
1. 基础结构
数组
一段连续的物理内存区域,通过下标定位元素;
- 查找时间复杂度:O(1);
- 中间插入、移除数组中元素 时间复杂度 O(n);
链表
一种链式数据结构,由若干个节点组成,每个节点包含指向下一个节点的指针;
链表的物理存储方式是数据存储,访问方式是顺序访问。
查找时间复杂度:O(n);
中间插入、删除的时间复杂度:O(1);
汇总
常用的数据结构有很多;大多是以数组和链表为基础进行构建;因此数组和链表也可以叫做数据结构的物理结构;

2. 衍生结构
栈
一种线性逻辑结构,可以用数组实现,也 可以用链表实现 ;先进后出原则;
队列
一种线性逻辑结构,可以用数组实现,也 可以用链表实现 ;先进先出原则;
哈希表
哈希表也叫散列表,是存储Key-Value映射的集合。对于某一个key, 哈希表可以在接近O(1) 的时间内进行读写操作。哈希表通过哈希函数实现 Key 和 数组下标的转化,通过开放地址法和链地址法来解决哈希冲突;
写操作
先将key 利用哈希函数转化为 值,然后取模,定位到数组的位置,插入此处;
若此处已有值,
则采用开放地址法,在下一个没有被占用的地方插入;
或者采用链地址法,在此处的元素下,链接一个元素;
3. 树🌲
二叉树
树的一种特殊形式,顾名思义,这种树🌲每个节点最多有2个孩子节点。注:最多2个是指,可以是2个,也可以是1个,也可以没有;
结构如下所示:
满二叉树
一个二叉树的
- 所有非叶子🍃节点都存在做孩子和右孩子;
- 并且所有叶子🍃节点都在同一层级上;
那么这个🌲树就是满二叉树;
如下所示: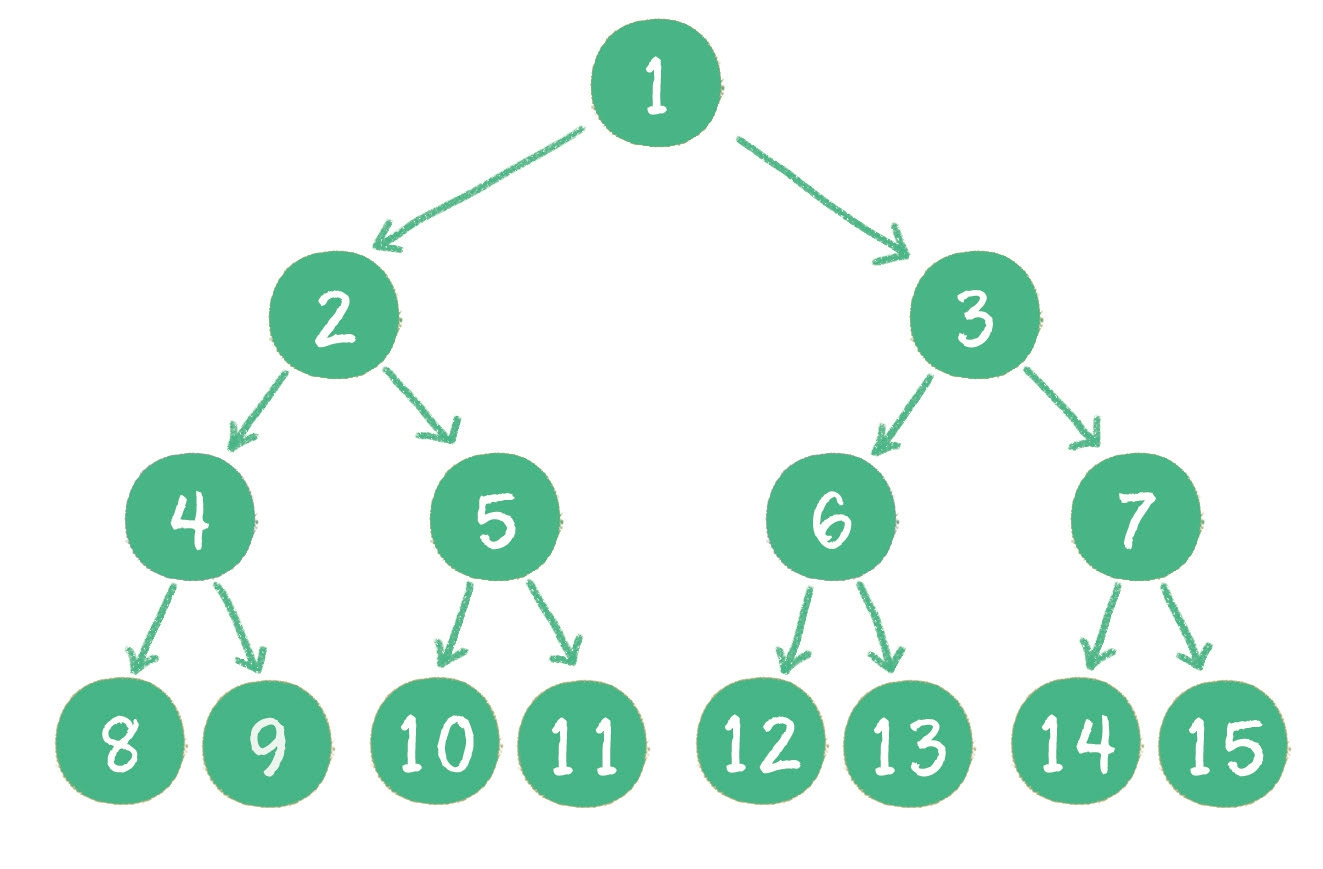
完全二叉树
对于有n个节点的二叉树,
- 按层级顺序编号,则所有节点的编号为从1到n;
- 若果这个树所有节点和同样深度的满二叉树的编号从1到n 的节点位置相同;
则这个二叉树为完全二叉树;
示例如下:
遍历
从宏观的角度来看,二叉树的遍历归结为两大类。
1) 深度优先遍历(前序遍历、中序遍历、后续遍历);
2)广度优先遍历(层序遍历);
注:深度优先遍历的条件是,以根节点为基准的,且先左后右,不这样的话,遍历的种类有 3! = 6种了;
前序遍历
即,根节点在首位;根节点、左节点、右节点;

中序遍历
即,根节点在中间;左节点、根节点、右节点;
后续遍历
即,根节点在后边;左节点、右节点、根节点;
遍历源码(java版)
TreeNode 定义
/**** 二叉树节点*/@Data@NoArgsConstructor@AllArgsConstructorpublic class TreeNode {private Integer data;private TreeNode leftNode;private TreeNode rightNode;}
TreeTravese 遍历测试
/*** @desc 二叉树遍历* @author liuph* @date 2022/02/22 17:03*/public class TreeTraverse {/**** <pre>* 创建一个二叉树,形式;*** 1* / \* 2 3* / \ \* 4 5 6* </pre>*/public TreeNode createTree(){TreeNode treeNode4 = new TreeNode(4, null, null);TreeNode treeNode5 = new TreeNode(5, null, null);TreeNode treeNode6 = new TreeNode(6, null, null);TreeNode treeNode2 = new