial)
- Each batch of tuples (每批元组)给出一个唯一的id, 称为 “transaction id” (txid) . 如果 batch (批次)被 replayed , 则给出完全相同的 txid .
- State updates (状态更新)跟随 batches (批次)的顺序. 也就是说, 在 batch 2 的状态更新成功之前, batch 3 的状态更新将不会被应用.
使用这些 primitives (原语), 您的 State implementation (State 实现)可以检测该 batch (批次)的 tuples (元组)是否已被处理, 并采取适当的操作以一致的方式更新状态. 您所采取的操作取决于您的 input spouts (输入端口)提供的关于每 batch 中的内容的 exact semantics (确切语义). 有关 fault-tolerance (容错)的 spouts 可能性有三种:”non-transactional (非事务性)”, “transactional (事务)” 和 “opaque transactional (不透明事务)” . 同样, 在 fault-tolerance (容错)方面有三种可能 state : “non-transactional (非事务性)” , “transactional (事务)” 和 “opaque transactional (不透明事务)” . 我们来看看每个 spout 类型, 看看你可以实现什么样的容错.
Transactional spouts
请记住, Trident 将 tuples (元组)作为 small batches (小批量)进行处理, 每个批处理都被赋予一个唯一的 transaction id (事务 ID). spouts 的属性根据他们可以提供的每 batch (批次)中的内容的 guarantees (保证)而有所不同. transactional spout 具有以下属性:
- 给定 txid 的 Batches (批次)总是相同的. txid 的批次的 Replays 将与该 txid 的第一次发出批次时的一组元组完全相同.
- batches of tuples (批量的元组)之间没有 overlap (重叠)( tuples (元组)在一个批次或另一个批次中, 而不是在多个批次中).
- 每个元组都是批量的(没有元组被跳过).
这是一个理解起来非常简单的类型的 spout , stream 被分为 fixed batches (固定批次), 从不改变. storm-contrib 具有 一个 transactional spout 的实现 针对于 Kafka .
你可能会想 - 为什么你不总是使用一个 transactional spout ?它们简单易懂. 你不能使用它的一个原因是因为它们不一定非常 fault-tolerant (容错). 例如, TransactionalTridentKafkaSpout 的工作原理是 txid 的批处理将包含来自所有 Kafka partitions 的元组. 一旦批次被发出, 在未来的任何时候批次被重新发出, 必须发出完全相同的元组集合才能满足 transactional spouts 的语义. 现在假设一个批处理从 TransactionalTridentKafkaSpout 发出, batch 无法处理, 同时一个 Kafka 节点宕机. 您现在无法像以前一样 replaying 同一批次(因为节点关闭, topic 的某些 partitions 不可用), 并且处理将 halt (停止).
这就是为什么存在 “opaque transactional (不透明事务)” spout - 它们容许这样的错误, 丢失 source nodes (源节点), 同时仍允许您实现 exactly-once (一次)处理语义. 我们将在下一节中介绍这些 spouts .
(一方面注意 - 一旦 Kafka 支持 replication (备份), 就有可能拥有对节点故障容错的 transactional spouts , 但该功能尚不存在. )
在我们介绍 “opaque transactional (不透明事务)” spouts 之前, 我们来看看如何设计一个具有 exactly-once semantics (完全一致的语义的) transactional spouts 的 State implementation (状态实现). 这种状态称为 “transactional state (事务状态)” , 并且利用了任何给定的 txid 始终与完全相同的元组集合相关联的事实.
假设您的 topology 计算 word count , 并且您想将 word counts 存储在 key/value database 中. key 将是这个 word , value 将包含 count . 您已经看到, 仅将 count 存储为 value 不足以知道是否已经处理了一批元组. 相反, 您可以做的是将 transaction id 存储在数据库中的 count 作为 atomic value (原子值). 然后, 当更新 count 时, 可以将数据库中的 transaction id 与当前批处理的 transaction id 进行比较. 如果它们相同, 则跳过该更新 - 由于强大的排序, 您可以确定数据库中的 value 包含当前 batch . 如果它们不同, 你会增加 count . 此逻辑工作原理是因为 txid 的批次不会更改, Trident 可确保 state updates 跟随 batches 的顺序.
