BloomFilter是什么?
Bloom filter是由Howard Bloom在1970年提出的二进制向量数据结构,它具有空间和时间效率,被用来检测一个元素是不是集合中的一个成员。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
优点
- 空间效率和查询时间都远远超过一般的算法。
它的插入和查询时间都是常数
- 良好的安全性
缺点
- 有一定的误识别率
可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。
- 删除困难
一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。
原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。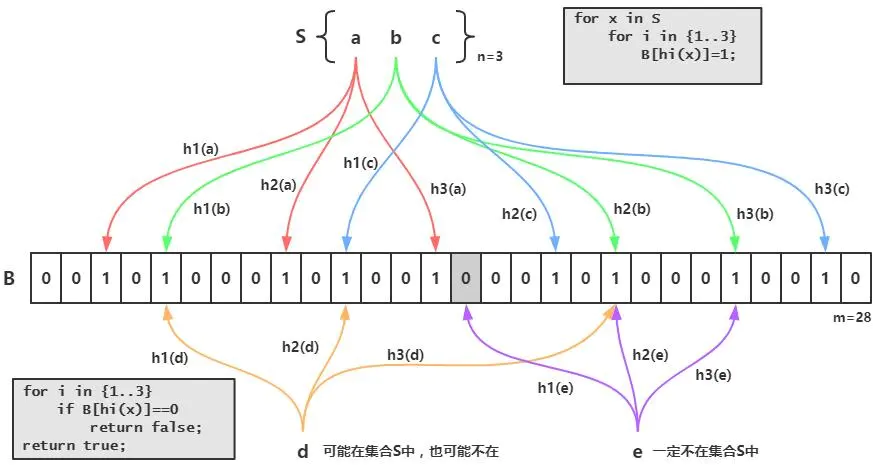
实现参数
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式: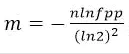
哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k:
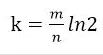
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考Bloom Filters - the math,Bloom_filter-wikipedia
自己实现
public class MyBloomFilter {/*** 你的布隆过滤器容量*/private static final int DEFAULT_SIZE = 2 << 28;/*** bit数组,用来存放key*/private static BitSet bitSet = new BitSet(DEFAULT_SIZE);/*** 后面hash函数会用到,用来生成不同的hash值,可随意设置,别问我为什么这么多8,图个吉利*/private static final int[] INTS = {1, 6, 16, 38, 58, 68};public static void main(String[] args) {MyBloomFilter myNewBloomFilter = new MyBloomFilter();myNewBloomFilter.add("张学友");myNewBloomFilter.add("郭德纲");myNewBloomFilter.add("蔡徐鸡");myNewBloomFilter.add(666);System.out.println(myNewBloomFilter.isContain("张学友"));//trueSystem.out.println(myNewBloomFilter.isContain("张学友 "));//falseSystem.out.println(myNewBloomFilter.isContain("张学友1"));//falseSystem.out.println(myNewBloomFilter.isContain("郭德纲"));//trueSystem.out.println(myNewBloomFilter.isContain("蔡徐老母鸡"));//falseSystem.out.println(myNewBloomFilter.isContain(666));//trueSystem.out.println(myNewBloomFilter.isContain(888));//false}/*** add方法,计算出key的hash值,并将对应下标置为true*/public void add(Object key) {Arrays.stream(INTS).forEach(i -> bitSet.set(hash(key, i)));}/*** 判断key是否存在,true不一定说明key存在,但是false一定说明不存在*/public boolean isContain(Object key) {boolean result = true;for (int i : INTS) {//短路与,只要有一个bit位为false,则返回falseresult = result && bitSet.get(hash(key, i));}return result;}/*** hash函数,借鉴了hashmap的扰动算法,强烈建议大家把这个hash算法看懂,这个设计真的牛皮加闪电*/private int hash(Object key, int i) {int h;return key == null ? 0 : (i * (DEFAULT_SIZE - 1) & ((h = key.hashCode()) ^ (h >>> 16)));}}
truefalsefalsetruefalsetruefalse
自己实现这边只使用了一次hash函数,实际实现的时候可能会使用到多次hash函数。
guava实现
引入guava包
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>29.0-jre</version></dependency>
测试类
测试分两步:
1、往过滤器中放一百万个数,然后去验证这一百万个数是否能通过过滤器
2、另外找一万个数,去检验漏网之鱼的数量
public class TestBloomFilter {
/**
* 布隆过滤器的大小
*/
private static int total = 1000000;
/**
* 布隆过滤器
*/
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
