Collection
增加方法
boolean add(E e)boolean addAll(Collection <? extends E> c)
删除方法
void clear()boolean remove(object o)boolean removeAll(Collection<?> c)
查看
Iterator<E> iterator();size();
判断
boolean contains(object o)boolean isEmpty();boolean equals();
List
继承自Collection 接口
boolean add(int index, E element);//查看E get(int index);int indexOf (Object o);int lastIndexOf(object o);//updateE set(int index, E element);void sort(Comparator<? super E> c);//deleteE remove(int index);
ArrayList
从源码描述中能够知道:
- ArrayList是可变数组的实现
- 允许null元素
- 容量是自增长的
- ArrayList不同步,如果有多个线程进行修改,需要加锁
- iterator和listIterator()是fail-fast机制的
底层数据结构
源码分析
ArrayList继承结构和层次关系
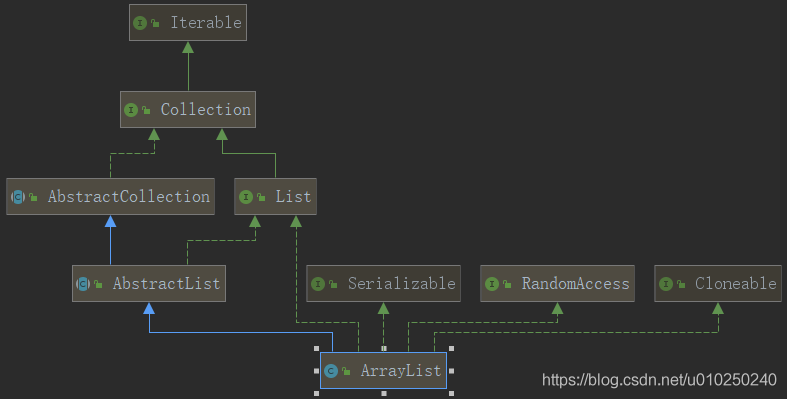
ArrayList实现了
serializable: 表示是ArrayList是可以转换成字节流实现了RandomAccess,表示 ArrayList支持随机访问,使用for循环会快于iterator迭代器
get(int index); 就是随机访问
实现了Cloneable 表示Object.clone方法
继承了AbstractList,表示在AbstractList的基础上增加一些ArrayList的特性方法
类的属性
- ArrayList有一个EMPTY_ELEMENTDATA ,当使用有参构造函数,传入0的时候,将其赋值给elementData数组
- DEFAULTCPACITY_EMPTY_ELEMENTDATA :使用无参构造函数的时候,将其赋值给elementData数组
- 有一个字段叫做DEFAULT_CAPACITY = 10,使用无参构造函数的时候,并且使用add方法添加了一个元素,这个数组大小就扩容成DEFAULT_CAPACITY
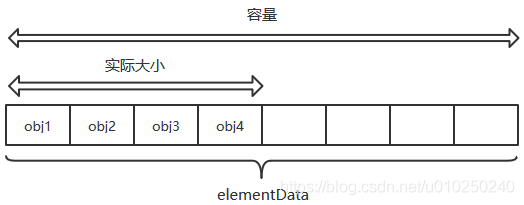
- size表示ArrayList实际的大小
- 一个Obejct数组 elementData,就是ArrayList的底层数据结构
- MAX_ARRAY_SIZE代表容器最大的大小,是Integer.MAXVALUE - 8, 因为要存储一些header words
构造方法
带参的构造函数ArrayList(int initialCapacity)
不带参构造函数ArrayList() : 直接把DEFAULTCPACITY_EMPTY_ELEMENTDATA 赋给 elementData