TreeNode(2, treeNode4, treeNode5);TreeNode treeNode3 = new TreeNode(3, null, treeNode6);return new TreeNode(1, treeNode2, treeNode3);}public void firstTraverse(TreeNode node){System.out.println("当前遍历节点:" + node.getData());TreeNode leftNode = node.getLeftNode();TreeNode rightNode = node.getRightNode();if(Objects.nonNull(leftNode)){firstTraverse(leftNode);}if(Objects.nonNull(rightNode)){firstTraverse(rightNode);}}public void middleTraverse(TreeNode node){TreeNode leftNode = node.getLeftNode();TreeNode rightNode = node.getRightNode();if(Objects.nonNull(leftNode)){middleTraverse(leftNode);}System.out.println("当前遍历节点:" + node.getData());if(Objects.nonNull(rightNode)){middleTraverse(rightNode);}}public void backTraverse(TreeNode node){TreeNode leftNode = node.getLeftNode();TreeNode rightNode = node.getRightNode();if(Objects.nonNull(leftNode)){backTraverse(leftNode);}if(Objects.nonNull(rightNode)){backTraverse(rightNode);}System.out.println("当前遍历节点:" + node.getData());}@Testpublic void traverseTest(){System.out.println("----------前序遍历----------");TreeNode tree = createTree();firstTraverse(tree);System.out.println("----------中序遍历----------");middleTraverse(tree);System.out.println("----------后序遍历----------");backTraverse(tree);}}
二叉堆
一种完全二叉树,有两种:最大堆 和最小堆,可以用于创建优先队列(最大优先级队列、最小优先级队列);
最大堆特点:
- 任何一个父节点,都不小于它任务子节点的值;
最小堆特点:
- 任何一个父节点,都不大于它任务子节点的值;
物理存储:
一般使用数组进行存储,规则如下:
假设父节点为p, 左子节点 = 2p + 1, 右子节点 = 2p + 2;
堆排序
利用最大堆/最小堆的特性,就行排序;
示例:使用最大堆进行从小到大排序;
步骤:
- 1)现将需要排序的数组转化成最大堆;
- 2)取堆顶元素 与数组最后一位进行交换;
- 3)将0-n-1 继续转化为最大堆,再次执行2)操作;
- 4)重复2)、3),直到排序完成;
代码示例(java)