考虑这个为什么它起作用的例子. 假设您正在处理由以下批次元组组成的 txid 3 :
["man"]["man"]["dog"]
假设数据库当前持有以下 key/value 对:
man => [count=3, txid=1]dog => [count=4, txid=3]apple => [count=10, txid=2]
与 “man” 相关联的 txid 为 txid 1 .由于当前的 txid 为 3 , 因此您可以肯定地知道这批元组在该 count 中未被显示. 所以你可以继续递增 count 2 并更新 txid . 另一方面, “dog” 的 txid 与当前的 txid 相同. 所以你确定当前批次的增量已经在数据库中被显示为 “dog” key . 所以你可以跳过更新. 完成更新后, 数据库如下所示:
man => [count=5, txid=3]dog => [count=4, txid=3]apple => [count=10, txid=2]
现在我们来看看 opaque transactional spouts (不透明事务 spouts), 以及如何设计这种 spout 的 states.
Opaque transactional spouts
如前所述, opaque transactional spout 不能保证 txid 的元组的批次保持不变. opaque transactional spout 具有以下属性:
- 每个元组都被 exactly one batch (正确的一个批次中) successfully 处理. 但是, 一个元组可能无法在一个批处理中处理, 然后在后续批处理中成功处理.
OpaqueTridentKafkaSpout 是一个具有此属性并且是对丢失 Kafka 节点有容错性的 spout . 无论何时 OpaqueTridentKafkaSpout emit a batch (发出批次), 它将从最后一批完成发出的位置开始发出元组. 这就确保了永远没有任何一个 tuple 会被跳过或者被放在多个 batch 中被多次成功处理的情况.
使用 opaque transactional spouts , 如果数据库中的 transaction id 与当前批处理的 transaction id 相同, 则不再可能使用 trick of skipping state updates (跳过状态更新的技巧). 这是因为在 state updates (状态更新)之间批处理可能已更改.
你可以做的是在数据库中存储更多的 state . 而不是在数据库中存储 value 和 transaction id , 而是将 value , transaction id 和上一个 value 存储在数据库中. 我们再次使用在数据库中存储 count 的示例. 假设您的批次的部分计数是 “2” , 现在是应用 state update (状态更新)的时间. 假设数据库中的 value 如下所示:
{ value = 4, prevValue = 1, txid = 2 }
假设你当前的 txid 是 3 , 与数据库不同. 在这种情况下, 您将 “prevValue” 设置为 “value” , 通过 partial count 增加 “value” , 并更新 txid . 新的数据库值将如下所示:
{ value = 6, prevValue = 4, txid = 3 }
现在假设你当前的 txid 是 2 , 等于数据库中的内容. 现在, 您知道数据库中的 “value” 包含来自当前 txid 的上一批次的更新, 但该批次可能已经不同, 因此您必须忽略它. 在这种情况下, 您的 partial count 将增加 “prevValue” , 以计算新的 “value” . 然后将数据库中的 value 设置为:
{ value = 3, prevValue = 1, txid = 2 }
这是因为 Trident 提供的批次的 strong ordering (强大顺序). 一旦 Trident 移动到新的批次进行状态更新, 它将永远不会返回到上一批. 而且由于 opaque transactional spouts 保证批次之间不 overlap (重叠) - 每个元组都被一个批次成功处理 - 您可以根据先前的 value 安全地进行更新.
Non-transactional spouts
Non-transactional spouts 不对每批中的内容提供任何保证. 所以它可能是 at-most-once (最多一次)的处理, 在这种情况下, 元组不会在失败的批次后重试. 或者它可能 at-least-once (至少处理一次), 其中可以通过多个批次成功处理元组. 没有办法为这种 spout 实现 exactly-once semantics (完全一次性语义).
spout 和 state type 的汇总
此图显示了 spouts / states 的哪些组合可以实现一次消息传递语义:
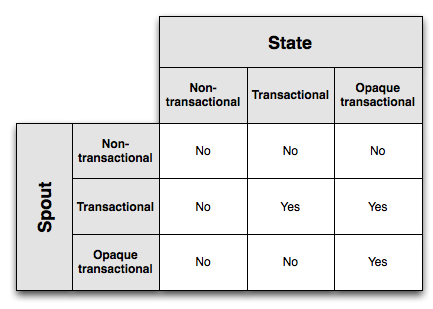
Opaque transactional states 具有最强的 fault-tolerance (容错能力), 但这需要以 txid 和两个 values 存储在数据库中为代价. Transactional states 在数据库中需要较少的 state , 但仅适用于 transactional spouts . 最后, non-transactional states 在数据库中需要最少的 state , 但不能实现 exactly-once semantics (一次性语义).