public static void main(String[] args) {
// 初始化1000000条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put(i);
}
// 匹配已在过滤器中的值,是否有匹配不上的
for (int i = 0; i < total; i++) {
if (!bf.mightContain(i)) {
System.out.println("有坏人逃脱了~~~");
}
}
// 匹配不在过滤器中的10000个值,有多少匹配出来
int count = 0;
for (int i = total; i < total + 10000; i++) {
if (bf.mightContain(i)) {
count++;
}
}
System.out.println("误伤的数量:" + count);
}
}
输出
误伤的数量:320
运行结果表示,遍历这一百万个在过滤器中的数时,都被识别出来了。一万个不在过滤器中的数,误伤了320个,错误率是0.03左右。
错误率的选择
看下BloomFilter的源码:
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long)expectedInsertions, fpp);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
@VisibleForTesting
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, BloomFilter.Strategy strategy) {
Preconditions.checkNotNull(funnel);
Preconditions.checkArgument(expectedInsertions >= 0L, "Expected insertions (%s) must be >= 0", expectedInsertions);
Preconditions.checkArgument(fpp > 0.0D, "False positive probability (%s) must be > 0.0", fpp);
Preconditions.checkArgument(fpp < 1.0D, "False positive probability (%s) must be < 1.0", fpp);
Preconditions.checkNotNull(strategy);
if (expectedInsertions == 0L) {
expectedInsertions = 1L;
}
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException var10) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", var10);
}
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long)expectedInsertions);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03D);
}
该版本的BloomFilter一共是5个create方法,最终都走向了第三个create方法。
- 看一下每个参数的含义:
- funnel:数据类型(一般是调用Funnels工具类中的)
- expectedInsertions:期望插入的值的个数,Long类型,取值范围大于等于0。
- fpp 错误率(默认值为0.03),Double类型,取值范围在0-1之间。
- strategy 哈希算法(我也不懂啥意思)Bloom Filter的应用

当我们使用这种没有指定错误率的方式创建的时候
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
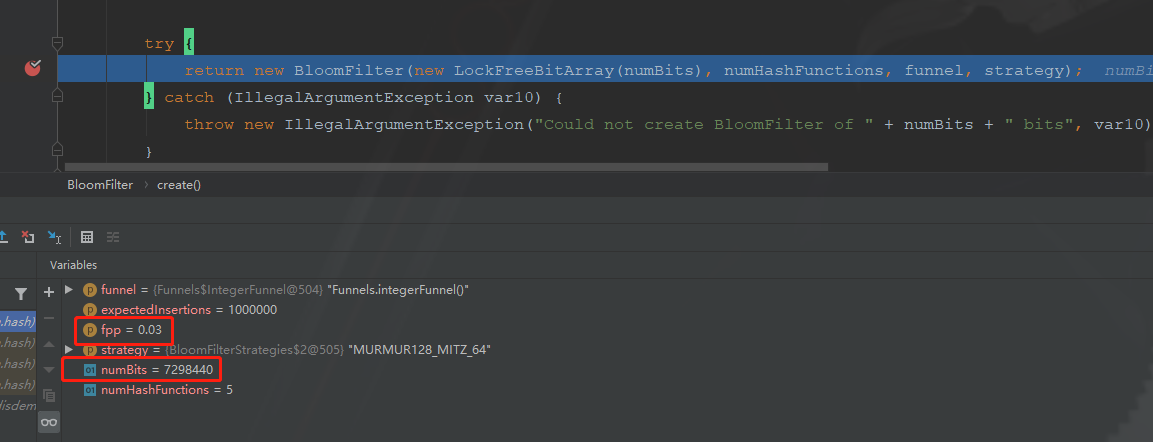
上面的numBits,表示存一百万个int类型数字,需要的位数为7298440,700多万位。理论上存一百万个数,一个int是4字节32位,需要4_8_1000000=3200万位。如果使用HashMap去存,按HashMap50%的存储效率,需要6400万位。可以看出BloomFilter的存储空间很小,只有HashMap的1/10左右。
上面的numHashFunctions,表示需要5个函数去存这些数字。
当我们使用指定错误率的方式创建的时候
错误率设置为0.0003
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.0003);
误伤的数量:4
此时误伤的数量为4,错误率为0.000004左右。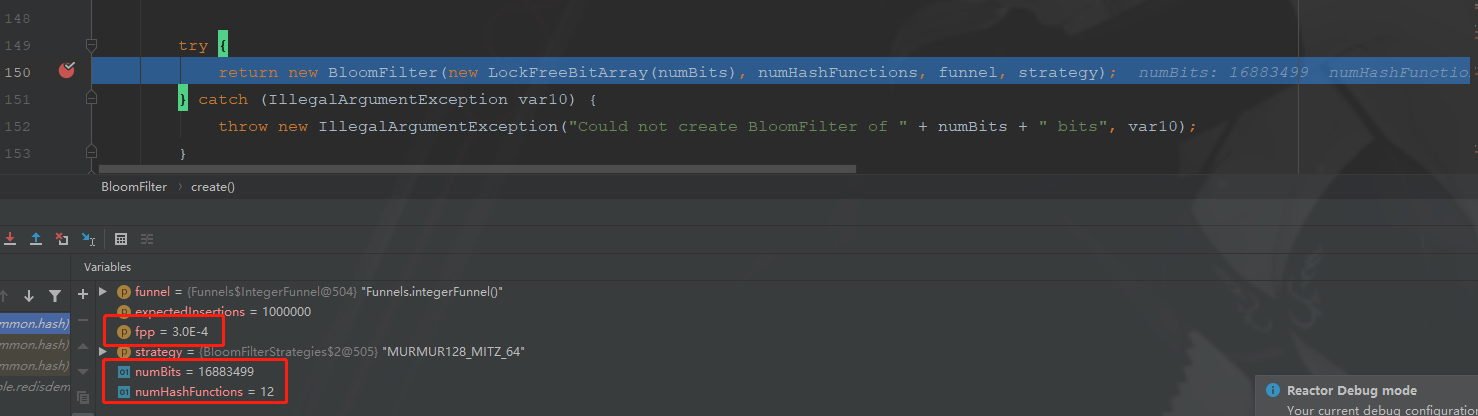
当错误率设为0.0003时,所需要的位数为16883499,1600万位,需要12个函数
和上面对比可以看出,错误率越大,所需空间和时间越小,错误率越小,所需空间和时间约大
使用场景
- cerberus在收集监控数据的时候, 有的系统的监控项量会很大, 需要检查一个监控项的名字是否已经被记录到db过了, 如果没有的话就需要写入db.
- 爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
- 垃圾邮件过滤。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。 :::info 以上这些场景有个共同的问题:如何查看一个东西是否在有大量数据的池子里面。 :::

若有收获,就点个赞吧
0 人点赞