public class HeapSortTest{// 向下调整public static void down(int [] a ,int start ,int end ){// 定义父节点、左孩子int p = start;int l = 2 * p + 1;while(l < end){if(a[l] < a[l+1]){ // 取最大的子节点l++;}if(a[p] < a[l]){ // 比父节点大,交换int temp = a[p];a[p] = a[l];a[l] = temp;}p = l;l = 2 * l + 1;}}// 升序排public static void sortAsc(int [] a){for(int i = a.length/2 - 1; i >= 0 ; i--){down(a, i, a.length - 1);}// 逐步取最大堆 堆顶,置换完成排序for(int i = a.length - 1; i > 0 ; i --){int temp = a[0];a[0] = a[i];a[i] = temp;down(a,0,i - 1);}}}
注:排序是为啥从 a.length - 2 开始呢,因为😄从队尾开始,保证每个元素都遍历,a.length = 2 * p + 2, p = a.length/2 - 1;
优先队列
此处优先队列基于二叉堆来实现,队列😄我们日常使用重点关注入队、出队,那么从这两个角度来说一下原理;
1)入队;
- a. 默认也插入到数组尾部;
- b. 做上浮操作(与 父节点 比较 ,大于父节点上浮);
- c. 将父节点作为起始节点,再找父节点,上浮;
- d. 重复b、c 完成入队;
2) 出队;
- a. 弹出a[0] 元素;
- b. 将最后一个元素,补齐到a[0];
- c. a[0] 做下沉处理;
示例代码(java)
public class MaxPriorityQueue {// 默认定义数组长度为1024private int [] a = new int [1024];// 定义当前存储的位置private int currentIndex = 0;// 添加元素public void add(int value){a[currentIndex]=value;if(currentIndex > 0){// 上浮操作up();}currentIndex++;}// 对数组最后一个存储的值进行上浮操作public void up(){// 计算父节点 l = 2p + 1, r = 2p + 2int p = currentIndex%2 == 0 ? (currentIndex-1)/2 : (currentIndex-2)/2;int currentTemp = currentIndex;while(p >= 0){if(a[p] < a[currentTemp]){ // 父节点 < 当前节点 ,交换int temp = a[p];a[p] = a[currentTemp];a[currentTemp] = temp;// 节点向上调整currentTemp = p;p = p%2 == 0 ? p/2 - 2 : p/2 -1;}else{break;}}}// 弹出元素,尾节点替换a[0],向下调整public int pop(){int value = a[0];a[0] = a[currentIndex - 1];a[currentIndex - 1] = 0;// 向下调整down();currentIndex--;return value;}// a[0] 向下调整public void down(){int