您选择的 state 和 spout types 是容错和存储成本之间的折中, 最终您的应用程序要求将决定哪种组合适合您.
State APIs
您已经看到了完成 exactly-once semantics (完全一次语义)所需要的复杂性. Trident 的好处是它将所有容错逻辑内部化 - 作为一个用户, 您不必处理比较 txids , 在数据库中存储多个值或类似的内容. 你可以这样编写代码:
TridentTopology topology = new TridentTopology();TridentState wordCounts =topology.newStream("spout1", spout).each(new Fields("sentence"), new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(MemcachedState.opaque(serverLocations), new Count(), new Fields("count")).parallelismHint(6);
管理 opaque transactional state logic 所需的所有 logic 都内在于 MemcachedState.opaque 调用. 此外, 自动批量更新以最小化到数据库的 roundtrips (往返行程).
基本 State interface (状态接口)只有两种方法:
public interface State {void beginCommit(Long txid); // can be null for things like partitionPersist occurring off a DRPC streamvoid commit(Long txid);}
当状态更新开始时, 您被告知, 当状态更新结束时, 在每种情况下都被给予了 txid . Trident 对于你的 state 如何工作, 什么样的方法有更新, 以及从中读取什么样的方法呢?
假设您有一个 home-grown database (本地生成的数据库), 其中包含用户位置信息, 并且您希望能够从 Trident 访问它. 您的 State implementation 将具有获取和设置用户信息的方法:
public class LocationDB implements State {public void beginCommit(Long txid) {}public void commit(Long txid) {}public void setLocation(long userId, String location) {// code to access database and set location}public String getLocation(long userId) {// code to get location from database}}
然后, 您可以向 Trident 提供一个 StateFactory , 它可以在 Trident tasks 中创建 State 对象的实例. 您的 LocationDB 的 StateFactory 可能看起来像这样:
public class LocationDBFactory implements StateFactory {public State makeState(Map conf, int partitionIndex, int numPartitions) {return new LocationDB();}}
Trident 提供 QueryFunction interface , 用于编写查询 source of state (状态源)的Trident 操作, 以及 StateUpdater 接口, 用于编写更新 source of state (状态源)的 Trident 操作. 例如, 我们来写一个操作 “QueryLocation” , 它查询 LocationDB 的用户位置. 我们先来看看如何在 topology 中使用它. 假设这种 topology 消耗了 userids 的 input stream:
TridentTopology topology = new TridentTopology();TridentState locations = topology.newStaticState(new LocationDBFactory());topology.newStream("myspout", spout).stateQuery(locations, new Fields("userid"), new QueryLocation(), new Fields("location"))
现在我们来看看 QueryLocation 的实现如何:
public class QueryLocation extends BaseQueryFunction<LocationDB, String> {public List<String> batchRetrieve(LocationDB state, List<TridentTuple> inputs) {List<String> ret = new ArrayList();for(TridentTuple input: inputs) {ret.add(state.getLocation(input.getLong(0)));}return ret;}public void execute(TridentTuple tuple, String location, TridentCollector collector) {collector.emit(new Values(location));}}
QueryFunction 的两个步骤执行. 首先, Trident 将一批读取合并在一起, 并将它们传递给 batchRetrieve . 在这种情况下, batchRetrieve 将接收 multiple user ids (多个用户 ID ). batchRetrieve 预期返回与输入元组列表大小相同的结果列表. 结果列表的第一个元素对应于第一个输入元组的结果, 第二个是第二个输入元组的结果, 依此类推.
你可以看到, 这个代码没有利用 Trident 的批处理, 因为它只是一次查询一个 LocationDB . 所以写一个更好的方法来编写 LocationDB 就是这样的:
public class LocationDB implements State {public void beginCommit(Long txid) {}public void commit(Long txid) {}public void setLocationsBulk(List<Long> userIds, List<String> locations) {// set locations in bulk}public List<String> bulkGetLocations(List<Long> userIds) {// get locations in bulk}}
然后, 您可以像这样编写 QueryLocation 函数:
public class QueryLocation extends BaseQueryFunction<LocationDB, String> {public List<String> batchRetrieve(LocationDB state, List<TridentTuple> inputs) {List<Long> userIds = new ArrayList<Long>();for(TridentTuple input: inputs) {userIds.add(input.getLong(0));}return state.bulkGetLocations(userIds);}public void execute(TridentTuple tuple, String location, TridentCollector collector) {collector.emit(new Values(location));}}
通过减少到数据库的 roundtrips (往返行程), 此代码将更加高效.