ArrayList(Collection<? extends E> c):构造一个包含指定Collection元素得列表:
把Collection转换成对象数组赋给elementData
如果Collection 长度 = = 0, 再把EMPTY_ELEMENTDATA 赋值给elementData
如果长度>0 并且 传入得Collection不能转换成Object[]类型得数组,就需要一次深拷贝(Arrays.copyOf),转换成Object[]类型的数组
主要方法
get方法():
判断一些有没有越界,没有就返回指定索引的元素,有就抛出异常
set(int index, E element):
判断有没有越界,如果没有越界,先记录Old Value, 然后更改对应索引的元素
add(E e)
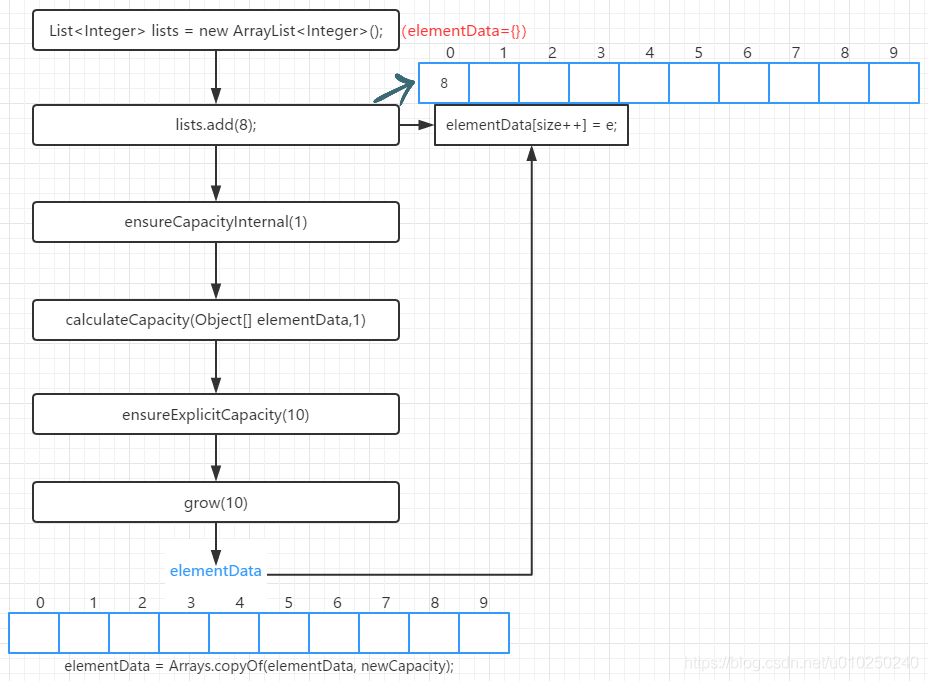
实际底层调用的是grow(minCapacity)
如果调用的是不带参构造函数,并且是第一次添加元素,扩容到默认默认容量10;如果不是空数组,添加size+1位置的元素
会在EnsureExplicitCapacity中自增 modCount 并且 当大小不够时调用grow()
grow():
第一次扩容成原来数组大小的1.5倍,如果这个newCapcity < minCapacity,就把minCapacity 赋值给 newCapcity 。
如果扩容后 newCapcity > MAX_ARRAYSIZE,就调用HugeCapacity(minCapacity) 赋值Integer.MAX_VALUE给newCapcity
调用Arrays.copyOf,进行数组扩容,默认用0赋值
(数组扩容后的底层数组长度newCapcity >= (原数组长度 + 1 或者默认长度)-> newCapcity )
可以减小扩容方法调用的次数
进行扩容的方法
List<Integer> lists = new ArrayList<Integer>();//由于不带参数的构造方法会赋值DEFAULTCPACITY_EMPTY_ELEMENTDATA ,第一次传入元素的时候会扩容到10lists.add(8);
不扩容的情况
List<Integer> lists = new ArrayList<Integer>(6);lists.add(8);
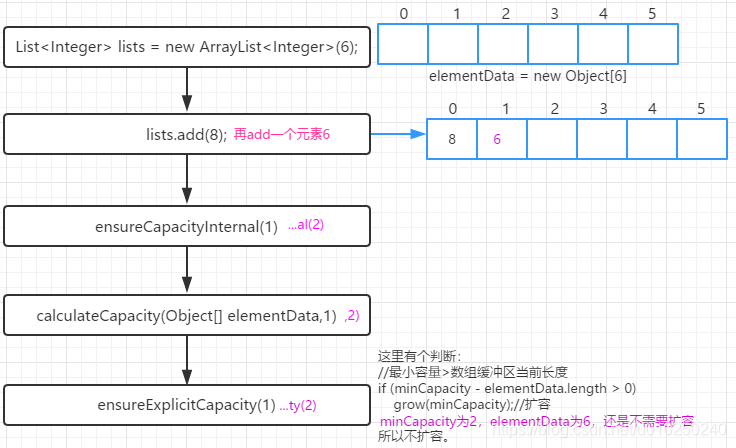
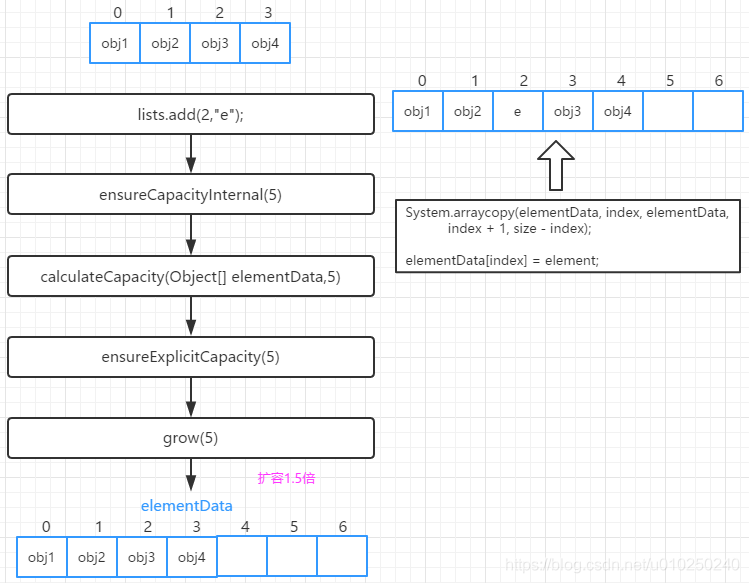
void add(int index, E element)
顺序后移的方式插入指定位置。
进行越界检查(
rangeCheckForAdd(index))ensureCapacityInternal()确保容量足够(可能需要扩容)
进行arrayCopy()目的就是空出index的位置插入element,并将index后的元素位移一个位置
elementData[index] = element;
size++;
remove(int index)
- 检查是否越界
- modCount++ 结构性修改次数
- 记录oldValue
- 将index后面的数向前移动一格System.arrayCopy
- size—,把整个数组的最后一个元素赋值为null,让GC来回收