p = 0;int l = 1;while(l < currentIndex){if(a[l] < a[l+1]){ // 取最大的子节点l++;}if(a[p] < a[l]){ // 父 < 最大子 ,替换int temp = a[p];a[p] = a[l];a[l] = temp;// 向下调整p = l;l = 2*l + 1;}else{break;}}}public void print(){for (int i = 0; i < currentIndex; i++) {System.out.print(a[i] + ",");}}@Testpublic void test(){MaxPriorityQueue priorityQueue = new MaxPriorityQueue();priorityQueue.add(6);priorityQueue.add(7);priorityQueue.add(9);priorityQueue.add(5);priorityQueue.add(4);System.out.print("最大堆:");priorityQueue.print();System.out.println();priorityQueue.pop();System.out.print("pop后最大堆:");priorityQueue.print();}}
红黑树
用途
jdk8的hashmap 当链表长度>8 是,自动转化为红黑树;
TreeMap、TreeSet 都使用红黑树作为底层数据结构;
为了更好的介绍红黑树,我们从 (BST)查找树、(AVL)平衡树、再到(RBT)红黑树;
三者的关系如下:
平衡树、红黑树 均属于 排序二叉树; 
查找树特点:
1)左子树上的所有节点的值均小于或者等于 它的 根节点的值;
2)右子树上所有的节点的值均大于或者等于 它的 根节点的值;
3) 左、右树叶分别为二叉排序树;
完美的情况下是这样的;
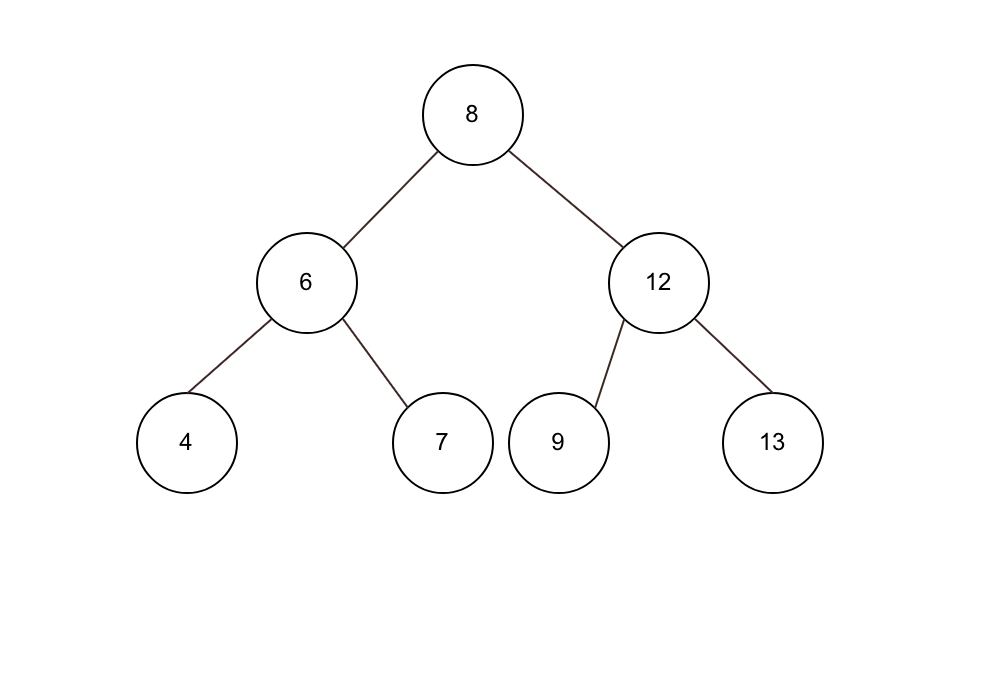
由于排序二叉树的特性,不断的插入可能演变成为 链表结构;之间复杂度一下 成了O(n);

平衡树特点:
- 在查找树的基础上,新增如下特点:
- 每个节点的左、右字数的高度差绝对值最多为1;
平衡功能的实现:
如下图,新增1会导致 高度差 > 1 , 此时平衡树会进行平衡,AVL 的调整过程称为:左旋和右旋;

旋转之前,首先确定旋转支点(pivot):这个旋转点就是失去平衡的这部分树,也是自平衡后的根节点;
左旋就是逆时针转,右旋是顺时针转
导致失衡的场景有四个:
左左失衡;
右右失衡;
左右失衡;
右左失衡;
删除元素,也会导致AVL失衡,需要再平衡,但是原理和插入元素是类似的。
场景一:左左失衡
7为支点,即旋转后的 root 节点,根据7进行旋转,9向下右旋,8作为9点左节点;
右右失衡 与之对应,不予介绍;
场景二: 左右失衡
即:插入的元素在左侧不平衡元素的右侧

先以7为支点,6向左下旋转,7上接9; 然后 就是左左结构了,以7为支点,9向右下旋转,8接9;
右左与 左右对应,不予介绍;
平衡树解决了 查找树可能转化成链表的为题; 那么为啥还会有红黑树呢?
就是因为平衡树的绝对平衡,新增、插入、删除的时候很容易就出现需要需要平衡的情况;导致新增、插入、删除效率低;
红黑树特点:
1) 所有节点非黑即红;
2)根节点、叶子节点均为黑色;
3)根几点 到叶子节点 中途 遇到的 黑点 ,所有线路个数一致;
4) 不能出现两个红节点相连的情况;
红黑树的平衡方式:变色、左旋、右旋
参见
- 小灰学算法


若有收获,就点个赞吧
0 人点赞