要 update state , 可以使用 StateUpdater interface . 这是一个 StateUpdater , 它使用新的位置信息来更新 LocationDB :
public class LocationUpdater extends BaseStateUpdater<LocationDB> {public void updateState(LocationDB state, List<TridentTuple> tuples, TridentCollector collector) {List<Long> ids = new ArrayList<Long>();List<String> locations = new ArrayList<String>();for(TridentTuple t: tuples) {ids.add(t.getLong(0));locations.add(t.getString(1));}state.setLocationsBulk(ids, locations);}}
以下是在 Trident topology 中使用此操作的方法:
TridentTopology topology = new TridentTopology();TridentState locations =topology.newStream("locations", locationsSpout).partitionPersist(new LocationDBFactory(), new Fields("userid", "location"), new LocationUpdater())
partitionPersist 操作更新 source of state (状态源). StateUpdater 收到该 State 和一批具有该 State 更新的元组. 该代码只是从输入元组中获取用户名和位置, 并将批量集合放入 States .
partitionPersist 返回表示由 Trident topology 更新的位置数据块的 TridentState 对象. 然后, 您可以在 topology 中的其他地方的 stateQuery 操作中使用此 state .
您还可以看到 StateUpdaters 被赋予了 TridentCollector . 发送到这个 collector 的元组转到 “new values stream” . 在这种情况下, 没有什么有趣的可以发送到该 stream , 但是如果您在数据库中进行更新 counts , 则可以将更新的 counts 发送到该 stream . 然后, 您可以通过 TridentState#newValuesStream 方法访问 new values stream 以进一步处理.
persistentAggregate
Trident 有另外一种更新 State 的方法叫做 persistentAggregate . 你在之前的 streaming word count 例子中应该已经见过了, 如下:
TridentTopology topology = new TridentTopology();TridentState wordCounts =topology.newStream("spout1", spout).each(new Fields("sentence"), new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
persistentAggregate 是在 partitionPersist 之上的另外一层抽象,它知道怎么去使用一个 Trident aggregator (Trident 聚合器)来更新 State . 在这个例子当中, 因为这是一个 grouped stream (分组流), Trident 会期待你提供的 state 是实现了 “MapState” 接口的. 用来进行 group 的字段会以 key 的形式存在于 State 当中, 聚合后的结果会以 value 的形式存储在 State 当中. “MapState” 接口看上去如下所示:
public interface MapState<T> extends State {List<T> multiGet(List<List<Object>> keys);List<T> multiUpdate(List<List<Object>> keys, List<ValueUpdater> updaters);void multiPut(List<List<Object>> keys, List<T> vals);}
当你在一个 non-grouped streams 上面进行 aggregations (聚合)的话, Trident 会期待你的 State 对象实现 “Snapshottable” 接口:
public interface Snapshottable<T> extends State {T get();T update(ValueUpdater updater);void set(T o);}
MemoryMapState 和 MemcachedState 分别实现了上面的 2 个接口.
Implementing Map States
在 Trident 中实现 MapState 是非常简单的, 它几乎帮你做了所有的事情. OpaqueMap , TransactionalMap , 和 NonTransactionalMap 类实现了所有相关的逻辑, 包括容错的逻辑. 你只需要将一个知道如何执行相应 key/values 的 multiGet 和 multiPuts 的 IBackingMap 的实现提供给这些类就可以了. IBackingMap 接口看上去如下所示:
public interface IBackingMap<T> {List<T> multiGet(List<List<Object>> keys);void multiPut(List<List<Object>> keys, List<T> vals);}
OpaqueMap 会用 OpaqueValue 的 value 来调用 multiPut 方法, TransactionalMap 会提供 TransactionalValue 中的 value , 而 NonTransactionalMaps 只是简单的把从 Topology 获取的 object 传递给 multiPut .
Trident 还提供了一种 CachedMap 类来进行自动的LRU cache (缓存) map key/vals .
最后, Trident 提供了 SnapshottableMap 类, 通过将 global aggregations (全局聚合)存储到 fixed key (固定密钥)中将一个 MapState 转换成一个 Snapshottable 对象.
大家可以看看 MemcachedState 的实现, 从而学习一下怎样将这些工具组合在一起形成一个高性能的 MapState 实现. MemcachedState 是允许你选择使用 opaque transactional , transactional , 还是 non-transactional 语义的.

若有收获,就点个赞吧
0 人点赞