- 返回被删除的元素
remove(Object o)
- 遍历所有对象(通过equals或者==来判断是否存在对应对象)
- 调用fastRemove
fastRemove
modCount++ 结构性修改次数
将index后面的数向前移动一格System.arrayCopy
size—,把整个数组的最后一个元素赋值为null,让GC来回收
removeRange(int fromIndex, int toIndex)
- modCount++ 结构性修改次数
- 记录要被删除索引的个数
- 通过System.arrayCopy把toindex后面的元素向前要删除元素的距离
- 把多出来的元素赋值null,让GC回收
RemoveAll 和 retainAll
调用的都是底层的batchRemove()
retainAll()表仅保留此 list 中那些也包含在指定 collection 的元素(可选操作)。换句话说,移除此 list 中未包含在指定 collection 中的所有元素。
list进行移除操作返回值为:true,反之返回值则为false。
indexOf和lastIndexOf
查找的时候按照o是null 使用==判断
如果o!=null,equals判断
indexOf(Object o)
- 如果对象o为null,遍历返回第一个null的下标
- 如果对象不为null,遍历返回第一个对象(equals判断)的下标
clear()
- modCOunt++
- 循环把所有元素置为null,等待GC
总结
1)arrayList可以存放null。
2)arrayList本质上就是一个elementData数组。
3)arrayList区别于数组的地方在于能够自动扩展大小,其中关键的方法就是grow()方法。本质上使用的是System.arrayCopy()方法复制成新的数组。
4)arrayList中removeAll(collection c)和clear()的区别就是removeAll可以删除批量指定的元素,而clear是全是删除集合中的元素。
5)arrayList由于本质是数组,所以它在数据的查询方面会很快,而在插入删除这些方面,性能下降很多,有移动很多数据才能达到应有的效果。
6)arrayList实现了RandomAccess,所以在遍历它的时候推荐使用for循环。
LinkedList
如果需要LinkedList成为线程安全,可以调用synchronizedList
内部结构分析
内部Node类作为双端链表
add
方法的核心就是三个函数
linkLast(Element e)linkFirst(E e)linkbefore(int index, E e)node(int index)
get(int index): 根据指定索引返回数据
getFirst(),element(),peek(),peekFirst() 这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,其中getFirst() 和element() 方法将会在链表为空时,抛出异常
remove
底层调用的是unlinkFirst 和 unlinkLast和unlink

若有收获,就点个赞吧
0 人点赞
